ISO 25000, which was originally developed from ISO 9000, describes quality within software development. For software developers, ISO 25010, which depicts the typical quality characteristics of software products, is of particular interest. This standard is of particular interest within ZEISS Digital Innovation too, as it not only affects the products of our customers, but also our internal processes. Especially in conjunction with the regular health checks, the standard is an important guideline as it defines which properties of software require particular attention. After more than ten years, this important standard is now being revised. This article deals with the changes we expect.
ISO 25010
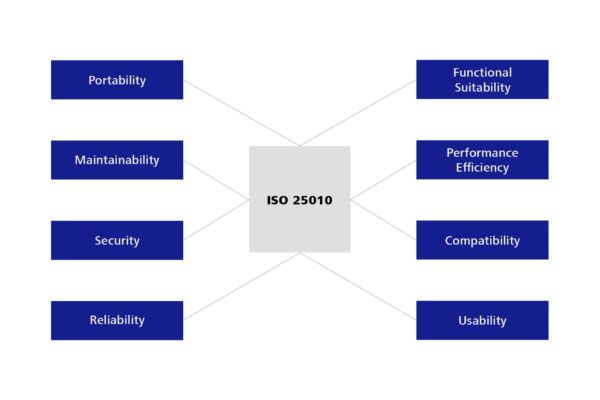
The ISO 25010 standard was approved in 2011, thereby replacing standard 9126, which was applicable at that time. It defines eight main characteristics of software, which are then divided into additional sub-characteristics.
Figure 1: Quality characteristics for software – defined in ISO 25010
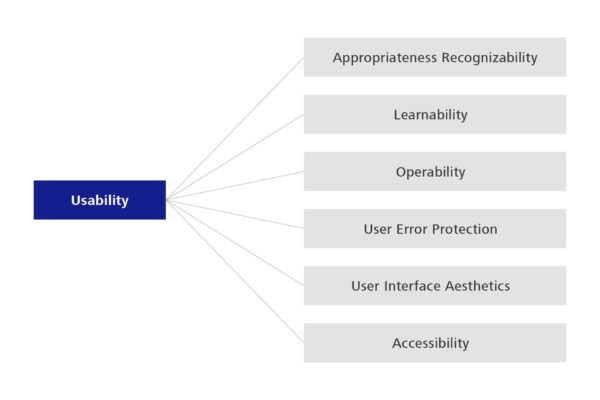
Usability, for example, is a well-known characteristic. It describes the degree to which the software supports its users in implementing their work processes. Important sub-categories include, for example, how easy it is to learn to use the software (learnability), and the degree to which it protects users from input errors (user error protection). The degree to which the software can be used by those with potential operating restrictions in terms of visual and hearing impairments is also relevant.
Figure 2: Sub-characteristics for the quality criterion usability
The detailed description within the standard makes it possible to provide various project participants, such as software architects, software testers or product owners with relevant descriptions of requirements and for these participants to prioritize appropriate quality characteristics.
Changes to the standard
ISO standards are subject to a review process every five years to check whether they are up-to-date. This was done for ISO 25010 in 2016 and 2021. During the last audit, various potential changes became apparent. For example, the feature of scalability is not currently included in the standard, although it is crucial for determining whether an application should be implemented in the cloud or on-premises. The question of whether the software should be implemented as a monolith or in the form of micro-services is also largely dependent on the required scalability.
The standardization entities had the chance to propose requested changes such as these until November 15, 2022. Thus a proposal is now available, which will be agreed on in the next three months. If the second edition follows the usual path, it can be expected that the new edition will be binding around mid-2023 and will be published broadly. But what specific changes can be expected?
Possible ISO 25010 – 2nd Edition
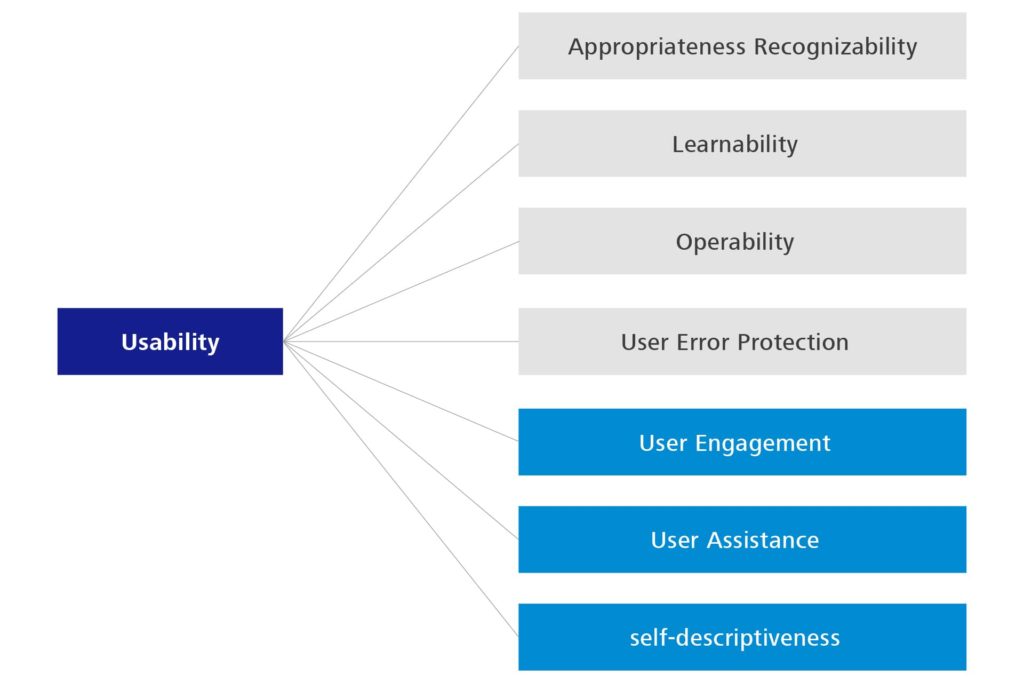
There are some changes relating to the usability characteristic, such as ‘Aesthetics’ and ‘Accessibility’ changing to ‘User Engagement’, ‘User Assistance’ and ‘Self-Descriptiveness’. The previously available descriptions have basically been explained in more detail or more clearly distinguished.
Figure 3: Sub-characteristics of Usability – 1st edition
Figure 4: Sub-characteristics of Usability – 2nd edition
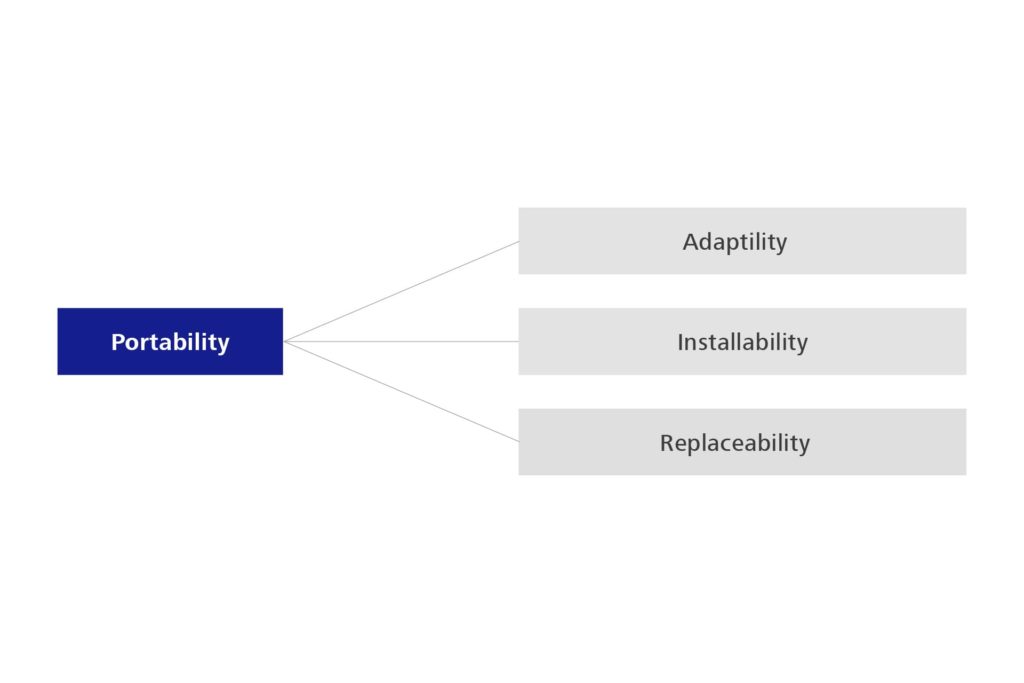
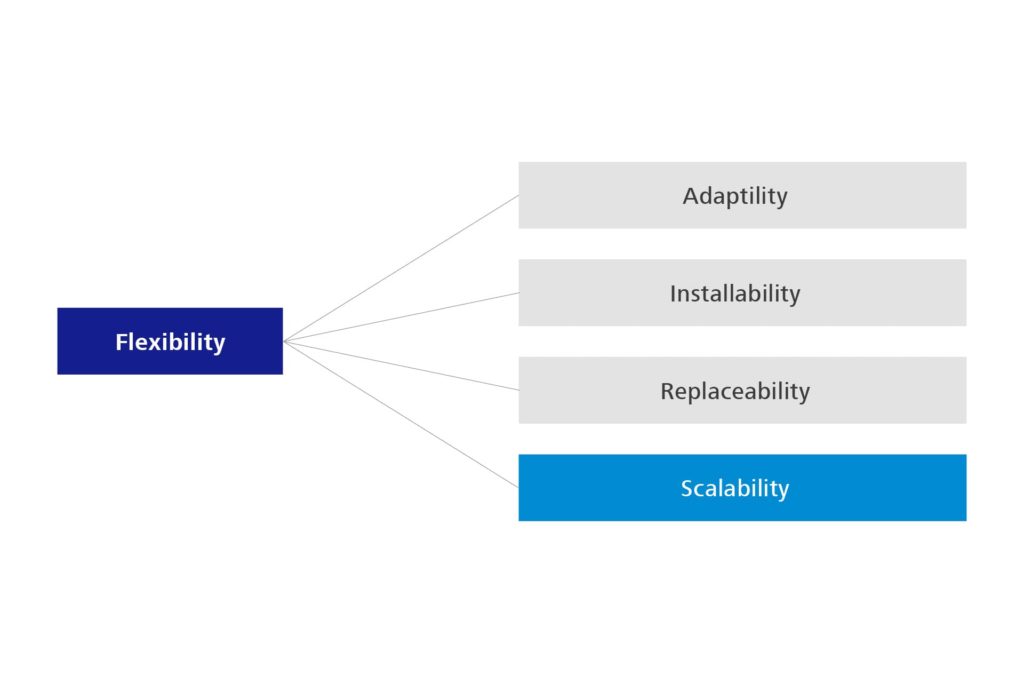
There is a further change in that ‘Portability’ is changing to ‘Flexibility’, which comes much closer to its actual character and distinguishes it more clearly from compatibility. Flexibility also includes the Scalability that has long been missing from the standard.
Figure 5: Sub-characteristics of Portability – 1st edition
Figure 6: Sub-characteristics of Portability – 2nd edition
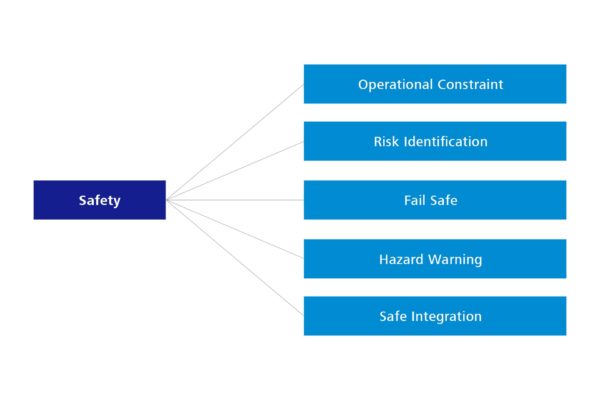
The biggest change relates to a new characteristic that has not yet been considered at all — Safety, in the sense of operational safety. Its introduction as an important quality characteristic therefore also reflects the significant prevalence of software in the context of hardware. After all, software controls hardware in many cases, and can therefore lead to damage to people and materials in the real world.
Figure 7: New quality characteristic – Safety
Conclusion
Changes to standards must always be viewed somewhat critically, as the standard becomes somewhat less well understood, especially during the transition period. For example, it can be expected that the similarity of the names in the different editions will cause some confusion about the different terms. On the other hand, the changes are comprehensible and useful. However, it is not yet certain to what extent the changes will take place, as the votes on these adjustments have not yet been finalized.
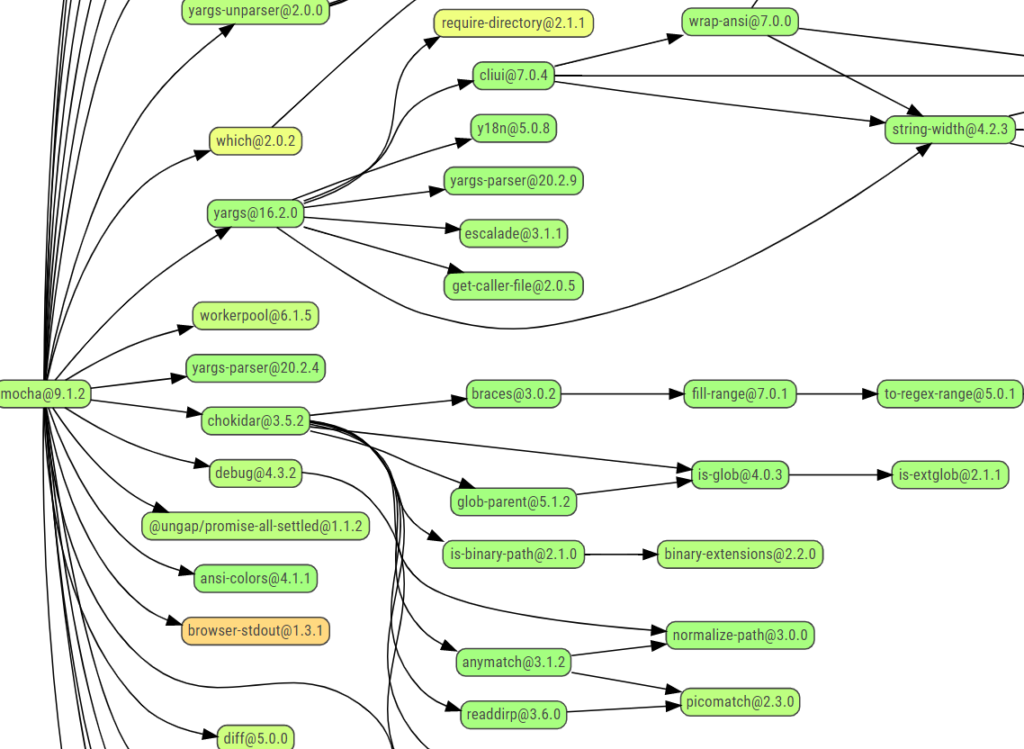
This blog post addresses the high standards of security and compliance that we have to meet in every software project. Trained security engineers are responsible for ensuring that we achieve this within any given project. An especially persistent challenge they face is dealing with the countless dependencies present in software projects, and getting them – and their variety of versions – under control.
Figure 1: An excerpt from the dependency graph of an npm package, taken from npmgraph.js.org/?q=mocha
Challenges in software projects
For some time now, large-scale software projects have consisted of smaller components that can each be reused to serve their particular purpose. Components with features that are not intended to be kept clandestine are increasingly being published in the form of free and open-source software – or FOSS for short – which is freely licensed for reuse.
To assess and prevent security vulnerabilities, it is vital that we have a complete overview of all the third-party libraries we are integrating, as any of our imported modules may be associated with multiple dependencies. This can result in the overall number of dependencies that we are aware of stretching into the thousands – making it difficult to maintain a clear picture of licences and security vulnerabilities among the various versions.
Based on reports of incidents in recent years, such as supply chain attacks and dependency hijacking, there is no mistaking the significant impact that issues like these can have. For an interesting meta-analysis of breaches of this kind, we would recommend Ax Sharma’s article “What Constitutes a Software Supply Chain Attack” (https://blog.sonatype.com/what-constitutes-a-software-supply-chain-attack). Here, we’re going to delve deeper into how to handle components in both large-scale and small-scale software projects, working from the perspective of a security engineer.
FOSS scanning tool solutions
Over time, some projects have managed to overcome the issues associated with identifying FOSS components. Today, there are programs available for creating bills of materials (BOMs) and overviews of security risks, and we have tried these out ourselves.
There are also large catalogues such as Node Package Manager (npm), containing detailed information about the components available in any given case.
Open-source components of this kind might be free to use, but they still involve a certain amount of work, particularly in cases where they are being used in major and long-term software projects.
To perform our own evaluations, we have combined the OWASP Dependency-Check (DC) tool and the OSS Review Toolkit in order to create a solution for identifying security problems through DCs and checking that licensing conditions are being adhered to. Compared with commercial solutions such as Black Duck, these tools provide a free, open option for gaining an overview of FOSS components in projects and evaluating the risks associated with them.
That said, our experience has shown that these tools also involve additional work in the form of configuration and ongoing reviews (in other words, re-running scans in order to identify new security issues).
What software engineers are responsible for
Our guidelines for ensuring secure development and using open-source tools outline the processes we require and the goals that our security engineers have to keep in mind when they are approaching a project. Below is probably the most important part of those guidelines:
It is our responsibility that the following so called Essential FOSS Requirements are fulfilled:
All included FOSS components have been identified and the fitness for purpose has been confirmed.
All licenses of the included FOSS have been identified, reviewed and compatibility to the final product/service offering has been verified. Any FOSS without a (valid) license has been removed.
All license obligations have been fulfilled.
All FOSS are continuously – before and after release – monitored for security vulnerabilities. Any relevant vulnerability is mitigated during the whole lifecycle.
The FOSS Disclosure Statement is available to the user.
The Bill of Material is available internally.
For that it must be ensured that
the relevant FOSS roles are determined and nominated.
the executing development and procurement staff is properly trained and staffed.
These guidelines form the basis for developing mandatory training, equipping subject matter experts with the right knowledge and putting quality control measures in place.
The processes involved
Investigation prior to integration (licences and operational risks such as update frequency)
Update monitoring (operational risks)
Let’s say that a new function needs to be built into a software project. In many cases, developers will already be aware of FOSS tools that could help introduce the function.
Where feasible, it is important that whichever developer is involved in the project knows how to handle package managers and the potential implications of using them so that they know how to account for the results produced by tools or analyses. As an example, developers need to be able to visualise how many parts are involved in a top-level dependency, or evaluate various dependencies associated with the same function in order to maintain security in any future development work. In other words, they must be able to assess operational risks. More and more nowadays, we are seeing projects that aim to keep the number of dependencies low. This needs to be taken into account when selecting components so that, wherever possible, additional dependencies only provide the functions that are really needed.
Before integration, the security engineer also has to check potential imports for any security vulnerabilities and verify that they have a compatible licence. An equally important job is reviewing the operational risks, involving aspects such as the following:
How up-to-date the import is
Whether it is actively maintained or has a keenly involved community
Whether the update cycle is agile enough to deal with any security vulnerabilities that crop up
How important secure handling of dependencies is considered to be
Whether the number of additional dependencies is reasonable and whether it is reduced where possible
During the development process and while operation is taking place further down the line, the project team also has to be notified whenever new security vulnerabilities are identified or closed. This may involve periodic scans or a database with security vulnerability alerts. Periodic scans have the advantage of running more independently than a database, which requires hardware and alerts to be provided. However, alerts are among the benefits offered by software composition analysis solutions such as Black Duck.
As the number of well-marked FOSS tools rises, the amount of time that needs to be invested in curating them manually is becoming comparatively low. The work that does need to be done may involve declaring a licence – and adding easy-to-find, well-formatted copyright details to components, as these have often been given highly unusual formats or left out altogether in older components. Cases in which no licence details are provided should never be misconstrued as carte blanche invitations to proceed – without a licence, a component must not be used without the author’s consent.
Example of a security vulnerability
An example of a complex security vulnerability was published in CVE-2021-32796. The module creating the issue, xmldom, is indirectly integrated via two additional dependencies in our example project here.
Black Duck shows the following security warning related to the module:
Figure 2: Black Duck example summarising a vulnerability
This gives a security engineer enough information to make a broad assessment of the implications that this vulnerability has. Information is also provided with the patch in version 0.7.0.
The importance of having enough time in advance when it comes to running updates/replacing components
Before issuing new publications under @xmldom/xmldom, we have had the time to check how much work would be involved if we were to do without this dependency.
To benefit from this kind of time in a project, it is useful to gain an overview of potential issues right at the development stage, and ensure that there is enough of a time buffer leading up to the point at which the product is published.
This makes it easier for developers to evaluate workarounds for problematic software libraries, whether they are affected by security vulnerabilities, incompatible licences or other operational risks.
Summary
This post has provided an overview of the project work we do involving the large variety of open-source software out there, and has outlined what security engineers need to do when handling open-source software. By using the very latest tools, we are able to maintain control over a whole range of dependencies and establish the transparency and security we need. Dependencies need to be evaluated by a trained team before they are integrated and then monitored throughout the software lifecycle, with the team responding to any issues that may arise.
In the field of application security, there are various concepts for achieving the goal of developing reliable and secure software. In this paper, Static Application Security Testing (SAST) and Software Composition Analysis (SCA) are introduced as important components of application security. Appropriate tools can be used to implement these concepts and increase application security.
SAST Tools
Static Application Security Testing is used to examine the code of a software for vulnerabilities and security holes.
How SAST tools work
As part of static code analysis, SAST focuses on compliance with secure coding guidelines and general programming standards. For example, developers can be helped to avoid vulnerabilities listed in the Top 10 of the Open Web Application Security Project (OWASP) or the Top 25 of the Common Weakness Enumeration (CWE).
SAST tools are part of white-box testing because they require access to an application’s source code. Ideally, SAST is used in two places in software development. First, in the development environment (IDE) of the software developers, in order to detect potential security vulnerabilities as soon as possible while writing program code. It also makes sense to integrate the SAST tool used into the Continuous Integration/Continuous Delivery (CI/CD) process. In this way, a static security analysis of the entire source code can be carried out. In addition, it can be ensured that only a code that has been checked by the SAST tool reaches the further stages of the development process such as testing and deployment. The earlier in the software development process a vulnerability or security hole is found, the more cost-effective it is to fix it.
Some SAST tools provide further functionalities, such as the execution of unit and integration tests. For the sake of completeness, it must be mentioned that SAST is only a single building block to a secure application and should definitely be complemented by other review and testing methods such as code reviews, Dynamic Application Security Testing (DAST), Interactive Application Security Testing (IAST) and manual testing.
SCA Tools
Software Composition Analysis serves to simplify and secure the use of free and open source software in software development projects. Free and Open Source Software (FOSS) has long been an important element in many software projects in order to map recurring tasks with reliable and field-tested software components.
Challenges in the use of FOSS
However, the use of FOSS gives rise to various risks that affect the application-secure and legally compliant operation of the developed software. FOSS components also have security vulnerabilities that are only discovered in the course of the development or operation of a software. Furthermore, FOSS is protected by legally binding licenses, some of which imply considerable restrictions on its use.
For these reasons, among others, it is important to know which FOSS is used in which version and under which license it was published. SCA tools support this by automating this process.
Reasons for using SCA tools
Extensive and recommended SCA tools are able to identify several million FOSS components. This makes it possible to create detailed Bill of Materials (BoM) that provide accurate insight into the FOSS in use. This information can then be used to identify vulnerabilities and security holes from many different sources. Subsequently, good SCA tools create risk and urgency assessments, which are complemented by recommendations for problem solving (FOSS update or workaround). In this way, it is possible to react to new threats to one’s own application within a very short time.
Many SCA tools can be integrated into highly automated processes such as Continuous Integration/Continuous Delivery (CI/CD) or DevSecOps. This makes it possible to react to FOSS vulnerabilities already during application development. Automated scans, which are part of the build process, also offer the possibility of rectification before the application is tested or deployed. From a security point of view, it is highly recommended that the software in operation be scanned at regular intervals by the SCA tool used. In this way, the security of the application with regard to the integrated FOSS components can also be guaranteed in this phase of the software life cycle.
Licenses under which FOSS is provided are often complex and can restrict the use or distribution of the application. A professional SCA tool recognizes several thousand licenses and supports the identification of license conditions and their effects. In addition, conflicts between different FOSS licenses should be able to be identified and issued as a warning. Furthermore, support in generating the FOSS Disclosure Statement can be part of the functional scope.
Conclusion
Developing secure software is a time-consuming and labour-intensive process. By integrating SAST and SCA tools into the development process, many manual tasks can be automated and performed with consistent thoroughness. For these and the many other reasons mentioned above, the use of such tools is an elementary part of application security. Therefore, it is essential – also in our software development projects at ZEISS Digital Innovation – to develop reliable, high-quality and, above all, secure software.
The use of an SAST tool and an SCA tool is an elementary component of application security. It is therefore essential – also in our software development projects at ZEISS Digital Innovation – to develop reliable, high-quality and, above all, secure software.
In this post, I am going to address a method of attack that has been #1 of the OWASP top 10 security risks for web applications for several years: SQL injection. Many developers are still scratching their heads, wondering how such a simple method of attack could make it to the top of the list of security vulnerabilities. One of the reasons why SQL injections are so popular with hackers is the fact that this vulnerability is so easy and quick to exploit. This is due to the strict time constraints during the development stages of applications, where functionality is prioritized and security precautions come last.
With an SQL injection, the hacker exploits the insufficient verification of data entered into the system. The standard database queries are rewritten to suit the attacker in order to gain access to sensitive data on the server. In worse cases, the attacker is even able to rewrite databases and upload their own content. The access point for such injections can be exploited by both external and registered users. That is why they say “Never trust the user!”.
To enable you to protect your systems against SQL injections, I am going to try and give you a basic understanding of how such injections work. As the term “injections” implies, they are manipulated SQL queries. Therefore, we have to take a closer look at the attack vectors. Common examples of SQL queries on websites include:
Authentication (login window)
Search boxes (retrieving relevant information from the database)
URL (modifying the hyperlink)
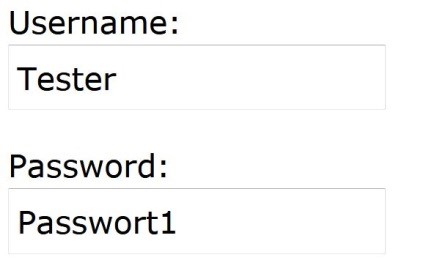
The login window provides two boxes in which the user information is to be entered. The information provided is transmitted to the server, and the database is scanned for a matching user.
Figure 1: Login mask for user query
If no matching user is found, the login fails. At the source code level, the string of “Username” and “Password” is used to build an SQL query, which is in turn used to access the database. The code would look something like this:
var User = getName("Tester");
var Password = getPass("Passwort1");
sql_cmd = 'SELECT * FROM Users WHERE Name ="' + User + '" AND Password ="' + + '"'
Resulting SQL query: → SELECT * FROM Users WHERE Name = “Tester” AND Password = “Passwort1”
In this example, the user input is accepted without verification and used to build the query. The system trusts the user input. If the user is a hacker who recognizes this vulnerability, they could exploit it as follows.
Figure 2: Login without verification
Special characters and commands are entered in the login fields to complement the SQL query. With the entries shown above, the resulting query would look as follows:
Resulting SQL query: → SELECT * FROM Users WHERE Name =”” or “”=“” AND Password =”” or “”=””‘
The additional OR in the query, which in this case always returns TRUE, results in every entry from the table being displayed. If the login system only checks whether a user with the respective password exists in the database, this query will always produce a positive result. Consequently, this entry would be a universal key for all attackers in an unprotected system.
This is one example of how an SQL injection in login fields can be done. The injection can also be done via the URL of a web page. The URL consists of the address of the web page and a path representing the directory of the server. This file path also includes PHP or HTML parameters reflecting the user’s query.
These parameters in the URL paths can be used for injections. Similar to the first example, the string can be replaced to manipulate an SQL query to serve the attacker’s purposes.
Changed URL: http://testmysql.com/report.php?id=105; DROP TABLE items; —
Resulting query: → SELECT * FROM items WHERE id = 105; DROP TABLE items; —
By adding DROP TABLES, another SQL command is added to the query and executed when the connection to the database is established. First, the desired standard query is executed. The database is searched for the ID 105, but immediately afterwards, the entire table and all the data it contains is deleted.
I hope that these two examples illustrate how critical injections can be for a database. Of course, you should note that the injections shown above are very simple examples. Such injections cannot be directly called up on any page. In practice, potential attackers have to work harder. Although it is possible to find web pages with such a URL path on Google, e.g.:
inurl:”product.php?id=” site:.de
In most cases, they are secured. Furthermore, the attacker must first get an overview of the system. Every database is structured differently and has different names for the tables, e.g. for the user information. You can actively protect your system by using standard frameworks. They are tried and tested and continually developed. If such a framework is further customized for your own system, attacking it becomes even more difficult. The attacker has to make several attempts to find out how queries are verified and which input formats are used. Unfortunately, the error messages displayed due to these attempted injections will sometimes give the attacker the information they need for their attack. This is why it is important to check the content of the error messages that the user sees. In the worst case, the error message reveals which database table and which columns contain certain data. With this information, it is very simple to build a corresponding injection. Another important safety measure is using a user with limited rights to access the database. This way, you can prevent commands, e.g. to delete or modify data in the tables. In addition, you should use “stored procedures” to further limit the possibilities to access the database.
Within the framework of a comprehensive quality assurance process, you can also identify potentially dangerous vulnerabilities by means of tests and subsequently eliminate them.
There are several tools for testing such security vulnerabilities; they exploit common vulnerabilities to test the systems for weak points. These tools are continually developed and can be used not only by developers, but also by testers. Examples of such tools:
BSQL Hacker
SQLmap
SQLNinja
Safe3 SQL Injector
Now that the basics are clear, I am going to demonstrate a practical example using one of the tools mentioned above. The SQLmap tool enables both attackers and testers to comb through the database of a web page with just a few command lines. If, for example, it is a PHP application with a “php?id” string in the URL path, this can be used as interface for the injection.
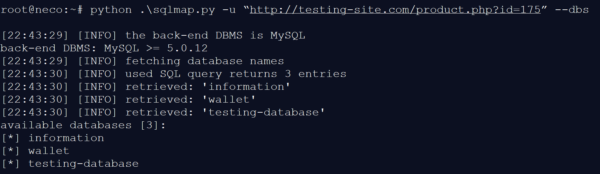
Figure 3: Query of related databases
By means of its standard queries, the tool checks which databases the web page is connected to. For our example, we will test the website “testing-site.com” that we ourselves created. The injection reveals that the databases INFORMATION, WALLET and TESTING-DATABASE constitute possible targets of an attack. Now that we know which databases are available, it is possible to analyze the next level.
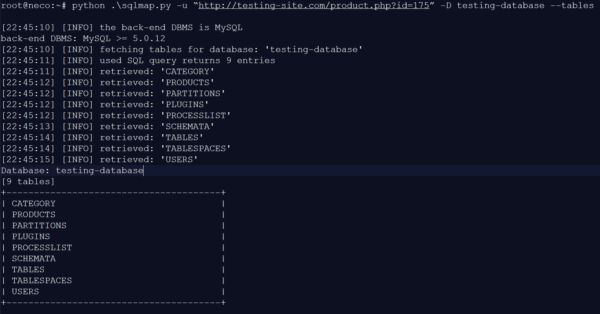
Figure 4: Tables of the TESTING database
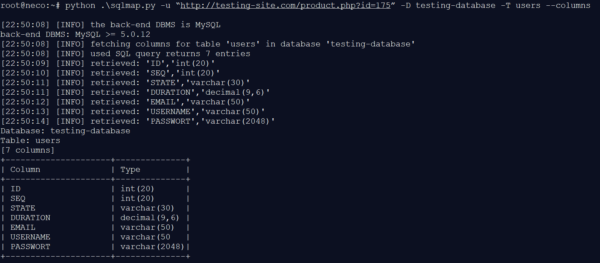
The TESTING database comprises nine tables. Next, we take a closer look at the USERS table to read out the information.
Figure 5: Analysis of the USERS table
After the in-depth analysis of the USERS table, the attacker now knows which columns need to be read out to obtain the desired data. With the information collected, it is now possible to to write a specific injection to retrieve data about the users from the database.
Figure 6: User information in plain text
USERNAME and EMAIL are stored in plain text in the database. The PASSWORD is encrypted. In the next step, you could for example use rainbow tables to decrypt the passwords, enabling you to use one of the users.
I hope this blog post gave you some insight into SQL injections and made you aware of the respective security vulnerabilities. Unfortunately, they are exploited to access foreign systems far too often, which is why it is important to take appropriate security precautions.
In my last post, Sebastian Safe built a login screen for his locksmith website. In this context, I addressed known security vulnerabilities and possible precautions that can be taken. Only users who are given the respective rights upon registration on the website should be granted access to the system.
Now, Sebastian is going to make sure that the users can use the required features of the website. The website can upload images, files or texts to the server. The uploaded files are then processed by the system and stored on corresponding server paths. Since he believes that only “selected” users have access to the system, Sebastian fails to take security precautions after the login. However, one has to assume that these users unknowingly have malware that they unintentionally upload to the system. Therefore, every user has to be treated as a potential hazard. Consequently, the data traffic on Sebastian’s website has to be verified and validated. This is where “Validate all input” comes in.
The objective of validation is to verify that the data entering the system do not cause any damage or cause information to be leaked. The data from the external system should be validated as quickly as possible to ensure that they can manipulate Sebastian’s website as little as possible. Even if the external systems are trusted systems, the incoming information has to be validated. This also includes partners whose data is required for processing. There is no such thing as 100% certainty that partner systems have not been compromised. The data should first be validated on the semantic and syntactical level. The file should have the logical structure of the respective file format, and the content should correspond to the required input. The following points should be observed in the validation.
1. Black- and whitelisting
This is the simplest method that Sebastian can implement. For uploading an image, it is important to verify that it is really possible to only upload image formats. It should not be possible to use an image upload field to upload scripts to the system that could subsequently attack it from within. However, it might be possible to upload files that have the outwardly correct format, but contain <SCRIPT> tags. Such files can execute scripts even when the file format has been verified. This method is called cross-site scripting (XSS), which is a type of injection that gives an attacker access to the system. Therefore, it is important to do not only a visual check, but to verify the content of the respective file as well.
2. Limits (min & max)
The value range for the entries and files should also be defined. This does not necessarily refer to uploading a file. It is also possible to send strings that are subsequently stored in the database. Consequently, if a date or number is entered, it is important to check, for example, that it has the correct length. When uploading files, it is advisable to check that the size of the imported file is not in the gigabyte range if it is a simple profile picture. All these considerations regarding minimum and maximum limits are common test scenarios that any professional QA team will observe. A special example of such a size limitation is the “billion laughs attack”. This is an XML file that defines an entity in the header. It consists of several LOL strings that multiply by ten due to the nested invocation.
In this example, the LOL string is uploaded to the system memory 1,000,000,000 times. Depending on the strength of the system’s hardware, reading this file can result in a complete collapse. The quantity and size of the string can even be increased, and several files of this kind could be uploaded simultaneously. In such a situation, it is therefore necessary for the system to terminate the process when a certain size is exceeded in order to protect itself. This is not a security vulnerability that leaks information, but it can be exploited to crash the system. And such a crash can then be used to take other steps to infiltrate our system.
For the testers among you, the billion laughs attack might be an interesting opportunity to test your test systems.
3. Client and server verification
It is important to make sure that the input is validated not only on the client, but on the server as well. In web applications, it is possible to bypass the javascripts by means of a proxy or direct queries to the server. Therefore, a double-sided safeguard is recommended. If the client verifies that the file has to be a JPG, and the file is uploaded only after this verification, verification on the server side could be neglected. However, if the attacker reads out the exact addresses and the structure of this upload query to the server by means of network monitoring tools, they will be able to create their own upload query by means of REST tools and bypass the client-side verification. This way, an attacker would be able to deposit scripts directly on the server, which they can then use to gain access to the server or read out information. Therefore, files have to be verified before and after the upload.
4. Server-side control
Another point to be considered is the determination of the location. It should be determined by the server, not the client. Depending on how much information an attacker has been able to read from the client’s scripts, such information can give them an overview of the server structure, giving them a larger target for the attack. Furthermore, the server should also rename a file upon storing it in the defined storage path. This ensures that any script content in the file that was overlooked and that would access the file’s own name cannot be executed because the file would not exist in this case.
servertestuploadsTestupload.JPG
—
servertestuploadsTE123ST321UPZEZELOAUIUID.JPG
These points can easily be verified by QA by checking the server directories after a test upload and analyzing the upload files located there.
In addition, there is software that scans the servers for malware and examines the uploaded files directly. For testing purposes, malware can be uploaded to the server to identify any such security vulnerabilities. However, such tests should always be agreed in advance with the person responsible for the system.
5. Regular expressions
Creating regular expressions for a specific task is a great tool to eliminate security vulnerabilities. The only characters allowed for the required input are those the system can process. It is not necessary to allow for the entire UTF-16 if only numbers are needed for a post code. This way, you can limit the potential risks for each input field. Again, they should be verified both on the client and the server side. Another important security guideline for regular expressions is NOT to use wildcards.
Simple expression for an email address:
[a-zA-Z]@[a-zA-Z].[a-zA-Z]
Here, a simple regular expression is used for email addresses, although it can be elaborated to a much greater degree.
As email addresses offer a very wide range to choose from, writing a restricting regular expression for them is difficult due to the large number of special characters alone. The good news is, there are numerous frameworks that already have such features and that will help you with the verification in this context.
These are just a few of the issues that ought to be observed to eliminate security vulnerabilities. What is also worth mentioning is that using known frameworks is usually better than devising your own features. On the one hand, these frameworks have been tried and tested and have evolved over time, and on the other hand, they are updated whenever new vulnerabilities are identified.
Known frameworks for input validation:
Django Validators
FluentValidation
Apache Commons Validators
Express Validator
The “FluentValidation” framework makes validating regular expressions, strings, etc. much easier for the developer. The framework is structured in such a way that you can use simple and clear verification features for the variables of a specific class that the user enters on the website interface. Sebastian created a small class for his locksmith customers, which he calls “Schluesseldienst”. The registered users enter the required information for this class via a registration form. This information includes the company name, address, email address and credit card number and is used to create the class. But before the class is used to store the information in the database, where the unverified data could cause damage, they are verified by the framework.
public class Locksmith
{
public int Id { get; set; }
public string firmname { get; set; }
public string address { get; set; }
public string email { get; set; }
public string creditcard { get; set; }
}
using FluentValidation;
public class CustomerService : AbstractValidator<Locksmith>
{ public CustomerService()
{ RuleFor(Locksmith => Locksmith.firmname).NotEmpty() //no spaces
.Length(1,100); // stringlength between 1 and 100
Rulefor(Locksmith => Locksmith.adress) .NotEmpty()
.Length(I,_ );
Rulefor(Locksmith => Locksmith.email) .NotEmpty()
.Length(_,_n)
.EmailAddress();// verify emailadress format
Rulefor(Locksmith => Locksmith.creditcard).NotEmpty()
.Length(_,_ )
.CreditCard(); // verify creditcard
Locksmith customer = new Locksmith(); CustomerService examiner = new CustomerService();
ValidationResult results = examiner.Validate(customer);
if(! results.IsValid) { foreach(var failure in results.Errors) { Console.WriteLine("attribut" + failure.PropertyName + " failed. Error: " + failure.ErrorMessage); } }
If the validation produces any errors, they are displayed and documented. This way, the correct content of the information is ensured before the data are stored.
This concludes the second part of my security talk. I hope this blog post gave you an overview of the validation of input in your systems.