From the Azure stack to a viable architecture
In the first part of this article, we translated typical manufacturing scenarios, from KPI reporting through OEE monitoring to predictive maintenance, into specific Azure stacks. We structured Azure building blocks to task clusters and demonstrated how data ingestion, storage, processing, and use interact using three example stack combinations.
But a platform does not stand or fall based on tool selection alone. In this second part, we focus on deeper questions: when is edge processing necessary, and when is pure cloud i ngestion enough? Where do the capabilities already provided by Azure or Microsoft Fabric end, and where does project-specific development begin? Which development practices ensure long-term maintainability of the platform? And which decision-making patterns repeatedly lead to unnecessary complexity or avoidable costs?
Edge vs. cloud: the central architecture question
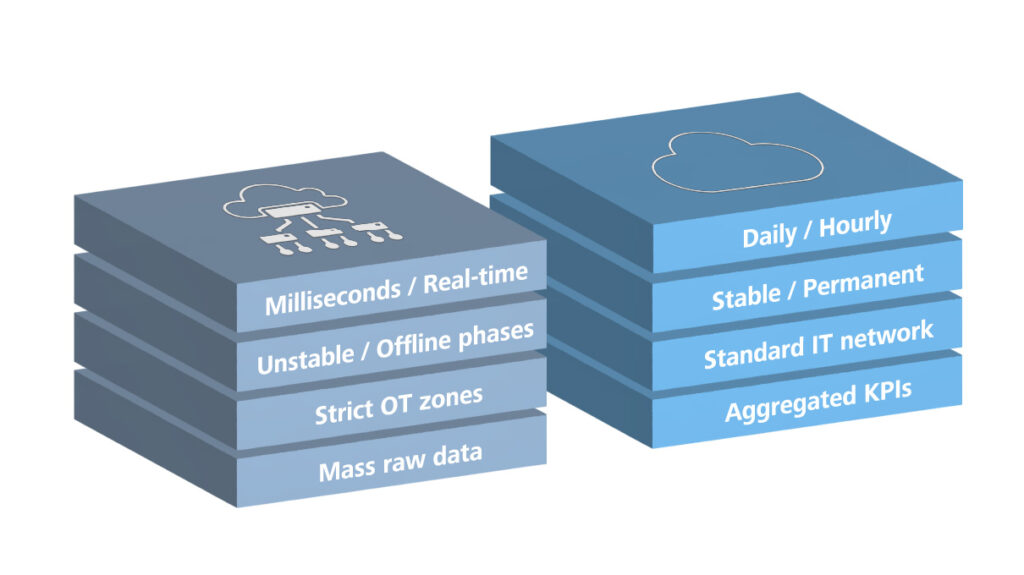
When is pure cloud ingestion enough, and when do we need edge? The answer depends on latency, network stability, and OT security zones. With daily reports, stable network connectivity, and IT-side data sources, you can go directly to the cloud. But with strict latency requirements, unstable internet connections, strict OT security zones, or high data volume, edge is the better choice. Real control loops in the millisecond range remain the responsibility of the automation layer; here the data platform mainly supports monitoring, analysis, and coordination. In our work with manufacturing companies, we see this decision regularly: it is rarely purely technical, but also touches security policies, operating concepts, and organizational boundaries.
For edge implementation, there are currently two comparable approaches in the Microsoft ecosystem, with different strengths. Azure IoT Edge is especially suitable when containerized logic should run on individual devices or gateways, for example for local preprocessing, filtering, inference, or offline buffering. Azure IoT Operations is stronger when you want to build a standardized industrial edge data layer with MQTT broker, OPC UA connectivity, and data flows to targets such as Azure Event Hubs, Azure Data Lake Storage (ADLS) Gen2, Microsoft Fabric OneLake, or Azure Data Explorer on Azure Arc and Kubernetes. What Microsoft does not take off your hands in either case is the choice of protocols, the filtering logic, the failover behavior, and the OT integration. OT, IT, and the data team need to work together here: OT defines latency and security requirements, IT operates the edge infrastructure, and the data team develops the processing logic.
Where Azure is turnkey and where project work begins
Azure is not a turnkey “Industry 4.0 product”, but a powerful ecosystem of building blocks. In the PaaS approach, Microsoft provides strong infrastructure support: Azure IoT Hub manages the device lifecycle, Azure Data Factory includes hundreds of standard connectors, ADLS Gen2 and open table formats such as Apache Iceberg or Delta Lake provide a solid Lakehouse foundation, Azure Data Explorer supports interactive time-series and telemetry analysis, Power BI integrates smoothly, and Azure Monitor monitors everything centrally. In the more integrated SaaS approach via Microsoft Fabric, OneLake provides the shared storage base, Data Factory handles data integration, Lakehouse handles processing, and Power BI handles usage within the same platform.
However, OT-specific connectors often require partners or custom development. Semantics are pure project work: what does “machine condition” mean? Which tags are needed? Which units apply? You develop the Bronze/Silver/Gold design, data contracts, data quality checks, and domain-specific applications yourself. Microsoft handles the infrastructure work, but domain architecture, data modeling, and governance remain your responsibility.
Modern software development: not optional, but mandatory
An often underestimated point is this: an industrial data platform is software and must be treated as such. Without modern development practices, it quickly becomes difficult to manage. At ZEISS Digital Innovation, we deliberately combine software engineering practices with the world of industrial data, not as an end in itself, but to keep projects maintainable and scalable in the long term.
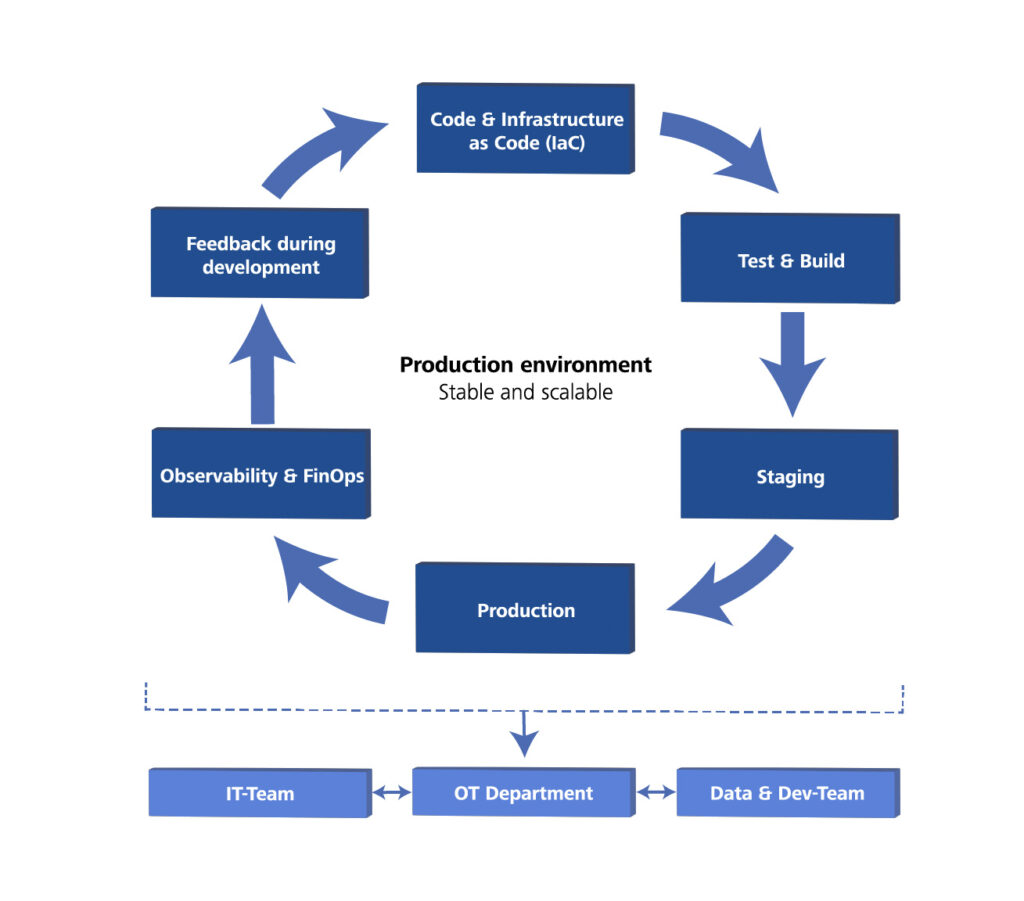
The foundation for this is the automation of infrastructure and deployments. Instead of manually clicking Azure resources together, the entire environment is described as Infrastructure as Code (IaC) (for example with Bicep or Terraform). This allows even complex setups for several plants to be rolled out consistently and under version control. Closely linked to this is Continuous Integration and Continuous Delivery (CI/CD) for data pipelines: Azure Data Factory pipelines or Azure Databricks Notebooks are treated like classic code, go through automated unit and integration tests with realistic test data, and move through clean staging environments into production. Faulty versions can then be reverted within minutes, before they cause unnoticed problems.
Once the platform is live, observability closes the loop, both technically and economically. Tools such as Azure Monitor and Azure Log Analytics do not just monitor whether pipelines run without errors and latencies stay within limits, but also continuously check data quality. Proactive alerts report problems before users notice them. Closely related to this is cost monitoring: Azure Cost Management does not only track spending at a high level, but also breaks it down by use case, plant, or business area with the help of cost allocation tags. Only this transparency allows sound decisions about which use case is economically sensible and where optimization is worthwhile. Cost awareness thus becomes an integral part of platform governance.
The roles are clearly divided: IT is responsible for landing zones, IaC, and the CI/CD setup. Data and development teams build pipelines and ML models, while OT provides the requirements and tests in the staging environment. Only this interaction creates a reliably maintainable platform.
Data governance: not a later add-on
Data governance deserves its own article, but the core message is clear: governance must be built in from the start. It is about data ownership (who is responsible?), data quality (which standards apply?), access control (who may see what?), and compliance (GDPR, audit requirements).
Azure supports this with Microsoft Purview for data catalogs and lineage, Azure RBAC (Role-Based Access Control) and Microsoft Entra ID for fine-grained access control, landing zones for clear domain ownership, and Azure Policy for enforced standards. Governance is especially critical in industrial data: production data may be regulated (pharma, automotive), OT data must not fall into the wrong hands, and without trust in data quality nobody will use the platform. Azure and Microsoft Fabric provide the tools, but you must define the governance strategy, roles, processes, and standards yourself.
Common mistakes – and what we can learn from them
In our work with customers, we keep seeing similar challenges. Knowing them and addressing them early is part of our role as a partner.
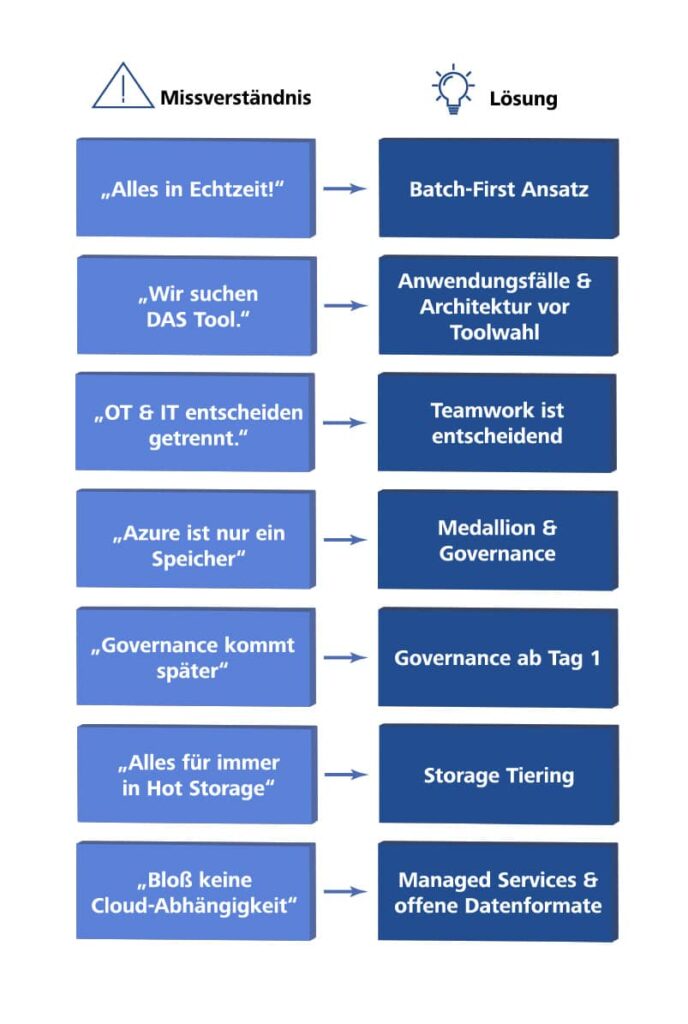
“We do everything in real time” is a classic. Every dashboard is supposed to update immediately, even when daily updates would be fully sufficient. The result: unnecessary complexity, higher costs, longer development time. The key question is: Which decisions are really made in real time? Often, a minimum viable product (MVP) with batch processing is the better start.
“We are looking for the one Azure product that solves everything” reveals a misunderstanding. There is no single “product”, but an ecosystem of building blocks. A platform is created through architecture, not through tool selection. Define use cases and architecture first, then choose the suitable building blocks.
“OT and IT decide separately” leads to isolated solutions. OT procures edge gateways, IT builds the cloud platform, and the data team hears nothing about it until the systems are incompatible. Industrial data processing is teamwork. Joint kickoffs, a shared architecture vision, and clear end-to-end responsibility are essential.
“Azure is only storage” is the safe road to a data swamp. If data lands in ADLS Gen2 “somehow” without structure, transformation, or governance, nobody will find anything later. The Medallion structure, data quality checks, and a catalog, for example with Microsoft Purview, are not extras, but basic requirements.
“Governance comes later” is an illusion. Governance added later is much harder than governance from the start. Define basic roles, access controls, and naming conventions from day one.
“All data stays in hot storage forever” is a classic cost trap. ADLS Gen2 offers different storage tiers, Hot, Cool, and Archive, with clearly different cost structures. If all historical data stays permanently in the Hot tier, storage costs become unnecessarily high. Define from the start: Which data needs fast access, which is rarely used, and which is only for long-term archiving? Azure Lifecycle Management automates this tiering. The same applies to data resolution: not every historical time series needs to be stored at full resolution. Downsampling older data saves storage volume and therefore cost.
“We don’t want cloud dependency” sounds cautious but often leads to expensive extra effort. If you only use VMs and open-source components, you give up managed services and must operate everything yourself: patching, scaling, and monitoring. The better question is: Can we keep data in standard formats and still benefit from managed services?
Conclusion: from architecture to implementation
An industrial data platform on Azure does not mean buying a product, but designing and implementing an architecture. Microsoft offers a mature ecosystem of building blocks that removes much of the infrastructure and platform work. The challenge is to choose the right building blocks, combine them sensibly, and create sustainable governance.
The most important principles are these: Start from the use case, not from the technology. Think in task clusters, not in product lists. A PaaS approach using individual Azure services and an integrated SaaS approach using Microsoft Fabric are two valid options with different strengths. Edge versus cloud is an architecture decision, not a tool question. Microsoft provides the infrastructure, not the business logic. Domain model, transformations, and governance remain your responsibility. Modern software development with IaC, CI/CD, and tests is mandatory, not optional. And above all, OT, IT, and the data team must work together. Industrial data is a shared task.
This is exactly where we at ZEISS Digital Innovation come in: as a partner that understands both the manufacturing world and modern cloud architectures. We translate between OT, IT, and data, ask the right questions, create clear architectures, and work with our customers to develop solutions that work in practice and remain maintainable in the long term. From requirements through implementation to operations, we support you on the path to a scalable, future-ready data platform.