Vom Konzept zur Umsetzung
In den vorangegangenen Artikeln haben wir über Architekturkonzepte für industrielle Datenplattformen gesprochen: Brownfield-Herausforderungen, Latenzklassen, Batch versus Streaming, die Medaillon-Architektur und die Frage nach Edge versus Cloud. Doch all diese Konzepte bleiben abstrakt, solange sie nicht in konkrete Technologieentscheidungen münden.
Dieser Artikel dient als Leitfaden, um die richtige technologische Basis für Ihre Fertigung zu finden. Wie übersetzen wir Architekturideen in sinnvolle Entscheidungen auf Microsoft Azure, und zwar aus der Perspektive von OT-, IT- und Datenteams? Auf Azure führen diese Fragen heute häufig zu zwei Grundrichtungen: entweder Platform as a Service (PaaS) mit einem aus Azure-Bausteinen zusammengesetzten Stack oder zu einer stärker integrierten Lösung als Software as a Service (SaaS) mit Microsoft Fabric. Keine dieser Richtungen ist per se überlegen; entscheidend sind Anwendungsfall, Betriebsmodell und vorhandene Kompetenzen. Als ZEISS Digital Innovation begleiten wir Fertigungsunternehmen genau bei dieser Transformation. Dieser Artikel ist bewusst kein Produktkatalog, sondern eine Entscheidungshilfe, die auf unseren Erfahrungen aus realen Projekten basiert. Wir starten vom konkreten Anwendungsfall, stellen die richtigen Fragen und zeigen, in welche Richtung die Antworten auf Azure führen. Dabei wird eines klar werden: Verwaltete Dienste nehmen viel Infrastrukturarbeit ab, aber die fachliche Architektur und Governance bleiben projektspezifische Aufgaben.
Ein wesentlicher Aspekt ist von Anfang an mitzudenken: die Kostenstruktur im täglichen Betrieb. Falsche Architekturentscheidungen – etwa Streaming statt Batch, fehlende Storage-Lifecycle-Policies oder unnötige Datenredundanz – führen schnell zu unerwartet hohen Cloud-Kosten. Aus unserer Projekterfahrung wissen wir: Wirtschaftlich tragfähige Architekturen entstehen, wenn Kosten von Beginn an mitgedacht und sorgfältig im Kontext des Betriebsmodell abgewogen werden.
Kurzer Rückblick: Die Grundprinzipien
Moderne Fertigungsunternehmen kämpfen mit Hunderten bis Tausenden Datenquellen in Silos. Eine industrielle Datenplattform schafft eine zentrale Infrastruktur, um diese Daten zu sammeln, zu verarbeiten und nutzbar zu machen. Dabei haben wir gelernt, dass nicht jeder Anwendungsfall Echtzeitdaten benötigt. Die Spanne reicht von Millisekunden für Prozesssteuerung bis zu Tagen für Management-Reports. Echte Regelkreise im Millisekundenbereich bleiben dabei in der Automatisierungsebene oder am Edge; die zentrale Datenplattform unterstützt vor allem Monitoring, Analyse und Koordination. Die richtige Einordnung spart Kosten und Komplexität.
Die Medaillon-Architektur strukturiert den Datenfluss: Bronze für Rohdaten, Silver für bereinigte Daten, Gold für aggregierte Business-Sichten. Und je nach Latenzanforderung und Netzwerkbedingungen entscheiden wir, ob Batch-Ingestion ausreicht oder Streaming nötig ist, ob wir am Edge vorverarbeiten oder direkt in die Cloud gehen. Mit diesem Grundverständnis können wir nun konkret werden: Wie übersetzen sich diese Prinzipien in konkrete Technologie? Für das Microsoft-Ökosystem bedeutet dies eine gezielte Auswahl passender Dienste.
Von Anwendungsfällen zu Technologieentscheidungen
Starten wir aber nicht mit Technologie, sondern mit typischen Anwendungsfällen aus der Fertigung. Die drei folgenden Szenarien sind als Ausbaustufen mit steigender Komplexität zu verstehen: von einfachem Reporting über laufendes Monitoring bis zu maschinellem Lernen (ML). In der Praxis wächst eine industrielle Datenplattform oft genau in dieser Reihenfolge. Für jeden Fall skizzieren wir zunächst den Lösungsansatz und leiten daraus später passende Technologiepfade ab.
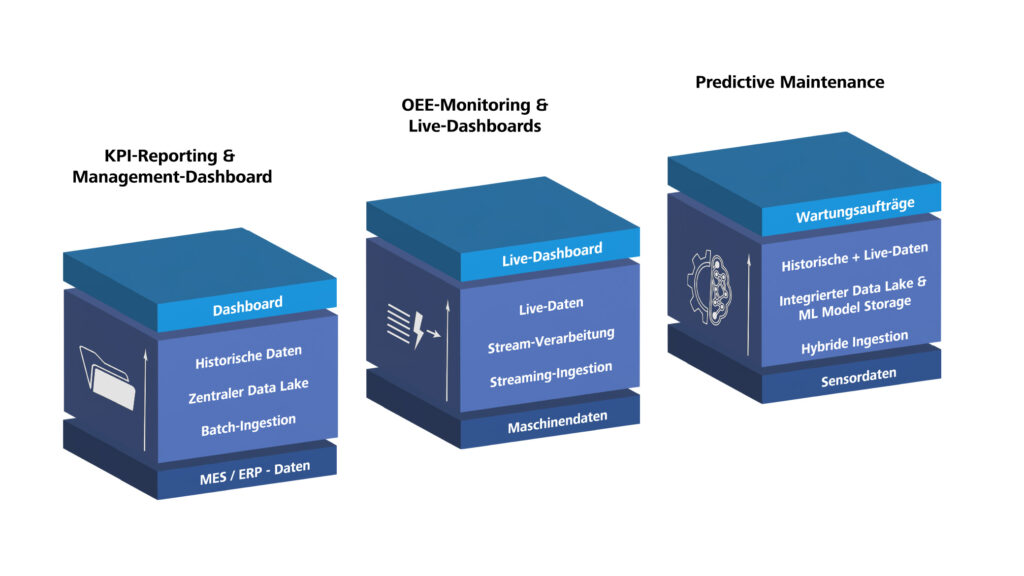
Szenario 1: KPI-Reporting und Management-Dashboards
Zunächst betrachten wir den klassischen Fall: Mitarbeitende der Fertigung und Führungskräfte möchten tägliche oder wöchentliche Berichte über Produktionszahlen, Ausschuss und Energieverbrauch sehen. Die Datenquellen sind überschaubar, die Netzanbindung ist stabil, und eine Aktualisierung im Stunden- oder Tagesrhythmus reicht aus. Hier genügt ein klarer Batch-Ansatz: Daten werden per Batch-Ingestion übernommen, in Bronze, Silver und Gold strukturiert und anschließend für Dashboards bereitgestellt. Der Hauptaufwand liegt weniger in der Technik als in Datenmodellierung, Definition der Key Performance Indicators (KPIs) und Governance.
Szenario 2: OEE-Monitoring und Live-Dashboards
Jetzt wird es anspruchsvoller: Der Mitarbeitende im Leitstand braucht sekunden- bis minutengenaue Anzeigen von Maschinenstatus und Gesamtanlageneffektivität (Overall Equipment Effectiveness, OEE) über mehrere Produktionslinien hinweg. Hier wird Streaming relevant. Maschinendaten werden per Streaming-Ingestion aufgenommen, nahezu in Echtzeit verarbeitet und parallel für historische Analysen abgelegt. Bei instabilen Netzen oder harten OT-Sicherheitszonen empfiehlt sich zusätzliche Edge-Verarbeitung am Shopfloor. Technisch ist das beherrschbar, organisatorisch aber nur erfolgreich, wenn OT, IT und Datenteam den Ende-zu-Ende-Pfad gemeinsam verantworten.
Szenario 3: Predictive Maintenance
Predictive Maintenance vereint das Beste und Anspruchsvollste aus beiden Welten. Sie brauchen Jahre historischer Zeitreihendaten zum Modelltraining und gleichzeitig aktuelle Streams für Vorhersagen, die zurück ins Tagesgeschäft fließen, etwa als Wartungsaufträge im Computerized Maintenance Management System (CMMS). Der passende Ansatz ist hybrid: Streaming-Ingestion für aktuelle Sensordaten, historisierte Zeitreihen im Lakehouse und eine Machine-Learning-Umgebung für Training und Inferenz. Gerade hier zeigt sich der Unterschied zwischen Plattform-Bausteinen und Projektarbeit besonders deutlich: Microsoft liefert Werkzeuge, aber Modellauswahl, Merkmalsbildung und Integration ins CMMS bleiben projektspezifisch.
Azure-Bausteine: Nicht als Produktliste, sondern als Werkzeugkasten
Statt eine endlose Produktliste abzuspulen, schauen wir uns Azure-Dienste nach Aufgabenfeldern an. Das hilft, die richtige Technologie für die jeweilige Herausforderung zu finden.
Grundsätzlich ergeben sich dabei zwei gut begründbare Wege: ein PaaS-Ansatz, bei dem Sie einzelne Dienste je Aufgabenfeld kombinieren, oder ein stärker integrierter Ansatz mit Microsoft Fabric, bei dem einzelne Funktionen enger verzahnt sind. Keiner der Wege ist automatisch besser. Entscheidend sind die gewünschte Integrationsdichte, das Betriebsmodell und die Frage, wie viel Plattformkomposition Ihr Team selbst übernehmen will.
Anbindung von Datenquellen und Datenaufnahme
Wie gelangen Daten von Maschinen und Sensoren ebenso wie Daten aus Datenbanken, Dateien oder Application Programming Interfaces (APIs) in die Plattform?
Tabelle 1: Azure-Bausteine für die Anbindung von Datenquellen und die Datenaufnahme
| Service | Wofür geeignet? | Typische Einordnung |
| Azure IoT Hub | Bidirektionale Kommunikation mit Geräten, Geräteidentitäten und Gerätelebenszyklus | Near-Real-Time |
| Azure Event Hubs | Hochskalierendes Streaming für Millionen Events pro Sekunde, keine Geräteidentität | Near-Real-Time |
| Azure Event Grid | Event-basierte Architekturen, MQTT-Unterstützung, Pub/Sub | Near-Real-Time |
| Azure IoT Edge | Containerisierte Logik auf Geräten oder Gateways, lokale Vorverarbeitung, Offline-Fähigkeit | Edge-nahe Verarbeitung |
| Azure IoT Operations | Edge-Datenebene auf Azure Arc/Kubernetes mit MQTT-Broker, OPC-UA-Anbindung und Streaming | Edge-nahe Verarbeitung |
| Azure Data Factory | Anbindung von Datenbanken, Datei- und API-Quellen, auch aus On-Premises-Umgebungen | Hauptsächlich Batch |
| Partner-Lösungen (z. B. OPC UA Gateways) | Protokoll-Übersetzung und Maschinenanbindung im Brownfield | Abhängig vom Setup |
Für kontinuierliche Datenströme von Maschinen und Sensoren sind Azure IoT Hub, Azure Event Hubs, Azure Event Grid sowie die Edge-Dienste die naheliegenden Bausteine. Azure IoT Hub eignet sich, wenn Sie Geräteidentitäten, sichere Kommunikation und den Gerätelebenszyklus mitdenken müssen. Azure Event Hubs ist dagegen für reines Hochvolumen-Streaming ohne Geräteverwaltung gedacht. Azure Event Grid passt besonders zu MQTT- oder eventgetriebenen Architekturen. Für Edge-Szenarien gibt es heute zwei gleichwertige Wege: Azure IoT Edge passt gut zu containerisierter Logik auf einzelnen Geräten oder Gateways, Azure IoT Operations ist stärker, wenn Sie auf Azure Arc/Kubernetes standardisierte industrielle Datenflüsse mit MQTT, OPC UA und vordefinierten Cloud-Zielen aufbauen möchten.
Für die Batch-Ingestion aus Systemen wie MES, ERP, SQL-Datenbanken, Dateifreigaben, SFTP oder APIs ist dagegen Azure Data Factory meist der passendere Baustein. Mit seinen vielen Konnektoren und einer Self-Hosted Integration Runtime lassen sich auch On-Premises-Quellen in die Plattform einbinden. Damit wird deutlich: Datenaufnahme in die Plattform ist breiter als reine Gerätekommunikation. Die passende Azure-Lösung hängt von Quelle, Latenzklasse und Betriebsmodell ab.
Datenspeicherung und Aufbereitung
Wie speichern wir Daten strukturiert, versionieren sie, historisieren sie und bereiten sie für Analysen vor?
Tabelle 2: Azure-Bausteine für Datenspeicherung und Aufbereitung
| Service | Wofür geeignet? | Medaillon-Rolle |
| Azure Data Lake Storage Gen2 | Skalierbarer, günstiger Objektspeicher für strukturierte und unstrukturierte Daten | Bronze, Silver, Gold |
| Apache Iceberg oder Delta Lake (z. B. auf Azure Databricks) | ACID-Transaktionen, Zeitreisen, Schema-Evolution auf dem Data Lake | Silver, Gold |
| Microsoft Fabric (OneLake und Lakehouse) | Integrierte SaaS-Plattform für Speicherung, Aufbereitung, Nutzung und Governance | Bronze, Silver, Gold |
| Azure Data Explorer | Hochperformante Analyse von Telemetrie-, Log- und Zeitreihendaten | Silver, Gold |
| Azure SQL Database / Azure Cosmos DB | Relationale oder NoSQL-Datenbanken für spezifische Anwendungsfälle | Gold (für Anwendungen) |
Azure Data Lake Storage (ADLS) Gen2 ist der kosteneffiziente Standardspeicher für alle Daten. Ein Tabellenformat wie Apache Iceberg oder Delta Lake kommt hinzu, wenn Sie Transaktionen gemäß ACID-Prinzip (Atomicity, Consistency, Isolation, Durability) und Historisierung mit Schema-Evolution brauchen, typisch für Silver und Gold. Wenn Sie große Telemetrie- und Zeitreihendaten interaktiv analysieren wollen, ist Azure Data Explorer häufig die präzisere Wahl. Microsoft Fabric deckt diese Schicht integrierter ab: OneLake als zentrale Speicherbasis, Lakehouse für Aufbereitung und gemeinsame Datennutzung über mehrere Workloads hinweg. Das Medaillon-Modell mappt so: Bronze speichert Rohdaten unverändert, Silver bereinigt und harmonisiert in Tabellen, Gold aggregiert für Business-Sichten.
Orchestrierung und Verarbeitung
Wie steuern, transformieren und aggregieren wir Datenflüsse – im Batch oder Streaming?
Tabelle 3: Azure-Bausteine für Orchestrierung und Verarbeitung
| Service | Wofür geeignet? | Batch/Streaming |
| Azure Data Factory | Orchestrierung, ETL/ELT, viele Konnektoren, GUI-basiert | Hauptsächlich Batch |
| Azure Databricks | Spark-basiert, flexibel für Batch und Streaming, ML-Workflows | Batch und Streaming |
| Azure Stream Analytics | SQL-basiertes Streaming, einfach für einfache Transformationen | Streaming |
| Microsoft Fabric mit Data Factory / Real-Time Intelligence | Integrierte Orchestrierung, Eventstreams, Eventhouse und Echtzeitanalytik | Batch und Streaming |
| Azure Functions | Serverless, ereignisgetrieben, für kleine Verarbeitungsschritte | Batch und Streaming |
Im PaaS-Ansatz eignet sich Azure Data Factory für klassische ETL-Jobs. Azure Databricks kommt bei komplexen Transformationen, großen Datenmengen und ML-Integration zum Einsatz. Azure Stream Analytics ist passend für einfache Streaming-Szenarien mit SQL, während Azure Functions kleine, ereignisgetriebene Aufgaben übernehmen. Beim Einsatz von Microsoft Fabric decken Data Factory und Real-Time Intelligence große Teile dieser Aufgaben in einer Plattform ab, von der Ingestion über Eventstreams bis zur Analyse in Eventhouse oder Power BI.
Nutzung und Integration
Wie machen wir Daten für Endnutzer und Anwendungen zugänglich?
Tabelle 4: Azure-Bausteine für Nutzung und Integration
| Service | Wofür geeignet? |
| Power BI | Business Intelligence, Dashboards, Reports, Datenanalyse in Fachbereichen |
| Azure API Management | APIs bereitstellen, absichern, monitoren, versionieren |
| Azure Digital Twins | Digitale Zwillinge für komplexe Anlagen, Raum- und Prozessmodelle |
| Azure App Service / Azure Container Apps | Web-Apps, individuelle Benutzeroberflächen, Microservices |
Power BI ist oft die Standardwahl für Dashboards. Bei Microsoft Fabric ist es direkt in der Plattform eingebettet. Azure API Management eignet sich für das Bereitstellen von Daten und ML-Modellen als APIs. Azure Digital Twins ist sinnvoll, wenn Sie Anlagen, Räume oder Prozessbeziehungen semantisch modellieren wollen. Azure App Service oder Azure Container Apps kommen ins Spiel, wenn individuelle Anwendungen oder Microservices benötigt werden.
Technologie-Stack-Beispiele
Um die Theorie greifbar zu machen, folgen drei konkrete Stack-Beispiele zu den eingangs dargestellten Szenarien. Jedes Beispiel zeigt zunächst den PaaS-Ansatz und eine mögliche Alternative mit Microsoft Fabric.
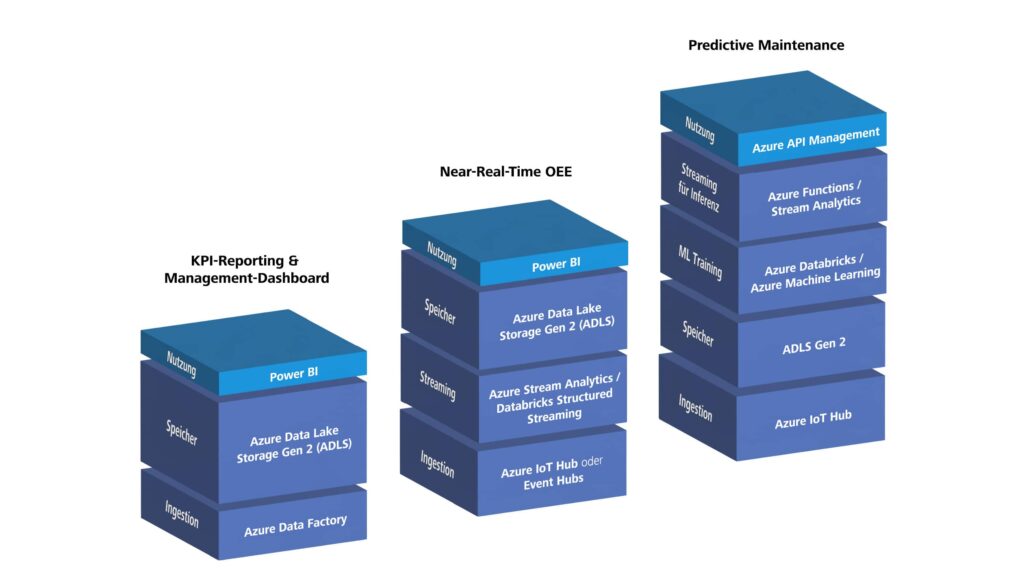
Beispiel 1: Minimaler Stack für Reporting
Anforderungen:
- Tägliche KPI-Berichte für ein Werk
- Datenquellen: MES-Datenbank (SQL), ein paar CSV-Exporte
- Nutzer: Management, Controlling
- Latenz: Tägliche Aktualisierung ausreichend
Azure-Stack:
- Ingestion: Azure Data Factory mit SQL-Konnektor und Blob-Konnektor, bei On-Premises-Quellen meist über Self-Hosted Integration Runtime
- Speicher: ADLS Gen2
- Bronze: Rohdaten aus SQL und CSV
- Silver: Bereinigte Daten (z. B. Zeitstempel normalisiert, Duplikate entfernt), Apache Iceberg als Tabellenformat
- Gold: Aggregierte KPIs (z. B. gefertigte Teile pro Linie, Ausschuss pro Produkt)
- Transformation: Azure Data Factory mit visuell entworfenen Datentransformationen (Mapping Data Flows) oder einfache Kopieraktivitäten
- Nutzung: Power BI liest direkt aus Gold-Layer
Alternative mit Microsoft Fabric: Fabric Data Factory lädt die Daten nach OneLake, ein Lakehouse bildet Bronze, Silver und Gold ab, und Power BI greift direkt auf dieselbe Plattform zu. Dieser Weg ist besonders dann attraktiv, wenn Datenintegration, Governance und BI möglichst eng in einer SaaS-Umgebung verzahnt sein sollen.
Hinweis: Dieser Stack ist nahezu schlüsselfertig. Der Hauptaufwand liegt in der Datenmodellierung, der Definition von KPIs und der Governance (Wer darf welche Daten sehen?).
Beispiel 2: Near-Real-Time OEE für mehrere Linien
Anforderungen:
- Sekunden- bis minutenaktuelle Anzeige von Maschinenstatus und OEE
- Mehrere Produktionslinien, unterschiedliche Maschinentypen
- Anzeige im Leitstand auf großen Monitoren
- Einfache Alarmierung bei Störungen
Azure-Stack:
- Ingestion: Azure IoT Hub oder Azure Event Hubs
- OPC UA Gateway sammelt Daten von Maschinen und sendet an Azure IoT Hub
- Edge (optional): Azure IoT Edge oder Azure IoT Operations
- Azure IoT Edge für lokale Vorverarbeitung, Filterung und Pufferung bei Netzwerkausfall
- Azure IoT Operations für standardisierte Datenflüsse auf Azure Arc/Kubernetes
- Streaming: Azure Stream Analytics oder Structured Streaming in Azure Databricks
- Berechnet OEE in nahezu Echtzeit, schreibt in ADLS Gen2 (Bronze/Silver)
- Speicher: ADLS Gen2 mit Apache Iceberg für Silver/Gold
- Nutzung: Power BI mit Echtzeitstreaming oder individuellen Dashboards (z. B. React App)
Alternative mit Microsoft Fabric: Real-Time Intelligence übernimmt Ingestion, Eventstreams und Echtzeitanalyse, während OneLake und Eventhouse die Datenbasis bilden. Power BI oder Real-Time-Dashboards visualisieren die Ergebnisse. Das ist besonders interessant, wenn Streaming, Analyse und Visualisierung in einer Plattform zusammengeführt werden sollen.
Hinweis: Azure bringt Streaming- und Visualisierungsbausteine mit, aber die Edge-Architektur (Filterlogik, Offline-Handling) und die OEE-Berechnungslogik sind projektspezifisch. OT muss Maschinen anbinden, IT muss Edge-Infrastruktur betreiben, das Datenteam muss die Streaming-Logik entwickeln.
Beispiel 3: Predictive Maintenance mit ML
Anforderungen:
- Vorhersage von Lagerausfällen basierend auf Vibrationsdaten
- Historische Daten über 2 Jahre nötig für Modelltraining
- Aktuelle Streaming-Daten für Vorhersagen
- Vorhersagen sollen ins CMMS fließen
Azure-Stack:
- Ingestion: Azure IoT Hub für Vibrationssensoren
- Speicher: ADLS Gen2 mit Apache Iceberg
- Bronze: Rohdaten (Vibration, Temperatur, etc.)
- Silver: Bereinigte Zeitreihen, Merkmalsbildung für ML
- Gold: Aggregierte Features für ML-Training
- ML: Azure Databricks oder Azure Machine Learning
- Modelltraining mit historischen Daten (Silver/Gold)
- Modell-Deployment als REST-API (z. B. über Azure Machine Learning Endpoints oder Model Serving in Azure Databricks)
- Streaming für Inferenz: Azure Functions oder Azure Stream Analytics ruft Modell-API auf
- Integration: Azure API Management stellt Vorhersagen für CMMS bereit
- Optional: Azure IoT Edge oder Azure IoT Operations bringt Modell oder Vorverarbeitung lokal an die Anlage
Alternative mit Microsoft Fabric: Microsoft Fabric kombiniert OneLake, Data Engineering, Data Science und Power BI in einer Plattform. Für Streaming-nahe Analysen kann Real-Time Intelligence die aktuellen Daten aufnehmen, während Modelle auf den historischen Daten in OneLake trainiert und ausgewertet werden. Wenn Vorhersagen sehr nah an der Anlage entstehen müssen, bleibt der Edge-Teil weiterhin eine eigenständige Architekturentscheidung.
Hinweis: Hier wird der Unterschied zwischen Plattform-Bausteinen und individueller Entwicklung besonders deutlich. Azure liefert ML-Tools, APIs und Bereitstellungsmechanismen, aber das Modell selbst, die Auswahl passender Datenmerkmale, das Konzept zum erneuten Trainieren des Modells und die Integration ins CMMS sind reine Projektarbeit. Ein enger Austausch zwischen Data-Science-Fachleuten, OT und IT ist dabei essenziell.
Zwischenfazit: Vom Anwendungsfall zum Azure-Stack
Die drei Szenarien und der Azure-Werkzeugkasten verdeutlichen: Es gibt keine universelle Antwort auf die Frage, welcher Stack der Richtige ist. Entscheidend ist, konsequent in aktuellen und insbesondere zukünftigen Anwendungsfällen zu denken. Latenzanforderungen, Datenvolumen, Nutzergruppen und organisatorische Rahmenbedingungen bestimmen, welche Kombination aus Ingestion, Speicherung, Verarbeitung und Visualisierung sinnvoll ist.
Microsoft stellt dafür zwei belastbare Richtungen bereit: den komponierten Azure-PaaS-Weg mit Diensten wie Azure IoT Hub, Azure Event Hubs, Azure Data Factory, ADLS Gen2, Azure Data Explorer oder Power BI, und den stärker integrierten SaaS-Weg über Microsoft Fabric mit OneLake, Data Factory, Real-Time Intelligence und Power BI in einer Plattform. Die vorgestellten Stack-Beispiele zeigen typische Einstiegspunkte – vom minimalen Batch-Reporting bis zum ML-getriebenen Predictive-Maintenance-Setup.
Doch mit der Wahl des richtigen Stacks ist es nicht getan. Im zweiten Teil dieses Artikels gehen wir auf die Fragen ein, die über den reinen Tool-Einsatz hinausgehen: Wann brauchen Sie Edge-Verarbeitung, wann reicht die Cloud? Wo hören die verwalteten Dienste auf, und wo beginnt die eigentliche Projektarbeit? Wie gestalten Sie Governance, moderne Softwareentwicklung und Betrieb so, dass die Plattform langfristig tragfähig bleibt? Und welche Fehlentscheidungen sollten Sie von Anfang an vermeiden?