From concept to implementation
In the previous articles, we discussed architecture concepts for industrial data platforms: brownfield challenges, latency classes, batch versus streaming, the Medallion Architecture, and the question of edge versus cloud. But all these concepts remain abstract until they lead to concrete technology decisions.
This article is a guide to finding the right technology foundation for your manufacturing environment. How do we translate architecture ideas into sensible decisions on Microsoft Azure from the perspective of OT, IT, and data teams? Using Azure, these questions often lead to two main directions today: either Platform as a Service (PaaS) with a stack made up of Azure building blocks, or a more integrated Software as a Service (SaaS) solution with Microsoft Fabric. Neither direction is inherently superior; what matters are the use case, the operating model, and the skills that already exist. At ZEISS Digital Innovation, we support manufacturing companies in exactly this transformation. This article is intentionally not a product catalog, but a decision guide based on our experience from real projects. We start from the specific use case, ask the right questions, and show which direction the answers point to on Azure. One thing becomes clear: managed services remove much of the infrastructure work, but domain architecture and governance remain project-specific tasks.
One important point must be considered from the start: the cost structure in day-to-day operation. Wrong architecture decisions, such as streaming instead of batch, missing storage lifecycle policies, or unnecessary data redundancy, quickly lead to unexpectedly high cloud costs. From our project experience, we know this: economically sound architectures emerge when cost is considered from the beginning and weighed carefully in the context of the operating model.
A brief recap: the basic principles
Modern manufacturing companies struggle with hundreds to thousands of data sources in silos. An industrial data platform creates a central infrastructure to collect, process, and use this data. We have learned that not every use case needs real-time data. The range goes from milliseconds for process control to days for management reports. True closed loops in the millisecond range remain in the automation layer or at the edge; the central data platform mainly supports monitoring, analysis, and coordination. The right classification saves cost and complexity.
The Medallion Architecture structures the data flow: Bronze for raw data, Silver for cleaned data, Gold for aggregated business views. And depending on latency requirements and network conditions, we decide whether batch ingestion is sufficient or streaming is necessary, and whether we preprocess data within edge or send it directly to the cloud. With this basic understanding, we can now get specific: How do these principles translate into actual technology? In the Microsoft ecosystem, this means a focused selection of suitable services.
From use cases to technology decisions
But let us not start with technology. Let us start with typical manufacturing use cases. The following three scenarios should be understood as stages of expansion with increasing complexity: from simple reporting to ongoing monitoring to machine learning (ML). In practice, an industrial data platform often grows in exactly this sequence. For each case, we first outline the solution approach and then derive suitable technology paths from it.
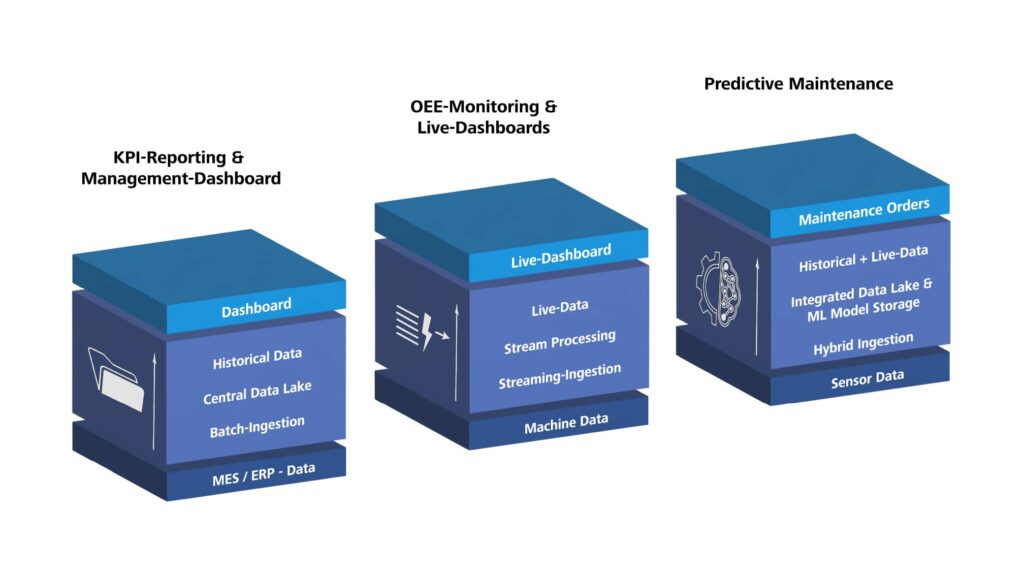
Scenario 1: KPI Reporting and Management Dashboards
Let us first look at the classic case: manufacturing staff and managers want daily or weekly reports on production figures, scrap, and energy consumption. The data sources are manageable, network connectivity is stable, and an update every hour or every day is enough. Here, a clear batch approach is sufficient: data is loaded through batch ingestion, structured in Bronze, Silver, and Gold, and then provided for dashboards. The main effort lies less in the technology than in data modeling, KPI definition, and governance.
Scenario 2: OEE Monitoring and Live Dashboards
Now it becomes more demanding: staff in the control room need second- to minute-level views of machine condition and Overall Equipment Effectiveness (OEE) across several production lines. This is where streaming becomes relevant. Machine data is captured through streaming ingestion, processed almost in real time, and stored in parallel for historical analysis. In unstable networks or strict OT security zones, additional edge processing on the shop floor is recommended. Technically this is manageable, but organizationally it only succeeds when OT, IT, and the data team share responsibility for the end-to-end path.
Scenario 3: Predictive Maintenance
Predictive maintenance combines the best and the most demanding parts of both worlds. You need years of historical time-series data for model training and, at the same time, current streams for predictions that flow back into day-to-day operations, for example as maintenance orders in the Computerized Maintenance Management System (CMMS). The right approach is hybrid: streaming ingestion for current sensor data, historical time-series data in the Data Lakehouse, and a machine learning environment for training and inference. This is exactly where the difference between platform building blocks and project work becomes especially clear: Microsoft provides tools, but model selection, feature engineering, and integration into the CMMS remain project-specific.
Azure Building Blocks: not as a product list, but as a toolbox
Instead of going through an endless product list, let us look at Azure services by task area. This makes it easier to find the right technology for each challenge.
In principle, this leads to two well-supported paths: a PaaS approach, where you combine individual services for each task area, or a more integrated approach with Microsoft Fabric, where individual functions are more tightly connected. Neither path is automatically better. What matters are the desired level of integration, the operating model, and the question of how much platform composition your team wants to take on itself.
Connecting data sources and ingesting data
How does data from machines and sensors, as well as data from databases, files, or Application Programming Interfaces (APIs), get into the platform?
Table 1: Azure building blocks for connecting data sources and ingesting data
| Service | Best suited for? | Typical classification |
| Azure IoT Hub | Bidirectional communication with devices, device identities, and device lifecycle | Near real-time |
| Azure Event Hubs | Highly scalable streaming for millions of events per second, no device identity | Near real-time |
| Azure Event Grid | Event-based architectures, MQTT support, Pub/Sub | Near real-time |
| Azure IoT Edge | Containerized logic on devices or gateways, local preprocessing, offline capability | Edge processing |
| Azure IoT Operations | Edge data layer on Azure Arc/Kubernetes with MQTT broker, OPC UA connectivity, and streaming | Edge processing |
| Azure Data Factory | Connection to databases, file and API sources, including from on-premises environments | Mainly batch |
| Partner solutions (e.g. OPC UA gateways) | Protocol translation and machine connectivity in Brownfield environments | Depends on the setup |
For continuous data streams from machines and sensors, Azure IoT Hub, Azure Event Hubs, Azure Event Grid, and edge services are the obvious building blocks. Azure IoT Hub is suitable when you need device identities, secure communication, and device lifecycle management. Azure Event Hubs, in contrast, is designed for pure high-volume streaming without device management. Azure Event Grid is especially suitable for MQTT or event-driven architectures. For edge scenarios, there are currently two equally valid paths: Azure IoT Edge is a good fit for containerized logic on individual devices or gateways, while Azure IoT Operations is stronger when you want to build standardized industrial data flows with MQTT, OPC UA, and predefined cloud targets on Azure Arc/Kubernetes.
For batch ingestion from systems such as MES, ERP, SQL databases, file shares, SFTP, or APIs, Azure Data Factory is usually the more suitable building block. With its many connectors and a self-hosted integration runtime, on-premises sources can also be connected to the platform. This shows that data ingestion into the platform is broader than pure device communication. The right Azure solution depends on the source, the latency class, and the operating model.
Data storage and preparation
How do we store data in a structured way, version it, keep its history, and prepare it for analysis?
Table 2: Azure building blocks for data storage and preparation
| Service | Best suited for? | Medallion role |
| Azure Data Lake Storage Gen2 | Scalable, cost-efficient object storage for structured and unstructured data | Bronze, Silver, Gold |
| Apache Iceberg or Delta Lake (e.g. on Azure Databricks) | ACID transactions, time travel, schema evolution on the Data Lake | Silver, Gold |
| Microsoft Fabric (OneLake and Lakehouse) | Integrated SaaS platform for storage, preparation, usage, and governance | Bronze, Silver, Gold |
| Azure Data Explorer | High-performance analysis of telemetry, log, and time-series data | Silver, Gold |
| Azure SQL Database / Azure Cosmos DB | Relational or NoSQL databases for specific use cases | Gold (for applications) |
Azure Data Lake Storage (ADLS) Gen2 is the cost-efficient standard storage for all data. A table format such as Apache Iceberg or Delta Lake is added when you need ACID (Atomicity, Consistency, Isolation, Durability) transactions and historical tracking with schema evolution, which is typical for Silver and Gold. If you want to analyze large telemetry and time-series datasets interactively, Azure Data Explorer is often the more precise choice. Microsoft Fabric covers this layer in a more integrated way: OneLake as the shared storage foundation, Lakehouse for data preparation, and shared data use across several workloads. The Medallion model maps as follows: Bronze stores raw data unchanged, Silver cleans and harmonizes it in tables, Gold aggregates it for business views.
Orchestration and processing
How do we control, transform, and aggregate data flows, in batch or in streaming?
Table 3: Azure building blocks for orchestration and processing
| Service | Best suited for? | Batch/Streaming |
| Azure Data Factory | Orchestration, ETL/ELT, many connectors, GUI-based | Mainly batch |
| Azure Databricks | Spark-based, flexible for batch and streaming, ML workflows | Batch and Streaming |
| Azure Stream Analytics | SQL-based streaming, simple for straightforward transformations | Streaming |
| Microsoft Fabric with Data Factory / Real-Time Intelligence | Integrated orchestration, event streams, Eventhouse, and real-time analytics | Batch and Streaming |
| Azure Functions | Serverless, event-driven, for small processing steps | Batch and Streaming |
In the PaaS approach, Azure Data Factory is suitable for classic ETL jobs. Azure Databricks comes into play for complex transformations, large data volumes, and ML integration. Azure Stream Analytics is a good fit for simple streaming scenarios with SQL, while Azure Functions handle small, event-driven tasks. When using Microsoft Fabric, Data Factory and Real-Time Intelligence cover large parts of these tasks within one platform, from ingestion through event streams to analysis in Eventhouse or Power BI.
Usage and integration
How do we make data accessible to end users and applications?
Table 4: Azure building blocks for usage and integration
| Service | Best suited for? |
| Power BI | Business intelligence, dashboards, reports, and data analysis in business units |
| Azure API Management | Provide, secure, monitor, and version APIs |
| Azure Digital Twins | Digital twins for complex assets, room models, and process models |
| Azure App Service/ Azure Container Apps | Web apps, custom user interfaces, microservices |
Power BI is often the standard choice for dashboards. With Microsoft Fabric, it is embedded directly in the platform. Azure API Management is suitable for providing data and ML models as APIs. Azure Digital Twins makes sense when you want to model assets, spaces, or process relationships semantically. Azure App Service or Azure Container Apps come into play when custom applications or microservices are needed.
Technology stack examples
To make the theory more concrete, let us look at three specific stack examples for the scenarios introduced above. Each example first shows the PaaS approach and then a possible alternative with Microsoft Fabric.
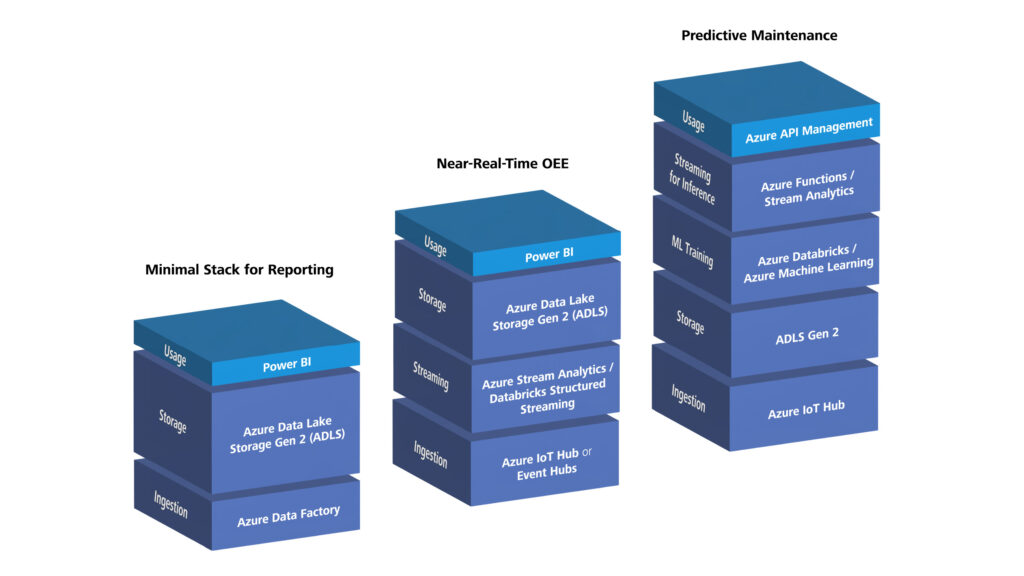
Example 1: minimal stack for reporting
Requirements:
- Daily KPI reports for one plant
- Data sources: MES database (SQL), a few CSV exports
- Users: management, controlling
- Latency: daily update is sufficient
Azure stack:
- Ingestion: Azure Data Factory with SQL connector and Blob connector; for on-premises sources usually through Self-Hosted Integration Runtime
- Storage: ADLS Gen2
- Bronze: raw data from SQL and CSV
- Silver: cleaned data (e.g. normalized timestamps, duplicates removed), Apache Iceberg as the table format
- Gold: aggregated KPIs (e.g. produced parts per line, scrap per product)
- Transformation: Azure Data Factory with visually designed data transformations (mapping data flows) or simple copy activities
- Usage: Power BI reads directly from the Gold layer
Alternative with Microsoft Fabric: Data Factory loads the data into OneLake, a Lakehouse maps Bronze, Silver, and Gold, and Power BI accesses the same platform directly. This path is especially attractive when data integration, governance, and business intelligence should be tightly connected in one SaaS environment.
Note: This stack is almost turnkey. The main effort lies in data modeling, KPI definition, and governance (who may see which data?).
Example 2: near real-time OEE for multiple lines
Requirements:
- Second- to minute-level view of machine condition and OEE
- Multiple production lines, different machine types
- Display in the control room on large monitors
- Simple alerting in case of faults
Azure stack:
- Ingestion: Azure IoT Hub or Azure Event Hubs
- OPC UA gateway collects data from machines and sends it to Azure IoT Hub
- Edge (optional): Azure IoT Edge or Azure IoT Operations
- Azure IoT Edge for local preprocessing, filtering, and buffering during network outages
- Azure IoT Operations for standardized data flows on Azure Arc/Kubernetes
- Streaming: Azure Stream Analytics or Structured Streaming in Azure Databricks
- Calculates OEE almost in real time and writes to ADLS Gen2 (Bronze/Silver)
- Storage: ADLS Gen2 with Apache Iceberg for Silver/Gold
- Usage: Power BI with real-time streaming or custom dashboards (e.g. React app)
Alternative with Microsoft Fabric: Real-Time Intelligence handles ingestion, event streams, and real-time analysis, while OneLake and Eventhouse form the data foundation. Power BI or real-time dashboards visualize the results. This is especially interesting when streaming, analysis, and visualization should be combined in one platform.
Note: Azure provides streaming and visualization building blocks, but the edge architecture (filter logic, offline handling) and the OEE calculation logic are project-specific. OT must connect the machines, IT must operate the edge infrastructure, and the data team must develop the streaming logic.
Example 3: Predictive Maintenance with ML
Requirements:
- Prediction of bearing failures based on vibration data
- Historical data over 2 years needed for model training
- Current streaming data for predictions
- Predictions should flow into the CMMS
Azure stack:
- Ingestion: Azure IoT Hub for vibration sensors
- Speicher: ADLS Gen2 with Apache Iceberg
- Bronze: raw data (vibration, temperature, etc.)
- Silver: cleaned time series, feature engineering for ML
- Gold: aggregated features for ML training
- ML: Azure Databricks or Azure Machine Learning
- Model training with historical data (Silver/Gold)
- Model deployment as REST API (e.g. through Azure Machine Learning endpoints or Model Serving in Azure Databricks)
- Streaming for inference: Azure Functions or Azure Stream Analytics call the model API
- Integration: Azure API Management provides predictions for the CMMS
- Optional: Azure IoT Edge or Azure IoT Operations brings the model or preprocessing locally to the asset
Alternative with Microsoft Fabric: Microsoft Fabric combines OneLake, data engineering, data science, and Power BI in one platform. For streaming-related analyses, Real-Time Intelligence can capture the current data, while models are trained and evaluated on the historical data in OneLake. If predictions must be generated very close to the asset, the edge part remains a separate architecture decision.
Note: This is where the difference between platform building blocks and custom development becomes especially clear. Azure provides ML tools, APIs, and deployment mechanisms, but the model itself, the selection of suitable features, the concept for retraining the model, and the integration into the CMMS are pure project work. Close cooperation between data science experts, OT, and IT is essential here.
Interim conclusion: from use case to Azure stack
The three scenarios and the Azure toolbox make it clear: there is no universal answer to the question of which stack is the right one. The key is to think consistently from current and especially future use cases. Latency requirements, data volume, user groups, and organizational conditions determine which combination of ingestion, storage, processing, and visualization makes sense.
Microsoft provides two solid directions for this: the composed Azure PaaS path with services such as Azure IoT Hub, Azure Event Hubs, Azure Data Factory, ADLS Gen2, Azure Data Explorer, or Power BI, and the more integrated SaaS approach via Microsoft Fabric path with OneLake, Data Factory, Real-Time Intelligence, and Power BI in one platform. The stack examples presented show typical starting points, from minimal batch reporting to an ML-driven predictive maintenance setup.
But choosing the right technology stack is not enough. In the second part of this article, we will address questions that go beyond the mere use of tools: When do you need edge processing and when is the cloud sufficient? Where do managed services end, and where does the actual project work begin? How can governance, modern software development, and operations be designed to ensure the platform remains viable in the long term? And what mistakes should you avoid from the very start?