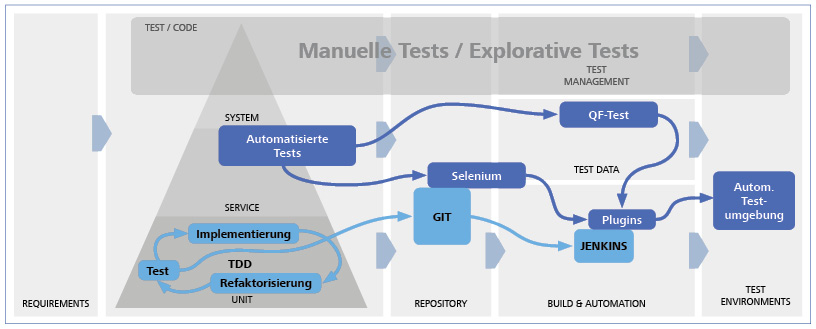
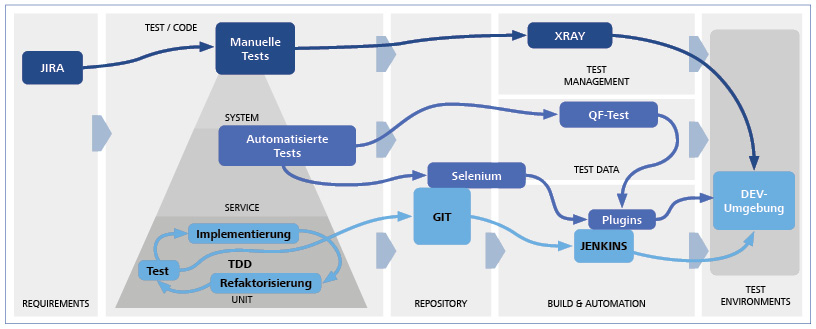
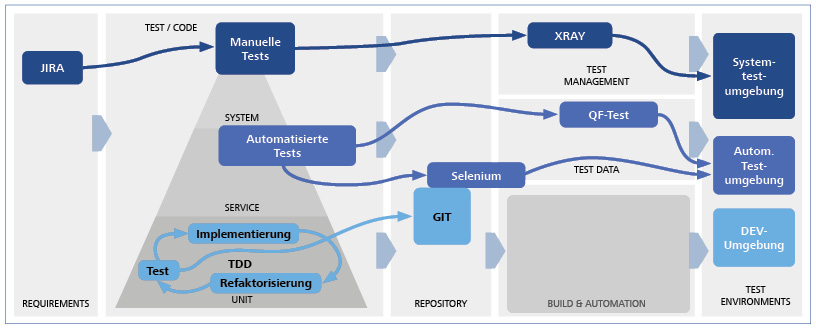
Im Serverless-Modell werden Anwendungskomponenten wie Datenbanken oder Komponenten zur Datenverarbeitung automatisch und bedarfsabhängig vom Cloud-Provider zur Verfügung gestellt und betrieben. Die Verantwortung des Cloud-Nutzers liegt darin, diese Ressourcen zu konfigurieren – etwa durch eigenen Code oder anwendungsspezifische Parameter – und sie zu kombinieren.
Kosten fallen nach verbrauchten Kapazitäten an und die Skalierung erfolgt automatisch auf Basis der Last. Bereitstellung, Skalierung, Wartung, Hochverfügbarkeit und Verwaltung von Ressourcen liegen in der Verantwortung des Cloud-Providers.
Serverless eignet sich besonders für schwer vorhersehbare oder kurzlebige Arbeitslasten, für Automatisierungsaufgaben oder Prototypen. Serverless ist weniger ideal für ressourcenintensive, langlebige und planbare Aufgaben, da in diesem Fall die Kosten signifikant höher sein können als bei selbstverwalteten Ausführungsumgebungen.
Building Blocks
Im Rahmen eines Serverless-Adventskalenders wurden die Cloud-Services von AWS und Azure gegenübergestellt. Die Türchen öffnen sich unter dem Hashtag #ZEISSDigitalInnovationGoesServerless.
Kategorie
AWS
Azure
COMPUTE Serverless Function
AWS Lambda
Azure Functions
COMPUTE Serverless Containers
AWS Fargate Amazon ECS/EKS
Azure Container Instances / AKS
INTEGRATION API Management
Amazon API Gateway
Azure API Management
INTEGRATION Pub-/Sub-Messaging
Amazon SNS
Azure Event Grid
INTEGRATION Message Queues
Amazon SQS
Azure Service Bus
INTEGRATION Workflow Engine
AWS Step Functions
Azure Logic App
INTEGRATION GraphQL API
AWS AppSync
Azure Functions mit Apollo Server
STORAGE Object Storage
Amazon S3
Azure Storage Account
DATA NoSQL-Datenbank
Amazon DynamoDB
Azure Table Storage
DATA Storage Query Service
Amazon Aurora Serverless
Azure SQL Database Serverless
SECURITY Identity Provider
Amazon Cognito
Azure Active Directory B2C
SECURITY Key Management
AWS KMS
Azure Key Vault
SECURITY Web Application Firewall
AWS WAF
Azure Web Application Firewall
NETWORK Content Delivery Network
Amazon CloudFront
Azure CDN
NETWORK Load Balancer
Application Load Balancer
Azure Application Gateway
NETWORK Domain Name Service
Amazon Route 53
Azure DNS
ANALYTICS Data Stream
Amazon Kinesis
Analytics
ANALYTICS ETL Service
AWS Glue
Azure Data Factory
ANALYTICS Storage Query Service
Amazon Athena
Azure Data Lake Analytics
Einen Überblick zu den genannten Services und ihren Eigenschaften sowie einige beispielhafte Architekturmuster haben wir in Form eines Posters zusammengetragen. Dieser Überblick ermöglicht einen leichten Einstieg in das Thema Serverless-Architektur.
Gerne senden wir Ihnen das Poster auch in Originalgröße (1000 x 700 mm) zu. Schreiben Sie uns dazu einfach eine E-Mail mit Ihrer Adresse an info.digitalinnovation@zeiss.com. Beachten Sie hierzu bitte unsere Datenschutzhinweise.
Best Practices für Serverless-Funktionen
Jede Funktion sollte nur eine Sache tun (Single Responsibility Principle). Dies verbessert Wartbarkeit und Wiederverwendbarkeit. Speicherkapazität, Zugriffsrechte und Timeout-Einstellung können gezielter konfiguriert werden.
Mit der Erhöhung des zugewiesenen Speichers einer Lambda-Funktion werden auch CPU‑ und Netzwerkkapazität erhöht. Ein optimales Verhältnis aus Ausführungszeit und Kosten sollte per Benchmarking gefunden werden.
Eine Funktion sollte keine weitere Funktion synchron aufrufen. Das Warten führt zu unnötigen Kosten und erhöhter Kopplung. Stattdessen ist asynchrone Verarbeitung, z. B. über Message Queues, einzusetzen.
Das Deployment-Paket einer Funktion sollte so klein wie möglich sein. Auf große externe Bibliotheken ist zu verzichten. Das verbessert die Kaltstartzeit. Wiederkehrende Initialisierungen von Abhängigkeiten sollten außerhalb der Handler-Funktion stattfinden, damit sie nur einmalig beim Kaltstart ausgeführt werden müssen. Es ist ratsam, betriebliche Parameter über Umgebungsvariablen einer Funktion abzubilden. Das verbessert die Wiederverwendbarkeit.
Die Zugriffsberechtigungen auf andere Cloud-Ressourcen sind für jede Funktion individuell und so restriktiv wie möglich zu definieren. Zustandsbehaftete Datenbankverbindungen sind zu vermeiden. Stattdessen sollten Service-APIs verwendet werden.
Eine besondere Herausforderung vieler Unternehmen besteht darin, dass Daten oft noch Jahre später für neue Anwendungsfälle von Interesse sein können, jedoch zu diesem Zeitpunkt bereits längst entsorgt wurden oder sich deren Schemata in der Zwischenzeit mehrfach geändert haben. Auch kommt es oft vor, dass Daten bereits vor dem ersten Speichern selektiert, aggregiert oder transformiert wurden und somit für die spätere Verwendung nicht mehr komplett vorliegen.
Gerade für datenintensive Vorhaben im Bereich von Data Science oder KI müssten passende Daten daher erst neu gesammelt werden, was eine starke Verzögerung in den geplanten Vorhaben verursacht.
Wie können Data Lakes helfen?
Data Lakes sind ein Architekturpattern, welches darauf abzielt, Daten aus verschiedenen Applikationen in einem zentralen Ökosystem langfristig verfügbar zu machen. Daten möglichst aller Bereiche und Abteilungen eines Unternehmens werden an einer zentralen Stelle vorgehalten. Im Gegensatz zu klassischen Data Warehouses werden dabei jedoch immer auch die Rohdaten gespeichert, oft in Objektspeichern wie S3.
Der Vorteil dabei ist, dass die Informationen in vollem Umfang zur Verfügung stehen und nicht wie in klassischen Data Warehouses bei der ersten Speicherung bereits reduziert oder transformiert werden. Dadurch gibt es in dem zentralen Datenpool kein an spezielle Nutzerbedürfnisse angepasstes Schema, sodass sich die Konsumenten die Bedeutung der Daten in diesem Fall selbst herleiten müssen.
Um den Vorteil von Data Lakes effizient nutzen zu können, sollten diese bereichsübergreifend zur Verfügung gestellt werden. Dadurch können die Daten an allen Stellen abgerufen werden, an denen sie benötigt werden.
Dabei gibt es die Möglichkeit, die Daten in verschiedenen Zonen abzulegen. Dies ermöglicht den Zugriff für verschiedene Abstraktionslevel. So dienen bspw. für Data Scientists Low-Level-Tools wie Athena dazu, einen sehr tiefen und detaillierten Einblick in den Datenpool zu bekommen, während für Fachabteilungen eher spezialisierte Data Marts bereitgestellt werden sollten.
Was bietet Amazon Athena?
Mit Amazon Athena lassen sich SQL-Abfragen direkt auf (semi-) strukturierten Daten in S3-Buckets ausführen – ohne die Notwendigkeit einer Datenbank mit einem festen Schema. Auch vorbereitende ETL-Prozesse (Extract Transform Load), wie aus dem Bereich klassischer Data Warehouses bekannt, sind für die Arbeit mit den Rohdaten nicht notwendig.
Da Amazon Athena in den Bereich der Serverless-Dienste fällt, ist keinerlei Provision von Infrastruktur erforderlich. Dies geschieht automatisiert und für den Nutzer transparent im Hintergrund. Das spart zum einen Aufwand und Spezialwissen, zum anderen fallen bei der Nutzung des Dienstes nur Kosten pro Gigabyte der aus S3 gelesenen Daten an.
Vortrag zum Online-Campus
Einen tieferen Einblick zu den technischen Hintergründen sowie den Einsatz- und Optimierungsmöglichkeiten gibt es im nachfolgender Aufzeichnung von unserem ersten Online-Campus. In diesem Video werden Erfahrungen aus der Praxis diskutiert und eine kurze Live-Demo in der AWS-Konsole gezeigt.
So genannte „Web Components“ sind eine Möglichkeit, wiederverwendbare UI-Komponenten für Web-Anwendungen zu bauen. Anders als bei etablierten Single-Page-App-Frameworks wie React oder Angular basiert das Komponenten-Modell aber auf Web-Standards. Da SPA-Frameworks aber weit mehr leisten als nur Komponenten zu bauen, stehen Web Components nicht in unmittelbarer Konkurrenz zu den etablierten Frameworks. Sie können diese aber sinnvoll ergänzen. Insbesondere dann, wenn Komponenten über Anwendungen mit verschiedenen Technologie-Stacks hinweg wiederverwendet werden sollen, können Web Components einen guten Dienst leisten.
Im Detail verbergen sich aber doch einige Tücken, wenn es um den Einsatz von Web Components in Single-Page-Anwendungen geht: Während die Einbindung in Angular-Anwendungen relativ einfach funktioniert, gibt es insbesondere bei React-Anwendungen einiges zu beachten.
Ob die „Schuld“ hierfür nun bei React oder dem Web-Components-Standard liegt, kommt auf die Perspektive an und ist nicht ganz so leicht zu beantworten. Es gibt aber auch Aspekte, bei denen Web Components auch in ihrer Kernkompetenz, dem Bauen von Komponenten den Kürzeren ziehen. Denn manches ist im Vergleich, z. B. mit React, unnötig kompliziert oder unflexibel.
Abbildung 1: Web Components und SPA-Frameworks
In dieser Artikelreihe soll es um diese und weitere Aspekte beim Zusammenspiel von Web Components und SPA-Frameworks, insbesondere React, gehen. Im ersten Teil der Reihe liegt der Fokus aber zunächst nur auf Web Components, was sich hinter dem Begriff verbirgt und wie man Web Components baut.
Was sind Web Components und wie baut man eigene Komponenten?
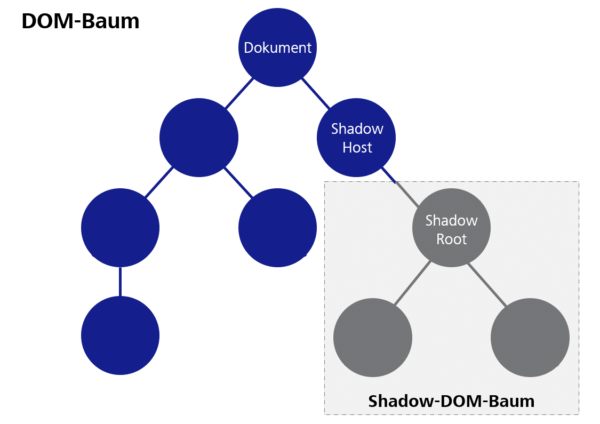
Hinter dem Begriff „Web Components“ verbergen sich mehrere separate HTML-Spezifikationen, die verschiedene Aspekte beim Entwickeln eigener Komponenten behandeln. Es gibt also nicht „den einen“ Standard für Web Components, sondern es handelt sich um eine Kombination von mehreren Spezifikationen.
Die beiden wichtigsten sind „Custom Elements“ und „Shadow DOM“. Die Custom-Elements-Spezifikation beschreibt u. a. die JavaScript-Basis-Klasse „HTMLElement“, von welcher eigene Komponenten abgeleitet werden müssen. Diese Klasse stellt zahlreiche Lifecycle-Methoden bereit, mit denen auf diverse Ereignisse im Lebenszyklus der Komponente reagiert werden kann. Beispielsweise lässt sich programmatisch darauf reagieren, dass die Komponente in einem Dokument eingehangen oder Attribute der Komponente gesetzt wurden. Entwickler und Entwicklerinnen einer Komponente können daraufhin die Darstellung der Komponente aktualisieren. Außerdem gehört zu Custom Elements die Möglichkeit, eigene Komponenten-Klassen unter einem bestimmten HTML-Tag zu registrieren, damit die Komponente anschließend im gesamten Dokument zur Verfügung steht.
Hinter „Shadow-DOM“ verbirgt sich eine Technik, mit der für eine Komponente ein eigener DOM-Baum angelegt werden kann, der vom restlichen Dokument weitestgehend isoliert ist. Das bedeutet, dass zum Beispiel CSS-Eigenschaften, die global im Dokument gesetzt wurden, nicht im Shadow-DOM wirksam sind und in die andere Richtung auch CSS-Definitionen innerhalb einer Komponente keine Auswirkungen auf sonstige Elemente im Dokument haben. Das Ziel ist eine bessere Kapselung der Komponenten und die Vermeidung von unerwünschten Seiteneffekten beim Einbinden von fremden Webkomponenten.
Im folgenden Code-Block ist eine einfache Hallo-Welt-Komponente zu sehen, die ein Property für den Namen der zu grüßenden Person enthält.
Im Konstruktor der Komponente wird zunächst für die Komponente ein eigener Shadow-DOM-Baum angelegt. Die Angabe „mode: open“ bewirkt, dass trotz der Shadow-DOM-Barriere von außen mittels JavaScript auf den DOM-Baum der Komponente zugegriffen werden kann.
Anschließend wird der „shadowRoot“, also der Root-Knoten des Shadow-DOM, entsprechend unserer Wünsche gestaltet – hier mittels „innerHTML“.
Mit „observedAttributes“ erklären wir, welche Attribute die Komponente haben soll bzw. bei welchen Attributen wir benachrichtigt werden möchten (wir können hier also auch Standard-Attribute wie „class“ angeben).
Die Benachrichtigung findet über die Methode „attributeChangedCallback“ statt, die als Parameter den Namen des geänderten Attributs sowie den alten und neuen Wert erhält. Da wir in unserem Fall nur ein einziges Attribut in „observedAttributes“ angegeben haben, wäre eine Prüfung auf den Namen des Attributs eigentlich nicht notwendig. Bei mehreren Attributen muss aber stets geschaut werden, welches Attribut gerade geändert wurde.
In unserem Fall prüfen wir zunächst, ob sich der neue Wert tatsächlich vom bisherigen unterscheidet (wir werden später noch sehen, wie das zustande kommen kann). Anschließend setzen wir die Property „person“, die wir als Klassenvariable angelegt haben, auf den Wert des übergebenen Attributs.
Um die Darstellung der Komponente zu aktualisieren wurde im Beispiel die Methode „update“ angelegt. Diese gehört nicht zum Custom-Elements-Standard, sondern dient hier nur dazu, die Update-Logik an einer Stelle zu sammeln. Darin holen wir das zuvor angelegte Span-Element mit der ID „person“ aus dem Shadow-DOM und setzen dessen Text auf den Wert der „person“-Property.
Abbildung 2: Shadow DOM
Als letzten Schritt sieht man im Code-Beispiel, wie unsere Komponenten-Klasse mit dem Tag-Namen „app-hello-world“ registriert wird. Wichtig ist hier, dass der Name mindestens ein Minus-Zeichen enthält. Diese Regel wurde geschaffen, um mögliche Namens-Kollisionen mit zukünftigen Standard-HTML-Tags zu vermeiden. Es hat sich daher als zweckmäßig erwiesen, ein sinnvolles Präfix für eigene Komponenten zu wählen, um so auch Kollisionen mit anderen Komponenten-Bibliotheken möglichst zu vermeiden (das im Beispiel gewählte Präfix „app“ dürfte in dieser Hinsicht kein gutes Vorbild sein). Ein wirklich sicherer Mechanismus zur Vermeidung von Konflikten existiert jedoch nicht.
Mittels Attribute haben wir nun also die Möglichkeit, einfache Daten in die Komponente hineinzureichen. Beim Thema „Attribute“ gibt es noch einige Besonderheiten und Fallstricke, die wir aber für den nächsten Teil dieser Artikelreihe aufheben wollen. Für diese allgemeine Einführung wollen wir es erst einmal dabei belassen.
Slots
Ein weiteres wichtiges Feature von Web Components, welches uns ebenfalls in einem späteren Teil der Reihe nochmal beschäftigen wird, sind die sogenannten Slots. Damit lassen sich HTML-Schnipsel an eine Komponente übergeben. Die Komponente entscheidet dann, wie sie die übergebenen Elemente darstellt. Wollen wir beispielsweise eine Hinweisbox bauen, die neben einem Text auch ein Icon darstellt und mit einem Rahmen umgibt, bietet es sich an, den Hinweistext nicht als Attribut, sondern mit einem Slot an die Komponente zu geben. Auf diese Weise sind wir nicht nur auf reinen Text beschränkt, sondern können beliebigen HTML-Content nutzen.
In der Anwendung kann das beispielsweise so aussehen:
<app-notification-box>
<p>Some Text with additional <strong>tags</strong></p>
</app-notification-box>
Wir müssen also nur die gewünschten HTML-Tags als Kindelemente schreiben. Innerhalb der Komponente muss dafür ein <slot>-Element im Shadow-Root auftauchen. Anstelle des Slot-Elements wird beim Rendering der Komponente dann der übergebene Content angezeigt.
Eine Komponente kann auch mehrere Slots enthalten. Damit der Browser aber entscheiden kann, welche HTML-Elemente er welchem Slot zuordnen soll, müssen in diesem Fall sogenannte „Named Slots“ benutzt werden, d. h. die Slots bekommen ein spezielles Name-Attribut. Nur höchstens ein Slot darf innerhalb einer Komponente ohne Name-Attribut vorkommen. Bei diesem spricht man vom „Default Slot“. In der Komponente kann das z. B. so aussehen:
Hier sieht man die Nutzung des „slot“-Attributs. Die Werte müssen zu den „name“-Attributen an den Slots innerhalb der Komponente passen. Folglich gehört dies zum Teil der öffentlichen API einer Komponente und muss entsprechend dokumentiert werden.
Events
Bisher haben wir nur gesehen, wie Daten in Komponenten hineingereicht werden können, jedoch noch nicht den umgekehrten Weg skizziert. Denn um wirklich interaktiv zu sein, müssen Entwickler und Entwicklerinnen auch die Möglichkeit haben, auf bestimmte Ereignisse zu reagieren und Daten von der Komponente entgegenzunehmen.
Für diesen Zweck dienen bei HTML Events. Und auch diesen Aspekt wollen wir uns in diesem Artikel nur kurz anschauen und später genauer unter die Lupe nehmen.
Web Components können sowohl Standard Events als auch Custom Events erzeugen.
Standard-Events sind dann nützlich, wenn die Art des Events so auch schon bei Standard-HTML-Elementen vorkommt und daher nicht neu erfunden werden muss, beispielsweise ein KeyboardEvent. Custom-Events sind dann sinnvoll, wenn zusätzliche Daten als Payload dem Event mitgegeben werden sollen. Wenn wir beispielsweise eine eigene interaktive Tabellenkomponente bauen, in der die Nutzenden einzelne Zeilen selektieren können, bietet es sich möglicherweise an, ein Event bei der Selektion auszulösen , welches als Payload die Daten der gewählten Zeile enthält.
Der Mechanismus zum Auslösen von Events ist für alle Arten von Events gleich. Dies ist im folgenden Code-Block zu sehen:
Zur Erzeugung eines Events wird entweder direkt eine Instanz von „Event“ oder eine der anderen Event-Klassen (zu denen auch „CustomEvent“ gehört) erzeugt. Alle Event-Konstruktoren erwarten als ersten Parameter den Type des Events. Dieser Typ wird später auch benutzt, um Listener für diese Events zu registrieren.
Der zweite Parameter ist optional und stellt ein JavaScript-Objekt dar, welches das Event konfiguriert. Für CustomEvent ist beispielsweise das Feld „detail“ vorgesehen, um beliebige Payload-Daten zu übergeben.
Fazit
Der Artikel gibt eine kurze Einführung in das Thema „Web Components“ und mit den gezeigten Techniken können bereits eigene Komponenten gebaut werden. Natürlich gibt es noch zahlreiche weitere Aspekte, die bei der Entwicklung von Web Components beachtet werden müssen. Nicht umsonst füllt das Thema so manches Fachbuch. In dieser Artikelreihe wollen wir vor allem auf einige Fallstricke eingehen, die bei einzelnen Themen auftreten können und genauer beleuchten, wie diese umgangen werden können. Auch eine kritische Auseinandersetzung mit der Web-Components-API soll Teil dieser Serie werden. Insbesondere das Zusammenspiel mit SPA-Frameworks wird uns in den nächsten Artikeln beschäftigen.
Wenn man in den Vertrieb wechselt, wird eine Sache schnell klar: Der Kaffeekonsum wird steigen. Denn wenn der Kunde fragt, ob man einen Kaffee möchte – wer beginnt dann schon gern ein Kennenlernen mit einem „Nein“?
Der Kaffee ist in der Regel der Teil des Small Talks, der zu Beginn der meisten Vertriebstermine eine positive Basis für das erste Treffen schafft. Beim Gespräch über den Kaffee, die Sorte, die Zubereitungsart etc. sowie auf dem gemeinsamen Weg zur Kaffeeecke lernt man sich kennen und baut eine erste Beziehung zueinander auf. Eine Basis, die man schätzen lernt.
Zumindest war das bisher so – doch dann kam Corona! Nicht nur, dass durch den Wegfall von Flügen der Weg zu den Kunden erschwert wurde, so machte sich im ersten Moment auch Ratlosigkeit breit. Wie können wir neue Themen bei bestehenden oder neuen Kunden identifizieren? Wie können wir Themen bei sinkenden Budgets und Umpriorisierungen für uns entscheiden, ohne vor Ort zu sein? Wie bauen wir das notwendige Vertrauen zueinander auf, ohne gemeinsam an einem Tisch gesessen zu haben?
Vor allem auch für den Dienstleistungssektor schienen diese Hürden zunächst unüberwindbar zu sein – zum Glück jedoch nur im ersten Schritt. Denn wie auch in anderen Unternehmensbereichen der ZEISS Digital Innovation haben wir uns im Vertrieb und im Bereich der Positionierung angeschaut, welche Werkzeuge unsere Entwicklungsteams nutzen, die schon seit vielen Jahren standortverteilte Softwareentwicklung betreiben. Und davon haben wir uns inspirieren lassen.
Der 14-tägige Abgleich aller Vertriebskollegen wurde ohnehin schon immer verteilt gelebt und durch unser CRM (SalesForce) unterstützt. Doch darüber hinaus sind wir auch in unserem Neukundenvertrieb inkl. Marketing-Team zu einem Daily-Modus gewechselt. So haben wir unseren Vertriebssprint von vier Monaten auf vier Wochen reduziert. D. h. morgens 9:30 Uhr synchronisiert sich das Marketing-Team entlang der Kampagnen mit dem Neukundenvertrieb und spricht über Ergebnisse, To-dos und Herausforderungen. Alle vier Wochen finden dann eine Retro, ein Review und ein Planning statt, in denen wir die vergangenen vier Wochen abschließen und reflektieren sowie die folgenden Wochen planen. Der neue Vier-Wochen-Rhythmus war notwendig, da Ende März 2020 noch niemand sagen konnte, welche Themen wir im Juni prioritär bearbeiten müssten – dies wäre jedoch eine nötige Voraussetzung gewesen, um den bis dahin genutzten Vier-Monatszyklus aus der Zeit vor Corona weiterführen zu können.
Damit wir die neuen verteilten Dailys auch aus dem Homeoffice leben konnten, kamen zu Beginn Skype for Business und der Microsoft Planner zum Einsatz. Später sind wir dann auf MS Teams umgeschwenkt und haben punktuell das zugehörige MS Whiteboard für die inhaltliche Arbeit herangezogen.
Dadurch haben wir nun ein Tool-Set, welches sich auch im Zusammenspiel mit Kunden in den letzten Wochen als sehr positiv erwiesen hat. MS Teams ist gefühlt in allen Organisationen angekommen und die Bereitschaft aller in der Nutzung von Conferencing-Tools ist um ein Vielfaches höher, sodass man schnell und unkompliziert diesen Weg beschreiten kann. Was wir als besonders positiv empfinden, ist die Bereitschaft, sich bei einem Meeting nicht nur über Audio auszutauschen, sondern auch den Videostream anzuschalten. Denn den Videostream zwischen den Beteiligten könnte man auch als das „Ersatzkaffeetrinken“ beschreiben – es gibt beiden Seiten ein besseres Gefühl füreinander und reduziert Interpretationsprobleme, die man in Telefonkonferenzen sonst oft hat. Gerade mit neuen Kunden oder neuen Ansprechpartnern ist dieses Vorgehen ein echter Segen für die folgende Zusammenarbeit.
Doch auch in den Projektvorphasen mussten wir unsere Rituale etwas anpassen. So konnten wir u. a. keinen zweitägigen Projektvisionsworkshop mit dem Kunden an einem Ort durchführen. Alternativ sind es nun 4 x 0,5 Tage mit jeweils 2x 2 h Sessions in MS Teams, die mit Hilfe eines Microsoft Whiteboards direkt und für alle sichtbar und editierbar dokumentiert werden. So war es uns möglich, mehrere Projekte auch in der Corona-Zeit anzugehen – sogar mit neuen Kunden, die vorher noch nie mit uns zusammengearbeitet hatten.
Das Ganze ist ein neues Szenario, welches für uns im Vertrieb immer noch etwas unwirklich und seltsam wirkt und den Vertrieb sicher nachhaltig verändern wird. Am Ende trinken wir wieder zusammen Kaffee – jedoch jeder an seinem Arbeitsplatz und verbunden durch MS Teams, Skype und Co.
Bei der ZEISS Digital Innovation wird der verteilte Ansatz schon lange gelebt. Gerade zu Corona-Zeiten ist dieser Ansatz gefragter denn je. Die gute Nachricht: Die Arbeit kann auch von zu Hause aus weiter gehen. Aber Remote-Arbeit ist nicht nur im Homeoffice möglich, sondern auch an unterschiedlichen Standorten und Büros.
Das klassische Pairing wird bereits sehr erfolgreich in der agilen Softwareentwicklung eingesetzt. Es ist eine effiziente Methode, um komplexe Aufgaben zusammen zu lösen und das bestmögliche Ergebnis durch das Wissen von zwei Personen zu erzielen. Außerdem ist es ein optimales Hilfsmittel, um Wissen zu verteilen. Durch eine ausführliche Kommunikation der Gedanken und Ideen erreichen beide Teilnehmer am Ende ein ähnliches Know-how-Level. In diesem Beitrag möchte ich daher zeigen, wie die verteilte Zusammenarbeit gelingen kann.
Vorstellung der Methode: Pair Testing
Das Pairing beinhaltet die Aufteilung des Paares in zwei Rollen. Auf der einen Seite gibt es den Driver. Dieser setzt seine Testidee um und teilt seine Gedanken dem Navigator mit. Hierbei erklärt der Driver alles, was er tut, so transparent wie möglich. Dadurch kann der Navigator die Ansätze und Schritte des Drivers nachvollziehen.
Auf der anderen Seite gibt es den Navigator. Dieser überprüft die Eingaben des Drivers und teilt ebenfalls seine Gedanken dazu mit. Dadurch können neue Lösungswege aufgezeigt werden und der Navigator kann durch Fragen seine Unklarheiten beseitigen. So lernen beide voneinander.
Damit jeder die Chance bekommt, die Anwendung zu erleben und seine Ideen umzusetzen, wechseln die Rollen regelmäßig. Der Wechsel erfolgt nach einer abgeschlossenen Testidee oder nach einigen Minuten. Dies wird auch die Rotation der Rollen genannt.
Abbildung 1: Driver und Navigator
Remote Arbeit: Technische Voraussetzungen
Damit beide Parteien remote miteinander arbeiten können, bedarf es einer geeigneten Konferenzsoftware, beispielsweise MS Teams oder Skype. Damit kann das Testobjekt via Screensharing geteilt werden. Für den Arbeitsprozess gibt es zwei Möglichkeiten:
Zum einen kann für die Rollenrotation die Maussteuerung abwechselnd eingefordert werden.
Alternativ kann auch zum Rollenwechsel die Bildschirmfreigabe gewechselt werden. Allerdings benötigen dann beide den Zugriff auf das Testobjekt. Ebenso kann ein Gedanke nicht direkt weitergeführt werden, da sich die Applikation nach dem Wechsel in einem anderen Zustand befindet.
Wenn man den Ansatz des Rollenwechsels nach einigen Minuten verfolgt, kann für das Stoppen der Zeit jede beliebige Stoppuhr-Funktion (bspw. Handy-Uhr) verwendet werden. Jedoch kann das zu Problemen führen, wenn man mitten in der Testidee unterbrochen wird und diese dann ggf. vom neuen Driver weiterverfolgt werden muss. Daher lohnt es sich hier, die Rotation nach abgeschlossenen Testideen durchführen zu lassen.
Pair Testing: Allgemeine Voraussetzungen
Um ein Gelingen des verteilten Arbeitens zu bewirken, gibt es noch andere Aspekte zu beachten.
Die Aufgaben für die Pair-Testing-Session sollten groß und komplex genug sein, so dass sie zu zweit gelöst werden können. Daher ist eine gute Vorbereitung der Session wichtig – hierbei sollten geeignete Aufgabenstellungen zurechtgelegt werden. Diese Inhalte können z. B. Stories sein, die getestet werden sollen.
Fokussierte Zusammenarbeit erfordert viel Konzentration. Daher ist es wichtig, abgestimmte Pausen einzulegen, um wieder Energie zu tanken. Einfache Aufgaben können auch allein schnell und effektiv gelöst werden. Daher ist es ratsam, sich Zeitfenster zu schaffen, in denen Pair-Testing-Sessions für die vorbereiteten Inhalte durchgeführt werden. Das kann dann z. B. bedeuten, dass man einen halben Tag zusammen im Paar testet und die andere Hälfte allein arbeitet.
Zusammenfassung
Pair Testing ist eine leichtgewichtige Methode, die von jedem unkompliziert eingesetzt werden kann. Mit der richtigen technischen Unterstützung ist sie auch remote einfach umzusetzen. So können wir voneinander lernen und uns bei komplizierten Aufgaben gegenseitig unterstützen, trotz weiter Entfernungen. Außerdem hilft die gemeinsame Arbeit, der Remote-Entfremdung vorzubeugen.
Softwareentwicklungsprojekte leben vom Einsatz moderner Testwerkzeuge, welche die Projektbeteiligten bei ihrer Arbeit unterstützen. Selenium gibt es seit dem Jahr 2004 und wirkt ggf. etwas angestaubt, aber trotzdem ist es nicht aus der Mode. Mit Selenium 4 holt es zu den neuen Herausfordern auf. Mit dieser Blogreihe möchte ich zeigen, was Selenium 4 bringt und wie sich mit einfachen Mitteln wichtige Funktionen einbauen lassen wie z. B. Screenshots, Videos, Reports und Ansätze von KI. Dabei versuche ich, die Ansätze nach ihrem Mehrwert (The Good) und ihren Herausforderungen (The Bad) zu bewerten sowie ggf. nützliche Hinweise (… and the Useful) zu geben.
Jason Huggins begann bereits 2004 mit der Arbeit an Selenium als internem Projekt zum Testen von Webseiten. Mit der Zeit entwickelte sich Selenium zum führenden Werkzeug in vielen Entwicklungsprojekten oder diente als Grundlage für andere Testwerkzeuge. Aktuell fühlt sich das Framework schon etwas altbacken an, aber es besticht gegenüber seinen Herausforderern mit einer breiten Unterstützung von Sprachen (Ruby, Java, Python, C#, JavaScript) und Browsern (Firefox, Internet Explorer, Safari, Opera, Chrome, Edge u. a.).
Was ist neu in Selenium 4?
Die Version 4, die für 2020 angekündigt ist, versucht, Selenium nun in die Moderne zu holen. Dazu gehören folgende Neuerungen:
WebDriver API wird W3C Standard
Damit wird es nur noch einen WebDriver für alle Browser geben.
Selenium4 IDE TNG
„TheNextGeneration“ Selenium IDE basiert auf Node JS und steht neben Firefox auch für Chrome bereit. Es lassen sich parallele Testläufe starten und es gibt erweiterte Testprotokollinformationen (Testergebnis, Laufzeit etc.).
Verbessertes WebDriver Grid
Das Einrichten sowie die Administration und der Docker-Support wurden verbessert.
Außerdem
Es gibt eine bessere UI und das Reporting / Logging wurden optimiert.
Dokumentation
Mit Version 4 soll es eine ausführliche Dokumentation und neue Tutorials geben.
Mit Version 4 setzt sich Selenium aus folgenden Teilen zusammen: dem Selenium WebDriver, der Selenium IDE und dem Selenium Grid. Der Selenium WebDriver ist eine Sammlung von verschiedenen Programmiersprachintegrationen, um Browser für eine Testautomatisierung anzusteuern. Die Selenium IDE ist ein Chrome oder Firefox Add-on, um direkt aus dem Browser mit der Testautomatisierung ohne Programmierkenntnisse zu starten und ermöglicht die Aufnahme und das Abspielen von Testfällen im Browser. Das Selenium Grid ermöglicht die gesteuerte und gleichzeitige Testdurchführung auf verschiedenen Maschinen und unterstützt die Administration unterschiedlicher Testumgebungen von einem zentralen Punkt aus. Damit lässt sich ein Testfall gegen verschiedene Browser- bzw. Betriebssystem-Kombinationen testen oder es lässt sich eine Liste von Testfällen skaliert auf mehreren Maschinen verteilt durchführen.
Selenium 4
The Good
The Bad
… and the Useful
WebDriver API → W3C Standardized Selenium 4 IDE TNG Improved WebDriver Grid Documentation
New challenger like cypress etc. Selenium 4 was announced for 2019
Neuere Frameworks zur Testautomatisierung besitzen bereits eine Funktion zur Erzeugung von Screenshots. Doch mit ein paar Codezeilen lässt sich auch in Seleniumtests die Möglichkeit für die Ablage von Screenshots einbauen.
private void screenShot(RemoteWebDriver driver, String folder, String filename) {
SimpleDateFormat dateFormat = new SimpleDateFormat("yyyyMMdd_HHmmss");
String timestamp = dateFormat.format(new Date());
try {
File scrFile = ((TakesScreenshot)driver).getScreenshotAs(OutputType.FILE);
// Now you can do whatever you need to do with it, for example copy somewhere
FileUtils.copyFile(scrFile, new File(folder + filename + "_" + timestamp + ".png"));
}
catch (IOException e) {
System.out.println(e.getMessage());
}
}
Dabei sollte man aber immer bei der Erzeugung und der Ablage der Datei auf den Einsatzzweck von Screenshots achten. Screenshots können zum einen dem Debugging dienen und auf Probleme hinweisen. Darum ist es sinnvoll, ggf. die Screenshots nur dann zu erzeugen, wenn Probleme auftreten. Nach diesem Ansatz kann man die Screenshot-Funktionalität um einen flexiblen und globalen Schalter erweitern, der sich je nach Notwendigkeit setzen lässt.
Zum anderen können Screenshots der Dokumentation der Testergebnisse dienen und in manchen Projekten sogar vorgeschrieben sein, da hier gesetzliche oder andere Vorgaben eingehalten werden müssen. Dann muss die Ablage der Screenshots nachvollziehbar sein und sich jede erzeugte Datei einen Testfall und dem zugehörigen Testlauf zuordnen lassen. Nach diesem Ansatz muss der Dateiname einen Verweis auf den Testfall und einen passenden Zeitstempel haben. Darüber hinaus muss auch das Ablageverzeichnis für diesen einen Testlauf erzeugt und benannt werden.
Screenshots
The Good
The Bad
… and the Useful
Ermöglicht den Nachweis des Ergebnisses des Testlaufs
Kann nur einen Moment darstellen
Kann auch zum „Debuggen“ genutzt werden
Im meinem nächsten Beitrag erstellen wir ein Video der Testdurchführung.
Die aktuelle Krise, ausgelöst durch COVID-19, beschäftigt nun schon seit vielen Wochen die Welt und stellt viele Unternehmen vor neue Herausforderungen. Von jetzt auf gleich zogen auch bei uns fast 95 % der Mitarbeiter für mehrere Wochen komplett ins Homeoffice um und arbeiten größtenteils immer noch viel von zu Hause aus. Wie hat sich das insbesondere auf meine Arbeit im Sales und Marketing Team ausgewirkt?
Während die verteilte und ortsunabhängige Arbeit in den Projektteams schon in großen Teilen zum Alltag gehört (siehe auch der Blogbeitrag „Softwareentwicklung in Zeiten von Corona – Business as usual?“), war dies allerdings in den zentralen Diensten (Buchhaltung, IT, Personal, Marketing, …) eine Neuerung. Als interner zentraler Dienstleister für die Mitarbeiter der ZEISS Digital Innovation lag der Fokus hier immer darauf, vor Ort zu sein, um direkt auf die Anliegen der internen „Kunden“ reagieren zu können. Zeitgleich mit unserer Angliederung ans Team ZEISS und dem damit verbundenen sehr hohen Workload durch den Brand Change, stellte uns der Wechsel ins heimische Office somit vor zusätzliche Herausforderungen.
Abbildung 1: Mein Arbeitsplatz im Homeoffice
Wie haben wir es dennoch geschafft, diesen Übergang nahezu reibungslos zu meistern und die Performance hoch zu halten? Indem wir uns auch hier an Vorgehensweisen aus der agilen Welt orientiert haben!
Bereits seit vielen Jahren setzen wir sowohl beim Vorgehen in den Projekten als auch im Management auf agile Methoden und haben dort nicht nur ein eigenes Vorgehensmodell entwickelt, sondern auch für die Zusammenarbeit in den zentralen Diensten verschiedenste Werte, Artefakte und Arbeitsweisen adaptiert. Diese helfen uns in dieser schwierigen Phase sowohl im Allgemeinen bei der internen Kommunikation der ZEISS Digital Innovation als auch im Speziellen bei der Zusammenarbeit in meinem Team, welches momentan aus fünf Personen besteht. Hierbei ist wichtig zu erwähnen, dass wir uns nur an diesen Arbeitsweisen ORIENTIEREN und diese nicht 1:1 nach Lehrbuch umsetzen, sondern für unser Unternehmen angepasst haben.
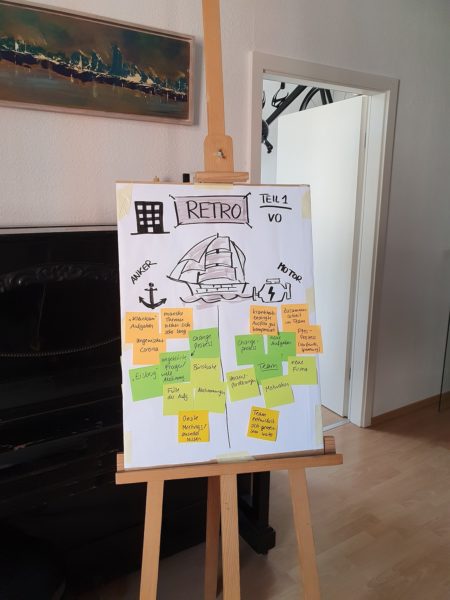
Durch ein iteratives Vorgehen inkl. Planning, Review und Retrospektiven stellen wir sicher, dass unsere Kampagnen innovativ bleiben, wir uns auch bei sehr vielen parallelen Kampagnen auf die richtigen Dinge fokussieren und uns vor allem auch regelmäßig hinterfragen. Reflexionstermine nach unseren Kampagnen (ähnlich Projekt-Retros), aus denen wir Lessons Learned ableiten, gehören dabei für uns ebenso dazu wie eine offene Kommunikation, ehrliches Feedback sowie Kreativtermine und Brainstorming-Runden zu neuen Themen. Kreatives Arbeiten und ein agiles Mindset setzen daher ohnehin schon eine gewisse Bereitschaft zur Anpassung voraus, so dass wir es geschafft haben, unsere Zusammenarbeit schnell neu zu organisieren und uns an die neuen Gegebenheiten anzupassen.
Abbildung 2: Team-Retro mit improvisiertem Whiteboard
Doch was heißt das nun konkret? Welche „Hilfsmittel“ haben uns geholfen, uns trotz Homeoffice und Verteilung zu organisieren?
Dailys
Da wir uns nicht mehr jeden Tag direkt im Büro gegenübersitzen und man natürlich so nicht mitbekommt, an welchen Themen der jeweils andere arbeitet, haben wir schnell festgestellt, dass aufgrund der Verteilung ein erhöhter Abstimmungsbedarf entsteht. Um dem entgegenzuwirken, haben wir nach sehr kurzer Zeit Dailys eingeführt. Jeden Morgen synchronisiert sich das Team kurz (wir haben für uns 20 min definiert) über die anstehenden Tagesaufgaben und die erledigten Arbeitspakete des vorherigen Tages. Wichtig ist hier insbesondere, dass JEDER zu Wort kommt und auch kurz erzählt, ob es bei ihm ggf. Herausforderungen gibt, die die Arbeit behindern könnten (Meeting-Marathon, Kinderbetreuung, …). Unter anderem um sicherzustellen, dass die Timebox eingehalten wird, moderiert der im Team ernannte Scrum Master das Daily. Dieser hat insbesondere auch darauf zu achten, dass eventuell aufkommende Diskussionen im Anschluss in separaten AdHoc Meetings weitergeführt werden und nicht das Daily blockieren.
Iterative Planung in kurzen Zyklen
Aufgrund von Corona und damit einhergehenden, sich ständig ändernden Rahmenbedingungen (ausgefallene Veranstaltungen, sich ändernde Kommunikationswege, …) sind wir bei der Planung unserer Kampagnen von einem dreimonatigen Planungszyklus in einen vierwöchigen Turnus gewechselt. Damit können wir unsere Arbeit stetig an die sich ändernden Prioritäten (Bewertung immer nach Dringlichkeit und Wichtigkeit) anpassen. Um sicherzustellen, dass wir dennoch keine langfristigen Aufgaben vergessen, haben wir einen Backlog, in dem alle Aktivitäten landen, die wir langfristig bearbeiten wollen, die aber nicht dringend oder wichtig sind.
Dieser Backlog ist auch eng verknüpft mit dem nächsten Thema.
Visualisierung mit geeigneten Tools und eine gute Infrastruktur
Die technischen Voraussetzungen sind essenziell, um gemeinsam an Themen arbeiten zu können. Ein Sharepoint bzw. OneDrive zum Teilen von Dateien, Videotelefonie über Skype und MS Teams, ein Wiki mit einer transparenten Kampagnendokumentation und natürlich ein gemeinsames Aufgabenboard sind hier Gold wert und nur ein kleiner Auszug der Tools, mit denen wir arbeiten. Um unsere Aufgaben stets im Blick zu haben, setzen wir im Team vor allem auf Microsoft Teams und den darin integrierten Microsoft Planner. Hier haben wir, ähnlich einem Kanban Board, alle Aufgaben übersichtlich gesammelt und können bei Planning und Review auswerten, was wir erreicht haben und was wir uns für die nächsten Iterationen vornehmen wollen. Als internes Service Center werden ständig Anforderungen an uns herangetragen, welche wir unter anderem dort dokumentieren, um so sicherzustellen, dass Aufgaben (auch insbesondere bei unvorhergesehenen Ausfällen oder in Vertretungssituationen) nicht vergessen werden. Generell ist Transparenz oberstes Gebot, wobei wir uns aber auch an dem (abgewandelten) Satz aus dem agilen Manifest orientieren: Funktionierende Software Kampagnen mehr als umfassende Dokumentation (https://agilemanifesto.org/iso/de/manifesto.html).
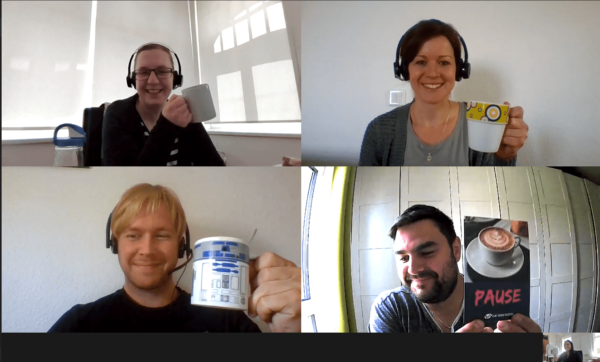
Schön und gut, wenn Prozesse und Werkzeuge funktionieren. Doch was ist mit der zwischenmenschlichen Kommunikation? Wir streben in der Zusammenarbeit eine Atmosphäre an, die neben offener Kommunikation auf Werten wie Vertrauen, Commitment, Offenheit und gegenseitigem Respekt basiert. Und im Mittelpunkt dieser Zusammenarbeit stehen immer Menschen und ein funktionierendes Team, in dem man sich aufeinander verlassen kann. Dieses Teamgefühl entsteht sicher auch durch die kleinen Gespräche zwischendurch über den Schreibtisch hinweg, ein gemeinsames Mittagessen oder eben einen kurzen Plausch an der Kaffeemaschine außerhalb des Meetings. All dies ist bei der verteilten Arbeit und beim „Social Distancing“ nur schwer umsetzbar und entfällt zu großen Teilen. Um uns als Team dennoch nicht „auseinander zu leben“ haben wir einmal in der Woche eine virtuelle Kaffeepause eingeführt. Diesen Termin nutzen wir bewusst, um auch einmal bei einer Tasse Kaffee (oder einem anderen Getränk) über Off-Topic-Themen zu sprechen und darüber, was uns zur Zeit so beschäftigt. Eben über die Dinge, die man sonst in den Pausen und auf dem Gang mal besprechen würde – bewusst nicht über Themen, die mit dem eigentlichen Aufgabenfeld zu tun haben. Und natürlich mit Video, um sich gegenseitig auch mal wieder zu sehen!
Abbildung 3: Wöchentlich stattfindende virtuelle Kaffeepause im Team
Doch auch über die Teamebene hinaus helfen uns bereits etablierte Formate, die aus unserem agilen Managementprozess resultieren – so z. B. unser ZEISS Stand-Up (Betriebsvollversammlung). Normalerweise in sechswöchigem Turnus stattfindend und im Anschluss an ein gemeinsames Pizzaessen an allen Standorten, informiert hier unser Management zu allen wichtigen aktuellen Themen, Zahlen, Daten und Fakten. Jeder Mitarbeiter, der Interesse hat, daran teilzunehmen, bekommt hier die Möglichkeit, während seiner Arbeitszeit vor Ort oder über Skype zuzuhören und im Anschluss auch Fragen zu stellen. Als wichtiger Eckpfeiler unserer Unternehmensinformation und -kommunikation sorgt dies für Transparenz auf allen Ebenen und findet seit dem 20.03.2020 sogar wöchentlich statt, um alle über die aktuellen Entwicklungen des Unternehmens in der Krise und ggf. getroffene Maßnahmen zu informieren. Neben den wirtschaftlichen Auswirkungen werden hier unter anderem auch spezielle Fragen besprochen, wie z. B. unser Hygienekonzept, das „Corona-Elterngeld“ bei Minusstunden und noch vieles mehr. Ein weiteres kleines Puzzlestück, das einem Sicherheit und Vertrauen gibt und die unternehmensweite Zusammenarbeit in dieser Krise erleichtert.
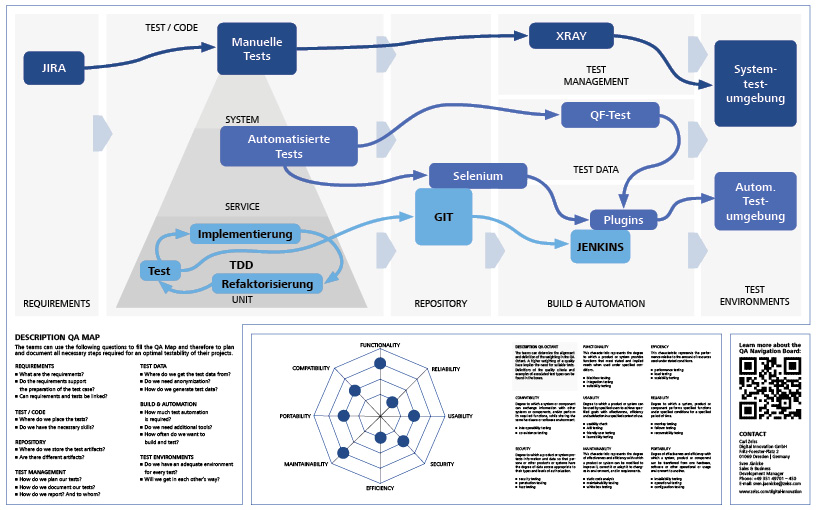
Mit Hilfe unseres agilen Visualisierungswerkzeugs, dem QA Navigation Board, möchten wir eine Methode vorstellen, mit der agile Entwicklungsteams typische QA-Problemfälle und deren Auswirkungen erkennen und diese beseitigen können.
Vergleichbar mit einem falschen Architekturansatz oder der Verwendung der falschen Programmiersprache kann eine falsche Test- und Qualitätssicherungsstrategie im Laufe des Projektes zu Beeinträchtigungen führen. Im besten Fall kommt es nur zu Verzögerungen oder Mehraufwand. Im schlechtesten Fall wird unzureichend getestet und es tauchen immer wieder schwerwiegende Abweichungen im Betrieb der Anwendung auf.
Einführung
Die Probleme werden durch die agilen Entwicklungsteams bemerkt und die Auswirkungen in der Retrospektive dokumentiert, aber oft können sie wegen fehlender QA-Expertise nicht die Ursache erkennen und somit das Problem auch nicht beheben. Das Team benötigt in diesen Fällen Unterstützung durch einen agilen QA-Coach. Dieser zeichnet sich dabei zum einen durch seine Kenntnisse in der agilen Arbeitsweise aus, aber zum anderen auch durch seine Erfahrungen in der agilen Qualitätssicherung.
Der erste Schritt in der Arbeit des agilen QA-Coaches ist es, den aktuellen Stand des Testvorgehens des agilen Entwicklungsteams festzuhalten. Dazu nutzt er zum Beispiel in einem Workshop das sogenannte QA Navigation Board. Mit dem QA Navigation Board haben die Entwicklungsteams ein visuelles Hilfsmittel, mit dem sie die planerischen Aspekte der Qualitätssicherung beurteilen können. Dabei kann das QA Navigation Board innerhalb der Projektlaufzeit auch als Referenz des aktuellen Vorgehens und als Ansatz für potenzielle Verbesserung genutzt werden.
Anti-Pattern
Darüber hinaus ermöglicht das QA Navigation Board eine Anamnese des aktuellen Testvorgehens. Der agile QA-Coach kann durch die Visualisierung bestimmte Symptome für Anti-Pattern im Qualitätssicherungs- und Testprozess aufdecken und diese mit dem Team direkt besprechen. Als Anti-Pattern werden in der Softwareentwicklung Lösungsansätze bezeichnet, die ungünstig oder schädlich für den Erfolg eines Projektes oder einer Organisation sind.
Nachfolgend möchte ich verschiedene Anti-Pattern vorstellen. Neben den Eigenschaften zur Identifikation, stelle ich noch deren Auswirkungen dar. Im Sinne des Gegenstücks zum Anti-Pattern, dem Pattern, werden auch gute und bewährte Problemlösungsansätze vorgestellt.
Anti-Pattern – Wird schon gut gehen
Dieses Anti-Pattern zeichnet sich durch das komplette Fehlen von Tests oder anderen Maßnahmen zur Qualitätssicherung aus. Dadurch ergeben sich schwerwiegende Konsequenzen für das Projekt und das Produkt. Das Team kann keine Qualitätsaussage über das Ergebnis seiner Arbeit treffen und besitzt damit streng genommen kein auslieferungsfähiges Produkt. Die Fehler tauchen beim Endanwender auf und sorgen damit immer wieder für Ablenkung im Entwicklungsprozess des Teams, da die sogenannten Incidents aufwendig analysiert und behoben werden müssen.
Keine Tests
Auswirkungen
Lösung
• Es gibt keine Tests
• Keine Qualitätssausage
• „Schnell weggehen“
• Getestet wird beim Anwender
• QA einführen
Der Lösungsansatz ist einfach: Testen! Je eher Abweichungen gefunden werden, desto einfacher lassen sie sich beseitigen. Darüber hinaus sorgen Qualitätssicherungsmaßnahmen wie Codereviews und statische Codeanalyse als konstruktive Maßnahmen für eine Verbesserung.
Anti-Pattern – Dysfunktionaler Test
Laut ISO 25010 gibt es acht verschiedene Qualitätskriterien für Software: Funktionalität, Effizienz, Kompatibilität, Benutzbarkeit, Zuverlässigkeit, Sicherheit, Wartbarkeit und Übertragbarkeit. Meist liegt der Schwerpunkt bei der Umsetzung neuer Software auf der Funktionalität, aber heutzutage spielen anderen Kriterien wie Sicherheit und Benutzbarkeit eine wichtige Rolle. Je höher die Priorität der anderen Qualitätskriterien ist, desto wahrscheinlicher ist es, für diese einen nicht-funktionalen Test vorzusehen.
Darum sollte die erste Frage zu Beginn eines Softwareprojektes lauten, auf welchen Qualitätskriterien der Fokus der Entwicklung und damit auch der Qualitätssicherung liegt. Um den Teams einen einfachen Einstieg in das Thema zu geben, nutzen wir den QA-Oktanten. Folgend der ISO 25010 beinhaltet der QA-Oktant die Qualitätskriterien für Softwaresysteme. Sie geben aber auch einen Hinweis auf die notwendigen Testarten, welche sich aus der gesetzten Gewichtung der unterschiedlichen funktionalen und nichtfunktionalen Kriterien ergeben.
Nur funktionale Tests
Auswirkungen
Lösung
• Es gibt nur funktionale Tests
• Keine Qualitätssausage über nicht-funktionale Kriterien
• Wichtige Qualitätskriterien mit Kunden besprechen
• Es geht wie gewollt, aber …
• Nicht-funktionale Testarten
• Mit dem QA-Oktanten starten
Anti-Pattern – Angriff der Dev-Krieger
Viele agile Entwicklungsteams – besonders Teams, die nur aus Entwicklern bestehen – setzen bei ihren QA-Maßnahmen nur auf entwicklungsnahe Tests. Meist kommen hier nur Unit- und Komponententests zum Einsatz. Diese lassen sich einfach im gleichen Entwicklungswerkzeug schreiben und schnell in den Entwicklungsprozess integrieren. Besonders komfortabel ist dabei die Möglichkeit, dass sich über Code Coverage Tools eine Aussage über die Abdeckung der Tests gegenüber dem Code geben lässt. Schnell tritt nämlich eine Sicherheit ein, wenn das Code Coverage Tool eine 100%-ige Testabdeckung meldet. Doch die Problematik steckt im Detail bzw. hier in der Komplexität. Für einfache Anwendungen wäre dieses Vorgehen ausreichend, aber bei komplexen Anwendungen treten Probleme auf.
Bei komplexen Anwendungen können trotz einer komfortablen Unit-Test-Abdeckung Fehler auftauchen, die sich erst durch aufwendige System- und End2End-Tests entdecken lassen. Und für diese aufwendigen Tests ist es notwendig, ein erweitertes QA-Know-how im Team zu haben. Tester oder geschulte Entwickler müssen auf höheren Teststufen der Komplexität der Anwendung entgegentreten, um hier eine passende Qualitätsaussage zu treffen.
Angriff der DevOnly
Auswirkung
Lösung
• Nur entwicklungsnahe Tests
• Kein End2End-Test
• Tester ins Team holen
• Kein Tester im Team
• Bugs treten bei komplexen Features auf
• Auf höheren Teststufen testen
• 100% Codeabdeckung
• Schnell
Anti-Pattern – Die Spanische Variante
Die Zeit, in der eine Funktion in den Code gebracht wurde und dann auf dem Zielsystem landet, wird immer kürzer. Damit verkürzt sich auch die Zeit für einen umfangreichen Test immer weiter. Für agile Projekte mit festen Iterationen durch Sprints ergibt sich ein weiteres Problem: Hier wird die Anzahl der zu prüfenden Funktionen mit jedem Sprint größer.
Reine klassische manuelle Tests kommen hier an ihre Grenzen. Darum sollten Tester und Entwickler gemeinsam an einer Testautomatisierungsstrategie arbeiten.
Manual Work
Auswirkung
Lösung
• Es gibt nur manuelle Tests
• Späte Rückmeldung bei Fehlern
• QA auf alle Schultern verteilen
• Tester überfordert
• Auf allen Teststufen testen
• Automatisierung einführen
Anti-Pattern – Automatisierte Regressionslücke
Das andere Extrem wäre ein Projekt ohne manuelle Tests. Dies bedeutet zwar eine hohe Integration in die CI-/CD-Prozesse und eine schnelle Rückmeldung bei auftretenden Fehlern, aber auch vermeidbare Probleme. Eine hohe Rate an Testautomatisierung ist mit einem großen Aufwand verbunden – sowohl bei der Erstellung der Tests als auch bei der Wartung. Und je höher die Komplexität der Anwendungsfälle ist und je schwieriger die verwendeten Technologien sind, desto höher ist die Wahrscheinlichkeit, dass durch Probleme während des Testdurchlaufes dieser stoppt oder aufwendige Prüfungen von Testabweichungen notwendig sind. Außerdem prüfen die meisten automatisierten Tests nur die Regression ab. Durch automatisierte Tests würden somit nie neue Fehler gefunden, sondern nur die Funktionsweise der Altfunktionen geprüft.
Darum sollte immer mit einem gesunden Augenmaß automatisiert werden und parallel durch manuelle und ggf. durch explorative Tests nach neuen Abweichungen Ausschau gehalten werden.
100% Testautomation
Auswirkung
Lösung
• Es gibt nur automatisierte Tests
• Sehr viel Aufwand
• Mit Augenmaß automatisieren
• Alle überfordert
• Manuelles Testen hat seinen Sinn
• Build Stops durch Problemfälle
Anti-Pattern – Testsingularität
Tests aus unterschiedlichen Teststufen und -arten haben jeweils einen unterschiedlichen Testfokus. Damit ergeben sich auch unterschiedliche Anforderungen an die Testumgebung wie Stabilität, Testdaten, Ressourcen etc. Entwicklungsnahe Testumgebungen werden sehr oft mit neuen Versionen versorgt, um die Entwicklungsfortschritte zu prüfen. Für die höheren Teststufen oder andere Testarten benötigt man einen stabileren Versionsstand über eine längere Zeit.
Um nicht ggf. die Tests durch einen geänderten Softwarestand bzw. eine geänderte Version zu kompromittieren, sollte es für jede Testart eine Testumgebung geben.
One Test Environment
Auswirkung
Lösung
• Es gibt nur eine Testumgebung
• Kein Testfokus möglich
• Mehrere Testumgebungen
• Kompromittierte Tests
• Nach Teststufe oder Testfokus
• Keine produktionsnahen Tests
• „Pro Testart eine Testumgebung“
Anti-Pattern – BauManuFaktur
Moderne Entwicklung lebt von einer schnellen Auslieferung und eine zeitgemäße Qualitätssicherung von der Integration der automatisierten Tests in den Build-Vorgang sowie der automatisierten Verteilung des aktuellen Softwarestandes auf die unterschiedlichen (Test-) Umgebungen. Ohne ein Build- oder CI-/CD-Werkzeug können diese Funktionen nicht bereitgestellt werden.
Sofern es in einem Projekt noch Aufgaben zur Bereitstellung eines CI-/CD-Prozesses gibt, können diese am Board als „To Dos“ markiert werden.
No Build Tool
Auswirkung
Lösung
• Es gibt kein Build-Werkzeug
• Keine CI/CD
• CI/CD einführen
• Langsame Auslieferung
• Lücken am Board markieren
• Späte Testergebnisse
• Ressourcenabhängig
Anti-Pattern – Early Adopter
Neue Technologien bringen meist auch neue Werkzeuge mit sich und neue Versionen neue Funktionen. Aber die Einführung neuer Werkzeuge und das Update auf neue Versionen birgt auch ein Risiko. Auch hier ist es ratsam, mit Bedacht vorzugehen und nicht alle Teile/Werkzeuge des Projektes auf einmal zu ändern.
In Zeiten des Social Distancing treten gelegentliche Videokonferenzrunden im Freundeskreis an die Stelle des gemeinsamen Kneipenbesuchs. Hier kam schnell die Diskussion auf, wie stark Corona den Arbeitsalltag beeinflusst.
Die allgemeine Meinung war, dass die Arbeitsfähigkeit stark beeinträchtigt und bei einigen sogar fast gar nicht mehr vorhanden sei. Die Arbeitgeber waren schlicht nicht bzw. nur stark eingeschränkt in der Lage, die notwendige Infrastruktur für die Arbeitsfähigkeit bereitzustellen. Und wenn dann die Infrastruktur endlich stand, wurde allen klar, was jeder weiß, der schon einmal verteilt gearbeitet hat: Es ist kompliziert! Wer darf sprechen? Kamera an oder aus? Da schreit ein Kind im Hintergrund, bitte das Mikrophon muten! Du möchtest etwas sagen? Bitte dein Mikrophon un-muten! Die Verbindung ist schlecht, ich verstehe nur jedes zweite Wort… die Liste lässt sich endlos weiterführen.
Viele sind es einfach nicht gewohnt, so zu arbeiten. Nicht zuletzt, da Kommunikation mehr ist als der bloße Austausch von Worten. Die Deutung bspw. von Körperhaltung, Mimik und Gestik der Gesprächspartner ist bei Telefon- und auch Videokonferenzen ungleich schwieriger. Das ist eine neue Situation, die viel Disziplin und Anpassungen aller Beteiligten erfordert!
Die Diskussionen mit meinen Freunden ziehen dann so vor sich hin und Erfahrungsberichte über Video-Tool-Anbieter wechseln sich mit Klagen über die eigentliche „Unmöglichkeit“ des Arbeitens in dieser Situation ab. Währenddessen suche ich in meinem Kopf verzweifelt nach eigenen Wortbeiträgen für diese Diskussion. Und ich finde auf die Frage „Was hat sich für dich seit Corona in deiner Arbeit geändert?“ nur die Antwort: „Eigentlich nichts!“
Das ist – zugegeben – eine leichte Übertreibung! Die Fahrt ins Büro, das gemeinsame Mittagessen mit Kollegen, der Schwatz an der Kaffeemaschine – all das fällt nun erst einmal weg und bedeutet einen herben Einschnitt und Verlust. Wenn, wie in meiner Situation, das Home-Office nicht nur Büro sondern auch noch Kita ist und beide Elternteile Vollzeit arbeiten, wird verteiltes Arbeiten auch für Menschen, die damit eigentlich Erfahrung haben, zu einer Herausforderung.
Aber auch hier gilt: Die Ausgangssituation ist für die meisten Menschen gleich. Insofern hilft es nur, sie entsprechend anzunehmen und das Beste daraus zu machen. Und genau da zeigt sich einmal mehr, wie wichtig es ist, bereits Erfahrungen im verteilten Arbeiten gesammelt zu haben.
Die ZEISS Digital Innovation (vormals Saxonia Systems AG) verfolgt seit vielen Jahren das Grundprinzip des Arbeitens in verteilten Teams. Nicht zuletzt, um die Work-Life-Balance der Mitarbeiterinnen und Mitarbeiter zu erhalten, ist es dem Unternehmen wichtig, dass die Leistungen für einen Kunden theoretisch überall erbracht werden können. Dadurch werden zum einen Reisekosten gespart und zum anderen wird sichergestellt, dass die notwendige Infrastruktur für die Arbeit vorhanden ist und nicht ggf. noch extra vom Kunden beschafft werden muss.
Abbildung 1: Verteilte Projektarbeit im Home-Office
Ich persönlich habe in meiner fünfjährigen Betriebszugehörigkeit erst ein Projekt erlebt, bei dem das Entwicklungsteam ständig an einem Standort versammelt war. In meinem aktuellen Projekt, gestartet im September 2019, liegt eine extreme Verteilung vor: Die sechs Projektmitglieder der ZEISS Digital Innovation sitzen an fünf unterschiedlichen Standorten, die Projekt-Stakeholder des Kunden an zwei Standorten. Insofern haben wir nicht erst seit Corona die Herausforderung des verteilten Arbeitens zu meistern, sondern diese Verteilung bereits zu Projektstart als Risiko identifiziert, dem wir uns stellen mussten.
Gelungen ist uns das meiner Meinung nach mit einem simpel anmutenden Mittel: Direkte Kommunikation!
Das Entwicklungsteam hat oft die Technik des PairProgramming eingesetzt, um einerseits den Know-how-Transfer innerhalb des Teams zu fördern, aber auch, um den individuellen Stil des jeweils anderen kennenzulernen. Daneben gehören bei uns Code Reviews zum Standardvorgehen. Diese dienen einerseits der Qualitätssicherung, andererseits fördern Code Reviews auch den Wissensaustausch innerhalb des Teams. Neben dem Daily-Meeting für alle Teammitglieder haben wir ein eigenes „DEV-Daily“ etabliert, in dem sich das Entwicklungsteam in kleinerer Runde über insbesondere technische Fragestellungen austauschen kann.
In regelmäßigen Refinement-Meetings werden fachliche Anforderungen mit technischen Lösungsansätzen gemappt. Ideen werden gesammelt, geprüft, angepasst, verworfen und neu entwickelt und das ohne Denkverbote und -schranken. Dadurch ist ein Raum der Kreativität und freien Entfaltung entstanden, in dem jedes Teammitglied seine Ideen einbringen kann und sich dadurch wertgeschätzt und mitgenommen fühlt: Trotz der Verteilung ist ein echter Teamspirit entstanden!
Die Etablierung dieser offenen Kommunikationskultur führt dazu, dass wir innerhalb des Teams intensiver und häufiger kommunizieren, sei es im Vier-Augen-Gespräch oder in der Gruppe. Dabei ist immer zu beachten, dass den individuellen Präferenzen der Teammitglieder hinsichtlich der Kommunikation Rechnung getragen wird: Manche Menschen sind Frühaufsteher. Sie sind um 8 Uhr morgens bereits voll in ihrem Flow und platzen fast, ihre neuen Ideen den Kolleginnen und Kollegen mitzuteilen, während andere um diese Uhrzeit noch kaum die Augen aufkriegen. Einige möchten gerne im Vorfeld einen Termin bekommen, um Dinge zu besprechen, damit sie planen und sich vorbereiten können. Andere springen ganz leicht zwischen Themen hin und her und man kann sie einfach ad hoc mit einem Anruf überfallen.
Um effizientes Arbeiten auch in einem verteilten Team zu ermöglichen, ist es zugegebenermaßen vermutlich nicht ausreichend, einfach „mehr zu kommunizieren“. Vielmehr ist ein durchdachtes Konzept, das alle Aspekte und Herausforderungen von verteiltem Arbeiten berücksichtigt, unabdingbar. Das gilt insbesondere für Teams mit wenig Erfahrung im verteilten Arbeiten.
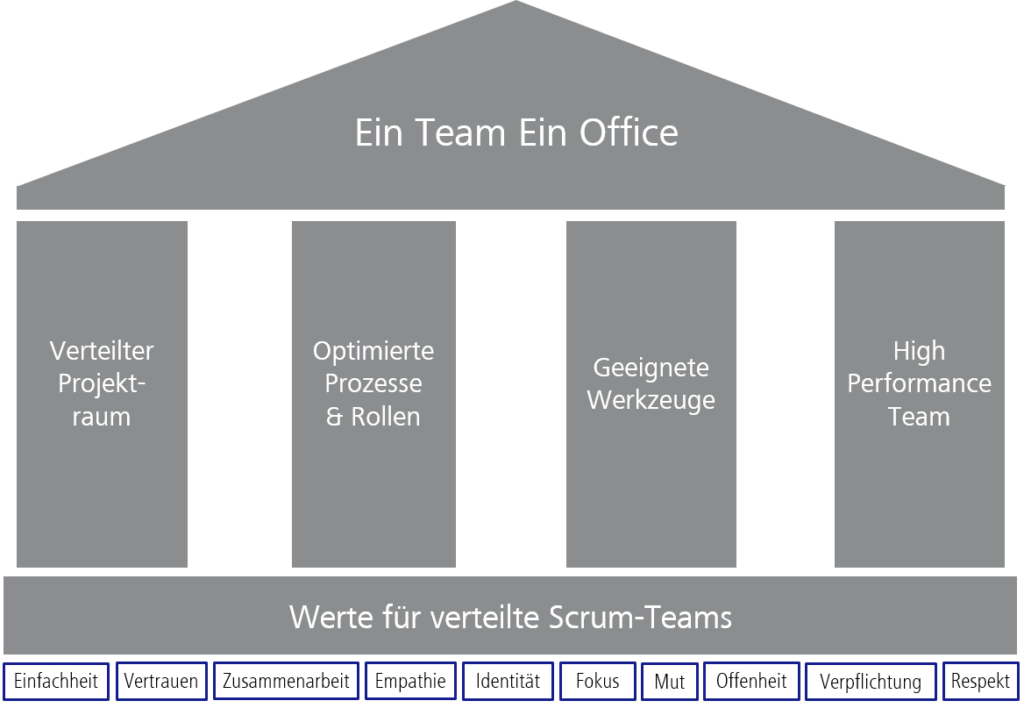
Die ZEISS Digital Innovation hat bereits vor einigen Jahren mit dem ETEO-Konzept Aufmerksamkeit erregt. ETEO („Ein Team Ein Office“) ist ein Framework zur verteilten Arbeit von Projektteams. Es gibt Projektteams einen Leitfaden an die Hand, wie verteilte Arbeit erfolgreich gestaltet werden kann. Eine permanente Videoverbindung zwischen den Standorten und die Nutzung eines digitalen Workboards für die Organisation von Aufgaben ermöglichen es den Teams, standortübergreifend zusammenzuarbeiten, quasi als wären sie an einem Standort versammelt. Die Videoverbindung ist dabei kein Muss, sondern lediglich ein Element aus dem Baukasten des bei ZEISS Digital Innovation gebräuchlichen Tool-Kits für verteiltes Arbeiten. Im Unternehmen gibt es speziell geschulte Mitarbeiter (ETEO-Coaches), welche die Teams in der Ramp-up-Phase eines Projektes und während des weiteren Projektverlaufs dediziert in Techniken für verteilte Zusammenarbeit schulen und hinsichtlich einzusetzender Tools beraten. Bei unseren Kunden führt dies oft zu „Aha-Effekten“, dass verteilte Zusammenarbeit durchaus möglich ist – und zwar ohne Performance-Einbußen befürchten zu müssen.
Abbildung 2: ETEO – unser Zusammenarbeitsmodell
Generell gilt aber auch für das verteilte Arbeiten: Das Werkzeug ist nichts, wenn man es nicht einzusetzen weiß! Damit meine ich, dass verteiltes Arbeiten ohne die entsprechende Disziplin und das passende Mindset der Beteiligten nicht gelingen kann. An dieser Stelle bleibt zu sagen: Man muss sich darauf ohne Vorbehalte einlassen sowie Tools und Techniken einfach mal ausprobieren. Und natürlich: Übung macht den Meister! Je länger ein Team verteilt zusammenarbeitet, desto stärker bilden sich die Best Practices für die verteilte Arbeit in der individuellen Teamkonstellation heraus. Man darf nicht außer Acht lassen, dass es das ultimative Konzept für verteiltes Arbeiten nicht gibt. Denn in Projekten kommunizieren keine Rollen oder Verantwortlichkeiten miteinander, sondern immer Menschen und die sind bekanntlich unterschiedlich.
Jedes Projekt ist anders und damit auch die Anforderungen an die verteilte Arbeit. Aber die Grundprinzipien sind überwiegend gleich. Das ist vergleichbar mit dem Bau eines Hauses: Ein Haus kann 1, 2, 3 oder 20 Stockwerke haben, ein Spitz- oder ein Flachdach, Doppelfenster oder einfache Fenster, aber jedes Haus hat ein Fundament, auf dem es steht.
Und die Fundamente der verteilten Arbeit sind bei ZEISS Digital Innovation sehr stabil!
In diesem Blogbeitrag möchte ich von meinen persönlichen Erfahrungen mit der Arbeit im ersten verteilten Team der Saxonia Systems (seit 03/2020 ZEISS Digital Innovation) in Dresden und Miskolc, Ungarn, berichten. Das Spannende daran ist, dass 60 Personen knapp 1000 km vom Hauptbüro von Saxonia Systems entfernt sitzen und an demselben Projekt arbeiten können wie die Kollegen im Büro neben ihnen. Und doch sind sie ein echtes Team. Für Leute, die die Arbeit in einem verteilten Team nicht kennen, ist zunächst vermutlich nicht ersichtlich, wie diese Art der Zusammenarbeit funktionieren kann. Ich schreibe als Scrum Master eines Teams, dessen eine Hälfte in Dresden sitzt, die andere Hälfte in Miskolc, Ungarn. Dieser Blogbeitrag soll zeigen, wie wir mit der Zusammenarbeit angefangen und wie wir Vertrauen und Mut gewonnen haben, um das Team aufzubauen.
Die ursprüngliche Zusammensetzung sah wie folgt aus: Drei Entwickler und ein Business Analyst aus Dresden, drei Entwickler und ein Scrum Master aus Miskolc. Der deutsche Teil des Teams arbeitete bereits an dem Projekt, aber bis zum Abgabetermin gab es noch sehr viel Arbeit. Unsere anfänglichen Erwartungen an die gemeinsame Arbeit waren sehr unterschiedlich: Am Anfang hatten wir Angst vor der Kamera an der Wand. Wie können wir arbeiten, wenn uns jemand den ganzen Tag beobachtet? Wie kann ein verteiltes Team funktionieren, wenn unsere Deutschkenntnisse nicht so gut sind? Wie können wir mit Kollegen in einer so großen Entfernung arbeiten?
Abbildung 1: Kurze Diskussion im Team
Die Zeit war knapp und wir haben schnell die Büros entsprechend des ETEO-Konzepts aufgebaut. Als die Grundlagen fertig waren, hatten wir unser erstes persönliches Treffen. Es waren nur ein paar Tage und diese Reise reichte gerade dazu, um uns gemeinsam ein Bild des Projekts zu machen. Wir dachten, da wir uns nun persönlich getroffen hatten, könnten wir in der Vorbereitung nicht mehr tun – jeder war sich sympathisch. Ab jetzt müssten wir uns auf den Projektanfang konzentrieren und das war’s. Doch wir merkten schnell, dass es nicht so einfach sein würde.
Wir stellten schon bald fest, dass die dauerhafte Videoverbindung nicht die Lösung für verteiltes Arbeiten ist, sondern nur ein Tool, welches das Team bei seiner Arbeit unterstützt. Es ist großartig, dass wir die anderen den ganzen Tag sehen können, aber zunächst würde niemand den Mut haben, sich vor den Fernseher zu stellen. Wie konnten wir von den Teammitgliedern, die sich nur ein- oder zweimal getroffen hatten, erwarten, dass sie sich trauen, eine einfache Frage vor dem ganzen Team zu stellen? Wahrscheinlich wäre die Antwort: Ich möchte die anderen nicht stören. Statt sie zu fragen, werde ich das Problem selbst googeln, oder? Mit etwas Glück werde ich die Antwort innerhalb kurzer Zeit finden, im schlimmsten Fall werde ich Stunden damit verbringen. Ich denke, es ist offensichtlich, dass das Team es sich nicht leisten kann, in solchen Situationen so viel Zeit zu verlieren, wenn es effektiv sein möchte.
Ich denke, diese Art von Mut wird in den Menschen gesteigert, wenn wir uns annähern können, um genug Vertrauen zueinander zu gewinnen. Es ist nicht einfach, Vertrauen aufzubauen ohne persönliche Treffen, informelle Gespräche, gemeinsame Abendessen und Teambuilding-Aktivitäten. Aufgrund meiner Erfahrungen kann ich sagen, dass das Wichtigste, das uns geholfen hat, ein echtes Team mit verteilten Standorten zu bilden, das intensive Reisen zwischen den Standorten in der frühen Phase war. Teammitglieder müssen nebeneinandersitzen, sie müssen wirklich das Gefühl haben, ein Team zu bilden und nicht nur an etwas zusammenzuarbeiten. Später ist es ausreichend, sich alle ein bis zwei Monate einmal zu treffen. Dies sollte jedoch der maximale Zeitabstand sein, denn die Verbindung muss beibehalten werden, da sonst die Produktivität des Teams abnimmt.
Abbildung 2: Abendessen zum Teambuilding
Ein weiteres wichtiges Ziel ist es, agil zu sein. Das klingt zwar nach einem Klischee, hilft dem Team aber dabei, Fortschritte zu machen und seine individuellen Werte aufzuzeigen. Im Folgenden werde ich einige Beispiele anführen, die uns dabei geholfen haben, dorthin zu kommen, wo wir heute sind.
Beispielsweise kam es vor, dass wir anfingen, mit einer neuen Technologie zu arbeiten, die nicht jedem bekannt war. Früher haben wir versucht, das Wissen über Pair Programming Sessions zu teilen, weil es kein spezielles Scrum Meeting für diese Art von Aktivitäten gab. Das Ergebnis einer Retrospektive war daher, dass wir „Developer Cafés“ organisieren mussten, in denen wir jede Woche zusammensaßen und im Team das Wissen über die gewählten Themen austauschen konnten.
Ein weiteres Beispiel ist das Deutschlernen. Unsere Projektsprache ist Englisch, aber das Team hat beschlossen, die täglichen Stand-up Meetings auf Deutsch abzuhalten, weil sie die Sprache lernen möchten. Zwar hört es sich so an, als ob das nur für die ungarischen Kollegen schwierig wäre, aber dem ist nicht so. Es stellt auch für die deutschen Kollegen eine große Verpflichtung dar, da sie langsamer als gewöhnlich sprechen und möglichst einfache Sätze verwenden müssen.
Abbildung 3: Workshop in Dresden
Solche Dinge ergeben sich normalerweise aus der Retrospektive, der wichtigsten Scrum-Zeremonie im Leben des Teams. Wir müssen unsere Probleme im Team klären und uns verbessern. Das ist die beste Gelegenheit, damit sich das Team weiterentwickeln kann. Dabei ist es sehr wichtig, dass das Team manchmal an einem Ort zusammen eine Retro machen kann. Persönliche Treffen helfen dabei, die Teambindung zu stärken – dies ist mein wichtigster Ratschlag. Denn mit der Zeit wird sich das Team weiterentwickeln, es muss nur unterstützt werden und das Gefühl bekommen, ein Team zu sein.