Die „Tester-Tea-Time“ ist ein Beitragsformat auf diesem Blog, in dem Themen aufgegriffen werden, die Testerinnen und Tester tagtäglich beschäftigen. Gewisse Problemstellungen oder Themen kehren immer wieder, daher soll hier eine Basis geschaffen werden, solche Phänomene zu erläutern und Lösungen dafür zu finden. Zudem sollen Diskussionen und neue Denkweisen angeregt werden. Im Testing können wir viel voneinander lernen, indem wir unseren Alltag beobachten!
Moderator: Willkommen zur Tester-Tea-Time! Im Interview mit Testerinnen und Testern der ZEISS Digital Innovation (ZDI) werden wir erneut spannende Themen diskutieren.
Widmen wir uns nun dem heutigen Thema. Dazu sprechen wir mit Sandra Wolf (SW), Testerin bei ZDI. Warum beschäftigen wir uns dieses Mal mit dem Thema „Rechtschreibung“ und wo siehst du den Zusammenhang mit der Softwareentwicklung?
SW: Der Alltag eines Testers hält viele Herausforderungen bereit. Gerade während des Testprozesses ist große Konzentration gefragt, wenn jedes Detail auf Qualität überprüft werden muss. Eines dieser Details ist die Rechtschreibung und Grammatik. Oft wird es unterschätzt, wie wichtig die korrekte Orthografie sein kann. Im Arbeitsalltag passiert es oft, dass Rechtschreibfehler in der Software gefunden werden. Doch wenn diese zur Behebung an die Entwicklung gemeldet werden, kommt es nicht selten vor, dass der Tester dafür belächelt wird. Die vorherrschende Meinung ist, dass das nur sehr kleine und unwichtige Fehler wären. Im heutigen Gespräch soll mit dieser Meinung aufgeräumt werden. Rechtschreibung und Zeichensetzung sind nicht gerade die beliebtesten Themen und werden häufig als sehr trocken empfunden. Dabei sind gerade diese Regeln, die wir seit der Schulzeit lernen, eine Orientierungshilfe für uns und unser Gehirn. Ein Wort, das richtig geschrieben wird, wird auch leichter gelesen, im Satz zu einer Aussage kombiniert und somit im Gehirn verarbeitet. Aufmerksame Leser – oder im Fall der Softwareentwicklung – Nutzer werden zwangsläufig über falsche Rechtschreibung in der Software stolpern. Es wurde sogar nachgewiesen, dass bestimmte Persönlichkeitstypen unterschiedlich emotional auf falsche Orthografie reagieren (vgl. Weiß, 2016). Somit können Fehler in diesem Bereich im Gegensatz zu ihrem trockenen Ruf Emotionen auslösen, die dann als Konsequenz den Umgang mit der Software beeinflussen.
Abbildung:Stanislaw Traktovenko und Sandra Wolf in der virtuellen Tester-Tea-Time im Gespräch.
Moderator: Von welcher Art der Beeinflussung sprechen wir in diesem Fall?
SW: Korrekte Rechtschreibung strahlt zum Beispiel Seriosität aus. In Bewerbungen und amtlichen Anträgen wird eine fehlerfreie Rechtschreibung vorausgesetzt. Es ist sogar in Studien belegt worden, dass beispielsweise die Chancen auf Bewilligung eines Kreditantrags durch sprachliche Fehler vermindert werden (vgl. Weiß, 2016). Übertragen wir das nun auf die Software, die wir entwickeln, ist nur ein möglicher Schluss zu ziehen: Rechtschreibung ist essenziell für eine adäquate Nutzung und die Außenwirkung der Software beim Kunden. Und somit sollte dieses Thema innerhalb des Entwicklungsprozesses eindeutig ernster genommen werden und mehr Aufmerksamkeit bekommen als bisher. Schauen wir uns den Alltag von Testern und Entwicklern an, dann wissen wir, dass die Funktionalität der Software im Mittelpunkt steht. Natürlich ist nachvollziehbar, dass ein kosmetisch wirkendes Thema wie die Rechtschreibung hinter aufwendig programmierten Anwendungsteilen zurücktritt. Das sollte alle Beteiligten des Prozesses allerdings nicht über die Wichtigkeit hinwegtäuschen. Denn ganz klar ist, dass der Erfolg eines Produktes und somit auch einer Anwendung von der sprachlichen Qualität beeinflusst werden kann. Der erste Eindruck beim Lesen eines Textes oder beim Nutzen einer Software lässt uns automatisch auch auf den Bildungsgrad der Schöpfer schließen (vgl. Frost, 2020). Somit kann durch eine fehlerhafte Rechtschreibung ein schlechtes Licht auf eine gute Software geworfen werden.
Moderator: Wie muss ich mir dieses “schlechte Licht”, in dem die Software dann steht, im Detail vorstellen?
SW: Durch eine schlechte Rechtschreibung kann das Vertrauen in die Qualität der Software verloren gehen und die Akzeptanz für die Anwendung sinken. Der Nutzer könnte davon ausgehen, dass generell wenig Wert auf Qualität gelegt wird, wenn schon mit der Rechtschreibung nachlässig umgegangen wird. Schließlich drückt eine korrekte Orthografie nicht nur Professionalität, sondern auch einen gewissen Respekt gegenüber dem Leser/Nutzer aus. Es konnte sogar festgestellt werden, dass eine Textqualität beeinflusst, ob jemand vom Interessenten zum Käufer wird. Wird das auf die Softwareentwicklung bezogen, kann es auf jeden Fall Budget einsparen, wenn von Anfang an auf die Rechtschreibung geachtet wird und die Meldung solcher Fehler ernst genommen wird (vgl. Frost, 2020). Letztendlich präsentieren wir in unseren Projekten auch unser Unternehmen, weshalb das Thema der Orthografie weitreichendere Auswirkungen haben kann, als wir zunächst denken. Im besten Fall kann durch eine gute Rechtschreibung der Ruf unserer Softwareentwicklung verbessert werden bzw. erhalten bleiben. Dadurch können wiederum mehr Kunden und höhere Umsätze erzielt werden, weil die gleichbleibende Qualität unserer Softwareprodukte ein Argument für eine Zusammenarbeit mit der ZDI sein kann.
Moderator: Hier möchte ich gern anknüpfen und Stanislaw Traktovenko (ST) aus unserem Usability-Team zu Wort kommen lassen. Welche Bedeutung nimmt das Thema der Rechtschreibung aus deiner Sicht ein? Siehst du ebenfalls die Auswirkungen in dem von Sandra Wolf beschriebenen Maße?
ST: Aus meiner Sicht hat die Rechtschreibung einen Einfluss auf die Lesbarkeit und dadurch auf die Wahrnehmung der Informationen in der Anwendung. Wir ordnen das den Usability-Prinzipien Konsistenz und Sprache zu. Rechtschreibfehler haben also potenziell eine direkte Auswirkung auf die Usability einer Anwendung. Eine inkorrekte Orthografie stört zum Beispiel den Lesefluss und somit die Wahrnehmung der Software durch den Nutzer. Es entsteht ein negatives Gefühl und der Nutzer beschäftigt sich nicht mehr mit der Aufgabe, die er mit der Software eigentlich verfolgt hatte. Er wird durch eine falsche Rechtschreibung abgelenkt und das beeinflusst seine Effektivität und Effizienz. Auch wenn Rechtschreibung nur ein kleiner Bruchteil der Usability ist, kann sie somit größere Auswirkungen haben als gedacht, so wie Sandra bereits vorher erläutert hat.
Moderator: Vielen Dank, Sandra und Stanislaw für diese interessanten Einblicke. Die Auswirkungen sind tatsächlich weitreichender als erwartet, das ist sehr erstaunlich. Wir können somit zusammenfassen, dass das trocken wirkende Thema der Rechtschreibung in allen Softwareprojekten ernst genommen werden muss, um eine möglichst hohe Qualität zu liefern und sowohl die Produkte als auch uns als Unternehmen adäquat zu präsentieren. Das Thema der Rechtschreibung wirkt im ersten Moment vielleicht banal, hat aber im Endeffekt eine große Wirkung und somit Wichtigkeit für uns alle. Das Thema sollte daher unbedingt die Aufmerksamkeit bekommen, die es verdient hat.
In den folgenden Beiträgen werden wir weitere Problemstellungen aus dem Alltag von Testerinnen und Testern aufgreifen und besprechen, welche möglichen Lösungsansätze es dafür gibt.
Die GraalVM ist nun seit reichlich zwei Jahren am Markt. Sie verspricht im Wesentlichen zwei Dinge: Bessere Laufzeiteigenschaften und die Integration mehrerer Programmiersprachen.
Dieser Blogbeitrag konzentriert sich auf die Performance. Dabei soll es aber nicht primär darum gehen, ob und wieviel ein spezielles Programm auf dem Graal-JDK schneller ausgeführt wird als auf einem herkömmlichen JDK. Die konkreten Messwerte und die relativen Vergleiche sind ohnehin nicht nur vom untersuchten Programm abhängig und wenig verallgemeinerbar, sondern auch nur Momentaufnahmen: Sowohl die GraalVM als auch beispielsweise das OpenJDK werden beständig weiterentwickelt, so dass sich auch die Messwerte stets ändern werden. Stattdessen beschäftigt sich der Blogbeitrag vor allem mit den Fragen: Warum sollte die GraalVM wesentlich performanter sein? Was macht sie anders als die herkömmlichen JDKs? Damit wird eine Abschätzung möglich, ob alle Programme performanter ausgeführt werden oder keine nennenswerte Steigerung zu erwarten ist oder ob die Performance-Steigerung nur in bestimmten Anwendungsfällen zu erwarten ist. Und letztendlich, ob das „herkömmliche“ Java demzufolge zu langsam ist…
Entwicklung der Compiler
Da die Performance eines Java-Programms wesentlich durch den Compiler bestimmt wird und auch hier die Kernfrage ist, was die GraalVM anders macht verschaffen wir uns zunächst einmal einen Überblick über Compiler.
In den Anfängen der Programmierung existierte zunächst noch gar kein Compiler – es wurde direkt der Maschinencode programmiert. Da dies unübersichtlich und wenig verständlich war, hat sich zeitnah der Assembler-Code entwickelt. Dabei handelt es sich jedoch im Wesentlichen um eine direkte Abbildung des Maschinencodes – nur dass statt Binär- oder Hexadezimal-Opcodes nun Buchstabenkürzel verwendet werden. Auch hier sprechen wir (zumindest im Scope dieses Blogbeitrags) noch nicht von einer Programmiersprache und einem Compiler.
Mit der Zeit wurde die Entwicklung immer komplizierterer Programme notwendig. Damit wurde der Assembler-Code zunehmend unpraktikabel. Daher wurden in den 1950er Jahren die ersten höheren Programmiersprachen entwickelt. Diese benötigten einen Compiler, der den Quelltext in Maschinencode übersetzt.
Dies war zunächst der klassische AOT-Compiler (AOT: Ahead Of Time). Der Quelltext wird analysiert (Syntaxanalyse), in eine interne Baumstruktur überführt (Syntaxbaum) und aus diesem wird Maschinencode generiert (Codegenerierung). Die entstehende Binärdatei kann nun direkt ausgeführt werden.
Alternativ zur AOT-Kompilierung kann ein Programm auch durch einen Interpreter ausgeführt werden. Hierbei wird der Quelltext eingelesen und zeilenweise durch den Interpreter umgesetzt. Die eigentlichen Operationen (z. B. Addition, Vergleich, Programmausgabe) führt dann der Interpreter aus.
Der AOT-Compiler hat gegenüber dem Interpreter den Vorteil, dass die Programme wesentlich schneller ausgeführt werden. Allerdings sind die erzeugten Binärdateien maschinenabhängig. Darüber hinaus hat der Interpreter bessere Fehleranalysemöglichkeiten, da er beispielsweise Zugriff auf Laufzeitinformationen hat.
Java, Interpreter und JIT-Compiler
Beim Entwurf der Programmiersprache Java war ein Ziel, dass sie architekturneutral und portabel ist. Aus diesem Grund wurde der Java-Quellcode von Anfang an in maschinenunabhängigen Bytecode übersetzt. Dieser konnte dann von einer Laufzeitumgebung, der JRE (Java Runtime Environment), interpretiert werden. Damit war der übersetzte Bytecode maschinenunabhängig. So konnten beispielsweise Applets ohne Anpassungen auf einem Windows-PC, einem Mac oder einer Unix-Workstation ausgeführt werden. Die JRE muss dazu – unabhängig vom Applet – vorab auf den Workstations installiert sein.
Diese Mischform – AOT bis zum Bytecode, dann Interpretation zur Laufzeit – ist übrigens keine Idee aus der Java-Welt: Bereits in den 1970er Jahren hat beispielsweise Pascal den p-Code genutzt. [1]
Als die Java-Technologie im Jahre 1995 veröffentlicht wurde [2], war diese Maschinenunabhängigkeit zunächst mit großen Performance-Einbußen verbunden. Viele der damals relevanten Programmiersprachen wie bspw. „C“ kompilieren ihren Quellcode direkt in Maschinencode (AOT). Dieser kann auf dem entsprechenden System nativ ausgeführt werden und ist somit wesentlich performanter als die Interpretation des Bytecodes. Zu jener Zeit hat sich in den Köpfen vieler IT-Fachkräfte die Grundeinstellung „Java ist langsam“ festgesetzt – damals zu Recht.
Nun ist aber ein weiteres Entwurfsziel der Programmiersprache Java die hohe Leistungsfähigkeit. Aus diesem Grund wurde im Jahr 1998 der JIT-Compiler (JIT: Just In Time) eingeführt [2]. Damit wurden die Performance-Einbußen durch die reine Interpretation stark reduziert.
Bei der JIT-Kompilierung wird der Bytecode beim Programmstart zunächst ebenfalls interpretiert. Allerdings wird dabei genau verfolgt, welche Programmteile wie oft ausgeführt werden. Die häufig ausgeführten Programmteile werden nun – zur Laufzeit – in Maschinencode übersetzt. Zukünftig werden diese Programmteile nicht mehr interpretiert, sondern es wird der native Maschinencode ausgeführt. Hier wird somit zunächst Ausführungszeit für die Kompilierung „investiert“, um bei jedem zukünftigen Aufruf dann Ausführungszeit einsparen zu können.
Die JIT-Kompilierung ist daher ein Mittelweg zwischen AOT-Kompilierung und Interpretation. Die Plattformunabhängigkeit bleibt erhalten, da der Maschinencode erst zur Laufzeit erzeugt wird. Und da die häufig genutzten Programmteile nach einer gewissen Warmlauf-Zeit als nativer Maschinencode ausgeführt werden, ist auch die Performance (dann) annähernd so gut wie bei der AOT-Kompilierung. Ganz allgemein gilt dabei: Je häufiger einzelne Programmteile ausgeführt werden, desto mehr können die anderen, interpretierten Programmteile bei der Performance-Betrachtung vernachlässigt werden. Und dies gilt vor allem für oft durchlaufene Schleifen oder langlaufende Server-Anwendungen, deren Methoden ständig aufgerufen werden.
Laufzeitoptimierungen
Mit den bisher betrachteten Mechanismen ist der JIT-Compiler zwar plattformunabhängig – kann sich aber an die Ausführungszeit des AOT-Compilers nur herantasten, sie jedoch nicht erreichen oder gar übertreffen. Aus diesem Grund war zu dem Zeitpunkt, als der JIT-Compiler in das JDK integriert wurde, noch keineswegs sicher, dass es für einen Siegeszug ausreichen wird.
Allerdings hat der JIT-Compiler einen großen Vorteil gegenüber dem AOT-Compiler: Er ist nicht nur auf die statische Quellcode-Analyse angewiesen, sondern er kann das Programm direkt zur Laufzeit beobachten. Da sich die allermeisten Programme in Abhängigkeit von Eingaben und/oder Umgebungszuständen unterschiedlich verhalten, kann der JIT-Compiler zur Laufzeit wesentlich zielgenauer optimieren.
Ein großer Pluspunkt sind dabei die spekulativen Optimierungen. Dabei werden Annahmen getroffen, welche in den meisten Fällen zutreffen. Damit das Programm trotzdem korrekt funktioniert, wird die Annahme mit einem sogenannten „Guard“ abgesichert. Beispielsweise geht die JVM davon aus, dass in einem produktiv ausgeführten Programm die Polymorphie so gut wie nicht genutzt wird. Natürlich ist die Polymorphie grundsätzlich sinnvoll, aber die praktischen Einsatzszenarien beschränken sich meist auf den Testbereich oder auf die Entkopplung einer Codebasis – üblicherweise zur Nutzung durch verschiedene Programme oder für zukünftige Erweiterbarkeit. Während der Laufzeit eines konkreten produktiven Programmes – und dies ist der Scope der JVM – wird die Polymorphie jedoch selten genutzt. Das Problem ist dabei, dass es beim Aufruf einer Interface-Methode relativ zeitaufwendig ist, für das vorhandene Objekt die passende Methoden-Implementierung herauszusuchen. Aus diesem Grund werden die Methodenaufrufe getrackt. Wird beispielsweise mehrmals die Methode „java.util.List.add(…)“ auf einem Objekt vom Typ „java.util.ArrayList“ aufgerufen, merkt sich die JVM dies. Bei den folgenden Methodenaufrufen „List::add“ wird darauf spekuliert, dass es sich wieder um eine ArrayList handelt. Zunächst wird mit einem Guard die Annahme abgesichert: Es wird geprüft, dass das Objekt tatsächlich vom Typ ArrayList ist. Üblicherweise trifft dies zu und die bereits mehrfach ermittelte Methode wird mittels der „gemerkten” Referenz einfach direkt aufgerufen.
Seit der Integration des JIT-Compilers in das JDK sind nun mittlerweile mehr als zwei Jahrzehnte vergangen. In dieser Zeit wurden sehr viele Laufzeitoptimierungen integriert. Die vorgestellte Polymorphie-Spekulation ist nur ein kleines Beispiel, welches verdeutlichen soll: Neben der Kompilierung von Maschinencode wurden sehr viele Optimierungen erdacht, welche in einer komplexen Sprache wie Java nur zur Laufzeit funktionieren. Wenn eine Instanz beispielsweise mittels Reflection erzeugt wird, ist es für einen AOT-Compiler sehr schwer bis unmöglich, den konkreten Typ zu bestimmen und die spekulative Optimierung umzusetzen. Der Geschwindigkeitsvorteil der aktuellen JIT-Compiler beruht demnach im Wesentlichen darauf, dass sie dem Programm bei der Ausführung zuschauen, Gewohnheiten erkennen und schließlich Abkürzungen einbauen können.
GraalVM
Die GraalVM ist ein JDK von Oracle, welches auf dem OpenJDK basiert. Sie bringt eine virtuelle Maschine sowie viele Entwickler-Tools mit – was soweit auch für die anderen JDKs gilt. Warum also erregt die GraalVM wesentlich mehr Aufmerksamkeit als die anderen JDKs?
Zunächst bringt die GraalVM einen GraalVM-Compiler mit, welcher in Java entwickelt wurde. Darüber hinaus soll auch die gesamte JVM in Java umgeschrieben werden. Im letzten Kapitel wurde dargelegt, dass die aktuellen JVMs vor allem deswegen sehr performant sind, weil jahrzehntelang verschiedenste Optimierungen ergänzt wurden, welche sich nun summieren. Diese Optimierungen sind vor allem Java-spezifisch. Sie werden zumeist von Leuten entwickelt, welche einen Java-Background besitzen. Wenn nun die Ausführungsumgebung nicht in C++ sondern in Java umgesetzt ist, sind folglich keine C++-Kenntnisse mehr notwendig, um Optimierungen beizusteuern. Die Entwickler-Community wird so mittel- bis langfristig auf eine breitere Basis gestellt.
Ein weiterer spannender Aspekt der GraalVM ist, dass sie nicht nur Java-basierte Sprachen unterstützt. Das “Truffle Language Implementation Framework” ist ein Ansatzpunkt für die Entwicklung eigener Sprachen (DSL). Der GraalVM-Compiler unterstützt mit dem Truffle-Framework entwickelte Sprachen, so dass diese auch in der GraalVM ausgeführt werden können und von allen Vorteilen entsprechend profitieren. Einige Sprachen wie JavaScript, Python oder Ruby werden dabei bereits von Haus aus seitens der GraalVM unterstützt. Da alle Truffle-Sprachen gleichzeitig und gemeinsam in der GraalVM ausgeführt werden können, wird hier auch von einer polyglotten VM gesprochen.
Darüber hinaus werden auch LLVM-basierte Sprachen unterstützt. Bei LLVM handelt es sich um ein Rahmenprojekt für optimierende Compiler [4][5]. Dabei werden nicht nur Compiler-Bestandteile und -Technologien für externe Compiler-Entwicklungen bereitgestellt, sondern es werden auch im LLVM-Projekt bereits Compiler für viele Programmiersprachen wie bspw. C/C++ oder Fortran angeboten. Die LLVM Runtime ist ein weiterer Bestandteil der GraalVM, mit welchem LLVM-basierte Sprachen aufbauend auf dem Truffle-Framework in der GraalVM ausgeführt werden können. Auf den polyglotten Aspekt soll hier aber nicht weiter eingegangen werden, denn er hätte seinen eigenen Blogbeitrag verdient.
GraalVM Native Image
Die für diesen Beitrag relevanteste Neuerung ist die sogenannte „Native-Image-Technologie“. Das native-image ist ein Entwickler-Tool der GraalVM. Es erzeugt aus Bytecode eine ausführbare Datei. Die Ziele sind eine bessere Performance und weniger Hauptspeichernutzung zur Laufzeit. Nun wurde aber bisher beschrieben, dass Java immer schneller geworden ist: Der JIT-Compiler übersetzt alle häufig ausgeführten (d. h. relevanten) Programmteile in nativen Maschinencode. Das Programm wird während der Ausführung beobachtet und es werden fortlaufend Laufzeitoptimierungen vorgenommen. Damit stellt sich also die Frage: Was kann denn hier noch um Größenordnungen verbessert werden?
Die Antwort ist verblüffend einfach: Die Startzeit. Auch mit JIT-Compilern wird der Bytecode zunächst interpretiert. Erstens ist der Programmstart meistens kein häufig ausgeführter Programmteil. Zweitens müssen diese Programmteile üblicherweise erst ein paarmal durchlaufen werden, damit der JIT-Compiler diese als lohnendes Übersetzungsziel erkennt. Mit den Laufzeitoptimierungen verhält es sich analog: Das Programm muss erst einmal zur Laufzeit beobachtet werden, damit die passenden Optimierungen erkannt und eingebaut werden können. An dieser Stelle kommt verschärfend hinzu, dass beim Start alle benötigten Objekte sowie deren Klassen inklusive der kompletten Vererbungshierarchie initialisiert werden müssen.
Da wir nun eine Vorstellung vom „Was“ haben, interessiert uns das „Wie“: Wie kann unser Programm dazu bewegt werden, schneller zu starten?
Bei der Erstellung des Native Image wird der Bytecode zunächst sehr umfangreich statisch analysiert. Unter anderem wird dabei geprüft, welche Code-Teile zur Laufzeit überhaupt ausgeführt werden können. Dies bezieht sich nicht nur auf die vom Nutzer bereitgestellten Klassen, sondern auf den gesamten Klassenpfad – also inklusive der von der JVM bereitgestellten Java-Klassenbibliotheken. Nur die ermittelten Quellcode-Fragmente werden in das Native Image aufgenommen. Somit wird an dieser Stelle zwar der Umfang stark reduziert – aber es wird auch eine „Closed world assumption“ aufgestellt: Sobald irgendetwas dynamisch zur Laufzeit geladen wird, steht das Native Image Tool vor einem Problem. Es erkennt nicht, dass auch diese Quellcode-Teile ausgeführt werden können und damit benötigt werden. Aus diesem Grund wird auf diese Weise nicht viel mehr als ein einfaches HelloWorld-Programm funktionieren. Deshalb kann und muss man bei der Erstellung des Native Image dem Tool noch Informationen mitgeben, was alles dynamisch aufgerufen werden kann.
Nach der statischen Analyse wird nun der erste Punkt umgesetzt, welcher die Startgeschwindigkeit erhöht: Da der JIT-Compiler mit der Interpretation starten würde, wird ein AOT-Compiler genutzt, um Maschinencode zu erstellen. Das erzeugte Native Image ist, wie der Name schon impliziert, nativ ausführbarer Maschinencode. Damit geht allerdings die Plattformunabhängigkeit verloren.
Zusätzlich zum nativ kompilierten Programm wird die sogenannte SubstrateVM in das Native Image aufgenommen. Hierbei handelt es sich um eine abgespeckte VM, welche nur die zur Ausführung des Native Image notwendigen Komponenten wie beispielsweise Thread Scheduling oder Garbage Collection enthält. Die SubstrateVM hat dabei auch Limitierungen, beispielsweise ist die Unterstützung eines Security Managers gar nicht vorgesehen.
Eine zusätzliche Steigerung der Startgeschwindigkeit wird erreicht, indem das Native Image bei der Erstellung bereits vorab initialisiert wird. Das Programm wird dazu nach dem Kompilieren soweit gestartet, bis die wesentlichen Initialisierungen erfolgt sind, aber noch kein Input von außen verarbeitet werden muss. Von diesem gestarteten Zustand wird ein Speicherabbild erstellt und in das Native Image gelegt.
An das „Was“ und das „Wie“ schließt sich nun noch ein eher kritisches „Warum“ an: Der AOT-Compiler ist schon ein halbes Jahrhundert bekannt und Java existiert mittlerweile auch seit einem Vierteljahrhundert. Vor allem in der Anfangszeit von Java wurden verschiedene AOT-Ansätze ausprobiert – welche sich jedoch nicht durchsetzen konnten. Warum sollte es jetzt anders sein? Warum wird ausgerechnet jetzt eine geringere Startzeit interessant, wenn sie doch mit Nachteilen verbunden ist? Warum sind die performanten Antwortzeiten im darauffolgenden tage- oder wochenlangen Betrieb plötzlich weniger wichtig?
Die Antwort ist im Cloud Computing zu suchen: Hier werden die Services in einer anderen Form zur Verfügung gestellt. Bisher wurden die Services vorwiegend in einem Anwendungscontainer betrieben, welcher Tag und Nacht ausgeführt wird und in welchem das Programm schon seit Tagen komplett durchoptimiert? ist. Schließlich wurde der Anwendungscontainer üblicherweise auch bei spärlicher Nutzung (z. B. Tageszeiten-abhängig) nicht heruntergefahren. Im Gegensatz dazu kann in der Cloud die Service-Infrastruktur bei Nicht-Nutzung problemlos heruntergefahren werden – somit können Kapazitäten gespart werden. Beim nächsten Aufruf wird die Infrastruktur wieder hochgefahren und der Aufruf wird ausgeführt. Das bedeutet, dass die Programme in der Cloud nicht im Dauerbetrieb laufen, sondern dass es sich unter Umständen bei jedem Aufruf um einen Kaltstart handelt. Demzufolge ist die Startzeit hier „auf einmal“ sehr entscheidend. Und da zu erwarten ist, dass zukünftig noch mehr Java-Programme in der Cloud statt in einem Anwendungscontainer ausgeführt werden, wird sich die Fokussierung auf die Startzeit wohl noch verstärken.
Hands On: HelloWorld
Nach der ganzen Theorie möchten wir dem JDK nun bei der Arbeit zuschauen. Dazu kommt zunächst die in Listing 1 dargestellte Klasse „HelloWorld“ zum Einsatz.
package de.zeiss.zdi.graal;
public class HelloWorld {
public static void main(String[] args) {
System.out.println("Moin!");
}
}
Listing 1
Zunächst die klassische Variante: Wir befinden uns auf einer Linux-VM und es ist ein OpenJDK installiert:
> java --version
openjdk 11.0.11 2021-04-20
OpenJDK Runtime Environment (build 11.0.11+9-Ubuntu-0ubuntu2.20.04)
OpenJDK 64-Bit Server VM (build 11.0.11+9-Ubuntu-0ubuntu2.20.04, mixed mode, sharing)
java 11.0.12 2021-07-20 LTS
Java(TM) SE Runtime Environment GraalVM EE 21.2.0.1 (build 11.0.12+8-LTS-jvmci-21.2-b08)
Java HotSpot(TM) 64-Bit Server VM GraalVM EE 21.2.0.1 (build 11.0.12+8-LTS-jvmci-21.2-b08, mixed mode, sharing)
Mit diesem Setup kompilieren wir die HelloWorld-Klasse (javac) und führen den entstandenen Bytecode auf einer JVM aus:
time java -cp target/classes de.zeiss.zdi.graal.HelloWorld
Damit erhalten wir folgende Ausgabe:
Moin!
real 0m0.055s
user 0m0.059s
sys 0m0.010s
Für die Auswertung ist hier die Summe der beiden Zeilen „user“ und „sys“ relevant. Das ist die Rechenzeit, die für die Programmausführung notwendig war – in dem Fall also ca. 69ms.
Eine Anmerkung zu den 55ms: Das HelloWorld-Programm hat vom Start bis zu seiner Beendigung 55ms „Real-Zeit“ (die Zeit, welche der Nutzer wahrnimmt) benötigt. Das ist weniger als die 69ms benötigte Rechenzeit. Dies liegt daran, dass das eingesetzte Linux-System mehrere Prozessoren besitzt. Für unsere Messungen soll hier aber die vom System aufgewandte Rechenzeit betrachtet werden. Erstens ist die Rechenzeit unabhängiger davon, wie viele Prozessoren das Programm ausgeführt haben. Und zweitens ist dies in der Cloud beispielsweise auch die Zeit, welche der Anwendungsbetreiber bezahlen muss.
Nun sind wir auf die GraalVM gespannt. Auf deren Homepage [3] wird sie zum Download angeboten. Für unsere Evaluation ist die Enterprise-Variante („Free for evaluation and development“) passend, da ein Großteil der Performance-Optimierungen nur hier enthalten sind.
Die Installation ist für Linux sehr gut dokumentiert und funktioniert nahezu problemlos. Damit ist die GraalVM als JDK nutzbar.
> java --version
java version "11.0.12" 2021-07-20 LTS
Java(TM) SE Runtime Environment GraalVM EE 21.2.0.1 (build 11.0.12+8-LTS-jvmci-21.2-b08)
Java HotSpot(TM) 64-Bit Server VM GraalVM EE 21.2.0.1 (build 11.0.12+8-LTS-jvmci-21.2-b08, mixed mode, sharing)
Unser HelloWorld-Programm können wir nun genauso mit dem GraalJDK kompilieren (javac) und ausführen. Damit erhalten wir die folgende Ausgabe:
Moin!
real 0m0.084s
user 0m0.099s
sys 0m0.017s
Interessanterweise benötigt die JVM des GraalJDK nahezu 70 % mehr Rechenzeit, um unser HelloWorld-Beispiel als Bytecode auszuführen. Nun verspricht die GraalVM den signifikanten Performance-Vorteil allerdings auch nicht primär bei der Ausführung von Bytecode, sondern bei Nutzung der Native-Image-Technologie.
Das native-image (das Entwickler-Tool) ist in der heruntergeladenen GraalVM noch nicht enthalten, dafür existiert aber das Kommandozeilen-Tool „gu“ (GraalVM Updater). Mit diesem kann man zusätzliche Komponenten nachladen, verwalten und aktualisieren. Auch hier unterstützt die Dokumentation der GraalVM sehr gut. Mit dem nachgeladenen Entwickler-Tool können wir nun aus dem Bytecode das Native Image erzeugen. Im Fall eines so trivialen Programms wie unserem HelloWorld-Beispiel genügt dazu ein einfacher Kommandozeilenbefehl mit dem vollqualifizierten Klassennamen als Argument:
cd ~/dev/prj/graal-eval/target/classes
native-image de.zeiss.zdi.graal.HelloWorld
Die Erstellung des HelloWorld Native Image benötigt reichlich 3 Minuten Rechenzeit – und das ausführbare Programm ist ca. 12 MB groß. Auf den ersten Blick vergleicht man die Größe vermutlich mit dem Bytecode: Die HelloWorld.class ist lediglich 565 Byte groß. Allerdings enthält das Native Image nicht nur die kompilierte Klasse, sondern alle relevanten Teile der Java-Klassenbibliothek sowie die SubstrateVM. Verglichen mit der Größe einer JRE liegt das Native Image nur noch bei grob geschätzt 10 %.
Doch zurück zu unserem Native Image: Wir haben es erfolgreich erstellt, können es ausführen und erhalten dabei die folgende Ausgabe.
time ./de.zeiss.zdi.graal.helloworld
Moin!
real 0m0.004s
user 0m0.003s
sys 0m0.001s
Dieses Resultat können wir erst einmal als relevanten Geschwindigkeitsgewinn stehen lassen.
Hands On: HelloScript
Bei der GraalVM wird immer wieder herausgestellt, dass es sich dabei nicht nur um eine Java-VM sondern um eine polyglotte VM handelt. Aus diesem Grund erweitern wir unser HelloWorld-Programm noch um einen kleinen Exkurs in die JavaScript-Welt. Der Quellcode dazu ist in Listing 2 dargestellt. Der wesentliche Unterschied ist hier der notwendige Übergang von der Java- in die JavaScript-Welt.
package de.zeiss.zdi.graal;
import javax.script.ScriptEngine;
import javax.script.ScriptEngineManager;
import javax.script.ScriptException;
public class HelloScriptEngine {
public static void main(String[] args) throws ScriptException {
ScriptEngine jsEngine = new ScriptEngineManager().getEngineByName("javascript");
System.out.print("Hello ");
jsEngine.eval("print('JavaScript!')");
}
}
Listing 2
Neben dieser universellen JavaScript-Anbindung mittels der javax.script.ScriptEngine wollen wir auch die Graal-spezifische JavaScript-Anbindung ausprobieren. Dazu nutzen wir org.graalvm.polyglot.Context. Der Quelltext ist in Listing 3 dargestellt.
package de.zeiss.zdi.graal;
import org.graalvm.polyglot.Context;
public class HelloScriptPolyglot {
public static void main(String[] args) {
System.out.print("Hello ");
try (Context context = Context.create()) {
context.eval("js", "print('JavaScript!')");
}
}
}
Listing 3
Die beiden HelloScript-Programme werden analog dem HelloWorld-Programm in Bytecode übersetzt. Bei der Erstellung der Native Images muss das Entwickler-Tool noch informiert werden, dass die JavaScript-Welt genutzt werden wird. Dies geschieht mit dem folgenden Aufruf:
cd ~/dev/prj/graal-eval/target/classes
native-image --language:js de.zeiss.zdi.graal.HelloScriptEngine
native-image --language:js de.zeiss.zdi.graal.HelloScriptPolyglot
Anschließend kann der Bytecode auf den VMs oder die Native Images nativ ausgeführt werden. Da das HelloScriptPolyglot Graal-spezifisch ist, können wir es allerdings nicht ohne Weiteres auf dem OpenJDK ausführen.
Ein Blick auf die Messwerte
Die drei Szenarien wurden jeweils als Bytecode auf dem OpenJDK, als Bytecode auf dem GraalJDK und als Native Image ausgeführt. Die durchschnittlichen Programmausführungszeiten sind in Tabelle 1 aufgeführt.
Hello World
HelloScriptEngine
HelloScriptPolyglot
Bytecode OpenJDK
69 ms
1321 ms
X
Bytecode GraalJDK
116 ms
2889 ms
2775 ms
Native Image
4 ms
13 ms
11 ms
Tabelle 1: Beispiel für durchschnittliche Programmausführungszeiten
Auf den ersten Blick fällt ins Auge, das die Ausführung als Native Image in allen drei Szenarien jeweils um ein Vielfaches schneller ist als die übliche Bytecode-Ausführung.
Auf den zweiten Blick fällt aber auch auf, dass die Bytecode-Ausführung mit dem GraalJDK wesentlich mehr Rechenzeit benötigt als mit dem OpenJDK: Im HelloWorld-Beispiel knapp 70 % mehr, bei dem HelloScriptEngine-Beispiel über 100 % mehr. Das wurde von Oracle so nicht kommuniziert, ist aber grundsätzlich auch kein allzu großes Problem, da die Motivation für den Einsatz der GraalVM vermutlich nicht in der schnelleren Bytecode-Ausführung liegt. Man sollte diesen Fakt aber im Hinterkopf behalten, wenn man den relevanten Speed-Up durch das Native Image ermitteln möchte: Zur Erstellung des Native Image muss schließlich die GraalVM installiert sein. Wenn man nun zum Vergleich die Bytecode-Ausführung misst und „java -jar …“ ausführt, wird der Bytecode mittels der GraalVM ausgeführt. Da im produktiven Betrieb aber bisher vermutlich eher das OpenJDK eingesetzt wurde, sollte man eher mit diesem vergleichen – und damit wäre der Speed-Up „nur“ noch reichlich halb so hoch.
Was zu bedenken ist
Um die versprochenen Performance-Gewinne zu erzielen, reicht es nicht, die GraalVM anstatt eines herkömmlichen JDKs zu installieren. Bei der Bytecode-Ausführung konnte – zumindest mit unseren Beispielen und unserem Setup – noch kein Performance-Gewinn erreicht werden. Dies ist erst mit einem Native Image möglich, welches gegenüber der Bytecode-Ausführung jedoch auch mehrere Nachteile hat, derer man sich bewusst sein sollte.
Im Native Image wird die SubstrateVM als JVM verwendet. Diese besitzt einige Einschränkungen. Abgesehen davon, dass derzeit noch nicht alle Features umgesetzt sind, stehen einige Dinge wie z. B. ein Security Manager gar nicht auf der Agenda.
Weiterhin sollte die Dauer des Build-Prozesses beachtet werden: Beim Native Image verschwindet die Startzeit nicht einfach. Die Rechenzeit wird mit verschiedenen Ansätzen „lediglich“ verlagert: Von der Ausführungszeit zur Build-Zeit. Die Erstellung unseres HelloWorld-Beispiels hat in unserer Umgebung reichlich drei Minuten benötigt – die Erstellung des HelloScript-Programmes dauerte bereits mehr als 20 Minuten (HelloScriptEngine: 1291s, HelloScriptPolyglot: 1251s).
Die größte Herausforderung ist aber die „Closed world assumption“. Bei der Erstellung des Native Image wird eine statische Codeanalyse durchgeführt – und nur die durchlaufenen Code-Teile werden in das Native Image kompiliert. Das funktioniert zwar für unser HelloWorld-Programm, aber bereits bei den JavaScript-Beispielen mussten Kommandozeilen-Parameter angegeben werden. Mittels „Reflection“ geladene Klassen werden nur erkannt, wenn der vollqualifizierte Klassenname festverdrahtet im Quellcode steht. Demzufolge gibt es Probleme mit allen Technologien, welche Dynamic Class Loading in irgendeiner Form nutzen: JNDI, JMX, …
Die dynamisch geladenen Programmteile können (und müssen) bei der Erstellung des Native Image explizit angegeben werden. Das schließt alle Programmteile ein: Neben dem eigenen Projekt-Code sind das auch alle eingesetzten Bibliotheken – bis hin zu denen der JRE. Da diese Konfiguration für „echte“ Programme eine wirkliche Herausforderung ist, werden hierzu Hilfswerkzeuge bereitgestellt, ohne die es in der Praxis vermutlich nicht funktioniert. Der Tracing Agent beispielsweise beobachtet ein als Bytecode ausgeführtes Programm. Er erkennt alle reflektiven Zugriffe und erzeugt daraus eine JSON-Konfiguration. Diese kann nun für die Erstellung des Native Image verwendet werden.
In der Praxis würde die Build-Pipeline also zunächst die Bytecode-Variante erstellen. Nun können alle automatisierten Tests mit dieser Bytecode-Variante ausgeführt werden, wobei der Tracing Agent die reflektiven Zugriffe erkennt. Unter der Annahme, dass dabei wirklich jeder Programmpfad ausgeführt wurde, kann nun das Native Image in einem weiteren Build-Schritt erzeugt werden. Dies führt direkt zum nächsten Punkt: Bei der Arbeit mit der Native-Image-Technologie wird der Build-Prozess insgesamt länger und komplexer.
Zusammenfassend bedeutet dies, dass beim Einsatz der Native-Image-Technologie einige Dinge kaum oder nicht möglich sind (bspw. Security Manager). Viele andere Dinge funktionieren zwar grundsätzlich, müssen aber umständlich konfiguriert werden. Hierfür ist eine Tool-Unterstützung gegeben und wird auch recht dynamisch weiterentwickelt. Die Hoffnung ist hier, dass die Mehraufwände (abgesehen von der Build-Dauer) durch die Werkzeuge kompensiert werden können. Allerdings wird dadurch der Build-Prozess auch komplexer und somit fehleranfälliger.
Fallstricke unter Windows
Abschließend noch ein Blick zur Windows-Plattform: Diese wird mittlerweile auch unterstützt. Vorbereitend für diesen Blogbeitrag wurden die Versionen „GraalVM Enterprise 20.3.0″ sowie „GraalVM Enterprise 21.0.0.2“ auf einem Windows-System betrachtet. Leider war hier die Dokumentation noch etwas lückenhaft und das Tooling greift noch nicht so gut ineinander wie in der Linux-Umgebung. Dadurch gab es auch Hindernisse, die unter Linux nicht aufgefallen sind. So trat beispielsweise ein Problem bei der Erstellung eines Native Images auf, wenn der zugrundeliegende Bytecode von einem anderen JDK (in dem Fall durch das OpenJDK) erzeugt wurde. Dabei ist die auftretende Fehlermeldung leider auch nicht so aussagekräftig, dass sie auf die eigentliche Ursache hinweist:
native-image de.zeiss.zdi.graal.HelloWorld
[de.zeiss.zdi.graal.helloworld:20764] classlist: 947.02 ms, 0.96 GB
[de.zeiss.zdi.graal.helloworld:20764] (cap): 3,629.54 ms, 0.96 GB
[de.zeiss.zdi.graal.helloworld:20764] setup: 5,005.98 ms, 0.96 GB
Error: Error compiling query code (in C:\Users\xyz\AppData\Local\Temp\SVM-13344835136940746442\JNIHeaderDirectives.c). Compiler command ''C:\Program Files (x86)\Microsoft Visual Studio\2019\BuildTools\VC\Tools\MSVC\14.28.29333\bin\HostX64\x64\cl.exe' /WX /W4 /wd4244 /wd4245 /wd4800 /wd4804 /wd4214 '-IC:\Program Files\Java\graalvm-ee-java11-21.0.0.2\include\win32' '/FeC:\Users\xyz\AppData\Local\Temp\SVM-13344835136940746442\JNIHeaderDirectives.exe' 'C:\Users\xyz\AppData\Local\Temp\SVM-13344835136940746442\JNIHeaderDirectives.c' ' output included error: [JNIHeaderDirectives.c, Microsoft (R) Incremental Linker Version 14.28.29337.0, Copyright (C) Microsoft Corporation. All rights reserved., , /out:C:\Users\xyz\AppData\Local\Temp\SVM-13344835136940746442\JNIHeaderDirectives.exe , JNIHeaderDirectives.obj , LINK : fatal error LNK1104: Datei "C:\Users\xyz\AppData\Local\Temp\SVM-13344835136940746442\JNIHeaderDirectives.exe" kann nicht ge?ffnet werden.]
Error: Use -H:+ReportExceptionStackTraces to print stacktrace of underlying exception
Error: Image build request failed with exit status 1
Ein weiterer Fallstrick bestand in der laufwerksübergreifenden Arbeit: Es ist unter Windows leider nicht möglich, die GraalVM auf einem Laufwerk zu installieren (in dem Fall unter C:\Programme) und auf einem anderen Laufwerk auszuführen (in dem Fall unter D:\dev\prj\…):
native-image de.zeiss.zdi.graal.HelloWorld
[de.zeiss.zdi.graal.helloworld:10660] classlist: 3,074.80 ms, 0.96 GB
[de.zeiss.zdi.graal.helloworld:10660] setup: 314.93 ms, 0.96 GB
Fatal error:java.lang.IllegalArgumentException: java.lang.IllegalArgumentException: 'other' has different root
at java.base/jdk.internal.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method)
[…]
Darüber hinaus konnten mit dem Native Image in der Windows-Umgebung leider keine Performance-Vorteile festgestellt werden. Derzeit ist die Windows-Unterstützung (sowohl die GraalVM-Toolchain selbst als auch die generierten Native Images) somit noch eher experimentell.
Fazit
Im Blogbeitrag wurde vor allem darauf eingegangen, dass die Startzeit der Java-Programme mit GraalVMs Native-Image-Technologie enorm verbessert werden kann. Es wurde dargestellt, welchen Ansätzen und welcher Techniken sich die GraalVM dabei bedient. Das Resultat wurde mit Messungen an Beispiel-Programmen untermauert. Auf der anderen Seite wurden aber auch einige Herausforderungen genannt, welche beim Einsatz der Native-Image-Technologie auftreten.
Mit länger laufenden Programmen sind vermutlich kaum Performance-Steigerungen zu erwarten, weil dann auch die Optimierungen der herkömmlichen JVMs greifen. Das ist erst einmal nur eine Behauptung. Eine Untersuchung dieses Aspekts würde den aktuellen Rahmen sprengen und hat genug Potenzial für einen eigenen Blogbeitrag.
Nun wollen wir uns noch kurz den Fragen aus der Einleitung zuwenden: Grundsätzlich ist das „herkömmliche“ Java schon lange nicht mehr langsam, sondern rasend schnell. Schon allein der Einsatz im (rechenintensiven) Big-Data-Umfeld ist ein Indiz hierfür. Die hauptsächliche Vorbedingung für diese hohe Performance ist eine gewisse Warmlaufzeit. Im Umkehrschluss heißt das: Der Start eines herkömmlichen Java-Programms lässt zu wünschen übrig – und genau dies ist der Hauptansatzpunkt der Native-Image-Technologie. Auf der anderen Seite bringt diese Technologie auch eine Menge Nachteile mit – vor allem für große, technik-reiche Anwendungen.
Zusammenfassend lässt sich sagen, dass die GraalVM das Potenzial hat, sich in verschiedenen Einsatzgebieten zu etablieren. Die polyglotten Eigenschaften können sich mehrsprachige Anwendungen zunutze machen und der Einsatz der betrachteten Native-Image-Technologie ist vor allem für Cloud Services durchaus denkbar. Allerdings wird sich der Einsatz der GraalVM vor allem für rechenintensive (d. h. meist auch länger laufende) nicht-triviale Anwendungen vermutlich nicht lohnen.
Abschließend soll noch als Vorteil für die GraalVM festgehalten werden, dass Compiler und Optimizer in Java implementiert sind. Das ist zwar zunächst grundsätzlich nicht besser oder schlechter als die bisherigen Implementierungen – wird aber mittel- bis langfristig die Chancen erhöhen, das Potential der Java-Community besser zu nutzen.
Alles in allem bleibt es wohl spannend: Eine grundsätzliche Ablösung des OpenJDK ist derzeit nicht absehbar. Und man darf schließlich auch nicht vergessen, dass die Entwicklung dort genauso wenig stillsteht. Allerdings hat die GraalVM durchaus das Potenzial, um sich (zunächst erst einmal?) in bestimmten Anwendungsgebieten zu etablieren.
Dieser Blogbeitrag befasst sich mit den hohen Ansprüchen an Security und Compliance, die wir an jedes Softwareprojekt stellen. Dafür verantwortlich ist in jedem Projekt ein ausgebildeter Security Engineer. Dabei stellen ihn insbesondere die unzähligen Dependencies in Softwareprojekten, welche in ihrer Vielzahl von Versionen unter Kontrolle gebracht werden müssen, vor große Herausforderungen.
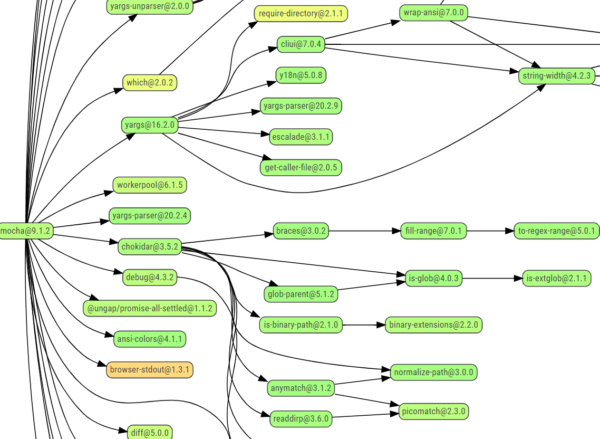
Abbildung 1: Ein Ausschnitt aus dem Abhängigkeits-Graph eines npm Paketes, aus npmgraph.js.org/?q=mocha
Herausforderungen in Softwareprojekten
Große Softwareprojekte bestehen schon seit langer Zeit aus kleineren Teilen, die für ihr jeweiliges Gebiet wiederverwendet werden können. Komponenten, bei denen es nicht um geheime Funktionalität geht, werden zunehmend als „FOSS (Free and Open Source Software)“ veröffentlicht. Das bedeutet „quelloffen“ (Open Source) und mit einer freien Lizenz zur Weiterverwendung.
Dabei ist es für die Einschätzung und Prävention von Sicherheitslücken äußerst wichtig, eine vollständige Übersicht über alle eingebundenen Drittbibliotheken zu haben. Denn jedes unserer importierten Module kann ebenfalls mit mehreren Abhängigkeiten verbunden sein. Schnell steigt dann die Anzahl an zu beobachtenden Abhängigkeiten in die Tausende und es ist nicht einfach, zwischen allen Versionen den Überblick über Lizenzen und Sicherheitslücken zu behalten.
Die Auswirkung der Problematik wird z. B. klar, wenn man Fälle von „Supply chain attacks“ und „Dependency Hijacking“ der letzten Jahre liest. Eine interessante Meta-Analyse ist „What Constitutes a Software Supply Chain Attack? “ von Ax Sharma (https://blog.sonatype.com/what-constitutes-a-software-supply-chain-attack). Den Umgang mit diesen Komponenten in großen wie kleinen Softwareprojekten aus Sicht eines Security Engineers möchten wir weiter erläutern.
Lösungsmöglichkeiten mittels FOSS Scanner
Über die Zeit haben sich einige Projekte dem Problem der Kenntlichmachung von FOSS-Komponenten gewidmet. Es gibt Programme zum Erstellen von Bill of Material (BOM) und Übersichten zu Sicherheitsrisiken, welche wir verprobt haben.
Weiter gibt es große Kataloge wie den „Node Paketmanager“ (npm), die selbst ausführliche Informationen zu den jeweils angebotenen Komponenten geben.
Auch wenn es diese freien und quelloffenen Komponenten gratis gibt, so sind sie nicht ohne Aufwand, besonders in langlebigen und wichtigen Softwareprojekten.
Wir haben für die Evaluierung den OWASP-Dependency Check (DC) und das OSS Review Toolkit als kombinierte Lösung für das Auffinden von Sicherheitsproblemen mit DC und Überprüfung der Einhaltung der Lizenzbestimmungen eingesetzt. Im Vergleich zu kommerziellen Lösungen wie BlackDuck bieten diese frei und kostenlos die Möglichkeit einer Übersicht über die FOSS-Komponenten in Projekten und die Bewertung von Risiken.
Das war aber unserer Erfahrung nach mit Mehraufwand sowohl in der Konfiguration als auch bei der kontinuierlichen Überprüfung, d. h. neuen Scans auf neue Sicherheitsprobleme, verbunden.
Verantwortung als Software Engineer
Unsere Richtlinien für sichere Entwicklung und den Einsatz von Open Source geben die notwendigen Prozesse und Ziele vor, an dem sich unsere Security Engineers in Vertretung der Projekte orientieren. Der vielleicht wichtigste Ausschnitt daraus wird im folgenden Abschnitt aufgeführt:
It is our responsibility that the following so called Essential FOSS Requirements are fulfilled:
All included FOSS components have been identified and the fitness for purpose has been confirmed.
All licenses of the included FOSS have been identified, reviewed and compatibility to the final product/service offering has been verified. Any FOSS without a (valid) license has been removed.
All license obligations have been fulfilled.
All FOSS are continuously – before and after release – monitored for security vulnerabilities. Any relevant vulnerability is mitigated during the whole lifecycle.
The FOSS Disclosure Statement is available to the user.
The Bill of Material is available internally.
For that it must be ensured that
the relevant FOSS roles are determined and nominated.
the executing development and procurement staff is properly trained and staffed.
Anhand dieser Richtlinien werden verpflichtende Trainings, Wissensträger und Qualitätskontrollen gebildet.
Vorstellung der Abläufe
Untersuchen vor Einbindung (Lizenzen, Operational Risk wie Update-Häufigkeit)
Überwachen von Updates (Operational Risks)
Irgendwann soll eine neue Funktion zu einem Softwareprojekt hinzugefügt werden. Oft kennen Entwickler bereits mögliche FOSS Software, die bei der Funktionalität hilft.
Ein wichtiger Aspekt ist, dass möglichst jeder Entwickler den Umgang mit Paketmanagern und mögliche Implikationen kennt, um Ergebnisse aus den Tools oder Analysen richtig einordnen zu können. Es ist z. B. sehr wichtig, sich zu veranschaulichen, aus wie vielen Teilen eine Top-Level-Abhängigkeit besteht – oder verschiedene Abhängigkeiten gleicher Funktionalität im Hinblick auf zukünftige sichere Entwicklung (Operationelle Risiken) zu bewerten. Immer öfter sehen wir das Ziel, die Zahl an Abhängigkeiten klein zu halten. Das sollte bei der Auswahl von Komponenten berücksichtigt werden, um möglichst nur das wirklich notwendige an Funktionalität von zusätzlichen Abhängigkeiten zu erhalten.
Bereits vor dem Einbinden sind durch den Security Engineer potenzielle Imports auf ihre kompatible Lizenz und bestehende Sicherheitslücken zu überprüfen. Ebenso wichtig ist aber auch der Blick auf das, was unter operationale Risiken fällt wie z. B.:
Aktualität
Lebendige Community oder aktive Instandhaltung
Update-Zyklus ausreichend agil, um auftretende Sicherheitslücken zu beseitigen
Wird Wert auf den sicheren Umgang mit Abhängigkeiten gelegt?
Ist die Anzahl an weiteren Abhängigkeiten sinnvoll und wird wenn möglich reduziert?
Im laufenden Entwicklungsprozess und später im Betrieb muss das Projektteam auch informiert werden, wenn neue Sicherheitslücken entdeckt oder geschlossen werden. Dafür können periodische Scans oder eine Datenbank mit Alerts für Sicherheitslücken eingesetzt werden. Für periodische Scans spricht die größere Unabhängigkeitvon der einen Datenbank – dafür müssen Hardware und Alerts selbst bereitgestellt werden. Diese wiederum sind einer der Mehrwerte einer Software-Composition-Analysis-Lösung wie BlackDuck.
Da der Anteil an gut gekennzeichneter FOSS steigt, wird bei neuen Versionen der Zeitaufwand für manuelle Kuration vergleichsweise geringer. Dazu zählen das Deklarieren einer Lizenz – und leicht auffindbare und formatierte Copyright-Angaben in den Komponenten, was in älteren Komponenten oft sehr individuell formatiert oder ganz weggelassen wurde. Ist keine Lizenz angegeben, so darf dies nicht fälschlicherweise als „Freibrief“ verstanden werden. Ohne eine Lizenz darf eine Komponente nicht ohne Einverständnis der Autoren benutzt werden!
Beispiel einer Sicherheitslücke
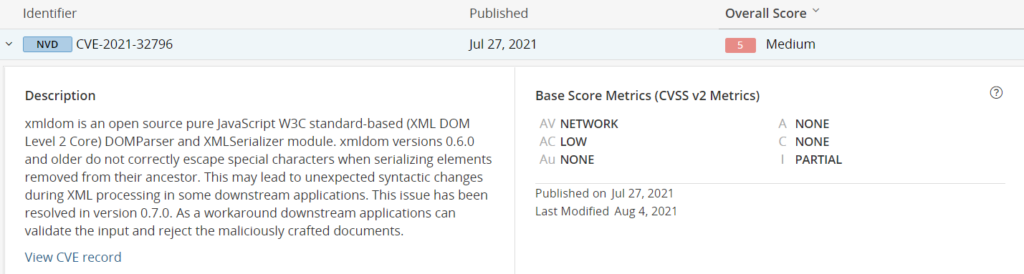
Ein Beispiel für eine komplizierte Sicherheitslücke ist unter dem CVE-2021-32796 veröffentlicht worden. Eingebunden wird das problematische Modul xmldom indirekt über zwei weitere Abhängigkeiten in unserem Beispielprojekt.
BlackDuck zeigt uns zu dem Modul folgende Sicherheitswarnung:
Abbildung 2: BlackDuck: Beispiel Zusammenfassung einer Schwachstelle
Damit kann der Security Engineer bereits eine grobe Einschätzung zur Tragweite der Sicherheitslücke vornehmen. Auch ist ein Hinweis auf dem Patch in Version 0.7.0 angegeben.
Wichtigkeit von Vorlauf für Updates/Austausch von Kompetenzen
Wir haben in der Zeit bis zu der „frischen Veröffentlichung“ unter @xmldom/xmldom bereits überprüfen können, welchen Aufwand es bedeuten würde, ohne diese Abhängigkeit auszukommen.
Um diese Zeit zu haben, ist es sehr nützlich, bereits im Entwicklungsprozess – und mit genügend Vorlauf zu einer Produktveröffentlichung – eine Übersicht über mögliche Probleme zu bekommen.
Das erleichtert den Entwicklern das Evaluieren von Ausweichlösungen für problematische Software-Bibliotheken, sei es wegen Sicherheitslücken, inkompatiblen Lizenzen oder anderer operativer Risiken.
Fazit
Dieser Beitrag hat einen Überblick über unsere Arbeit mit der großen Vielfalt an Open Source in unseren Projekten und die Aufgaben als Security Engineer im Umgang mit Open Source gegeben. Damit bringen wir mittels moderner Werkzeuge die Vielfalt an Abhängigkeiten unter Kontrolle und schaffen die notwendige Transparenz und Sicherheit. Bereits vor Einbinden von Abhängigkeiten sollte eine Evaluierung dieser von einem geschulten Team durchgeführt werden, und danach während des ganzen Software-Lebenszyklus überwacht und auf Probleme reagiert werden.
Softwaresysteme werden durch die stetig wachsende Anzahl von Anwendungen auf unterschiedlichen Plattformen immer komplexer. Ein entscheidender Faktor für den Erfolg eines Softwareprodukts ist dessen Qualität. Daher führen immer mehr Unternehmen systematische Prüfungen und Tests möglichst auf den verschiedenen Plattformen durch, um einen vorgegebenen Qualitätsstandard sicherstellen zu können. Um trotz des höheren Testaufwands kurze Release-Zyklen einhalten zu können, wird es notwendig, die Tests zu automatisieren. Dies wiederum führt dazu, dass eine Testautomatisierungsstrategie definiert werden muss. Einer der ersten Schritte bei der Einführung einer Testautomatisierungsstrategie ist die Evaluierung von geeigneten Testautomatisierungswerkzeugen. Da jedes Projekt einzigartig ist, variieren sowohl die Anforderungen als auch die Wahl der Werkzeuge. Diese Blogreihe soll eine Hilfestellung bei der Auswahl der passenden Lösung geben.
Abbildung 1: Zur Einführung einer Testautomatisierungsstrategie gehört auch die Evaluierung geeigneter Testautomatisierungswerkzeuge
Einführung
Im Rahmen meiner Abschlussarbeit übernahm ich die Aufgabe, den Scrum-Teams der ZEISS Digital Innovation (ZDI) ein Hilfsmittel an die Hand zu geben, mit dem sie das passende Testautomatisierungswerkzeug schnell und flexibel finden können. Die Herausforderung bestand dabei darin, dass die Projekte spezifische Szenarien besitzen und die Anforderungen gegebenenfalls gesondert gewichtet werden müssen. Den Stand der Arbeit und die Ergebnisse möchte ich euch in diesem und den nächsten Blogartikeln vorstellen.
Die Softwareentwicklung ist schon seit langem ein Bereich, der sich schnell verändert. Doch während diese Entwicklungen in der Vergangenheit vor allem auf technologischer Ebene stattgefunden haben, beobachten wir derzeit größere Veränderungen im Bereich der Prozesse, der Organisation und der Werkzeuge in der Softwareentwicklung. Diese neuen Trends sind jedoch mit Herausforderungen verbunden wie z. B. Änderungen im Anforderungsmanagement, verkürzten Timelines und speziell den gestiegenen Anforderungen an die Qualität. Durch die Entwicklung bedarfsgerechter Lösungen und die Optimierung der Qualität werden heute sowohl die Effizienz als auch die Effektivität innerhalb der Softwareentwicklung gesteigert.
Zudem werden Softwaresysteme durch die stetig wachsende Anzahl von Anwendungen auf unterschiedlichen Plattformen immer komplexer. Da die Qualität ein entscheidender Faktor für den Erfolg eines Softwareprodukts ist, führen immer mehr Unternehmen systematische Prüfungen und Tests möglichst auf den verschiedenen Plattformen durch, um einen vorgegebenen Qualitätsstandard sicherzustellen. Eine Anfang 2021 durchgeführte SmartBear-Umfrage ergab, dass viele Unternehmen, unabhängig von der Branche, bereits verschiedene Arten von Tests durchführen, wobei das Testen von Webanwendungen mit 69 % an erster Stelle und das Testen von API/Webdiensten mit 61 % an zweiter Stelle steht. Das Desktop-Testing wird von 42 % der Befragten durchgeführt. Insgesamt 62 % der Befragten geben an, dass sie mobile Tests durchführen, davon 29 % für native Applikationen (Apps) (SmartBear, 2021, S. 12). Um trotz des höheren Testaufwands kurze Release-Zyklen einhalten zu können, wird es notwendig, die Tests zu automatisieren.
Als ZDI unterstützen wir unsere Kunden innerhalb und außerhalb der ZEISS Gruppe bei ihren Digitalisierungsprojekten. Zusätzlich bieten wir individuelle Testservices an. Darum gibt es bei uns eine Vielzahl von Projekten mit unterschiedlichen Technologien und unterschiedlichen Lösungen. Als kleine Auswahl sind hier Schlagwörter wie Java, .Net, JavaFX, WPF, Qt, Cloud, Angular, Embedded etc. zu nennen. Bei solchen komplexen Projekten steht die Qualitätssicherung immer im Vordergrund und die Projekte sind abhängig vom Einsatz moderner Testwerkzeuge, welche die Projektbeteiligten bei den manuellen, aber besonders bei den automatisierten Tests unterstützen. Dabei wäre ein Werkzeug wünschenswert, das diese Automatisierung effektiv und effizient unterstützt. Testerinnen und Tester stehen jedoch bei der Auswahl eines Testautomatisierungswerkzeugs vor einer Vielzahl von Herausforderungen.
Herausforderungen
Bei der Recherche und den Interviews im Rahmen meiner Arbeit wurden als größte Herausforderungen bei der Testautomatisierung die Vielfalt der verfügbaren Testwerkzeuge und die fortschreitende Fragmentierung des Marktes genannt. Aufgrund dieser Fragmentierung stehen für den gleichen Einsatzzweck eine Vielzahl von Werkzeugen bereit.
Die Auswahl wird noch schwieriger, da sich die Werkzeuge nicht nur in der Technologie unterscheiden, die sie testen können, sondern auch im Arbeitsansatz. Wenn von Automatisierung die Rede ist, wird sie immer mit Skripting in Verbindung gebracht. In den letzten Jahren wurde jedoch ein neuer Ansatz für GUI-Tests entwickelt, der als NoCode/LowCode bezeichnet wird. Dieser Ansatz erfordert grundsätzlich keine Programmierkenntnisse und ist daher auch bei Automatisierungseinsteigern beliebt. Trotzdem bleibt das Skripting die dominierende Methode, obwohl manchmal beide Ansätze verwendet werden, um möglichst viele aus dem Qualitätssicherungsteam einzubeziehen (SmartBear, 2021, S. 33).
Die Art und Weise des Testautomatisierungsansatzes und damit der Einsatz eines Testautomatisierungswerkzeugs sind abhängig von den Anforderungen im Projekt. Dies bedeutet, dass die Anforderungen bei jedem neuen Projekt immer wieder neu geprüft werden müssen.
Bestandsaufnahme
Im Rahmen der Interviews, der Analyse des aktuellen Vorgehens und der Auswertung einer internen Umfrage konnte ich folgende Vorgehensweisen für die Auswahl der Werkzeuge in den Projekten identifizieren, die sich als „Quasi-Standard“ etabliert haben:
Das Werkzeug ist Open Source und kostet nichts.
Es wurde mit dem Werkzeug schon einmal gearbeitet und es wurde als vertrauenswürdig eingestuft.
Ein Ziel der Umfrage war es, herauszufinden inwieweit die Projektsituation einen Einfluss auf die Toolauswahl hat. Darum wurden im nächsten Schritt die Projekt-Situationen bzw. die verwendeten Vorgehensmodelle der Projekte und deren Einfluss untersucht. Es zeigte sich, dass nicht die Vorgehensmodelle einen direkten Einfluss auf die Toolauswahl haben, sondern die Personen oder Gruppen, die als zukünftige Anwender das Werkzeug nutzen oder die den Einsatz freigeben.
Bei der Überprüfung des Einflusses dieser operativ-eingebundenen Beteiligten zeigte sich, dass es noch weitere Interessengruppen gibt, die direkt oder indirekt einen Einfluss auf die Auswahl eines Werkzeuges haben. Dies sind z. B.:
Softwarearchitektinnen und Softwarearchitekten, die die Technologie oder Tool-Ketten innerhalb des Projektes definieren,
das Management, das Vorgaben festlegt für den Einkauf oder die Verwendung der Werkzeuge (OpenSource, GreenIT, strategische Partnerschaften etc.) oder
die IT des Unternehmens, die durch die verwendete Infrastruktur den Einsatz bestimmter Werkzeuge verhindert (FireWall, Cloud etc.).
Darüber hinaus fanden sich bei den Recherchen bereits erste Ansätze von Checklisten für die Auswahl von Testwerkzeugen. Sie basierten meist auf wenigen funktionalen Kriterien und wurden in Workshops durch die Projektmitglieder bestimmt. Die Auswertung zeigte, dass es keine einheitliche Methode gibt und dass die so ausgewählten Tools sehr oft später durch andere Werkzeuge ersetzt wurden. Dies wurde notwendig, da bei der Auswahl notwendige Anforderungen an das Werkzeug übersehen wurden.
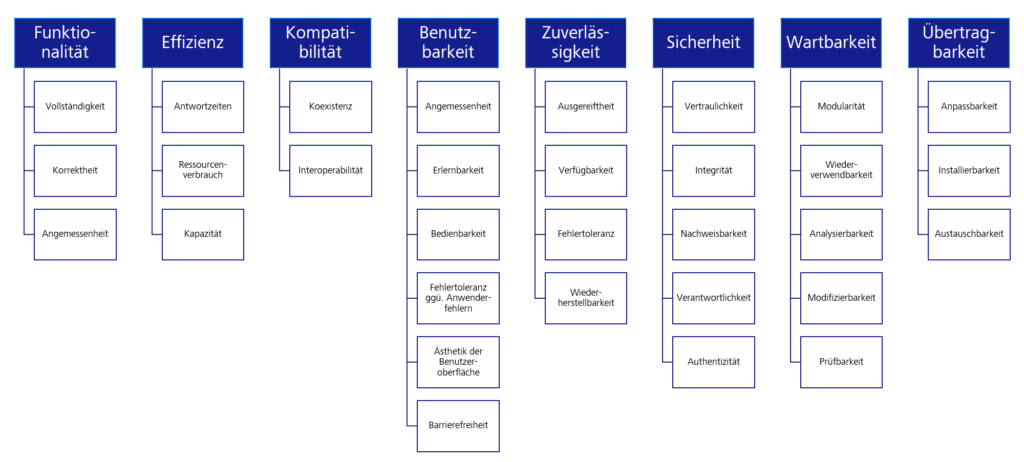
In der Mehrzahl der Fälle waren die vergessenen Anforderungen nicht-funktionaler Natur, wie z. B. Kriterien der Usability oder Anforderungen an die Performance. Darum war ein nächster Schritt bei der Prüfung relevanter Kriterien, die ISO/IEC 25000 Software Engineering (Qualitätskriterien und Bewertung von Softwareprodukten) heranzuziehen.
Nicht immer, aber sehr oft, waren die übersehenen Anforderungen nicht-funktionaler Natur. Darum war ein nächster Schritt bei der Prüfung relevanter Kriterien, die ISO/IEC 25000 Software Engineering (Qualitätskriterien und Bewertung von Softwareprodukten) heranzuziehen.
Abbildung 2: Kriterien für Software nach ISO/IEC 25010
Im nächsten Blogartikel dieser Reihe wird aufgezeigt, wie der Kriterienkatalog aufgebaut ist und wie sich die finale Liste der Kriterien zusammensetzt.
Literatur
SmartBear (2021): State of Software Quality | Testing.
Dieser Beitrag wurde fachlich unterstützt von:
Kay Grebenstein
Kay Grebenstein arbeitet als Tester und agiler QA-Coach für die ZEISS Digital Innovation, Dresden. Er hat in den letzten Jahren in Projekten unterschiedlicher fachlicher Domänen (Telekommunikation, Industrie, Versandhandel, Energie, …) Qualität gesichert und Software getestet. Seine Erfahrungen teilt er auf Konferenzen, Meetups und in Veröffentlichungen unterschiedlicher Art.
Im Bereich der Application Security gibt es verschiedene Konzepte, um das Ziel zu erreichen, zuverlässige und sichere Software zu entwickeln. In diesem Beitrag werden das Static Application Security Testing (SAST) und die Software Composition Analysis (SCA) als wichtige Bestandteile der Application Security vorgestellt. Zur Umsetzung dieser Konzepte und Erhöhung der Application Security können entsprechende Tools eingesetzt werden.
SAST Tools
Static Application Security Testing dient dazu, den Code einer Software auf Schwachstellen und Sicherheitslücken zu untersuchen.
Funktionsweise der SAST Tools
Als ein Teil der statischen Codeanalyse fokussiert SAST die Einhaltung von Secure Coding Richtlinien und generellen Programmierstandards. Beispielsweise können Entwicklerinnen und Entwickler dabei unterstützt werden, Schwachstellen, die in der Top 10 des Open Web Application Security Project (OWASP) oder der Top 25 der Common Weakness Enumeration (CWE) aufgelistet sind, zu vermeiden.
SAST Tools sind Teil des White-Box Testings, denn sie benötigen Zugriff auf den Quellcode einer Applikation. Idealerweise wird SAST an zwei Stellen in der Softwareentwicklung eingesetzt. Zunächst in der Entwicklungsumgebung (IDE) der Softwareentwicklerinnen und Softwareentwickler, um möglichst zeitnah potenzielle Sicherheitslücken während des Schreibens von Programmcode aufzuspüren. Außerdem ist es sinnvoll, das eingesetzte SAST-Tool in den Prozess zur Continuous Integration/Continuous Delivery (CI/CD) zu integrieren. Auf diese Weise kann eine statische Sicherheitsanalyse des gesamten Quellcodes erfolgen. Zusätzlich kann sichergestellt werden, dass nur ein durch das SAST-Tool geprüfter Code die weiteren Stufen des Entwicklungsprozesses wie Test und Deployment erreicht. Je früher im Softwareentwicklungsprozess eine Schwachstelle oder Sicherheitslücke gefunden wird, desto kostengünstiger ist es, sie zu beheben.
Einige SAST Tools stellen weitere Funktionalitäten bereit, wie die Ausführung von Unit- und Integrationstests. Der Vollständigkeit halber muss erwähnt werden, dass SAST nur ein einzelner Baustein zu einer sicheren Applikation ist und durch weitere Überprüfungs- und Testmethoden wie Code Reviews, Dynamic Application Security Testing (DAST), Interactive Application Security Testing (IAST) und manuelle Tests unbedingt ergänzt werden sollte.
SCA Tools
Software Composition Analysis dient dazu, den Einsatz von freier und Open Source Software in Softwareentwicklungsprojekten zu vereinfachen und sicher zu gestalten. Free and Open Source Software (FOSS) ist seit Langem ein wichtiger Bestandteil in vielen Softwareprojekten, um wiederkehrende Aufgaben durch zuverlässige und einsatzerprobte Softwarekomponenten abzubilden.
Herausforderungen beim Einsatz von FOSS
Allerdings ergeben sich durch den Einsatz von FOSS verschiedene Risiken, die den applikations- und rechtssicheren Betrieb der entwickelten Software betreffen. Auch FOSS-Komponenten haben Sicherheitsschwachstellen, die erst im Laufe der Entwicklung oder des Betriebs einer Software entdeckt werden. Des Weiteren ist FOSS durch rechtlich bindende Lizenzen geschützt, die teils erhebliche Einschränkungen für die Verwendung mit sich bringen.
Unter anderem aus diesen Gründen ist es wichtig zu wissen, welche FOSS man in welcher Version einsetzt und unter welcher Lizenz diese veröffentlicht wurde. Hierbei unterstützen SCA Tools, indem sie diesen Prozess automatisieren.
Gründe für den Einsatz von SCA Tools
Umfangreiche und empfehlenswerte SCA Tools sind in der Lage, mehrere Millionen FOSS-Komponenten zu identifizieren. Dadurch ist es möglich, detaillierte Bill of Materials (BoM) zu erstellen, die einen exakten Einblick in die verwendete FOSS gewährleisten. Anhand dieser Informationen können nachfolgend Schwachstellen und Sicherheitslücken aus vielen verschiedenen Quellen ermittelt werden. Im Anschluss erstellen gute SCA Tools Risiko- und Dringlichkeitsbewertungen, die durch Empfehlungen zur Problemlösung (FOSS-Update oder Workaround) ergänzt werden. Somit kann innerhalb kürzester Zeit auf neue Bedrohungen für die eigene Applikation reagiert werden.
Viele SCA Tools lassen sich in stark automatisierte Prozesse wie Continuous Integration/Continuous Delivery (CI/CD) oder DevSecOps einbinden. Damit ist es möglich, bereits während der Applikationsentwicklung auf FOSS-Schwachstellen zu reagieren. Durch automatisierte Scans, die Teil des Build-Prozesses sind, besteht auch hier die Nachbesserungsmöglichkeit, bevor die Applikation getestet oder deployed wird. Aus Security-Sicht ist es dringend zu empfehlen, dass die im Betrieb befindliche Software in regelmäßigen Abständen durch das eingesetzte SCA-Tool gescannt wird. So kann auch in dieser Phase des Software-Lebenszyklus die Sicherheit der Applikation in Bezug auf die integrierten FOSS-Komponenten gewährleistet werden.
Lizenzen, unter denen FOSS bereitgestellt wird, sind oftmals komplex und können den Einsatz oder Vertrieb der Applikation einschränken. Ein professionelles SCA-Tool erkennt mehrere tausend Lizenzen und unterstützt bei der Identifizierung von Lizenzbedingungen und deren Auswirkungen. Zusätzlich sollten Konflikte zwischen unterschiedlichen FOSS-Lizenzen ermittelt und als Warnung ausgegeben werden können. Weiterhin kann die Unterstützung bei der Generierung des FOSS Disclosure Statements zum Funktionsumfang gehören.
Fazit
Sichere Software zu entwickeln, ist ein zeit- und arbeitsintensiver Prozess. Durch die Integration von SAST- und SCA Tools in den Entwicklungsprozess können viele manuelle Tätigkeiten automatisiert und gleichbleibend gründlich durchgeführt werden. Aus diesen und den vielen anderen oben genannten Gründen ist der Einsatz solcher Werkzeuge ein elementarer Bestandteil der Application Security. Deshalb ist er – auch in unseren Softwareentwicklungsprojekten bei der ZEISS Digital Innovation – unerlässlich, um zuverlässige, qualitativ hochwertige und vor allem sichere Software zu entwickeln.
Der Einsatz eines SAST Tools und eines eines SCA Tools ist ein elementarer Bestandteil der Application Security. Somit ist er – auch in unseren Softwareentwicklungsprojekten bei der ZEISS Digital Innovation – unerlässlich, um zuverlässige, qualitativ hochwertige und v. a. sichere Software zu entwickeln.
Ein großer Teil der Apps, die wir regelmäßig benutzen, stellen für verschiedene Benutzerinnen und Benutzer individuelle Daten und Dienste bereit und müssen daher ihre Anwenderinnen und Anwender eindeutig identifizieren können.
Die klassische Herangehensweise wäre es hier, ein Login-Formular zu bauen und mit einer eigenen Nutzerdatenbank zu verwalten, was jedoch einige Nachteile mit sich bringen kann. Dieser Artikel stellt die alternative Herangehensweise mit den Protokollen „OAuth“ und „OpenID Connect“ vor, die für den Zweck der sicheren Authentifizierung und Autorisierung entwickelt wurden.
Nachteile der klassischen Login-Formulare
Die eingangs beschriebene, klassische Variante der User-Authentifizierung hat einige Nachteile:
Security
Sicherheitskritische Funktionen selbst zu bauen, ist immer mit einem gewissen Risiko verbunden. Bei Passwörtern reicht es beispielsweise nicht aus, einfach nur Hash-Werte abzuspeichern. Denn die Passwörter müssen selbst dann sicher sein, wenn der ungünstigste Fall eintritt und die Datenbank in die Hände von Hackern gelangt. Dafür stehen spezielle Verfahren zur Verfügung, jedoch müssen diese eben auch richtig implementiert sein. Im Zweifel bietet es sich daher in aller Regel an, lieber auf etablierte und durch Expertinnen und Experten begutachtete freie Produkte zu setzen, als diese selbst nachzubauen.
Aufwand
Mit einer einfachen Login-Maske ist es nicht getan. Auch weitere Prozesse wie Registrierung, Passwort ändern, Passwort vergessen usw. müssen bedacht und implementiert werden. Und natürlich gibt es auch hier Best Practices, beispielsweise hinsichtlich Usability, die beachtet werden sollten. Der Aufwand, um alle diese Aspekte in hoher Qualität umzusetzen, sollte nicht unterschätzt werden.
Zwei-Faktor-Authentifizierung
Um die Sicherheit weiter zu erhöhen, sollte den Usern die Möglichkeit gegeben werden, für den Login einen zweiten Faktor zu benutzen. Das kann z. B. ein Einmal-Code sein, der per SMS versandt oder durch eine Authenticator App generiert wird. Aber auch Hardware Token werden gern benutzt. Die Sicherheit wird dadurch enorm gesteigert, da es nun nicht mehr ausreicht, das Passwort zu erraten. Angreiferinnen und Angreifer müssen stattdessen zusätzlich im Besitz des Smartphones oder Hardware Token sein. Diese zusätzlichen Sicherheitsfeatures selbst zu implementieren, ist aber nicht nur fehleranfällig, sondern, siehe vorherigen Punkt, auch aufwändig.
Zentrale Account-Verwaltung
Insbesondere im Firmenkontext ist es häufig eine wichtige Anforderung, dass die Account-Informationen aus einer zentralen Verwaltung (z. B. LDAP, Active-Directory) genutzt werden können. Wenn Mitarbeiterinnen und Mitarbeiter sowieso einen Firmen-Account haben, warum sollten sie dann für jede firmeninterne Anwendung einen zusätzlichen Account mit (hoffentlich) individuellen Passwort anlegen? Die Möglichkeit für Single-Sign-On erhöht zusätzlich den Nutzerkomfort. Und auch außerhalb des Firmenkontexts möchten viele eben nicht für jede App und jede Webseite einen eigenen Account anlegen und sich die Zugangsdaten merken, sondern nutzen lieber einen zentralen Identitäts-Provider.
„OAuth“ und „OpenID Connect“ als Lösungsansatz
Mit den Protokollen „OAuth“ und „OpenID Connect“ stehen zwei Protokolle bereit, die genau für diesen Zweck entwickelt wurden.
Die tatsächliche Implementierung dieser Standards stellt in der Praxis dann aber meist doch eine gewisse Hürde dar, insbesondere wenn man das erste Mal mit diesen Verfahren in Berührung kommt. Dies liegt einerseits daran, dass die Abläufe eben doch etwas komplexer sind als ein simpler Abgleich mit einem gespeicherten Passwort-Hash. Ein anderer Grund dürfte sein, dass die Standards mehrere Varianten (sogenannte Flows) vorsehen, die in unterschiedlichen Situationen zum Einsatz kommen. Als Neuling steht man schnell vor der Frage, welche Variante für die eigene Anwendung die beste ist und wie es dann ganz konkret umzusetzen ist. Die Antwort auf diese Frage ist insbesondere von der Art der Anwendung abhängig, d. h. ob es sich z. B. um eine native Mobile-App, eine klassische serverseitig gerenderte Web-Anwendung oder eine Single-Page-App handelt.
In diesem Artikel wollen wir nicht zu sehr in die Tiefe der beiden Protokolle gehen (wer mehr über OAuth und OpenID Connect lernen möchte, dem sei dieser sehr gute Vortrag auf Youtube empfohlen: https://www.youtube.com/watch?v=996OiexHze0).
Stattdessen wollen wir einen konkreten Anwendungsfall herausgreifen, der bei uns in Projekten relativ häufig vorkommt: Wir bauen eine Single-Page-App (SPA), die statisch ausgeliefert wird. Das heißt, dass sich auf dem Server keine Frontend-Logik befindet, sondern lediglich JavaScript- und HTML-Dateien bereitgestellt werden. Stattdessen stellt der Server lediglich eine API zur Benutzung durch die SPA (und andere Clients) bereit, mit der sich Daten holen und Operationen ausführen lassen. Diese API könnte mittels REST oder GraphQL implementiert sein. Wie bei OAuth üblich, kommt hierbei ein separater Authentication-Service zum Einsatz, wir wollen daher die Benutzerverwaltung nicht selbst implementieren. Dies könnte z. B. ein Cloud-Anbieter sein oder eine selbst gehostete Software, beispielsweise der freie Open-Source-Authentication-Server „Keycloak“. Wichtig ist lediglich, dass der Authentication-Dienst OAuth2/OpenID Connect „spricht“.
Das spannende an dieser Konstellation ist, dass anders als bei einem serverseitig verarbeiteten Web-Frontend, die Authentifizierung zunächst außerhalb der Einflusssphäre des Servers stattfindet (nämlich rein clientseitig in der SPA bzw. im Browser des Nutzers). Die SPA muss anschließend aber Requests gegen die Server-API absenden, wobei der Server der Glaubwürdigkeit der Requests zunächst mal misstrauen und die Authentifizierung nochmal selbstständig überprüfen muss.
Arbeiten mit OAuth: Implicit Flow und Authorization Code Flow
Die OAuth-Spezifikation gibt mehrere Flows vor, für unseren Zweck wollen wir uns aber nur zwei genauer anschauen: Den sogenannten „Implicit Flow“ und den „Authorization Code Flow“. Letztlich geht es bei beiden Varianten darum, dass der Auth Provider der Anwendung einen sogenannten „Access Token“ ausstellt, den die Anwendung anschließend bei allen Requests an den API-Server mitschickt. Der API-Server wiederum kann anhand des Access Token die Authentizität des Requests feststellen. Die Flows unterscheiden sich lediglich darin, wie genau die Ausstellung des Access Token vonstattengeht.
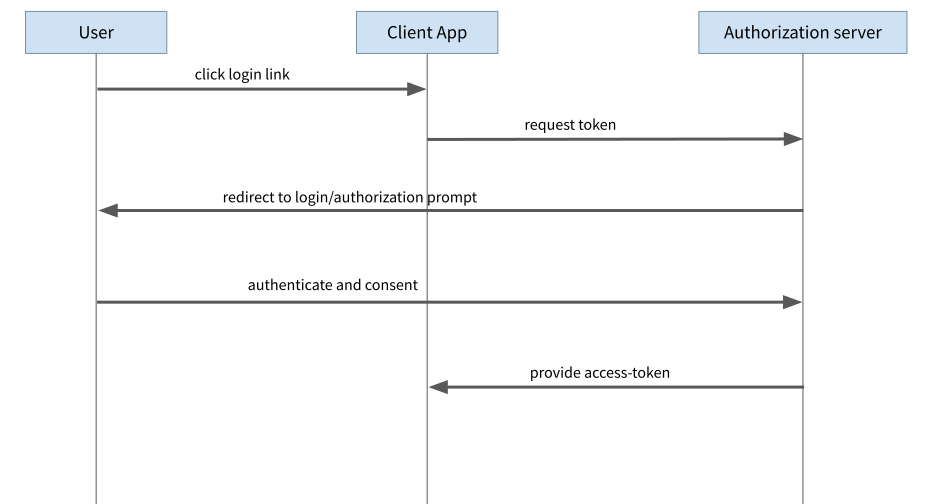
Der Implicit Flow war jahrelang die Empfehlung für den Einsatz in JavaScript-Anwendungen im Browser. Zunächst leitet die Anwendung den User auf eine Login-Seite des Auth-Providers weiter. Nach erfolgtem Login leitet der Auth-Provider den Browser wieder auf die ursprüngliche Seite zurück und übergibt der Anwendung den Access Token als Teil der Response. Genau hier liegen aber auch die Probleme bei dieser Variante. Über verschiedene Wege ist es für einen Angreifer oder eine Angreiferin möglich, an den Access Token zu gelangen, beispielsweise indem die Redirects manipuliert werden und damit der Access Token nicht mehr an die eigentliche App, sondern an den Angreifer oder die Angreiferin geschickt wird.
Abbildung 1: Implicit Flow
Der Implicit Flow war von Anfang an eine Notlösung für JavaScript-Anwendungen im Browser. Zum Zeitpunkt der Standardisierung gab es für Browser-Scripts keine Möglichkeit, Requests auf andere Server als den eigenen auszuführen (sogenannte Same-Origin-Policy). Damit war die Ausführung des eigentlich besseren Authorization Code Flow nicht möglich. In der Zwischenzeit wurde mit dem sogenannten CORS-Mechanismus (für Cross-Origin Resource Sharing) ein System eingeführt, welches genau diese Lücke schließt und Requests auch auf andere Server ermöglicht, sofern diese den Zugriff erlauben.
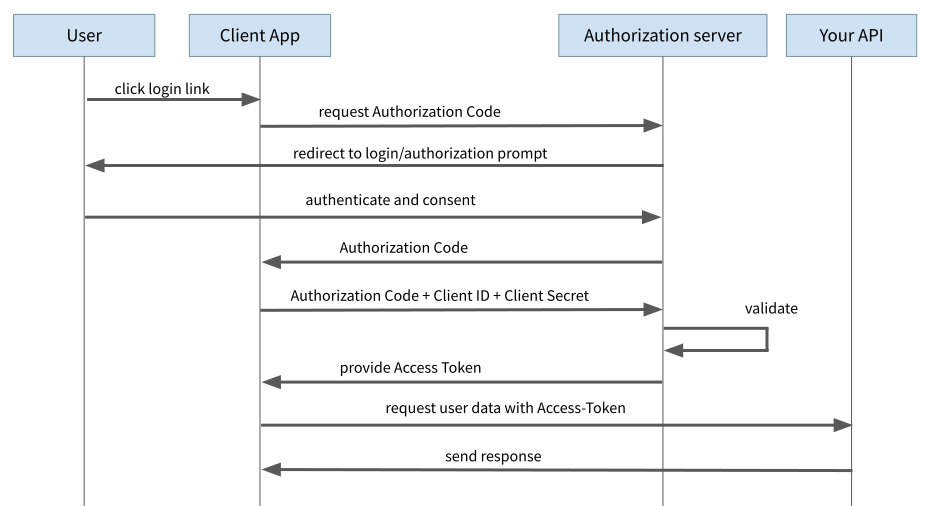
Beim Authorization Code Flow findet ebenfalls ein Redirect auf die Login-Seite des Auth Providers statt. Anstelle eines Access Token schickt der Auth Provider aber lediglich einen sogenannten „Authorization Code“ an den Client. In einem separaten Request muss dieser Authorization Code zusammen mit der „Client ID“ und dem „Client Secret“ an den Auth Provider geschickt und gegen das Access Token eingetauscht werden. Die Client-ID kennzeichnet den Client (in unserem Fall die Single-Page-App) und ermöglicht dem Auth-Server, für verschiedene Clients verschiedene Regeln anzuwenden. Die Client-ID ist im Prinzip öffentlich bekannt und taucht bei einigen Apps/Diensten als Teil der URL auf.
Das Client Secret dagegen ist ein geheimer Code, den nur dieser eine Client verwenden darf, um sich gegenüber dem Auth Server auszuweisen (wir kommen gleich noch einmal darauf zurück). Der entscheidende Punkt ist hier, dass dieser zweite Request nicht als GET-Request sondern als POST-Request implementiert wird. Damit sind die übermittelten Informationen nicht Teil der URL und sind mittels HTTPS (welches selbstverständlich verwendet werden muss) vor den Blicken von Hackern geschützt.
Abbildung 2: Authorization Code Flow
Das Problem mit der browserbasierten Single-Page-App
Eigentlich ist dieser Flow aber vor allem für serverseitig gerenderte Web-Anwendungen gedacht, so dass der Austausch des Authorization Codes gegen den Access Token auf dem Server stattfindet. In dem Fall kann insbesondere das Client Secret auf der Serverseite verbleiben und muss nicht an den Browser übermittelt werden. Bei Single-Page-Apps muss aber der gesamte Prozess im Browser stattfinden und daher benötigt die App auch das Client Secret. Die Schwierigkeit ist somit, das Client Secret „geheim“ zu halten. In der Praxis stellt sich dies als praktisch unmöglich heraus, denn letztlich muss das Client Secret als Teil des Anwendungscodes gebundelt und an den Browser ausgeliefert werden. Das Bundling bei modernen SPA-Frameworks produziert zwar unlesbaren JavaScript-Code, aber es bleibt eben JavaScript und ein Angreifer oder eine Angreiferin könnte sich diesen Code anschauen, das Client Secret extrahieren und damit die Anwendung kompromittieren. Die Lösung hierfür lautet „PKCE“.
Authorization Code Flow mit PKCE
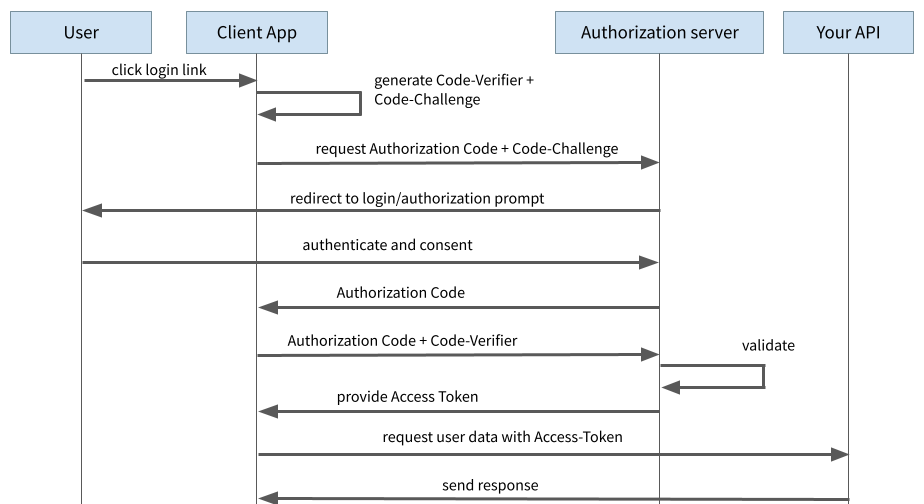
PKCE steht für „Proof Key for Code Exchange“ und ist eine Erweiterung des Authorization Code Flows. Hierbei wird auf das statische Client Secret verzichtet und stattdessen im Prinzip bei jedem Authentifizierungsvorgang ein neues Secret dynamisch generiert.
Dazu wird ganz am Anfang ein sogenannter „Code Verifier“ generiert. Dabei handelt es sich um eine Zeichenkette aus Zufallszahlen. Aus dem Code Verifier wird die „Code Challenge“ berechnet, in dem der Code Verifier mit dem Hash-Verfahren SHA256 gehasht wird.
Beim initialen Login-Vorgang zum Anfragen des Authorization Codes schickt die Anwendung die Code Challenge mit zum Auth Provider. Der Auth Provider merkt sich die Code Challenge und antwortet wie bisher mit dem Authorization Code.
Abbildung 3: Authorization Code Flow mit PKCE
Beim anschließenden Request für den Austausch des Authorization Codes gegen den Access Token schickt der Client nun den Code Verifier mit. Der Auth Provider kann nun prüfen, ob der Code Verifier und die Code Challenge zusammenpassen, indem er seinerseits das Hashing mit SHA256 durchführt.
Ein Angreifer kann bei diesem Verfahren nicht mehr das Client Secret extrahieren, da kein solches Client Secret mehr existiert. Von außen könnte ein Angreifer oder eine Angreiferin höchstens die Code Challenge abgreifen, da diese beim initialen Request über einen Browser Redirect an den Auth Provider übermittelt wird. Der Angreifer oder die Angreiferin hat aber keine Kenntnis vom Code Verifier und kann diesen auch nicht anhand der Code Challenge ableiten. Ohne den Code Verifier stellt der Auth Provider aber kein Access Token aus, womit ein Angreifer oder eine Angreiferin erfolgreich ausgesperrt ist.
Ursprünglich wurde das PKCE-Verfahren vor allem für native Mobile-Apps entwickelt, es lassen sich damit aber auch im Quellcode öffentlich einsehbare Single-Page-Apps sicher umsetzen. Und nicht nur das: Mittlerweile wird das Verfahren sogar für weitere Anwendungsarten wie serverseitige Anwendungen empfohlen, für die bisher der normale Authorization Code Flow mit Client Secret vorgesehen war.
PKCE im Detail
Da der Authorization Code Flow mit PKCE das Mittel der Wahl für Single-Page-Apps ist, wollen wir die einzelnen Schritte etwas genauer anschauen.
Code Verifier und Code Challenge
Zunächst wird der Code Verifier und die Code Challenge berechnet:
In diesem und den folgenden Beispielen verwende ich verkürzte Zufallswerte, um die einzelnen Schritte und Parameter besser darstellen zu können. In einer realen Anwendung müssen hier natürlich echte Zufallswerte generiert werden.
Zufallswerte im Security-Kontext sind aber ein eigenes Thema für sich und daher wollen wir an dieser Stelle nicht im Detail darauf eingehen, wie genau der Code Verifier generiert wird. Als Stichwort sei aber die relativ neue Web-Crypto-API genannt, die unter anderem Funktionen zur Generierung von sicheren Zufallszahlen bereitstellt. Auch für das Hashing mittels SHA256 stellt die Web-Crypto-API die richtigen Hilfsmittel bereit.
Request Token
Nun wird ein Redirect bzw. GET-Request ausgeführt, um den Authorization Code zu erhalten:
Dem Request werden die Code Challenge und die Methode, die zum Berechnen der Code Challenge benutzt wurde (in unserem Fall also SHA256), mitgegeben.
Zusätzlich wird noch ein sogenannter „State“-Parameter mitgegeben, der ebenfalls aus einem Zufallswert besteht. Auf diesen werden wir gleich noch genauer eingehen.
Login und Redirect
Der Browser wird zur Login-Seite beim Auth Provider weitergeleitet, auf der sich die User einloggen und die App autorisieren können. Anschließend leitet der Auth Provider wieder zur App zurück und nutzt dafür den beim ersten Request übergebenen „request_uri“-Parameter. In der Regel konfiguriert man im Auth Provider eine oder mehrere gültige Redirect-URIs, um zu verhindern, dass ein Angreifer oder eine Angreiferin den Request manipuliert und eine gefälschte Redirect-URI unterschieben will.
Die Redirect-URI muss natürlich im Router der Single-Page-App konfiguriert sein und dort die Parameter entgegennehmen, die der Auth Provider dem Client mitteilen möchte. Der Request dazu sieht in etwa so aus:
Der Authorization Code ist ein Token, den wir im nächsten Schritt gegen den eigentlichen Access Token eintauschen wollen (auch hier nochmal der Hinweis, dass ich zur vereinfachten Darstellung hier ausgedachte und verkürzte Zufallswerte benutze. Ein echter Authorization Code sieht anders aus).
Außerdem taucht wieder der State-Parameter auf. Diesen haben wir im vorherigen Schritt als Zufallswert generiert und dem Auth Provider mitgeschickt. Der Auth Provider schickt den State unverändert wieder zurück. Auf diese Weise kann unsere Client App herausfinden, ob der Antwort-Request tatsächlich auf einen eigenen Token Request folgt oder nicht. Sollte ein Angreifer einen Token Request initiiert haben, wäre der dazugehörige State-Parameter bei der App unbekannt und der Request damit direkt als unsicher entlarvt. Dieses Verfahren schützt insbesondere gegen sogenannte CSRF-Attacken (Cross Site Request Forgery, weitergehende Erklärung u. a. hier: https://security.stackexchange.com/questions/20187/oauth2-cross-site-request-forgery-and-stateparameter).
Exchange Code for Access Token
Nun können wir unseren Authorization Code gegen den eigentlichen Access Token austauschen. Dazu starten wir einen POST-Request:
Als Parameter übergeben wir u. a. den Authorization Code und den Code Verifier. Als Antwort erhalten wir nun endlich den Access Token, den wir anschließend für Requests gegen den API-Server verwenden können. Die Antwort sieht in etwa so aus:
Wir erhalten den Access Token und einige weitere Informationen zum Token.
Wie sieht so ein Access Token genau aus? Als Format hat sich der „JSON Web Token“ Standard, kurz JWT, etabliert. Dieser ermöglicht nicht nur den standardisierten Austausch von Authentication-/Authorization-Daten, sondern auch die Verifizierung der Token. Zur Verifizierung steht dabei sowohl eine symmetrische als auch asymmetrische Verifikation zur Verfügung. Damit kann unser API-Server die Gültigkeit der Access Token prüfen, ohne den Auth Provider bei jedem Request kontaktieren zu müssen.
User-Freundlichkeit steigern mit dem Refresh Token
Ein weiterer Aspekt von OAuth sind sogenannte „Refresh Token“. Im vorherigen Beispiel haben wir einen solchen Token zusammen mit dem Access Token erhalten. Die Idee ist, die Gültigkeit von Access Token möglichst kurz zu halten (im Bereich von einigen Minuten bis wenige Stunden). Nach Ablauf des Access Token muss dieser erneuert werden. Dies hat den Vorteil, dass eventuell kompromittierte Access Token nur begrenzten Schaden anrichten können. Außerdem haben User bei OAuth die Möglichkeit, ihre Autorisierung rückgängig zu machen, d. h. beispielsweise die Berechtigung einer App, auf die eigenen Daten zugreifen zu dürfen, beim Auth Provider wieder zu entziehen. Da zur Verifikation von Access Token auf Seiten des API-Servers aber keine Kommunikation mit dem Auth Provider vorgesehen ist, bekommt der API-Server von diesem Rechte-Entzug nichts mit.
Sobald jedoch der alte Access Token abgelaufen ist und ein neuer besorgt werden muss, greifen die neuen Berechtigungen. Allerdings möchte man aus Komfortgründen die eigenen Anwenderinnen und Anwender ungern alle paar Minuten erneut zum Einloggen auffordern. Aus diesem Grund übermittelt der Auth Provider einen länger gültigen Refresh Token. Dieser wird in der Client App gespeichert und bei Ablauf des Access Token benutzt, um sich bei beim Auth Provider einen neuen Access Token zu holen. Der Auth Provider fordert in diesem Fall keinen neuen Login vom Nutzer oder der Nutzerin. Sollte dieser aber zuvor die Berechtigungen für die App entzogen haben, stellt er keine neuen Access Token mehr aus. Wichtig ist: Der Refresh Token ist noch wertvoller als der Access Token und muss daher um jeden Preis vor dem Zugriff von unberechtigten Dritten geschützt werden!
Fazit
OAuth ist ein spannendes Protokoll, das die meisten Fragen rund um Authentifizierung und Autorisierung sicher lösen kann. Allerdings ist das Thema nicht gerade einsteigerfreundlich und am Anfang können einen die vielen Begriffe und Abläufe schnell überfordern.
Hat man sich dann endlich in die Thematik eingedacht, stellt sich die Frage nach der Umsetzung. Insbesondere bei Single-Page-Anwendungen existieren im Netz noch viele Anleitungen, die auf den mittlerweile nicht mehr empfohlenen Implicit Flow verweisen. Mit PKCE steht aber eine Erweiterung bereit, die auch den besseren Authorization Code Flow für JavaScript-Anwendungen ermöglicht.
Um die Umsetzung zu vereinfachen, existieren zahlreiche Bibliotheken. Zum einen bieten Cloud-Anbieter, die OAuth nutzen, häufig eigene Hilfsbibliotheken an. Empfehlenswert ist aber auch ein Blick auf die Bibliothek „OIDC-Client“ (https://github.com/IdentityModel/oidc-client-js), die eine anbieterunabhängige Lösung bietet. Neben dem reinen OAuth unterstützt diese Bibliothek auch die Erweiterung „OpenID Connect“, die OAuth um Funktionen für User-Profile und Authentifizierung ergänzt. Die Bibliothek abstrahiert zwar die einzelnen Schritte der OAuth Flows, so dass man sich nicht mehr mit den einzelnen Requests und deren Parametern „herumschlagen“ muss. Ein gewisses Grundverständnis der Abläufe ist aber dennoch nützlich und hilft bei der sinnvollen Verwendung der Bibliothek.
Seit Beginn der Covid-Pandemie steht das Gesundheitswesen unter enormem Druck. Die demografische Entwicklung, der Wandel des Krankheitsspektrums, gesetzliche Vorschriften, Kostendruck und Fachkräftemangel bei gleichzeitig steigendem Anspruch der Patienten stellt Gesundheitsorganisationen vor einige Herausforderungen. Hier bieten die Digitalisierung und der Einsatz moderner Technologien wie Künstlicher Intelligenz oder Machine Learning zahlreiche Chancen und Potentiale zur Effizienzsteigerung, Fehlerreduktion und somit Verbesserung der Patientenbehandlung.
Abbildung 1: Digital Health Solutions mit Azure Health Data Services für eine optimale und zukunftsfähige Patientenversorgung
Nutzung medizinischer Daten als Basis für eine optimierte Patientenversorgung
Grundlage für die Nutzung dieser Technologien und für eine zukunftsfähige prädiktive und präventive Versorgung sind medizinische Daten. Diese finden sich bereits heute überall. Die meisten Akteure im Gesundheitswesen und die im Einsatz befindlichen Medizingeräte speichern diese aber immer noch on-premise, was zu Millionen von isolierten medizinischen Datensätzen führt. Um einen vollumfänglichen Überblick über die Krankheitsgeschichte eines Patienten zu erhalten und darauf aufbauend Behandlungspläne im Sinne einer patientenzentrierten Behandlung zu erstellen und übergreifende Erkenntnisse aus diesen Datensätzen ableiten zu können, müssen Organisationen Gesundheitsdaten aus verschiedenen Quellen integrieren und synchronisieren.
Um die Entwicklung von Ökosystemen im Gesundheitswesen zu unterstützen, bieten die großen globalen Public Cloud Provider (Microsoft Azure, Amazon Web Service und Google Cloud Platform) zunehmend spezielle SaaS- und PaaS-Dienste für den Healthcare-Sektor an, die Unternehmen eine Basis für ihre eigenen Lösungen bieten können. Durch unsere Erfahrung bei ZEISS Digital Innovation als Implementierungspartner der Carl Zeiss Meditec AG und von Kunden außerhalb der ZEISS Gruppe haben wir bereits früh erkannt, dass Microsoft ein besonders leistungsfähiges Healthcare-Portfolio bietet und dieses weiter stark ausbaut. Das wurde auch auf der diesjährigen Ignite wieder deutlich.
ZEISS Digital Innovation (re.) bei der Ignite 2021 im Gespräch darüber, wie man langfristigen Nutzen aus Gesundheitsdatenmit Microsoft Cloudfor Healthcare ziehen kann. (Hier geht’s zum vollständigen Video)
Medizinische Datenplattformen auf Basis von Azure Health Data Services
Eine Möglichkeit für den Aufbau einer solchen medizinischen Datenplattform als Basis eines Ökosystems ist die Nutzung vonAzure Health Data Services. Mit Hilfe dieser Services lassen sich Speicherung, Zugriff und Verarbeitung von medizinischen Daten interoperabel und sicher gestalten. Tausende Medizingeräte können miteinander verbunden werden und die so generierten Daten von zahlreichen Anwendungen skalierbar und robust genutzt werden. Da es sich bei den Azure Health Data Services um PaaS-Lösungen handelt, sind sie „out of the box“ nutzbar und werden vollständig von Microsoft entwickelt, verwaltet und betrieben. Sie sind dadurch außerdem standardmäßig sicher und compliant und mit geringem Aufwand hoch verfügbar. Dies senkt den Implementierungsaufwand und damit auch die Kosten erheblich.
Auch die Carl Zeiss Meditec AG setzt bei der Entwicklung seines digitalen, datengesteuerten Ökosystems auf Azure Health Data Services. Das gemeinsam mit der ZEISS Digital Innovation entwickelte ZEISS Medical Ecosystem verbindet Geräte und klinische Systeme über eine zentrale Datenplattform mit Applikationen und schafft so einen Mehrwert auf verschiedenen Ebenen zur Optimierung des klinischen Patientenmanagements.
Als zentrale Schnittstelle für die Geräteanbindung wird hier der DICOM Service der Azure Health Data Services genutzt. Da DICOM ein offener Standard zur Speicherung und zum Austausch von Informationen im medizinischen Bilddatenmanagement ist, kommunizieren ein Großteil der medizinischen Geräte, die Bilddaten generieren, mithilfe des DICOM-Protokolls. Durch eine erweiterbare Konnektivitätslösung, die auf Azure IoT Edge basiert, können diese Geräte unter Verwendung des DICOM-Standards direkt mit der Datenplattform in Azure verbunden werden. Dies ermöglicht die Integration einer Vielzahl von Geräten, die bereits seit Jahren bei Kunden im Einsatz sind, in das Ökosystem. Dies erhöht die Akzeptanz und sorgt dafür, dass mehr Daten in die Cloud fließen und weiterverarbeitet werden können, um klinische Anwendungsfälle zu ermöglichen und neue Verfahren zu entwickeln.
Als zentraler Data Hub der Plattform dient Azure API for FHIR®. Dort werden alle Daten des Ökosystems strukturiert gespeichert und miteinander verknüpft, um sie zentral auffindbar zu machen und den Applikationen zur Verfügung zu stellen. HL7® FHIR® (Fast Healthcare Interoperability Resources) bietet ein standardisiertes und umfassendes Datenmodell für Daten im Gesundheitsweisen. Damit können nicht nur einfache und robuste Schnittstellen zu den eigenen Anwendungen umgesetzt werden, sondern auch die Interoperabilität mit Drittsystemen wie EMR-Systemen (Electronic Medical Record), Krankenhausinformationssystemen oder der elektronischen Patientenakte sichergestellt werden. Die Daten aus den medizinischen Geräten, historische Messdaten aus lokalen PACS-Lösungen und Informationen aus anderen klinischen Systemen werden nach dem Hochladen automatisch weiterverarbeitet, strukturiert und zentral in Azure API for FHIR® aggregiert. Dies ist ein Schlüsselfaktor, um mehr wertvolle Daten für klinische Anwendungsfälle zu sammeln und den Kunden ein nahtlos integriertes Ökosystem zu bieten.
Abbildung 2: Aufbau einer medizinischen Datenplattform mit Azure Health Data Services
Erfolgreiche Zusammenarbeit von ZEISS Digital Innovation und Microsoft
Als Early Adopter der Azure Health Data Services arbeiten unsere Entwicklungsteams bei ZEISS Digital Innovation eng mit der Produktgruppe der Azure Health Data Services im Microsoft Headquarter in Redmond, USA, zusammen und gestalten so die Services im Sinne unserer Kunden mit. In regelmäßigen Co-Creation-Sessions zwischen den Teams der ZEISS Digital Innovation und Microsoft wird das Lösungsdesign für aktuell implementierte Features der Azure Health Data Services diskutiert. So können wir sicherstellen, dass auch die komplexesten derzeit bekannten Anwendungsfälle berücksichtigt werden.
We are working very closely with ZEISS Digital Innovation to shape Azure’s next generation health services alongside their customer needs. Their strong background in the development of digital medical products for their customers is a core asset in our collaboration and enables the development of innovative solutions for the healthcare sector.
Steven Borg (Director, Medical Imaging at Microsoft)
Elisa Kunze ist seit 2013 bei der ZEISS Digital Innovation tätig und konnte dort bei ihren unterschiedlichen Tätigkeiten im Sales und Marketing viele Projekte, Teams und Unternehmen in unterschiedlichsten Branchen kennenlernen und begleiten. Heute betreut sie als Key Account Managerin ihre Kunden im Health Sector bei der Umsetzung ihrer Projektvisionen.
Ein nicht unerheblicher Teil der Arbeit eines Softwarearchitekten besteht darin, verschiedene Lösungsalternativen miteinander zu vergleichen. Hierbei wird oft auf Entscheidungstabellen bzw. Bewertungsmatrizen zurückgegriffen, wobei beide Begriffe in aller Regel synonym verwendet werden. Dieser Artikel soll einen Einblick in zwei grundlegende Vorgehen bieten und jene nach ihrer Eignung bewerten.
Abbildung 1: Softwarearchitekten müssen oft verschiedene Lösungsalternativen miteinander vergleichen. Dafür nutzen sie oft bestimmte Bewertungsmatrizen.
Arten von Bewertungsmatrizen
Bewertungsverfahren, um mehrere zur Auswahl stehende Varianten miteinander zu vergleichen, reichen von einfachen, über Abstimmung entstandene Rankings bis hin zu komplizierten Bewertungsverfahren über Matrizenrechnungen. Die Herausforderung besteht darin, für den Vergleich zwei zur Auswahl stehender Optionen die am besten geeignete Methodik zur objektivierten Bewertung zu finden. Kriterien hierfür sind:
Schneller Vergleich
Einfaches, unkompliziertes Verfahren
Geringe bis keine Einarbeitungszeit
Beliebige Personenanzahl
Nach kurzem Vergleichen der Bewertungsverfahren anhand der genannten Kriterien stellt sich hier die sehr verbreitete und bekannte Nutzwertanalyse als das Mittel der Wahl heraus. Warum? Weil sich mit ihr unkompliziert und einfach Optionen anhand verschiedener Kriterien vergleichen lassen, ohne dass es eines großen mathematischen Aufwandes bedarf. Die Varianten werden bei der Nutzwertanalyse mithilfe gewichteter Kriterien mit einem Score bewertet, Gewichtung und Score miteinander multipliziert und alle Bewertungen für eine Option addiert (siehe Beispiel).
Abbildung 2: Bewertung der einzelnen Varianten in einer Nutzwertanalyse
Dieses Verfahren sollte fast jedem geläufig sein und findet auch in der Praxis in vielen Bereichen Anwendung. Neben der Bewertung durch die bewertende Person ergibt sich eine potenzielle subjektive Fehlerquelle: die Gewichtung der Kriterien. Da die Score-Vergebung nicht objektiver gestaltet werden kann, muss eine Möglichkeit der objektiven Gewichtungsberechnung gefunden werden. Diese ist absolut unumgänglich, wenn eine aussagekräftige Nutzwertanalyse gefordert ist. Die objektivierte Gewichtung stellt sicher, dass keine durch z. B. Zeitdruck entstandenen, „kopflosen“ Entscheidungen getroffen werden und die Gewichtung möglichst unabhängig vom Betrachtenden ist.
Verfahren zur Gewichtungsberechnung
Wie schon bei der Nutzwertanalyse besteht hierbei der Anspruch, dass das Verfahren unkompliziert, schnell und ohne Einarbeitungszeit erfolgt. Unter diesen Prämissen kristallisieren sich insbesondere zwei Verfahren heraus, die im Folgenden kurz erläutert werden.
Abgestufte Gewichtung
Bei der abgestuften Gewichtungsberechnung werden alle Kriterien hinsichtlich ihrer Bedeutung untereinander verglichen. Dabei umfasst die Skala fünf Abstufungen von -2: „wesentlich kleinere Bedeutung“ bis hin zu 2: „wesentlich größere Bedeutung“. Für jede Paarung von Kriterien muss daher diese granulare Einschätzung erfolgen. Über eine an Matrizenrechnung angenähertes Verfahren wird dann die Gewichtung berechnet.
Abbildung 3: Beispiel für eine Skala bei einer abgestuften Gewichtung
Prioritätengewichtung
Hierbei wird auf die granulare Bewertung verzichtet und lediglich unterschieden in „wichtiger“ oder „unwichtiger“. Somit wird jedes Kriterium mit jedem anderen verglichen und das wichtigere in der Tabelle notiert. Über den relativen Anteil der Anzahl eines Kriteriums wird dann die Gewichtung ermittelt. Diese Vorgehensweise lässt sich gut im Team integrieren, da man nach dem Ranking durch die Einzelpersonen alle Ergebnisse zusammenführen kann und somit eine repräsentative Gewichtung erhält.
Abbildung 4: Beispiel für eine Prioritätengewichtung einzelner Kriterien
Wann ist welches Verfahren geeignet?
Prinzipiell kann jedes Verfahren zur Gewichtungsberechnung in jeder Situation angewendet werden. Die folgende Tabelle gibt aber Anhaltspunkte, bei welchen Gegebenheiten welche Berechnungsart vorteilhaft sein kann.
Abgestufte Gewichtung
Prioritätengewichtung
Geringe Anzahl an Kriterien
Hohe Anzahl an Kriterien
Geringe Anzahl an bewertenden Personen
Hohe Anzahl an bewertenden Personen
Ausreichend Zeit verfügbar
Wenig Zeit verfügbar
Besonders wichtige Entscheidung
Zusammenfassend kann gesagt werden, dass das Verfahren der abgestuften Gewichtung häufig zu aufwändig ist, wenn man in der Praxis davon ausgeht, dass Entscheidungen teilweise nicht einmal von einem repräsentativen Bewertungsverfahren begleitet werden. Die Prioritätengewichtung hingegen ist eine unkomplizierte, schnell verständliche und auch im Team implementierbare Möglichkeit und wird daher besonders empfohlen.
Neben der Nutzwertanalyse können auch noch weitere Verfahren und Kennzahlen zum Variantenvergleich hinzugezogen werden, beispielweise Standardabweichung, Anzahl Gewinne/Verluste usw., welche die schlussendliche Entscheidung leichter machen sollen, aber nicht Bestandteil dieses Beitrags sind.
Viele Projekte arbeiten mit Datenbanken und da muss natürlich die Performance des Systems getestet werden. Meist werden kleinere Datenmengen durch manuelle Tests eingegeben, aber wie erhält man Massendaten?
Die übliche Antwort lautet natürlich „Kauf eines der Tools“ – und meist zu Recht. Diese Tools haben eine (oft) recht einfach bedienbare UI, sind flott und vor allem können sie semantisch sinnvolle Daten generieren.
Abbildung: Um einen aussagekräftigen Performance-Test für Datenbanken durchzuführen, müssen Testerinnen und Tester die Verarbeitung sowohl kleiner als auch großer Datenmengen simulieren.
Daten generieren mit SQL
Dennoch, mit ein wenig SQL kann man auch selbst derartige Daten generieren. Interessant wird es bei der Verknüpfung von mehreren Tabellen, was im folgenden Beispiel eine wichtige Rolle spielt.
Szenario: Unser Projekt verwaltet Firmen und deren Anlagen und für diese sollen Rechnungsdaten generiert werden. Für diese Daten gibt es im Projekt verschiedene Ansichten und Abfragen. Wir möchten einige Bereiche mit wenig Daten haben (um die Funktion des Systems zu testen), aber auch Massendaten.
Zuerst erzeugen wir die Firmen (hier nur drei Stück) mit einer einzigen Anweisung. Das ist der erste wichtige Punkt, um eine gute Performance bei der Generierung der Daten zu erreichen. Natürlich könnte man auch drei INSERT-Statements nacheinander schreiben oder mit PL/SQL einen Loop 1..3 verwenden. Ab einer gewissen Zahl von Daten, die man erzeugen möchte, wird das aber massiv langsamer werden.
Teilabfrage „firma_seq“: Erzeugt eine Sequenz von 1..3
InsertStatement: Die Firma soll einen aussagekräftigen Namen erhalten (hohe Nummer = viel Daten).
insert into firma (name)
select
'Firma '||firma_seq.firma_nummer as name
from (
select rownum as firma_nummer
from dual
connect by level<=3
) firma_seq
;
Als nächstes möchten wir die Anlagen zu den Firmen erzeugen. Nicht vergessen: Wir wollen einige Bereiche mit wenig, andere mit viel Daten. Daher sollen zur ersten Firma drei Anlagen zugeordnet werden, zur zweiten Firma sechs Anlagen usw.
Teilabfrage „firma“: Durch das Ranking erhält man eine laufende Nummer 1..N, damit kann man auch einfach die gewünschte Anzahl Anlagen je Firma festlegen. Diese Abfrage produziert je Firma genau eine Zeile.
Teilabfrage „anlage_seq“: Wir benötigen eine Sequenz, um durch den Join auf die „firma“ Teilabfrage je Firma und gewünschte Anzahl von Anlagen eine Zeile zu generieren. Dazu nehmen wir eine großzügig geschätzte Sequenz. Der Join wird durch die zuvor ermittelte Anzahl der Anlagen je Firma begrenzt.
InsertStatement: Der Anlagenname soll erkennen lassen, zu welcher Firma diese Anlage gehört.
insert into anlage (firma_id, name)
select
firma.firma_id,
'Anlage '||firma.firma_nummer||'.'||anlage_seq.anlage_nummer
from (
select
firma_id,
dense_rank() over (order by firma_id) as firma_nummer,
dense_rank() over (order by firma_id) * 3 as anzahl_anlagen
from firma
) firma
join (
select rownum as anlage_nummer from dual connect by level<=1000
) anlage_seq on (anlage_seq.anlage_nummer <= firma.anzahl_anlagen)
;
Zuletzt soll noch je Firma und Anlage eine Abrechnung pro Kalendermonat generiert werden. Hier soll es weniger um die Joins gehen, stattdessen sollen Daten im Vordergrund stehen.
Kernstück für zufällige Daten ist in Oracle das dbms_random Package. Es bietet mehrere Funktionen zur Erzeugung von Zahlen an, mit dem Standardbereich 0..1 oder mit selbst definierten Bereichen. Die Nachkommastellen der generierten Zahlen muss man allerdings selbst durch Rundung kontrollieren. Es steht ein Generator für Zeichen zur Verfügung, mit einigen Modi wie Groß, Klein, alphanumerisch, …
Rechnungsnummer: Drei Großbuchstaben, gefolgt von sechs Ziffern
Betrag: Ein zufälliger Wert im Bereich 100..900 Euro.
Zuschlag: Bei ca. 10 % der Rechnungen soll ein Zuschlag von 50 € erhoben werden, das wird durch den Vergleich einer Zufallszahl im Bereich 0..1 auf < 0.10 erreicht.
insert into abrechnung (firma_id,anlage_id,abrechnungsmonat,rechnungsnummer,betrag,zuschlag)
select
firma.firma_id,
anlage.anlage_id,
to_date('01.'||monat||'.2021', 'dd.mm.yyyy') as abrechnungsmonat,
dbms_random.string('U',3) || round(dbms_random.value(10000,99999), 0) as rechnungsnummer,
round(100 + dbms_random.value(100,900),2) as betrag,
case when dbms_random.value<0.10 then 50 else null end as zuschlag
from firma
join anlage
on anlage.firma_id = firma.firma_id
join (
select rownum as monat from dual connect by level<=12
) monat_seq on (1=1)
order by 1,2,3
;
Fazit
Einen Schönheitspreis gewinnen diese Daten nicht, dafür sollte man besser auf die erwähnten Produkte zurückgreifen. Aber in unserem Projekt hat dieser Ansatz geholfen, vom ersten Tag an Daten in ausreichender Qualität und vor allem Quantität bereitzustellen. Damit konnten wir von Anfang an auch die Performance des Systems sicherstellen. Zudem kann im Endergebnis das System mehr Daten verarbeiten sowie diese auch schneller verarbeiten als ähnliche Systeme beim Kunden.
Source Code
--------------------------------------------------------------------------------------------------------------
-- Datenmodell anlegen
--------------------------------------------------------------------------------------------------------------
drop table abrechnung;
drop table anlage;
drop table firma;
create table firma (
firma_id number(9) generated as identity,
name varchar2(100) not null,
constraint pk_firma primary key (firma_id)
);
create table anlage (
anlage_id number(9) generated as identity,
firma_id number(9) not null,
name varchar2(100) not null,
constraint pk_anlage primary key (anlage_id),
constraint fk_anlage_01 foreign key (firma_id) references firma (firma_id)
);
create table abrechnung (
abrechnung_id number(9) generated as identity,
firma_id number(9) not null,
anlage_id number(9) not null,
abrechnungsmonat date not null,
rechnungsnummer varchar(30) not null,
betrag number(18,2) not null,
zuschlag number(18,2),
constraint pk_abrechnung primary key (abrechnung_id),
constraint fk_abrechnung_01 foreign key (firma_id) references firma (firma_id),
constraint fk_abrechnung_02 foreign key (anlage_id) references anlage (anlage_id)
);
--------------------------------------------------------------------------------------------------------------
-- Daten generieren
--------------------------------------------------------------------------------------------------------------
-- Alle Daten löschen
truncate table abrechnung;
truncate table anlage;
truncate table firma;
whenever sqlerror exit rollback;
-- Firmen erzeugen (hier 3)
insert into firma (name)
select
'Firma '||firma_seq.firma_nummer as name
from (select rownum as firma_nummer from dual connect by level<=3) firma_seq
;
commit;
-- Anlagen je Firma einfügen. Die erste Firma erhält drei Anagen, die nächste sechs Anlagen, ...
insert into anlage (firma_id, name)
select
firma.firma_id,
'Anlage '||firma.firma_nummer||'.'||anlage_seq.anlage_nummer
from (
-- Je Firma deren laufende Nummer ermitteln und die gewünschte Anzahl von Anlagen
select
firma_id,
dense_rank() over (order by firma_id) as firma_nummer,
dense_rank() over (order by firma_id) * 3 as anzahl_anlagen
from firma
) firma
join (
-- Eine Sequenz von Anlagen, durch den Join die benötigten Zeilen je Firma mit N Anlagen zu erhalten
select rownum as anlage_nummer from dual connect by level<=1000
) anlage_seq on (anlage_seq.anlage_nummer <= firma.anzahl_anlagen)
-- order by 1,2
;
commit;
-- Je Firma und Anlage eine Abrechnung je Kalendermonat erzeugen.
-- Die Rechnungsnummer ist ein zufälliger String mit drei Bucstaben und sechs Ziffern.
-- Der Betrag ist ein zufälliger Wert im Bereich 100..900 Euro.
-- Der Zuschlag von 50 Euro wird bei ca. 10% der Rechnungen gesetzt.
insert into abrechnung (firma_id,anlage_id,abrechnungsmonat,rechnungsnummer,betrag,zuschlag)
select
firma.firma_id,
anlage.anlage_id,
to_date('01.'||monat||'.2021', 'dd.mm.yyyy') as abrechnungsmonat,
dbms_random.string('U',3) || round(dbms_random.value(10000,99999), 0) as rechnungsnummer,
round(dbms_random.value(100,1000),2) as betrag,
case when dbms_random.value<0.10 then 50 else null end as zuschlag
from firma
join anlage on anlage.firma_id = firma.firma_id
join (select rownum as monat from dual connect by level<=12) monat_seq on (1=1)
-- order by 1,2,3
;
commit;
Innerhalb von ZEISS Digital Innovation (ZDI) gibt es in regelmäßigen Abständen eine interne Weiterbildungsveranstaltung – den sogenannten ZDI Campus. Dabei präsentieren wir als Mitarbeiterinnen und Mitarbeiter Softwareentwicklungsthemen mittels Vorträgen, Workshops oder Diskussionsrunden.
Katharina hatte beim vergangenen ZDI Campus schon einmal über kollaborative Testmethoden berichtet und auch Blogartikel bezüglich Remote Pair Testing sowie Remote Mob Testing veröffentlicht. Daher wollten wir das Thema gern auf dem nächsten ZDI Campus weiterführen und einen Workshop aus der Themenwelt kollaborativer Testmethoden anbieten. Aufgrund der Covid-19-Pandemie musste der nächste Campus jedoch online stattfinden. Dennoch wollten wir mehreren Teilnehmerinnen und Teilnehmern die Möglichkeit bieten, eine Testmethode am praktischen Beispiel anzuwenden und haben uns daher für einen remote Mob Testing Workshop entschieden.
Doch es gab eine Herausforderung: Wir hatten noch nie mit so vielen Personen im Mob remote gearbeitet!
Aufbau des Workshops
Wie in dem Blogbeitrag über Remote Mob Testing beschrieben ist es sinnvoller, kleine Gruppen aus vier bis sechs Personen zu betreuen. Durch das verteilte Arbeiten kann es sonst häufiger zu Verzögerungen durch technische Probleme (z. B. schlechte Verbindung, schlechte Tonqualität) kommen, was die Einsatzzeit des jeweils aktuellen Navigators verkürzen könnte. Auch kann man als Facilitator bei kleineren Gruppen besser den Überblick behalten und die Teilnehmenden können die Rolle des Navigators oder Drivers häufiger einnehmen. (Zur Erläuterung der verschiedenen Rollen siehe ebenfalls Blogbeitrag Remote Mob Testing)
Unser Setting sah wie folgt aus:
Microsoft Teams als Kommunikationsplattform
Leicht verständliches Testobjekt (Website)
3 Facilitators
39 Teilnehmerinnen und Teilnehmer aus den Bereichen QA, Entwicklung und Business Analyse
Zeitlicher Rahmen: 1,5 h
Weil wir allen die Möglichkeit geben wollten, das Mob Testing selbst an einem praktischen Beispiel kennenzulernen, haben wir im Vorfeld des Workshops keine Teilnehmerbegrenzung festgelegt. Schlussendlich hatten alle drei Facilitators über 12 Teilnehmerinnen und Teilnehmer.
Beim Remote Mob Testing nehmen alle Teilnehmenden einmal die aktive Rolle des Navigators ein.
Als Testobjekt haben wir eine einfache Website gewählt, damit sich alle auf das Vermitteln bzw. Kennenlernen der Testmethode konzentrieren konnten und sich nicht noch zusätzlich Wissen über die Anwendung aneignen mussten.
Feedback
Schon während der Durchführung des Workshops fiel uns auf, dass die Wartezeiten, bis eine aktive Rolle (Driver oder Navigator) eingenommen wird, als unangenehm empfunden werden könnte.
Dies wurde auch in der Feedbackrunde angesprochen. Daher empfehlen wir, dass der Mob bei Testideen mit unterstützt. Es bedeutet nämlich nicht, dass man sich als Mob-Mitglied zurücklehnen und mit den Gedanken abschweifen kann. Das vermeidet auch doppeltes Testen oder sich die Blöße geben zu müssen, nicht aufgepasst zu haben.
Teilweise fiel es einigen Teilnehmenden am Anfang schwer, sich bei der Rolle des Drivers darauf zu konzentrieren, nur die Anweisungen des Navigators auszuführen und eigene Testideen zurückzuhalten. Durch entsprechende Hinweise des Facilitators gewöhnten sich die Teilnehmerinnen und Teilnehmer jedoch nach einiger Zeit daran. Dieser Aspekt des Mob Testings wurde als sehr positiv empfunden, weil alle in der Rolle des Navigators zu Wort kommen und eigene Testideen einbringen können.
Dennoch kam die Frage auf, warum die Rollen Navigator und Driver nicht zusammengefasst werden können. Dazu lässt sich Folgendes sagen: Es fördert den Lernprozess, wenn ein Mitglied Schritt für Schritt artikuliert, was es vorhat. So bindet man mehr Teilnehmerinnen und Teilnehmer in diese aktive Rolle ein. Durch das Mitteilen des Ziels wird es den Teilnehmenden erleichtert, den Ideen des Navigators zu folgen. Andernfalls kann es passieren, dass einige Schritte zu schnell und mit zu wenig Erklärung durchgeführt werden. Dadurch ginge die Nachvollziehbarkeit verloren und dem Mob würde es erschwert, sich aktiv einzubringen.
Weiteres positives Feedback gab es zur Rolleneinteilung und dem gesamten Vorgehen. Den Aussagen der Befragten nach erhalte man die Testansätze zum Teil durch den Weg, den der vorherige Navigator eingeschlagen hat und betrachtet daher das Testobjekt aus den unterschiedlichsten Blickwinkeln. Aus diesem Grund ist es immer sinnvoll – je nach Zweck der Mob Testing Session – Teilnehmerinnen und Teilnehmer mit unterschiedlichen Kenntnissen einzuladen. Das erhöht den Lernprozess und die Anzahl der Testfälle. Das einfache Beispiel-Testobjekt habe zudem geholfen, sich auf die Methode zu konzentrieren und sie zu verinnerlichen.
Sehr positiv hervorgehoben wurde das kollaborative Arbeiten beim Mob Testing. Dadurch wird der agile Gedanke gelebt.
Lösungsansatz für eine große Teilnehmerzahl
Das Problem einer zu hohen Teilnehmeranzahl könnte man lösen, indem man im Vorfeld die Gruppengröße begrenzt oder aber eine neue Rolle einführt: die Rolle des Zuschauers. Dabei würde dann eine Trennung zwischen aktiven Teilnehmern und Teilnehmerinnen einerseits sowie Zuschauerinnen und Zuschauern andererseits vollzogen. Die Teilnehmenden würden das oben beschriebene Vorgehen durchführen und sich an die Rollenverteilung (Navigator, Driver, Mob) sowie den Rollenwechsel halten. Die Zuschauerinnen und Zuschauer würden nur beobachten und nicht teilnehmen. Auch Kommentare von ihnen wären nicht erlaubt, weil das bei einer hohen Zuschauerzahl die aktiven Teilnehmenden stören könnte.
Fazit
Alles in Allem ist der Workshop auf der Campus-Veranstaltung sehr gut angekommen und hat gezeigt, dass es sehr gut möglich ist, Mob Testing auch remote und somit für das verteilte Arbeiten anzuwenden. Durch diese Möglichkeit kann das Zusammenarbeiten beibehalten werden, auch wenn es nicht immer möglich ist, sich vor Ort zu treffen.
Dieser Beitrag wurde verfasst von:
Maria Petzold
Maria Petzold arbeitet seit 2010 bei der ZEISS Digital Innovation. Als Testmanagerin liegt ihr Fokus auf der Qualitätssicherung von Software. Vor allem in medizinischen Softwareprojekten konnte sie ihre Test-Erfahrungen sammeln.