Vom Azure-Stack zur tragfähigen Architektur
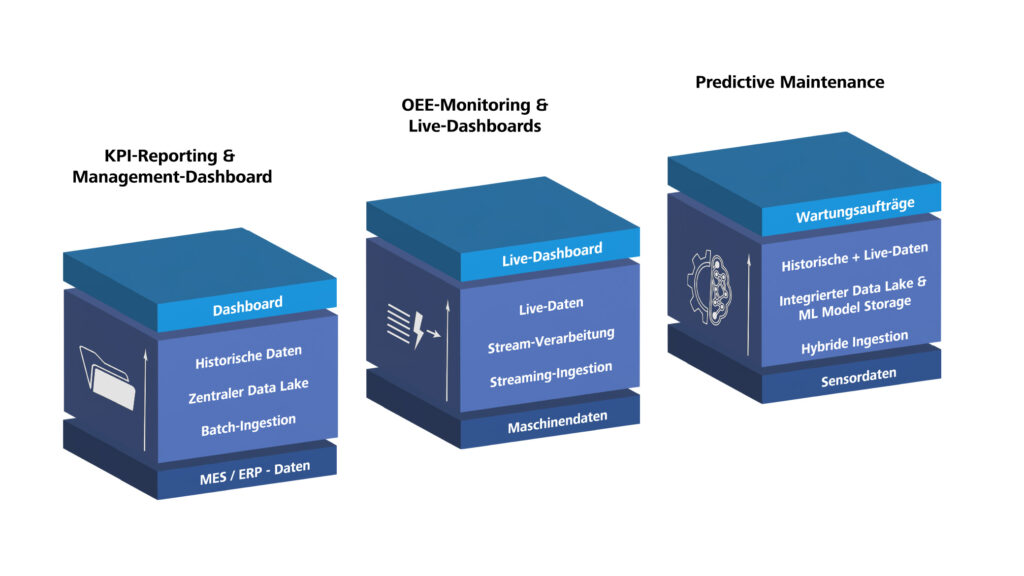
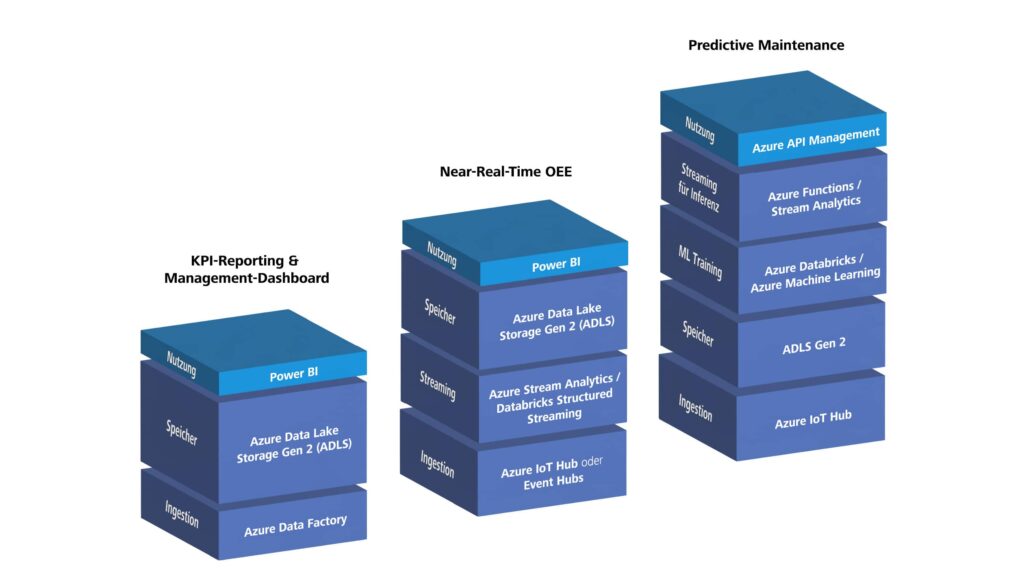
Im ersten Teil dieses Artikels haben wir typische Fertigungsszenarien – von KPI-Reporting über OEE-Monitoring bis zu Predictive Maintenance – auf konkrete Azure-Stacks übersetzt. Wir haben Azure-Bausteine nach Aufgabenclustern strukturiert und für drei exemplarische Stack-Kombinationen gezeigt, wie Ingestion, Speicherung, Verarbeitung und Nutzung ineinandergereifen.
Doch eine Plattform steht und fällt nicht allein mit der Tool-Auswahl. In diesem zweiten Teil widmen wir uns den Fragen, die tiefer gehen: Wann ist Edge-Verarbeitung notwendig, und wann reicht reine Cloud-Ingestion? Wo endet das, was Azure oder Microsoft Fabric bereits mitbringen, und wo beginnt die projektspezifische Entwicklung? Welche Entwicklungspraktiken sorgen dafür, dass die Plattform langfristig wartbar bleibt? Und welche Entscheidungsmuster führen immer wieder zu unnötiger Komplexität oder vermeidbaren Kosten?
Edge vs. Cloud: Die zentrale Architekturfrage
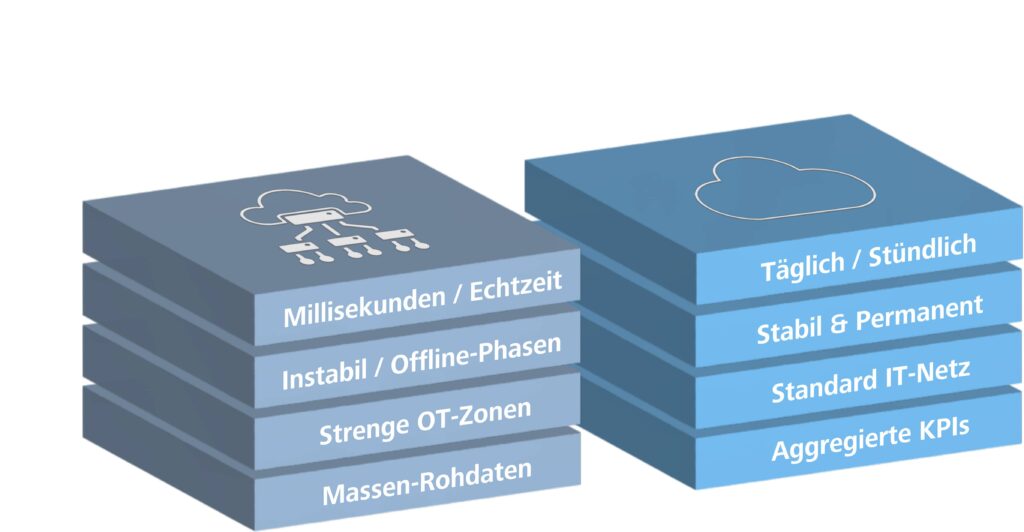
Wann reicht reine Cloud-Ingestion, wann brauchen wir Edge? Die Antwort hängt von Latenz, Netzwerkstabilität und OT-Sicherheitszonen ab. Bei täglichen Berichten, stabiler Netzanbindung und IT-seitigen Datenquellen können Sie direkt in die Cloud gehen. Aber bei strengen Latenzanforderungen, instabilen Internet-Verbindungen, harten OT-Sicherheitszonen oder hohem Datenvolumen ist Edge die bessere Wahl. Für echte Regelkreise im Millisekundenbereich bleibt die Automatisierungsebene zuständig; die Datenplattform unterstützt hier vor allem Monitoring, Auswertung und Koordination. In unserer Arbeit mit Fertigungsunternehmen erleben wir diese Entscheidung regelmäßig: Sie ist selten rein technisch, sondern berührt Sicherheitsrichtlinien, Betriebskonzepte und organisatorische Grenzen.
Für die Edge-Umsetzung gibt es im Microsoft-Ökosystem heute zwei vergleichbare Ansätze mit unterschiedlichen Schwerpunkten. Azure IoT Edge eignet sich besonders, wenn containerisierte Logik auf einzelnen Geräten oder Gateways laufen soll, etwa für lokale Vorverarbeitung, Filterung, Inferenz oder Offline-Pufferung. Azure IoT Operations ist stärker, wenn Sie auf Azure Arc und Kubernetes eine standardisierte industrielle Edge-Datenebene mit MQTT-Broker, OPC-UA-Anbindung und Datenflüssen zu Zielen wie Azure Event Hubs, Azure Data Lake Storage (ADLS) Gen2, Microsoft Fabric OneLake oder Azure Data Explorer aufbauen wollen. Was Microsoft Ihnen in beiden Fällen nicht abnimmt: die Auswahl der Protokolle, die Filterlogik, das Failover-Verhalten und die OT-Integration. Hier müssen OT, IT und Datenteam zusammenarbeiten: OT definiert Latenz- und Sicherheitsanforderungen, IT betreibt die Edge-Infrastruktur, und das Datenteam entwickelt die Verarbeitungslogik.
Wo Azure schlüsselfertig ist und wo die Projektarbeit beginnt
Azure ist kein schlüsselfertiges „Industrie 4.0-Produkt“, sondern ein mächtiges Ökosystem von Bausteinen. Im PaaS-Ansatz liefert Microsoft starke Unterstützung für die Infrastruktur: Azure IoT Hub verwaltet den Gerätelebenszyklus, Azure Data Factory bringt Hunderte Standard-Konnektoren mit, ADLS Gen2 und offene Tabellenformate wie Apache Iceberg oder Delta Lake bilden ein solides Lakehouse-Fundament, Azure Data Explorer deckt interaktive Zeitreihen- und Telemetrieanalyse ab, Power BI integriert nahtlos, und Azure Monitor überwacht alles zentral. Im stärker integrierten Weg mit Microsoft Fabric übernimmt OneLake die gemeinsame Speicherbasis, Fabric Data Factory die Datenintegration, Lakehouse die Verarbeitung und Power BI die Nutzung in derselben Plattform.
Doch OT-spezifische Konnektoren brauchen oft Partner oder Individualentwicklung. Die Semantik – was bedeutet „Maschinenstatus“, welche Tags, welche Einheiten? – ist reine Projektarbeit. Das Bronze/Silver/Gold-Design, Datenverträge, Datenqualitätsprüfungen und domänenspezifische Anwendungen entwickeln Sie selbst. Microsoft nimmt Ihnen Infrastrukturarbeit ab, aber fachliche Architektur, Datenmodellierung und Governance bleiben Ihre Verantwortung.
Moderne Softwareentwicklung: Nicht optional, sondern Pflicht
Ein oft unterschätzter Aspekt: Eine industrielle Datenplattform ist Software und muss auch so behandelt werden. Ohne moderne Entwicklungspraktiken wird sie schnell unbeherrschbar. Bei ZEISS Digital Innovation vereinen wir bewusst Software-Engineering-Praktiken mit der Welt der industriellen Daten – nicht als Selbstzweck, sondern um Projekte langfristig wartbar und skalierbar zu halten.
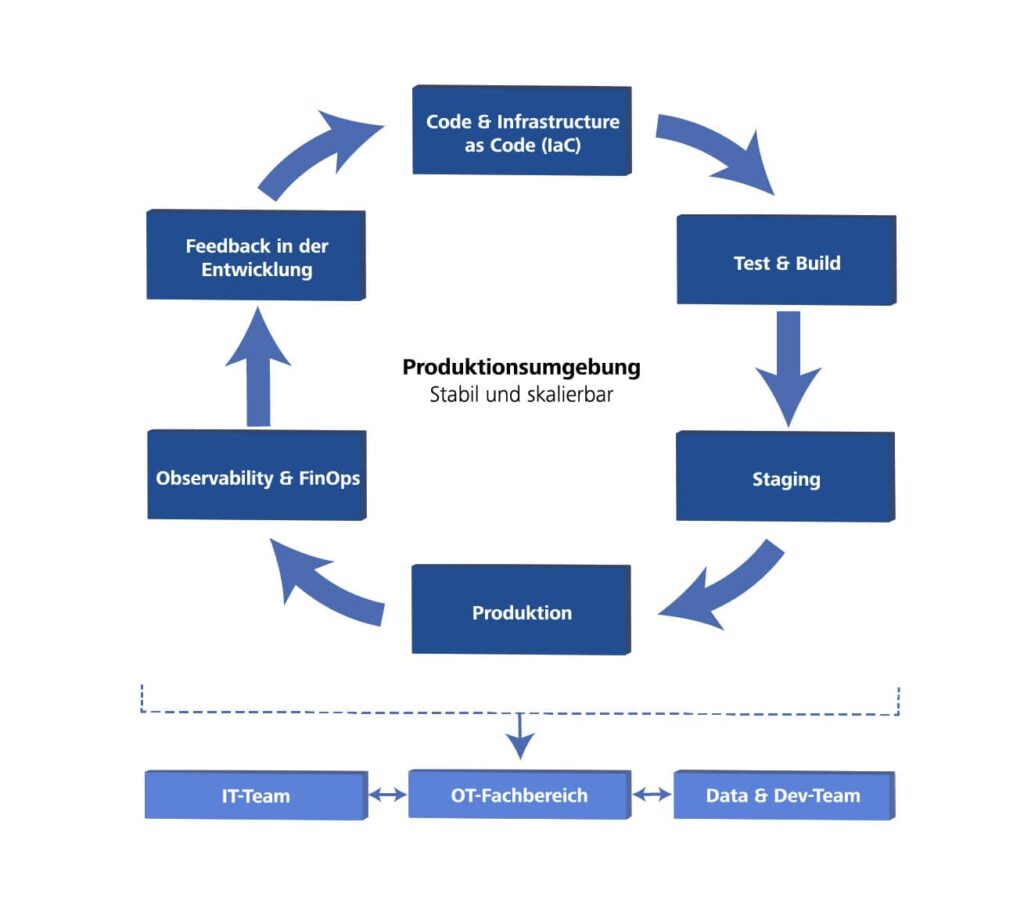
Der Grundstein dafür ist die Automatisierung von Infrastruktur und Deployments. Statt Azure-Ressourcen manuell zusammenzuklicken, wird die gesamte Umgebung als Infrastructure as Code (IaC) (z. B. mit Bicep oder Terraform) beschrieben. So lassen sich selbst komplexe Setups für mehrere Werke konsistent und versioniert ausrollen. Hand in Hand damit geht Continuous Integration and Continuous Delivery (CI/CD) für Daten-Pipelines: Azure Data Factory Pipelines oder Azure Databricks Notebooks werden wie klassischer Code behandelt, durchlaufen automatisierte Unit- und Integrationstests mit realistischen Testdaten und wandern über saubere Staging-Umgebungen in die Produktion. Fehlerhafte Versionen lassen sich so in Minuten zurückrollen, bevor sie unbemerkt Schaden anrichten.
Sobald die Plattform produktiv läuft, schließt Observability den Kreis, und zwar in technischer wie wirtschaftlicher Hinsicht. Tools wie Azure Monitor und Azure Log Analytics überwachen nicht nur, ob Pipelines fehlerfrei laufen und Latenzen im Rahmen bleiben, sondern prüfen auch kontinuierlich die Datenqualität. Proaktive Warnungen melden Probleme, bevor Nutzer sie bemerken. Eng damit verzahnt ist die Kostenüberwachung: Azure Cost Management verfolgt Ausgaben nicht nur pauschal, sondern bricht sie mithilfe von Cost-Allocation-Tags auf Anwendungsfälle, Werke oder Fachbereiche herunter. Nur durch diese Transparenz lässt sich fundiert entscheiden, welcher Anwendungsfall wirtschaftlich sinnvoll ist und wo Optimierungen lohnen. Kostenbewusstsein wird so zum integralen Bestandteil der Plattform-Governance.
Die Rollen sind dabei klar verteilt: Die IT verantwortet Landing Zones, IaC und CI/CD-Setup. Data- und Dev-Teams entwickeln Pipelines und ML-Modelle, während die OT die Anforderungen liefert und in der Staging-Umgebung testet. Nur in diesem Zusammenspiel entsteht eine zuverlässig wartbare Plattform.
Data Governance: Kein nachgelagertes Extra
Data Governance verdient einen eigenen Artikel, aber die Kernbotschaft ist klar: Governance muss von Anfang an mitgedacht werden. Es geht um Datenhoheit (Wer ist verantwortlich?), Datenqualität (Welche Standards gelten?), Zugriffskontrolle (Wer darf was sehen?) und Compliance (DSGVO, Audit-Anforderungen).
Azure unterstützt mit Microsoft Purview für Datenkataloge und Lineage, mit Azure RBAC (Role-Based Access Control) und Microsoft Entra ID für fein granulare Zugriffssteuerung, mit Landing Zones für klare Domänen-Verantwortung und mit Azure Policy für erzwungene Standards. Gerade im Bereich industrieller Daten ist Governance kritisch: Produktionsdaten können reguliert sein (Pharma, Automotive), OT-Daten dürfen nicht in falsche Hände, und ohne Vertrauen in die Datenqualität nutzt niemand die Plattform. Azure und Microsoft Fabric liefern die Werkzeuge, aber die Governance-Strategie – Rollen, Prozesse, Standards – müssen Sie selbst definieren.
Typische Fehlentscheidungen – und was man daraus lernt
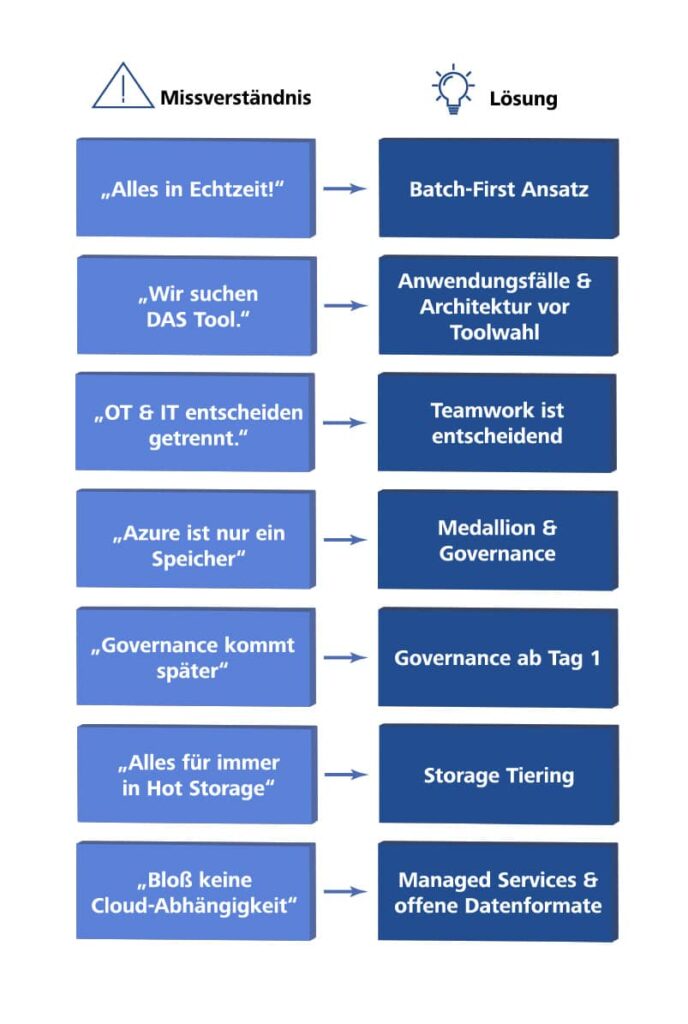
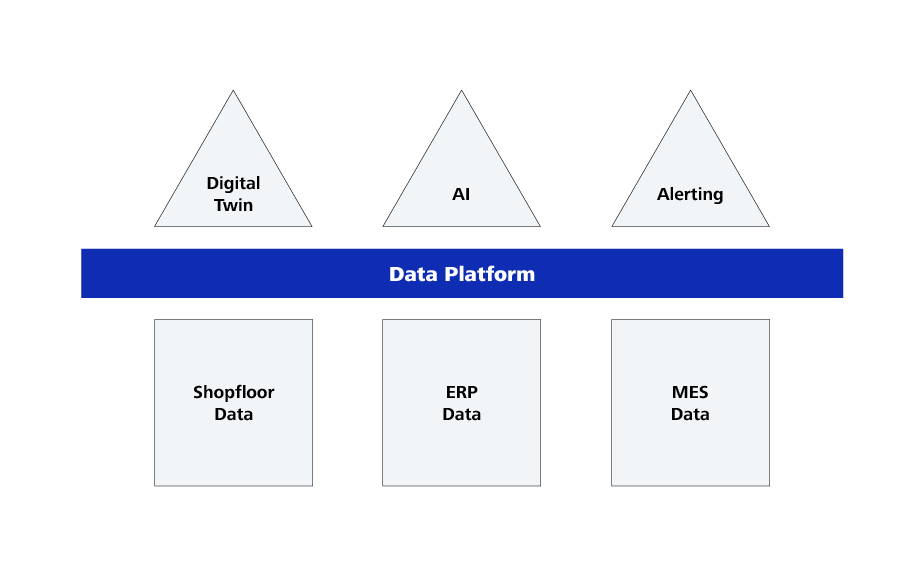
Abbildung 2: Prinzipien der modernen Softwareentwicklung
In der Zusammenarbeit mit unseren Kunden begegnen uns immer wieder ähnliche Herausforderungen. Diese zu kennen und frühzeitig anzusprechen, gehört zu unserer Rolle als Partner.
„Wir machen alles in Echtzeit“ ist ein Klassiker. Jedes Dashboard soll sofort aktualisiert sein, auch wenn tägliche Updates völlig ausreichen würden. Das Ergebnis: unnötige Komplexität, höhere Kosten, längere Entwicklungszeit. Die entscheidende Frage lautet: Welche Entscheidungen werden tatsächlich in Echtzeit getroffen? Oft ist ein Minimum Viable Product (MVP) mit Batch-Verarbeitung der bessere Start.
„Wir suchen das eine Azure-Produkt, das alles löst“ offenbart ein Missverständnis. Es gibt kein „Produkt“, sondern ein Ökosystem von Bausteinen. Eine Plattform entsteht durch Architektur, nicht durch Tool-Auswahl. Definieren Sie zuerst Anwendungsfälle und Architektur, dann wählen Sie passende Bausteine.
„OT und IT entscheiden getrennt“ führt zu Insellösungen. OT beschafft Edge-Gateways, IT baut die Cloud-Plattform, das Datenteam erfährt nichts – bis die Systeme inkompatibel sind. Industrielle Datenverarbeitung ist Teamarbeit. Gemeinsame Kickoffs, gemeinsame Architektur-Vision und klare End-to-End-Verantwortung sind essenziell.
„Azure ist nur ein Speicher“ ist der sichere Weg zum Datensumpf. Wenn Daten „irgendwie“ in ADLS Gen2 landen ohne Struktur, Transformation oder Governance, findet niemand mehr etwas. Die Medaillon-Struktur, Datenqualitätsprüfungen und ein Katalog, etwa mit Microsoft Purview, sind keine Extras, sondern Grundvoraussetzungen.
„Governance kommt später“ ist eine Illusion. Nachträgliche Governance ist deutlich schwerer als Governance von Anfang an. Definieren Sie grundlegende Rollen, Zugriffskontrollen und Benennungskonventionen vom ersten Tag an.
„Alle Daten für immer in Hot Storage“ ist eine klassische Kostenfalle. ADLS Gen2 bietet verschiedene Storage-Tiers – Hot, Cool und Archive – mit deutlich unterschiedlichen Kostenstrukturen. Wer alle historischen Daten dauerhaft im Hot-Tier speichert, verursacht unnötig hohe Speicherkosten. Definieren Sie von Anfang an: Welche Daten brauchen schnellen Zugriff, welche werden selten gebraucht, welche dienen nur der Langzeitarchivierung? Azure Lifecycle Management automatisiert dieses Tiering. Gleiches gilt für die Datenauflösung: Nicht jede historische Zeitreihe muss mit voller Auflösung gespeichert werden, Downsampling alter Daten spart Speichervolumen und damit Kosten.
„Wir wollen keine Cloud-Abhängigkeit“ klingt nach Vorsicht, führt aber oft zu teurem Mehraufwand. Wer nur VMs und Open-Source-Komponenten nutzt, verzichtet auf verwaltete Dienste und muss alles selbst betreiben – Patching, Skalierung und Monitoring. Die bessere Frage: Können wir Daten in Standardformaten halten und trotzdem von verwalteten Diensten profitieren?
Fazit: Von der Architektur zur Umsetzung
Eine industrielle Datenplattform auf Azure bedeutet nicht, ein Produkt zu kaufen, sondern eine Architektur zu entwerfen und umzusetzen. Microsoft bietet ein ausgereiftes Ökosystem von Bausteinen, das viel Infrastruktur- und Plattformarbeit abnimmt. Die Herausforderung: die richtigen Bausteine auszuwählen, sinnvoll zu kombinieren und nachhaltige Governance zu schaffen.
Die wichtigsten Prinzipien: Starten Sie vom Anwendungsfall, nicht von der Technologie. Denken Sie in Aufgabenclustern, nicht in Produktlisten. Ein PaaS-Ansatz mit einzelnen Azure-Diensten und ein integrierter SaaS-Ansatz mit Microsoft Fabric sind zwei valide Wege mit unterschiedlichen Stärken. Edge versus Cloud ist eine Architekturentscheidung, keine Tool-Frage. Microsoft liefert die Infrastruktur, nicht Fachlogik. Domänenmodell, Transformationen und Governance bleiben Ihre Verantwortung. Moderne Softwareentwicklung mit IaC, CI/CD und Tests ist Pflicht, kein Extra. Und vor allem: OT, IT und Datenteam müssen zusammenarbeiten. Industrielle Daten sind eine Gemeinschaftsaufgabe.
Genau hier setzen wir als ZEISS Digital Innovation an: Als Partner, der sowohl die Fertigungswelt als auch moderne Cloud-Architekturen versteht. Wir übersetzen zwischen OT, IT und Data, stellen die richtigen Fragen, schaffen klare Architekturen und entwickeln gemeinsam mit unseren Kunden Lösungen, die in der Praxis funktionieren und langfristig wartbar bleiben. Von den Anforderungen über die Implementierung bis zum Betrieb begleiten wir Sie auf dem Weg zu einer skalierbaren, zukunftsfähigen Datenplattform.