Im ersten Teil der Blogserie haben wir die Herausforderungen bei der Wahl des geeigneten Werkzeugs für die Testautomatisierung skizziert. Im zweiten Teil ging es um die Relevanz und eine mögliche Klassifizierung von Auswahlkriterien der Werkzeuge, die sich zum Teil standardisieren lassen, aber fallweise auch variabel sein müssen. In diesem dritten Artikel stellen wir die Liste der Kriterien, den Kriterienkatalog, dessen Verprobung und die Ergebnisse daraus vor.

Liste der Kriterien
Die folgende Abbildung stellt die finale Liste der Auswahlkriterien dar. Dabei wurden die variablen Kriterien als „SuT-Kriterien“ gekennzeichnet. Die ermittelten Kriterien können angepasst, erweitert und aktualisiert werden.
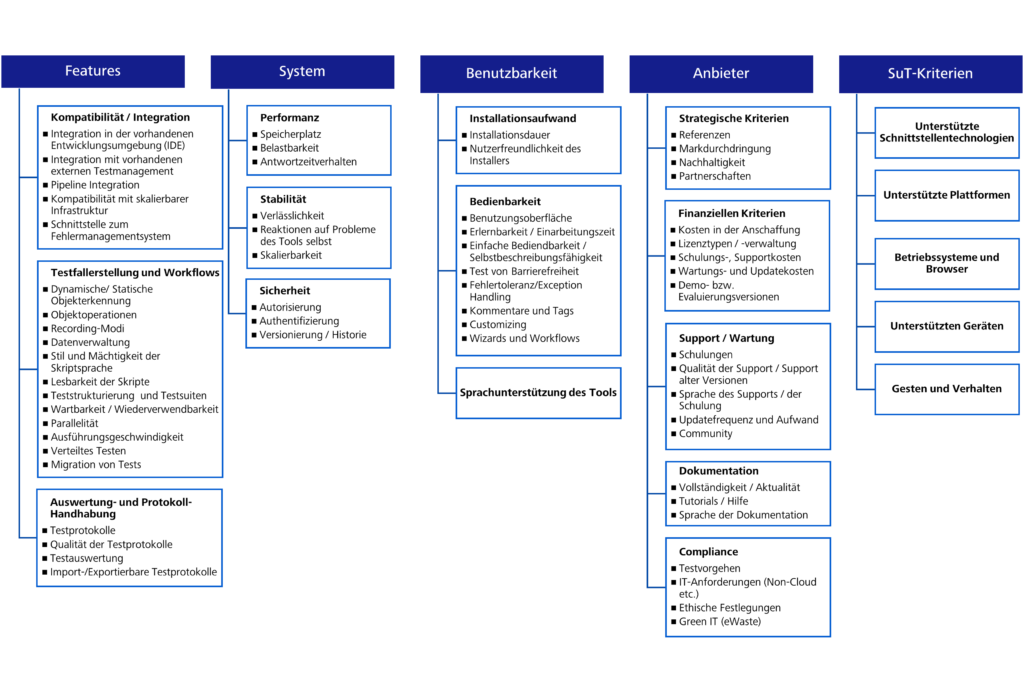
Die Standardkriterien sind in vierzehn (14) Oberkriterien unterteilt, wie z.B. in Kompatibilität, Bedienbarkeit, Performance oder Dokumentation. Den Oberkriterien sind Unterkriterien zugeordnet. So hat das Oberkriterium Dokumentation beispielweise drei (3) Unterkriterien.
Kriterienkatalog
Nachdem die Kriterien feststanden, erstellten wir im nächsten Schritt den eigentlichen Kriterienkatalog. Da verschiedene, mehrdimensionale Ziele in die Entscheidungen einfließen, eignete sich dafür ein systematischer Ansatz. Er lässt eine multi-kriteriale Entscheidungsanalyse (auch Multi Criteria Decision Analysis oder MCDA genannt) zu. Eine dieser Anwendungsformen der multi-kriterialen Entscheidungsanalyse ist die sogenannte Nutzwertanalyse (Gansen 2020, S. 5). Die Nutzwertanalyse findet überall dort Anwendung, wo eine Bewertung vorgenommen oder eine Beurteilung getroffen wird, z. B. im Projektmanagement, im Controlling.

Anforderungen an den Kriterienkatalog
Für die eigentliche Anfertigung des Kriterienkatalogs definierten wir zunächst die Anforderungen. Sie sind im Folgenden tabellarisch in Form von User Stories zusammengefasst und stellen alle notwendigen Arbeitsschritte dar.
| Nr. | User Stories |
|---|---|
| 1 | Als Benutzer möchte ich die Projektstammdaten eingeben, damit ich besser nachvollziehen kann, von wem, wann und für welches Projekt der Katalog erstellt wurde. |
| 2 | Als Benutzer möchte ich einen neuen Katalog erstellen, um eine neue Nutzwertanalyse durchführen zu können. |
| 3 | Als Benutzer möchte ich eine Nutzwertanalyse durchführen, um eine objektive Entscheidung treffen zu können |
| 4 | Als Benutzer möchte ich die Kriterien gerecht und leicht gewichten, um die Relevanz für das Projekt besser steuern zu können. |
| 5 | Als Benutzer möchte ich einen Überblick über die Bewertungsgrundlage haben, um die Lösungsalternativen besser bewerten zu können. |
| 6 | Als Benutzer möchte ich einen klaren Überblick über die durchgeführte Nutzwertanalyse haben, damit ich schnell das Werkzeug mit dem höchsten Nutzen finden kann. |
| 7 | Als Benutzer möchte ich die zuletzt bearbeitete Nutzwertanalyse aufrufen, um sie weiter bearbeiten zu können. |
| 8 | Als Benutzer möchte ich den Katalog exportieren, damit ich diesen weiterleiten kann. |
Aufbau des Kriterienkatalogs
Der Kriterienkatalog wurde mit Excel, sowie Visual Basic for Applications (VBA) entwickelt. Das entwickelte Tool wurde in verschiedene Arbeitsmappen unterteilt, die jeweils eine spezifische Aufgabe widerspiegeln.
Die Einstiegsmaske
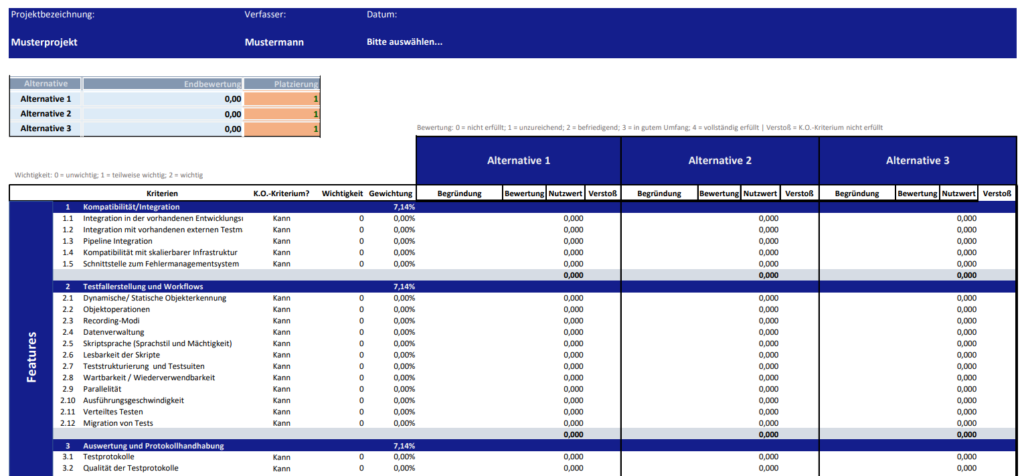
Beim Öffnen der Datei erscheint ein Dialogfenster (siehe Abbildung 3). Zunächst ist auszuwählen, ob der zuletzt bearbeitete Katalog aufgerufen oder ein neuer Katalog erstellt werden soll. Im Falle eines neuen Katalogs wird dann ein Formular angezeigt, das vom Benutzer ausgefüllt werden muss. Die Eingaben des Benutzers zu den SuT-Kriterien werden dem Katalog als variable Kriterien hinzugefügt (siehe Abbildung 4).
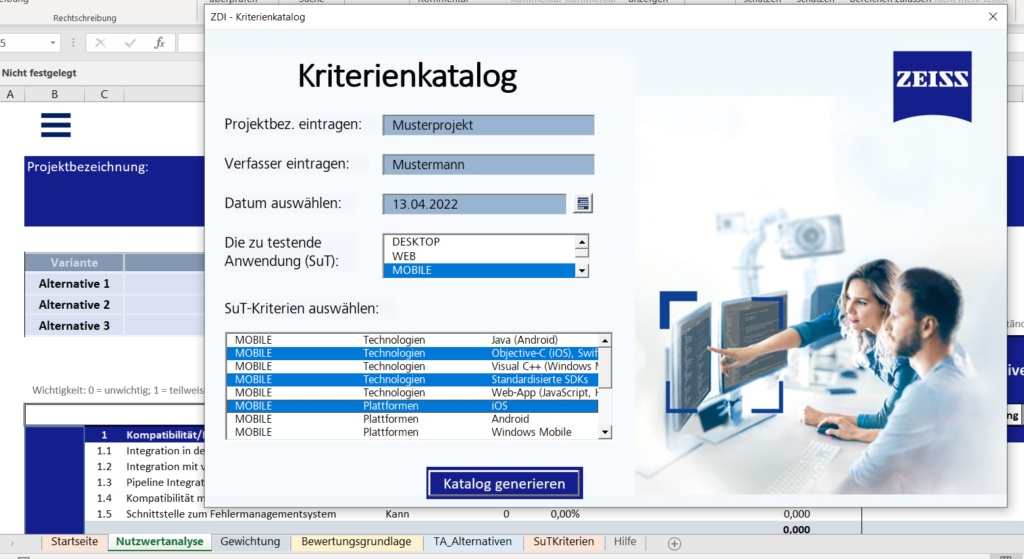
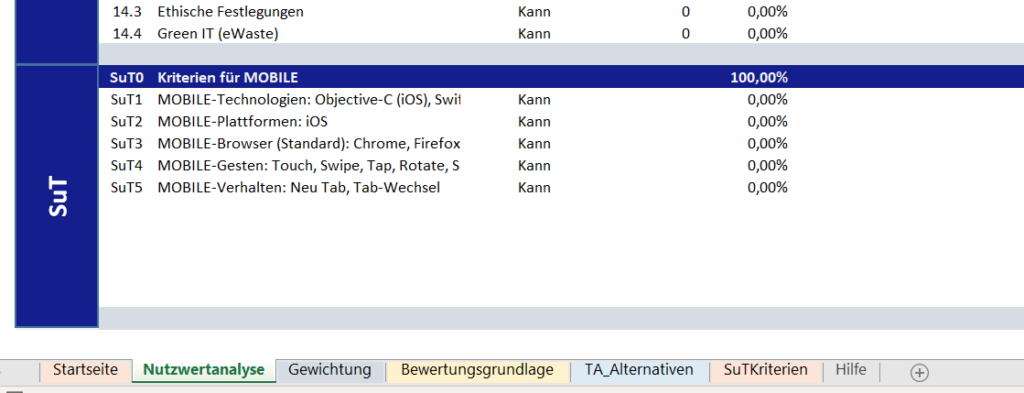
Abbildung 4: Angaben der SuT-Kriterien im Katalog
Die Nutzwertanalyse
Die Nutzwertanalyse wird in vier Schritten durchgeführt. Nach der Identifizierung der Kriterien folgt deren Gewichtung. Danach wird die Kriterienerfüllung gemessen und schließlich der Nutzwert jeder Alternative berechnet (Gansen 2020, S. 6). Sind die Bewertungskriterien sachgerecht beurteilt, kann mit Hilfe der Nutzwertanalyse eine objektive, rationale Entscheidung getroffen werden (Kühnapfel 2014, S. 4).
Gewichtung der Kriterien
Nachdem die Kriterien, insbesondere die variablen Kriterien, ausgearbeitet worden sind, ist eine Gewichtung dieser Kriterien vorzunehmen. Entscheidend ist es, die Kriterien entsprechend ihrer Bedeutung für das spezielle Testautomatisierungsprojekt so zu gewichten, damit sie optimal zur Erreichung der Ziele des Projekts beitragen. Die Summe der Gewichtungen von Standardkriterien und variablen Kriterien soll jeweils 100% ergeben. Bei den Standardkriterien werden zuerst die Oberkriterien mit Hilfe der Paarvergleichsmethode gewichtet, in Form einer Matrix zusammengestellt und paarweise miteinander verglichen (Wartzack 2021, S. 315).
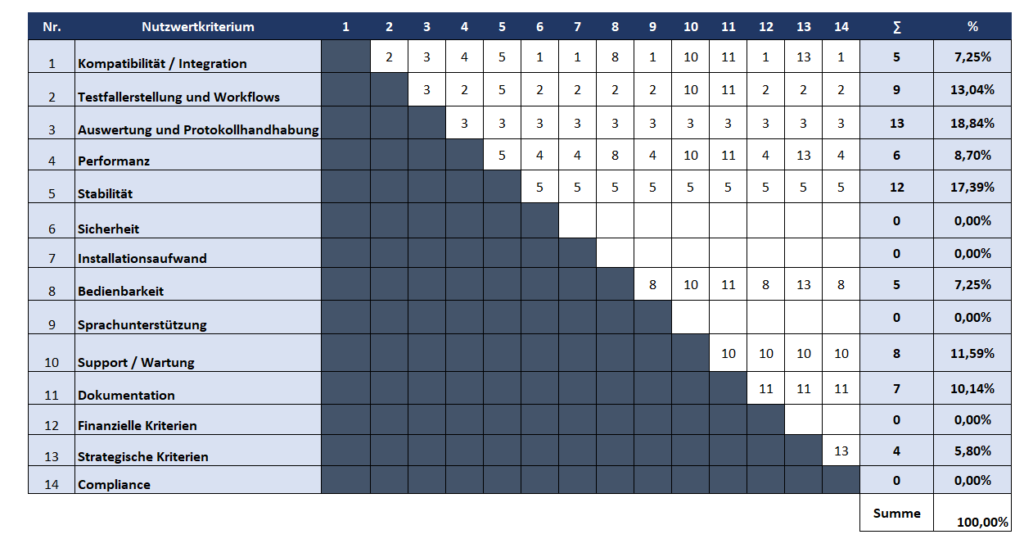
Abbildung 5: Paarweiser Vergleich der Oberkriterien für ein Beispielprojekts
Oberkriterien: Sicherheit, Installationsaufwand, Sprachunterstützung
Anschließend wird die Wichtigkeit jedes Unterkriteriums anhand einer Ordinalskala von null bis zwei bestimmt:
0 = „unwichtig“; 1 = „teilweise wichtig“; 2 = „wichtig“
Die vergebenen Punkte werden addiert und mit der entsprechenden Gewichtung des Oberkriteriums multipliziert. Daraus ergibt sich eine proportionale Gewichtung aller Standardkriterien. Entsprechend wird mit den anderen Ober- bzw. Unterkriterien verfahren. Am Ende beträgt die Summe aller Gewichtungen der Standardkriterien am Ende 100%.
Messung der Kriterienerfüllung
Ausgangspunkt ist die Beantwortung der Frage: „In welchem Maße ist das Kriterium bei der zu bewertenden Testautomatisierungswerkzeugen erfüllt?“. Für den Kriterienerfüllungsgrad wird ein 5-stufiges Modell verwendet, dargestellt in Tabelle 2 (Gansen 2020, S. 17).
| 0 | Nicht erfüllt. |
| 1 | Ist unzureichend / kaum erfüllt. |
| 2 | Ist teilweise erfüllt. |
| 3 | Ist in gutem Umfang erfüllt. |
| 4 | Ist in sehr gutem Umfang erfüllt / vollständig erfüllt. |
Wird die Note 4 vergeben, erfüllt das Tool ein Kriterium vollständig. Im Falle der Nichterfüllung wird die Note 0 vergeben. Auf diese Weise werden die entsprechenden Eigenschaften eines Testautomatisierungswerkzeugs zu einer messbaren Größe.
Aggregation der Bewertungen
Liegt der Erfüllungsgrad jedes Kriteriums vor, kann der Nutzwert berechnet werden. Für den Nutzwert gilt folgende Formel:
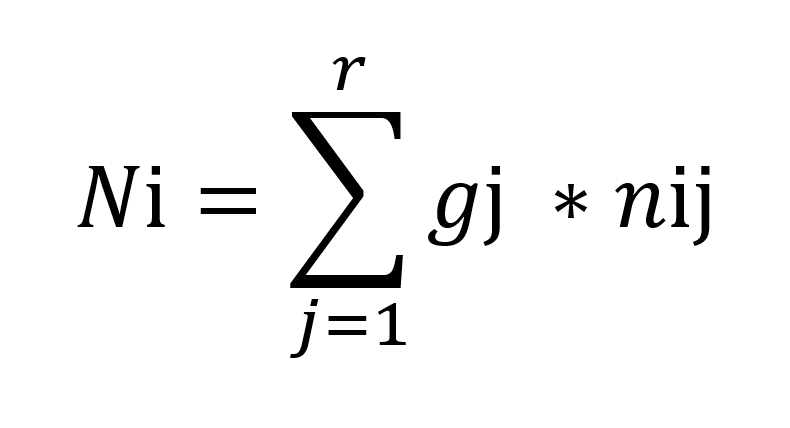
N i = Nutzwerte der Alternative i
Gj = Gewichtung des Kriterium j
nij = Teilnutzen der Alternative i in Bezug auf das Kriteriums j
Die Teilnutzen werden aufsummiert. Das Ergebnis stellt den tatsächlichen Wert eines Werkzeugs dar. Anhand der ermittelten Nutzwerte lässt sich schließlich eine Rangfolge der betrachteten Alternativen aufstellen und für die Entscheidungsfindung nutzen (Gansen 2020, S. 6). Es lässt sich die Werkzeuglösung wählen, die alle Anforderungen am besten erfüllt und die den größten Nutzwert aufweist.
Es gibt Kriterien, die sich als notwendig herausstellen. Diese werden als Ausschlusskriterien (K.O.-Kriterien) bezeichnet. Wenn ein Ausschlusskriterium (K.O.-Kriterium) nicht erfüllt ist (0), liegt ein Verstoß vor, der zum sofortigen Ausschluss einer Alternativlösung führt.

Navigationsleiste und Export
Die Navigationsleiste gibt dem Benutzer einen Überblick über die Struktur des Katalogs und ermöglicht es, sich mühelose darin zu bewegen.
Der Katalog kann als PDF- oder Excel-Datei exportiert und der Speicherort dafür frei gewählt werden.
Ergebnisse der Verprobung des Kriterienkatalogs
Aus der Verprobung konnten folgende relevante Erkenntnisse gewonnen werden:
- Das Zielmodell zur Identifizierung der variablen Kriterien war hilfreich, um gemeinsam Ideen für die SuT-Kriterien zu sammeln.
- Die Anwendung des paarweisen Vergleichs schaffte Klarheit über die wichtigen Faktoren bzw. Oberkriterien. Dank der Darstellung wurde die Vergleichbarkeit hergestellt. So konnten „Bauchentscheidungen“ deutlich reduziert werden.
- Der Kriterienkatalog zeigte einen systematischen, verständlichen und nachvollziehbaren Weg auf, um sich ein geeignetes Werkzeug empfehlen zu lassen. Außerdem konnte festgestellt werden, wo die Stärken des empfohlenen Testautomatisierungsframeworks liegen. So wurde die Abdeckung der Auswahlkriterien mit höherer Relevanz durch das Framework überprüft. Das verringert den Bedarf an Diskussionen innerhalb des Teams, die die endgültige Entscheidung herauszögern würden.
- Aufgrund des für die Bewertung verwendeten 5-Stufen-Modells war ein sehr detailliertes Know-how über Testautomatisierungswerkzeuge erforderlich, das in den meisten Fällen nicht vorhanden ist. Daher würden die Mitarbeiterinnen und Mitarbeiter einige Kriterien nach ihrem Empfinden bzw. Gefühl bewerten. Folglich wären die Bewertungen teilweise subjektiv und die gewählte Alternative letztlich nicht die optimale. Um in diesem Fall ein zuverlässigeres Ergebnis zu erhalten, sollte mindestens eine weitere Person mit Testexpertise zu der Bewertung hinzugezogen werden.
Fazit & Ausblick
In der vorliegenden Arbeit wurde ein strukturierter und systematischer Ansatz für den Auswahlprozess untersucht. Anhand dessen kann ein geeignetes GUI-Testautomatisierungswerkzeug ausgewählt werden, das sowohl den Projekt- als auch den Unternehmensanforderungen genügt. Dabei wurde ein entsprechender Kriterienkatalog entwickelt, der vor allem als Basis für die Transparenz und Nachvollziehbarkeit der Entscheidungsfindung dient.
Es ist geplant, den Kriterienkatalog in weiteren Projekten einzusetzen. Die dabei gesammelten Erfahrungen sollen in die nächste Version 2.0 des Kriterienkatalogs einfließen.
Dieser Beitrag wurde fachlich unterstützt von:

Kay Grebenstein
Kay Grebenstein arbeitet als Tester und agiler QA-Coach für die ZEISS Digital Innovation, Dresden. Er hat in den letzten Jahren in Projekten unterschiedlicher fachlicher Domänen (Telekommunikation, Industrie, Versandhandel, Energie, …) Qualität gesichert und Software getestet. Seine Erfahrungen teilt er auf Konferenzen, Meetups und in Veröffentlichungen unterschiedlicher Art.