Die Asset Administration Shell (AAS) ist ein aufstrebendes Konzept im Zusammenhang mit der Datenhaltung eines Digitalen Zwillings. Es handelt sich dabei um eine virtuelle Repräsentation einer physischen oder logischen Einheit, wie beispielsweise einer Maschine oder eines Produkts. Die AAS ermöglicht es, relevante Informationen über diese Einheit zu sammeln, zu verarbeiten und zu nutzen, um eine effiziente und intelligente Produktion zu gewährleisten. Die Architekturstandardisierung der AAS ermöglicht die Kommunikationen zwischen digitalen Systemen und ist damit die Grundlage für Cyber Physical Systems (CPS). Die Herleitung des Bedarfs eines Digitalen Zwillings in der Industrie finden Sie hier: ZEISS Digital Innovation Blog – Der digitale Zwilling als eine Säule von Industrie 4.0
Dieser Artikel beschäftigt sich mit der konkreten Implementierung eines Beispiels. In einem Szenario wollen wir mit Hilfe einer Referenzimplementierung des Fraunhofer-Institut für Experimentelles Software Engineering IESE (BaSyx Implementierung der AAS v3) einen Austausch von Informationen zwischen zwei beteiligten Partnern herstellen. Beide Beteiligten sind dabei einfachheitshalber innerhalb eines Unternehmens angesiedelt und teilen sich die Infrastruktur.
Hinweis: Auch über Unternehmensgrenzen hinweg kann diese Anwendung verteilt werden. Die dabei zu berücksichtigenden sicherheitskritischen Aspekte sind nicht Teil dieses Szenarios.
Szenario
Werk A ist Hersteller von Messkopfzubehör und stellt u. a. Taster her.
Werk B stellt Messköpfe her und möchte Taster von Werk A an ihrem Messkopf verbauen.
Zusätzlich zur physischen Weitergabe des Tasters müssen Informationen ausgetauscht werden. Die Verkaufsabteilung von Werk A stellt Kontaktinformationen zur Verfügung, damit der technische Einkauf von Werk B Preise sehen und verhandeln kann. Weiterhin muss Werk A z. B. ebenfalls eine Dokumentation zur Verfügung stellen.
Für diesen Austausch der beiden Informationen:
Kontaktdaten und
Dokumentation
soll das Konzept der AAS zum Einsatz kommen.
Infrastruktur
Für unser Szenario wollen wir den Typ 2 der Asset Administration Shell verwenden. Dabei wird die AAS auf Servern zur Verfügung gestellt und es findet nicht ein Austausch von AASX-Dateien statt, sondern eine Kommunikation zwischen den unterschiedlichen Services via REST-Schnittstellen.
In unserem Szenario laufen die unterschiedlichen Services innerhalb eines Kubernetes Clusters in Docker Containern.
Services
Wir nehmen die BaSyx Implementierung her, um die AAS zur Verfügung zu stellen. Genauer gesagt, folgende Komponenten:
AAS Repository,
Submodel Repository,
ConceptDescription Repository,
Discovery Service,
AAS Registry sowie
eine Submodel Registry.
AAS Repository, Submodel Repository und ConceptDescription Repository werden dabei innerhalb eines Containers zur Verfügung gestellt – dem AAS environment.
Technische Umsetzung
Die Kommunikation erfolgt dabei nur mittels API-Aufrufen an die entsprechenden REST-Schnittstellen der Services.
Wir werden dabei einfache Python-Skripte nutzen, um eine Kommunikation darzustellen, bei dem das Herstellerwerk B Informationen zu einem Produkt (hier: ein Taster für einen Sensor) des Komponentenwerks A erhalten will.
Ablauf
Werk B kennt nur eine Asset ID von einem Taster, aber weiß sonst nichts über diese Komponente.
Werk B fragt mit der Asset ID den Discovery Service an, um an eine AAS ID zu gelangen.
Mit dieser AAS ID wird die zentrale AAS Registry angefragt, die den AAS Repository Endpunkt des Werk A zur Verfügung stellt.
Über diesen Endpunkt und die AAS ID erhält Werk B die komplette Asset Administration Shell inkl. der relevanten Submodel-IDs.
Mit diesen Submodel-IDs (u.a. für Kontaktinformationen und Dokumentation) fragt B die Submodel Registry von A an und erhält die Submodel Repository Endpunkte.
B fragt die Submodel-Endpunkte an und erhält die kompletten Submodel-Daten. Zu diesen Daten gehört die gewünschte KontaktiInformation für den Einkäufer und eine komplette Dokumentation zu dem Taster-Asset.
Im Folgenden wird der Ablauf noch einmal im Detail mittels UML-Sequenz-Diagrammen dargestellt.
UML-Sequenz: Erstellung Registrierung AAS im Komponenten-Werk A
Das Werk A ist für die Registrierung ihrer eigenen Komponente zuständig.
Abbildung 1: UML-Sequenz: Erstellung Registrierung AAS im Komponentenwerk A
UML-Sequenz: Anfordern der Komponentendaten
Das Werk B benötigt Daten zu der Komponente und fragt entsprechend in der AAS-Infrastruktur an. Hierbei steht dem Werk B ggf. nur die Asset ID der Komponente zur Verfügung, in unserem Fall die des Tasters.
Abbildung 2: UML-Sequenz: Anfordern der Komponentendaten
Implementierung
Damit der oben beschriebene Ablauf funktioniert, müssen zum einen die erwähnten Services zur Verfügung gestellt werden. Zum anderen müssen Shells und Submodelle angelegt werden und zusätzlich in den Registries hinterlegt werden.
Bereitstellung der Services
Die Bereitstellung erfolgt via Docker Container, die innerhalb eines Kubernetes Clusters laufen. Hierbei bekommt jedes BaSyx Image ein Kubernetes Deployment welches via Kubernetes Replica-Sets die entsprechenden Pods starten. Mittels z. B. Port-Forwarding werden die entsprechenden Ports vom Host erreichbar gemacht. Dieses ist notwendig um die APIs entsprechend von den Beispiel-Python-Skripten anzusprechen.
Die Kubernetes Deployment Konfiguration schaut folgendermaßen aus und ist dabei relativ einfach gehalten. Es existieren vier Deployments mit jeweils einem Replica-Set.
Abbildung 3: Kubernetes-Deployment-Konfiguration
Erzeugen der AAS von Werk A
Werk A möchte z. B. die Kontaktinformationen zu seiner Taster-Komponente zur Verfügung stellen.
Dazu werden Submodelle im AAS Repository erzeugt (hier: im AAS-Environment) und in der Submodel Registry registriert.
Danach wird die Asset Administration Shell im AAS Repository erzeugt und der AAS Registry registriert.
Anschließend wird im AAS Repository die Referenz der Shell hinzugefügt.
Hiermit ist der Registrierungs-Prozess vom Komponentenwerk abgeschlossen.
Anfragen von Kontakt-Informationen vom Werk B
Werk B möchten die Kontakt-Informationen erhalten und fragt entsprechend dem oben beschriebenen Workflow die unterschiedlichen AAS-Services an. Am Ende wird der Submodel-Datensatz abgerufen, der die gewünschten Werte enthält und kann dann z. B. innerhalb eines User-Interfaces zur Verfügung gestellt werden.
Fazit
Die Asset Administration Shell vom Typ 2 ist ein verteiltes System, welches auf die entsprechenden Repositories, Registries und den Discovery Service baut. In unserem Beispiel haben wir nur ein einfaches Submodel-Template für Kontaktdaten verwendet. Allerdings stehen weitaus mehr Templates für viele Anwendungsfälle zur Verfügung.
Die Kommunikation zwischen den Services zur Bereitstellung und zum Abruf der Daten ist relativ unkompliziert möglich, wobei in diesem Szenario Aspekte wie z. B. Sicherheit nicht im Fokus waren.
Die in diesem Artikel beschriebene Beispielimplementierung lässt das enorme Potential des AAS-Konzepts erahnen und regt dazu an, konkrete Umsetzungen zu starten.
Dieser Beitrag wurde verfasst von:
Daniel Brügge
Daniel Brügge arbeitet als Softwareentwickler bei ZEISS Digital Innovation mit dem Fokus auf Cloud-Entwicklung und verteilte Anwendungen.
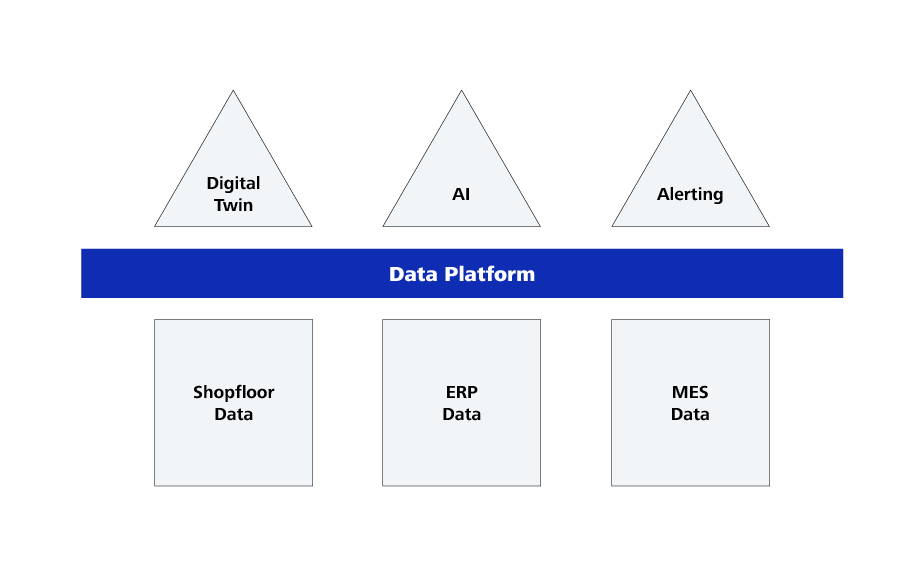
Alle modernen Digitaltechnologien zur Produktionsoptimierung wie Digitale Zwillinge und Künstliche Intelligenz oder klassische Verfahrensweisen wie Prozessdaten-Monitoring und Alarmierung haben eines gemeinsam: Sie können nur implementiert werden, wenn die Prozessdaten in einer hohen Qualität zur Verfügung stehen. Ist das nicht der Fall, kann mit modernen Digitaltechnologien nicht gearbeitet werden.
Bevor also z. B. mit KI im Unternehmen gestartet werden kann, gilt es sich mit der Bereitstellung der Daten zu beschäftigen. Um für unterschiedlichste spätere Anwendungsfälle nicht jedes Mal neu anfangen zu müssen, bietet es sich an, einen allgemeinen, generischen Ansatz für das Sammeln und Bereitstellen von Daten zu wählen. Es handelt sich dabei um eine Art von Middleware, die wir an dieser Stelle als Datenplattform bezeichnen.
Die erste Aufgabe einer Datenplattform ist es, die Daten aus unterschiedlichsten Datensilos zu sammeln und gemeinsam bereitzustellen. In einer diskret arbeitenden Fabrik sind das in erster Linie Maschinendaten (z. B. Prozessdaten über die Zeit, Alarmmeldungen, Zustandsmeldungen), Auftragsdaten aus dem ERP-System (z. B. Arbeitsaufträge, Arbeitsgänge, Stücklisten, Chargennummer, Teile- und Baugruppennummern), MES-Daten (z. B. Lagerorte, Zwischenlagerzeiten, Maschinenbelegungen) und verschiedenste Daten aus Drittsystemen je nach Branchenausprägung, wie z. B. aus CAD und CAQ-Systemen. Diese Daten sind in modernen Produktionsumgebungen stets vorhanden, können aber ohne eine Datenplattform nicht in Beziehung zueinander gestellt und auswertbar gemacht werden.
Wie jede andere Software auch, kann eine Datenplattform in zwei Wegen realisiert werden: Als Standardsoftware oder als Individualsoftware, zugeschnitten auf genau einen Kunden. Im Folgenden wollen wir die Vor- und Nachteile der verschiedenen Lösungsmöglichkeiten betrachten.
Datenplattform als Standardprodukt
Seit einigen Monaten bringen mehr und mehr Hersteller verschiedenste Standardprodukte auf den Markt. Sie sind teils universal verwendbar, teils stark auf eine bestimmte Branche zugeschnitten. Der Vorteil von standardisierter Software liegt auf der Hand: Sie ist im Idealfall sehr schnell verfügbar und einsatzbereit. Außerdem bringt sie in den meisten Fällen auch sofort Business-Applikationen mit, mit deren Hilfe aktuelle Problem- und Fragestellungen gelöst werden können. In einigen Fällen können die Business-Applikationen sogar durch nicht-IT-Fachkräfte bedient werden und es bedarf keinem Data-Engineer.
Aber bringt dieser Out-of -the-box Gedanke wirklich einen Mehrwert im Zuge der digitalen Transformation einer Fabrik? Das Kernproblem der digitalen Transformation ist das notwendige Umdenken von Mitarbeitenden hinsichtlich datengetriebener Produktion. Oft sind Anforderungen und Wünsche an eine Datenplattform noch nicht ausgeprägt oder vorhanden, da die meisten Mitarbeitenden mit dieser Art von Software noch nicht in Berührung gekommen sind. Ein objektiver, systematischer Vergleich zwischen mehreren Produkten verschiedener Hersteller ist schwierig oder gar unmöglich. So kann es dazu kommen, dass hohe Investitions- und Lizenzkosten für ein suboptimales Produkt gezahlt werden oder erst sehr spät festgestellt wird, dass das Produkt nicht geeignet ist. Bei kleinen und mittelständigen Softwareherstellern ist der Investitionsschutz nur bedingt vorhanden, da diese auch dynamisch auf den Markt reagieren müssen. Im Zweifel kann das bedeuten, dass das Produkt von heute auf morgen nicht mehr gepflegt wird.
Cloud-native Individuallösung
Um den sich ständig ändernden Anforderungen aus dem Prozess der digitalen Transformation des Unternehmens gerecht zu werden, bietet sich eine individuelle Softwarelösung für die Datenplattform an. Als Technologie der Wahl haben sich in den letzten Jahren die Cloud-nativen Services der großen Hyperscaler Microsoft Azure und Amazon Web Services (AWS) herausgebildet. Diese haben einen entscheidenden Vorteil: Durch die Wahl moderner Technologie-Services, welche als Platform as a Service (PaaS) bereitstehen, ist die potenzielle Lösung der Datenplattform hoch performant, kostengünstig und nachhaltig im Sinne der Langlebigkeit des Softwarecodes. Dies wirkt sich in Form eines sehr hohen Investitionsschutzes aus. Die Programmierung der Datenplattform erfolgt stets durch einen Integrator wie z. B. ZEISS Digital Innovation unter Verwendung der Services eines Hyperscalers. Diese Kombination bringt weitere Vorteile mit sich. Im Gegensatz zu einem Standardprodukt eines konkreten Herstellers kann die individuelle Lösung nach der Fertigstellung auch durch den Kunden selbst betrieben werden. Wenn erforderlich, ist der Betrieb sogar durch dritte Parteien möglich. Das reduziert die Abhängigkeit von Integratoren, was für geplante Laufzeiten der Datenplattform von schätzungsweise zehn bis 20 Jahren oder mehr enorm wichtig ist. Die Abhängigkeit von den Hyperscalern ist ein untergeordnetes Thema. Bei der Wahl der PaaS-Technologien kann der Integrator solche nutzen, die bei mehr als einem Hyperscaler zur Verfügung stehen. Ein Umzug von Microsoft zu AWS oder umgekehrt ist zwar mit Arbeit verbunden aber absolut möglich. Dieser Schritt ermöglicht es dem Kunden, auf zukünftige Betriebskostenerhöhungen der Hyperscaler zu reagieren.
Co-Innovationen durch Barrierefreiheit
Die bisherigen Erkenntnisse der startenden digitalen Transformation von Unternehmen im Zuge der vierten industriellen Revolution belegen einen zwingenden Bedarf von Co-Innovation. Damit ist die enge Zusammenarbeit von mehreren industriellen Partnern gemeint, die ihr hochspezialisiertes Wissen nutzen, um einen höheren gemeinsamen Mehrwert für Kunden zu schaffen, als einzelne Unternehmen in der Lage wären.
Die Cloud-native Individuallösung bietet genau diesen Vorteil der barrierefreien Zusammenarbeit von mehreren Unternehmen auf der Datenplattform. Im Kontext der PaaS-Lösungen eines Hyperscalers kann man sich von dritten Firmen genau die Business-Applikationen kaufen oder programmieren lassen, die exakt auf den Anwendungsfall passen, den es im eigenen Unternehmen zu lösen gilt. Diese Basis ermöglicht es dann, stets auf modernste Technologien wie KI oder digitale Zwillinge aufzusetzen, damit Vorreiter in der eigenen Branche zu werden und einen Wettbewerbsvorteil zu generieren.
Ein Cyber-physikalisches System (CPS) steuert einen physikalisch-technischen Prozess und vereint dazu Elektronik, komplexe Software und Netzwerkkommunikation z.B. über das Internet. Charakteristisch ist, dass alle Elemente einen untrennbaren Beitrag zur Funktionsweise des Systems leisten. Daher wäre es falsch, jedes Gerät mit etwas Software und einem Netzwerkanschluss zu einem CPS zu erklären.
Gerade im Fertigungsumfeld sind CPS oft mechatronische Systeme, z.B. vernetzte Roboter. Embedded Systems stehen im Kern dieser Systeme, werden durch Netzwerke miteinander verbunden und durch zentrale Softwaresysteme z.B. in der Cloud ergänzt.
Cyber-physikalische Systeme sind durch ihre Vernetzung in der Lage, auch Infrastrukturen automatisch zu steuern, die über größere Entfernungen oder viele Orte verteilt sind. In der Vergangenheit waren diese nur begrenzt automatisierbar. Beispiele dafür sind dezentral gesteuerte Stromnetze, Logistikabläufe und verteilte Produktionsprozesse.
Im Fertigungsumfeld ermöglichen CPS durch ihre Automatisierung, Digitalisierung und Vernetzung eine hohe Flexibilität und Autonomie der Produktion. Dadurch werden z.B. Matrix-Produktionssysteme möglich, die hohe Variantenvielfalt für große und kleine Stückzahlen unterstützen [1].
Es hat sich bisher keine einheitliche Definition durchgesetzt, da der Begriff breite und unspezifische Anwendung findet und manchmal auch utopisch-futuristische Konzepte damit vermarktet werden [2].
Woher kommt der Begriff?
Innovationen im Bereich der IT, Netzwerktechnik, Elektronik etc. ermöglichten in den vergangenen Jahren komplexe, automatisierte und vernetzte Steuerungssysteme. Akademische Disziplinen wie die Steuerungs- und Regeltechnik sowie die Informationstechnik boten kein passendes Konzept für den neuen Mix aus technischen Prozessen, komplexen Daten und Software. Daher wurde ein neues Konzept mit einem passenden Namen nötig.
Der Begriff steht in enger Verwandtschaft zum Internet of Things (IoT). Außerdem bilden Cyber-physikalische Systeme den technischen Kern für viele Innovationen, die das Label „smart“ im Namen tragen: Smart Home, Smart City, Smart Grid etc.
Übrigens wird der deutsche Begriff nicht einheitlich verwendet, die alternative Schreibweise Cyber-physische Systeme wird z.B. durch den Verein Deutscher Ingenieure (VDI) in seinen Normen propagiert. In der Fachliteratur hat sich diese Schreibweise aber bisher nicht durchgesetzt.
Merkmale von CPS
Wie bereits erwähnt gibt es keine allgemein anerkannte Definition. Aus der Vielzahl von Definitionen lassen sich aber folgende Merkmale destillieren:
Im Kern steht ein physikalischer oder technischer Prozess.
Es gibt Sensoren und Modelle, um den Zustand des Prozesses digital zu erfassen.
Es gibt komplexe Software, um auf Basis des Zustands eine (teil-)automatische Entscheidung zu treffen. Dabei ist ein menschlicher Eingriff möglich, aber nicht zwingend nötig.
Es gibt technische Mittel, um die getroffene Entscheidung umzusetzen.
Alle Elemente des Systems sind vernetzt, um Informationen auszutauschen.
Ein Modell für den Aufbau eines CPS ist das Schichtenmodell nach [2]
Abbildung 1: Schichtenmodell für den inneren Aufbau von Cyber-physikalischen Systemen
Beispiele von Cyber-physikalischen Systemen
Selbststeuernde Fertigungsmaschinen und -prozesse (Smart Factory)
Dezentrale Steuerung von Stromerzeugung und -verbrauch (Smart Grids)
Gebäudeautomatisierung im Haushalt (Smart Home)
Verkehrssteuerung in Echtzeit, durch zentrale oder dezentrale Steuerung mit Verkehrsleitsystemen oder Apps (Element der Smart City)
Beispiel für ein Cyber-physikalisches System in der Industrie
In diesem Beispiel wird eine Fertigungsmaschine vorgestellt, die durch Software und Vernetzung weitgehend autonom agieren kann und dabei Leerlauf- Ausfall- und Wartungszeiten minimiert. Für unser Beispiel nehmen wir an, dass es sich um eine Werkzeugmaschine für die Zerspanung handelt.
Vernetzte Elemente des Systems:
Werkzeugmaschine mit
QR-Code-Kamera zur Werkstück-Identifikation
RFID-Leser zur Werkzeug-Identifikation
Automatische Vorratsüberwachung
Verschleißerkennung und Wartungsvorhersage
Zentrales IT-System für Konstruktionsdaten und Werkzeugparameter (CAM)
MES/ERP-System
Die Fertigungsmaschine in unserem Beispiel ist in der Lage, das Werkstück und das Werkzeug zu identifizieren. Dafür können die gängigen Technologien RFID oder QR-Code verwendet werden. Ein zentrales IT-System verwaltet Konstruktions- und Vorgabedaten, z.B. bei CNC-Maschinen ein Computer-aided Manufacturing-System (CAM). Die Fertigungsmaschine ruft mit der ID von Werkstück und Werkzeug alle Daten aus dem zentralen System ab, die für die Bearbeitung nötig sind. Damit entfällt die manuelle Eingabe von Parametern, die Daten werden durchgängig digital verarbeitet. Die Identifikation ermöglicht die Verbindung von physikalischer Schicht und Datenschicht eines Cyber-physikalischen Systems.
Basierend auf den Konstruktions- und Vorgabedaten werden die eingerüsteten Werkzeuge und die in der Maschine vorhandenen Material- und Ressourcenvorräte überprüft. Bei Bedarf benachrichtigt die Maschine das Personal. Durch diese Validierung vor Bearbeitungsbeginn kann Ausschuss vermieden und die Auslastung erhöht werden.
Die Maschine überwacht ihren Zustand (in Betrieb, Leerlauf, Störung) und meldet diesen digital an ein zentrales System, mit dem Auslastung und weitere Betriebskennzahlen erfasst werden. Solche Funktionen zur Zustandsüberwachungen sind typischerweise in ein Manufacturing Execution System (MES) integriert und mittlerweile weit verbreitet. Für eine höhere Autonomie ist die Maschine in unserem Beispiel zusätzlich in der Lage, den eigenen Verschleiß zu messen, daraus Wartungsbedarf vorherzusagen und zu melden. Diese Funktionen sind unter dem Stichwort Predictive Maintenance bekannt. Diese Maßnahmen erhöhen die Maschinenverfügbarkeit und erleichtern Wartung und Arbeitsplanung.
Durch den Einsatz von Elektronik und Software ist unser fiktive Fertigungsmaschine in der Lage, weitgehend autonom zu arbeiten. Die Rolle des Menschen wird auf Beschickung, Rüsten, Entstörung und Wartung reduziert, er unterstützt damit nur noch die Maschine im Fertigungsprozess.
Literatur
[1] Forschungsbeirat Industrie 4.0, „Expertise: Umsetzung von cyber-physischen Matrixproduktionssystemen,“ acatech – Deutsche Akademie der Technikwissenschaften, München, 2022.
[2] P. H. J. Nardelli, Cyber-physical systems: theory, methodology, and applications, Hoboken, New Jersey: Wiley, 2022.
[3] P. V. Krishna, V. Saritha und H. P. Sultana, Challenges, Opportunities, and Dimensions of Cyber-Physical Systems, Hershey, Pennsylvania: IGI Global, 2015.
[4] P. Marwedel, Eingebettete Systeme: Grundlagen Eingebetteter Systeme in Cyber-Physikalischen Systemen, Wiesbaden: Springer Vieweg, 2021.
Kundenindividuelle Massenproduktion, demografischer Wandel, Arbeitskräftemangel und Verlagerung von Produktionsstätten sind einige der globalen Herausforderungen, mit denen produzierende Unternehmen weltweit konfrontiert werden. Folglich verlangen Produktionsstandorte in Hochlohnländern nach hochautomatisierten und flexiblen Produktionssystemen, um wettbewerbsfähig zu bleiben. Industrieroboter und Sondermaschinen haben sich bei der Bewältigung einiger dieser Herausforderungen als wichtige Hilfsmittel und Wegbereiter erwiesen. Die flexible Programmierung solcher Fertigungssysteme ermöglicht es, Aufgaben wie Handhabung, Transport und verschiedene Produktionsprozesse automatisch mit hoher Präzision, Geschwindigkeit und Qualität durchzuführen.
Zwar wurden die Vorteile solcher Produktionssysteme vielfach nachgewiesen, es ist jedoch zu beachten, dass ein erheblicher Integrations- und Programmieraufwand erforderlich ist, bevor diese Systeme produktiv eingesetzt werden können. In den meisten Fällen erfordert die Softwareentwicklung für Produktionssysteme den Einsatz physischer Komponenten unter realen Bedingungen. Die Verfügbarkeit solcher Systeme ist jedoch häufig aus verschiedenen Gründen eingeschränkt, beispielsweise weil das System in Betrieb ist, parallel entwickelt wird oder im schlechtesten Falle überhaupt nicht existiert. Dieses Problem führt dazu, dass die Entwicklung der Software verzögert oder aufgeschoben wird, bis die erforderlichen physischen Komponenten verfügbar und integriert sind. Zudem gilt die Programmierung eines Industrieroboters als eine nicht gerade triviale Aufgabe, die qualifizierte Bedienende mit einem guten räumlichen Verständnis des Arbeitsbereichs und mit Fachkompetenz erfordert. Die Herausforderung besteht darin, eine Bewegungssequenz zu programmieren, die den Ablauf des Produktionsprozesses und die Prozessqualität sicherstellt und gleichzeitig Kollisionen vermeidet. Deshalb wird die Programmierung von Industrierobotern heutzutage häufig noch manuell durchgeführt und gilt als eine anspruchsvolle und ressourcenintensive Aufgabe.
Die Probleme der Roboterprogrammierung sind auf einer abstrakteren Ebene auch bei der Softwareentwicklung in anderen Bereichen anzutreffen. Es stellt sich also folgende Frage: Wie gehen Softwareentwickler mit diesen Problemen um, wenn es zum Beispiel keine Module oder Schnittstellen gibt? Die Antwort: Wir erstellen Mock-ups! In gewisser Weise sind Mock-ups nichts anderes als Modelle, die eine gewünschte Funktion simulieren. Allerdings klingt die Modellierung eines Roboters ein wenig komplizierter als die Implementation einer Datenbank oder einer Schnittstelle. Dieser Blogartikel soll das Gegenteil beweisen und zeigt in einem kurzen Tutorial, wie man kinematische Simulationsmodelle einfach und effizient erstellen kann, um die Programmierung solcher Fertigungssysteme zu erleichtern.
Dieser Blogbeitrag soll den Lesern Folgendes vermitteln:
Grundlegendes Verständnis von kinematischen Simulationsmodellen
Die Möglichkeit, ein einfaches kinematisches Modell eines Manipulators (z. B. Roboter, Drehtisch, Linearachsen) basierend auf freier und Open-Source-Software (FOSS) zu erstellen, das für Prototyping-, Entwicklungs- und Testzwecke verwendet werden kann
Kinematische Modellierung
Bezugssystem
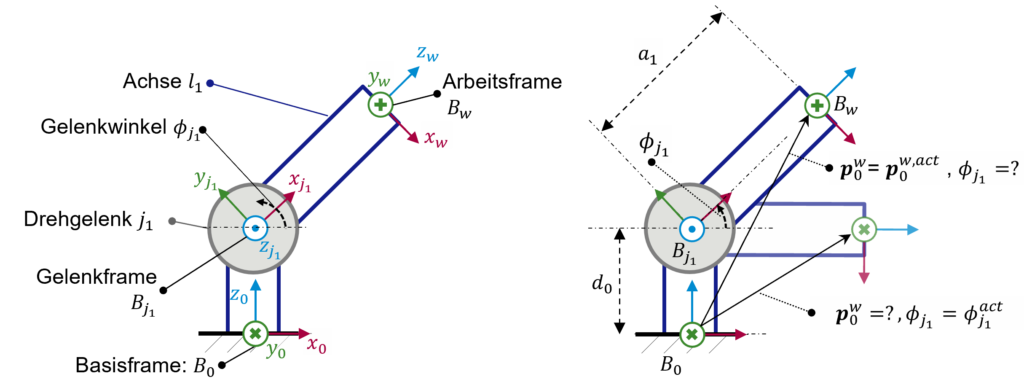
Im Vorfeld der Simulation der Kinematik eines Robotersystems müssen zunächst einige grundlegende mathematische Konzepte und die im Zusammenhang mit der kinematischen Modellierung genutzte Terminologie verstanden werden. Zu diesem Zweck betrachten wir zunächst ein minimales System, das aus einem Drehgelenk \(j_1\) und eine Achse \(l_1\) besteht.
Die Achse ist starr mit dem Gelenk verbunden. Das bedeutet, wenn das Gelenk um seine z-Achse (Frame \(B_{j_1}\)) um einen Winkel von \(\phi_{j_1}\) rotiert, dreht sich die Achse \(l_1\) mit. Gehen wir hier davon aus, dass sich der Ursprungskoordinatenframe des Systems im Basiskoordinatenframe bei \(B_0\) befindet. Darüber hinaus beschreibt der Vektor \(p_0^w := (x, y, z, a^x, \beta^y, \phi^z)^T\) die Pose (Position und Rotation) der Achse im Arbeitsframe \(B_w\). Das kinematische 2D-Modell eines solchen Systems und seiner Komponenten ist links in Abbildung 1 dargestellt.
Abbildung 1: Einfaches kinematisches Modell mit einem Drehgelenk und einer Achse
Kinematisches Modell
Wenn wir davon ausgehen, dass wir einige Bewegungen programmieren oder simulieren müssen, werden wir zwangsläufig mit mindestens einem der folgenden Probleme konfrontiert:
Inverskinematik-Problem: Welcher Winkel \(\phi_{j1}\) entspricht einer aktuellen Pose \(p_0^{w,act}\)?
Vorwärtskinematik-Problem: Welches ist die resultierende Pose \(p_0^w\) für einen gegebenen Gelenkwinkel \(\phi_{j1}^{act}\)?
Diese Fragen werden auf der rechten Seite von Abbildung 1 visualisiert und stellen die grundlegenden Probleme der kinematischen Modellierung dar, die als Inverskinematik- und Vorwärtskinematik-Probleme bezeichnet werden. Um diese Fragen zu beantworten, müssen zunächst alle räumlichen Beziehungen zwischen allen aufeinanderfolgenden[1] Frames des Systems abgeschätzt werden. Das heißt von der Basis \(B_0\) zum Gelenk \(B_{j1}\) und vom Gelenk \(B_{j1}\) zum Arbeitsframe \(B_w\). Die relativen räumlichen Beziehungen[2] zwischen zwei Frames werden durch die Translationskomponenten \(x_{\Delta}, y_{\Delta}\), und \(z_{\Delta}\) und die Rotationskomponenten \(\alpha_{\Delta}^x\), \(\beta_{\Delta}^y\), und \(\phi_{\Delta}^z\) modelliert. In Tabelle 1 sind die geometrischen Beziehungen für alle aufeinanderfolgenden Frames des kinematischen Systems von Abbildung 1 angegeben.
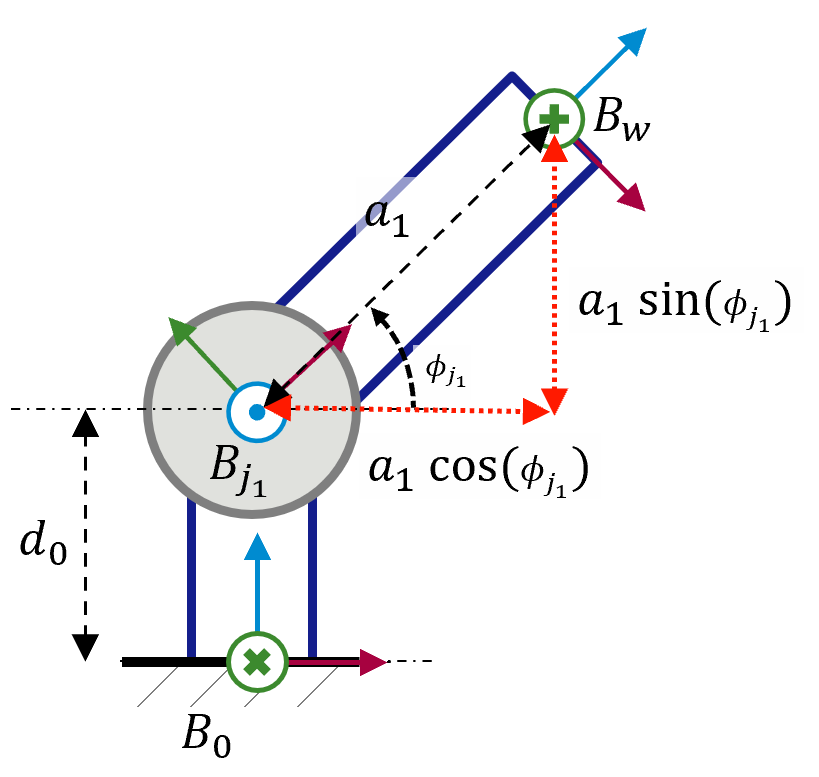
Nachdem wir nun die geometrischen Beziehungen unseres Systems definiert haben, kann das kinematische Modell, mithilfe dessen die vorhergehenden Fragen beantwortet werden, beschrieben werden. Das Vorwärtskinematik-Model, dass die resultierende Pose für einen angeordneten Gelenkwinkel liefert, könnte beispielsweise mithilfe der in Abbildung 2 dargestellten trigonometrischen Beziehungen abgebildet werden.
Abbildung 2: Trigonometrische Beziehungen im Bezugssystem
\(x_0^w\) = \(a_1 \cos (\phi_{j1})\)
\(y_0^w\) = 0
\(z_0^w\) = \(d_0 + a_1 \sin (\phi_{j_1})\)
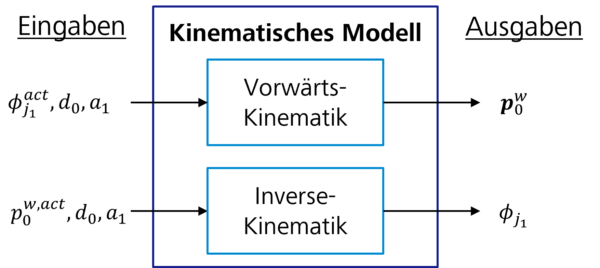
Obwohl diese geometrischen Funktionen die Kinematik unseres Bezugssystems ausreichend modellieren, ist hierbei zu beachten, dass die Beschreibung des kinematischen Modells auf diese Weise für komplexere Systeme mit mehreren Gelenken und Achsen nicht so einfach ist. Aus diesem Grund werden zur Berechnung von Mehrkoordinatentransformationen in der Regel andere mathematische Ansätze genutzt, z. B. homogene Matrizen oder Quaternionen. Die Beschreibung dieser Methoden würde den Rahmen dieses Blogbeitrags sprengen. Für den Rest des Artikels ist es ausreichend zu wissen, welche Eingaben und Ausgaben wir von einem kinematischen Modell erwarten können. Diese Modelle können als Black-Box-Komponenten angenommen werden, wie in Abbildung 3 dargestellt.
Abbildung 3: Vorwärtskinematik- und Inverskinematik-Black-Box-Modelle
Implementierung
Nach der Einführung der zentralen Konzepte der kinematischen Modellierung wird eine einfache Möglichkeit zur Implementierung kinematischer Ketten vorgestellt.
In der Industrie gibt es bereits eine Reihe von Spezifikationen und Formaten, die sich mit der Modellierung von kinematischen Ketten befassen, z. B. Collada, AutomationML, OPC UA Robotics. Unserer Erfahrung nach hat sich jedoch kein branchenweites Standardformat durchgesetzt. Dies stellt ein umfassenderes Problem auf dem Gebiet der Robotik dar, wo Programmiersprachen hauptsächlich herstellerspezifisch sind und es keine Standards für die Roboterprogrammierung oder -modellierung gibt. Dies ist einer der Gründe, weshalb das Robot Operating System (ROS) im Jahr 2010 ins Leben gerufen wurde. ROS ist eine FOSS-Robotik-Middleware, die verschiedene Bibliotheken (z. B. kinematische Modellierung, Wahrnehmung, Visualisierung, Bahnplanung) für die hardwareunabhängige Programmierung von Robotersystemen enthält. Diese Eigenschaften haben ROS zu einem Framework gemacht, das in der Robotikforschung als Stand der Technik gilt. Aufgrund der Beliebtheit und der Merkmale des ROS-Frameworks (z. B. Leistungsfähigkeit, Hardwareneutralität, FOSS, Modularität, Skalierbarkeit) haben Hersteller von Robotern und Feldgeräten (z. B. Greifer und Sensoren) sowie Drittanbieter von Software begonnen, Programmierschnittstellen für ROS anzubieten.
Im Rahmen der Entwicklung von ROS wurde das Unified Robot Description Format (URDF) zur Modellierung von kinematischen Ketten eingeführt. Beim URDF handelt es sich um ein offenes Standard-XML-Schema zur Beschreibung der geometrischen Beziehungen zwischen Gelenken und Achsen eines Roboters. Zusätzlich zur Modellierung kinematischer Ketten bietet das URDF die Möglichkeit, die physikalischen Eigenschaften von Gelenken zu modellieren (z. B. Trägheit, Dynamik und Achsenbegrenzungen) oder CAD-Dateien zur Modellierung der Volumeneigenschaften von Achsen zu verwenden, die für Kollisionstests genutzt werden können. Da das URDF einem XML-Schema folgt, können kinematische Modelle darüber hinaus einfach und lesbar dargestellt werden. So beschreibt der folgende Auszug in Abbildung 4 beispielsweise die kinematischen Beziehungen zwischen dem Gelenk j1 und der Achse l1 aus Tabelle 1.
Nachdem die geometrischen Beziehungen zwischen allen Achsen und Gelenken mithilfe einer URDF-Datei beschrieben wurden, kann das kinematische Modell visualisiert und zur Berechnung von Endeffektorpositionen oder erforderlichen Gelenkrotationen genutzt werden. ROS enthält eine Handvoll Pakete basierend auf Bibliotheken von Drittanbietern, die alle diese Funktionen implementieren. Die Verwendung dieser Bibliotheken ist in der ROS-Dokumentation beschrieben.
<!--Alle Achsen unseres Modells.-->
<!--Das Root-Frame in ROS wird base_link genannt und repräsentiert das Root-Frame (B_0) in unserem System. -->
<link name="base_link"/>
<!--Achse 1 unseres Modells. -->
<link name="link_1"/>
<!-- Der Arbeitsframe unseres Modells wird als Achse dargestellt.-->
<link name="work_frame"/>
<!--Alle Gelenke unseres Modells.-->
<!--Das Drehgelenk 1, das die Basisachse (parent-Achse) mit Achse 1 (child-Achse) verbindet, wird hier modelliert.
Das Gelenk befindet sich im Ursprung der child-Achse.-->
<joint name="joint_1" type="revolute">
<parent link="base_link"/>
<child link="link_1"/>
<!-- Auswahl der Rotationsachse, in unserem Fall um das Gelenk um die z-Achse in positiver Richtung.-->
<axis xyz="0 0 1"/>
<!-- Hier wird die Transformation zwischen parent- und child-Achse angegeben.-->
<!-- Die Translationskomponenten (xyz) werden in Metern angegeben. -->
<!-- Die Rotation wird durch die Euler-Winkel (rpy) in Radianten ausgedrückt, und zwar nach folgender
Notation (r)oll (x-Achsen-Rotation), (p)itch (y-Achsen-Rotation) und (y)aw (z-Achsen-Rotation). -->
<origin xyz="0 0 0,4" rpy="1,57079632679 0,0 0,0"/>
<!-- Das Modell eines beweglichen Gelenks muss weitere physikalische Eigenschaften umfassen. -->
<limit effort="100" lower="-0,175" upper="3,1416" velocity="0,5"/>
</joint>
Abbildung 4: URDF-Auszug zur Beschreibung der kinematischen Beziehung zwischen Gelenk \(j_1\) und Achse \(l_1\)
Erweitertes System
Nachdem die Grundlagen der kinematischen Modellierung und die Verwendung von URDF zur Implementierung eines kinematischen Modells verstanden wurde, steht der Beschreibung komplexerer kinematischer Ketten mit mehreren Gelenken, wie in Abbildung 5 dargestellt, nichts mehr im Wege.
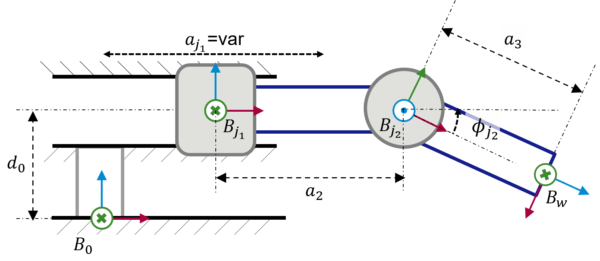
Abbildung 5: Erweitertes kinematisches Modell unter Berücksichtigung eines Schub- und eines Drehgelenks
Die entsprechenden geometrischen Beziehungen sind in Tabelle 2 angegeben. Darüber hinaus ist das vollständige URDF im Anhang zu finden.
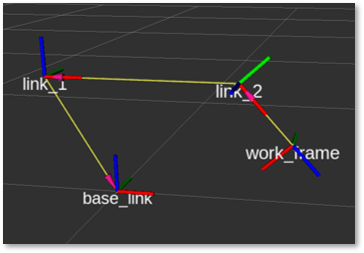
Abbildung 6: URDF-Visualisierung in ROS mit zwei verschiedenen Gelenkkonfigurationen und folgenden Werten: \(d_0\) = 300mm, \(a_2\) = 500mm, \(a_3\) = 200mm. Die Abbildung rechts zeigt auch die Integration von Oberflächenmodellen zur Modellierung der Volumeneigenschaften der Achsen.
Zusammenfassung und Ausblick
Die Programmierung eines Roboters ist eine komplexe und ressourcenintensive Aufgabe, die in den meisten Fällen auch die Nutzung des physikalischen Systems erfordert. Diese Hindernisse wirken sich direkt auf die Softwareentwicklung und Inbetriebnahme solcher Systeme aus. Ein kinematisches Modell (Mock-up) des Roboters hat das Potenzial, die Programmierung zu vereinfachen, ohne dabei das physische System zu benötigen, und gleichzeitig die Kosten zu senken. Allerdings gilt die Modellierung von Robotersystemen als eine nicht gerade triviale Aufgabe, die in einem ersten Schritt die Beschreibung ihres kinematischen Modells erfordert. Deshalb wurden in diesem Blogbeitrag zunächst die mathematischen Mindestgrundlagen zum Verständnis der kinematischen Modellierung vorgestellt. In einem weiteren Schritt haben wir anschließend gezeigt, wie kinematische Modelle mithilfe des Standardformats URDF nahtlos implementiert werden können.
Mit den Erkenntnissen in diesem Blogbeitrag sollten die Leser in der Lage sein, kinematische Modelle zu beschreiben, die als Mock-ups für Prototyping- oder Entwicklungszwecke eingesetzt werden können. Nachdem nun die erste Hürde der kinematischen Modellierung überwunden ist, können sich die Anwender solche Modelle mit folgenden Themen auseinandersetzen:
Bereitstellung kinematischer Modelle als Microservices für Entwicklungs-, Test- und Inbetriebnahmezwecke (weiterführende Literatur: Mocks in der Testumgebung)
Entwicklung anwenderfreundlicherer Programmier-Frameworks basierend auf kinematischen Simulationen unter Einsatz von VR (Virtual Reality) oder AR (Augmented Reality)
[1] Aus diesem Grund werden diese Modelle im Allgemeinen als serielle kinematische Ketten bezeichnet. Es gibt auch parallele kinematische Modelle zur Darstellung von Delta-Robotern. Die kinematische Modellierung solcher Systeme wird im Rahmen dieses Blogbeitrags nicht behandelt.
[2] Auf dem Gebiet der Robotik wird die Transformation zwischen zwei Koordinatenframes häufig mit homogenen Transformationen und einer Gruppe von vier Parametern beschrieben, die die Translations- und Orientierungsverschiebung beschreiben. Diese Parameter werden als die Denavit-Hartenberg-Parameter bezeichnet.
Während immer mehr Startups, Mittelständler und Großkonzerne die Digitalisierung und Vernetzung für den Ausbau ihres Geschäfts nutzen und dabei auch völlig neuartige Geschäftsmodelle entwickeln, wächst der weltweite Bedarf an Standardisierung und Umsetzungskompetenz. So haben sich aus ehemaligen Worthülsen wie „Big Data“, „Internet of Things“ (IoT) und „Industrie 4.0“ längst konkrete Technologien entwickelt, die den digitalen Wandel vorantreiben und Unternehmen bei der Steigerung ihrer Produktivität, der Optimierung von Lieferketten und letztlich der Erhöhung von Rohertragsmargen unterstützen. Dabei profitieren sie vor allem von den wiederverwendbaren Diensten der sogenannten Hyperscaler wie Amazon, Microsoft, Google oder IBM, sind aber oft selbst nicht in der Lage, die Implementierung maßgeschneiderter Lösungen mit eigenem Personal zu stemmen. Die ZEISS Digital Innovation (ZDI) begleitet und unterstützt als Partner und Entwicklungsdienstleister ihre Kunden bei der digitalen Transformation.
Cloud-Lösungen hatten es lange Zeit vor allem im industriellen Umfeld schwer, da es weit verbreitete Vorbehalte in Bezug auf Daten-, IT- und Anlagensicherheit wie auch Entwicklungs- und Betriebskosten gab. Zudem erforderte die Anbindung und Aufrüstung unzähliger heterogener Bestandssysteme viel Fantasie. Inzwischen sind diese Grundsatzfragen weitgehend geklärt und Cloud-Anbieter werben mit spezifischen IoT-Diensten um neue Kunden aus dem produzierenden Gewerbe.
Um die typischen Chancen und Herausforderungen von IoT-Umgebungen möglichst praxisnah illustrieren zu können, wird ein interdisziplinäres ZDI-Team – bestehend aus erfahrenen Expertinnen und Experten aus den Bereichen Business-Analyse, Software-Architektur, Frontend- und Backend-Entwicklung, DevOps-Engineering sowie Testmanagement und Testautomatisierung – in bewährter agiler Vorgehensweise einen Demonstrator entwickeln, anhand dessen später auch kundenspezifische Anforderungen auf Umsetzbarkeit geprüft werden können.
Im Demonstrator wird eine vernetzte Produktionsumgebung mithilfe einer fischertechnik Lernfabrik simuliert und mit einer selbst entwickelten Cloud-Anwendung gesteuert. Die Lernfabrik enthält mit unterschiedlichen Sensoren, Kinematiken, Fördertechnik und insbesondere einer Siemens S7 Steuerung viele typische Elemente, wie sie auch in echten Industrieanlagen zum Einsatz kommen. Über etablierte Standards wie OPC UA und MQTT werden die Geräte an ein ebenfalls integriertes IoT-Gateway angebunden, das die gesammelten Daten seinerseits über eine einheitliche Schnittstelle den dafür optimierten Cloud-Diensten bereitstellt. Umgekehrt lässt das Gateway unter Berücksichtigung strenger Anforderungen an die IT- und Anlagensicherheit auch steuernde Zugriffe auf die Produktionsanlagen von außerhalb der Werksinfrastruktur zu.
Abbildung 2: Greifarm mit blauem, NFC codiertem -Werkteil
Das Herstellen und Absichern der Konnektivität ist nach erfolgter Inbetriebnahme für die über alle ZDI-Standorte verteilt arbeitenden Kolleginnen und Kollegen einerseits ein organisatorisches Erfordernis, andererseits handelt es sich dabei bereits um eine Kernanforderung jeder praxistauglichen IoT-Lösung mit durchaus weitreichenden Konsequenzen für die Gesamtarchitektur. Technologisch wird sich das Team zunächst auf die Cloud-Services von Microsoft (Azure) und Amazon (AWS) konzentrieren und dabei umfangreiche Erfahrungen aus anspruchsvollen Kundenprojekten im IoT-Umfeld einbringen. Weiterhin stehen Architektur- und Technologie-Reviews sowie die Implementierung erster Monitoring Use Cases im Fokus. Darauf aufbauend sind in der Folge auch komplexere Use Cases zur Taktzeitoptimierung, Maschineneffizienz, Qualitätssicherung oder Nachverfolgung (Track and Trace) geplant.
Besonders gut ist die ZDI auch im Bereich Testservices aufgestellt. Anders als in stark softwarelastigen Branchen wie z. B. der Logistik oder Finanzwirtschaft wurden die Testmanagerinnen und Testmanager in zahlreichen fertigungsnahen Use Cases jedoch immer wieder mit der Frage konfrontiert, wie Hardware, Software und insbesondere deren Zusammenspiel auf der Steuerungsebene möglichst vollumfänglich und vollautomatisch getestet werden können, ohne wertvolle Maschinen- und Anlagenzeit zu benötigen. In hyperkomplexen Produktionsumgebungen, wie sie ZEISS beispielsweise in der Halbleiter- und Automotive-Industrie vorfindet, können die ansonsten weit verbreiteten digitalen Zwillinge aufgrund schwer modellierbarer Zusammenhänge und teilweise gänzlich unbekannter Einflussfaktoren nur noch bedingt Abhilfe leisten. Umso wichtiger ist die Konzeption einer geeigneten Testumgebung, mit der Fehler eingegrenzt, reproduziert und möglichst minimalinvasiv behoben werden können.
Wir werden auf diesem Blog regelmäßig über den Projektfortschritt berichten und unsere Erfahrungen teilen.