Die ursprünglich aus der ISO 9000 hervorgegangene ISO 25000 beschreibt die Qualität innerhalb der Softwareentwicklung. Hierbei ist für Softwareentwicklerinnen und Softwareentwickler insbesondere die ISO 25010 von Interesse, welche typische Qualitätsmerkmale von Softwareprodukten abbildet. Innerhalb der ZEISS Digital Innovation ist dieser Standard von besonderem Interesse, da er sich nicht nur auf die Produkte unserer Kunden, sondern auch auf unsere internen Abläufe auswirkt. Gerade in Verbindung mit den regelmäßig durchgeführten Health Checks stellt der Standard eine wichtige Richtschnur dar, weil er definiert auf welche Eigenschaften von Software besonderes Augenmerk gelegt werden sollte. Nach über zehn Jahren ist es nun so weit, dass dieser so wichtige Standard überarbeitet wird. Dieser Artikel behandelt die zu erwartenden Änderungen.
Die ISO 25010
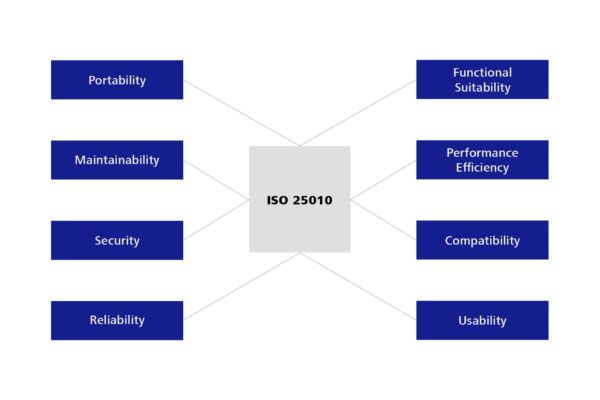
Der Standard ISO 25010 wurde im Jahr 2011 abgesegnet und ersetzte damit den bis zu diesem Zeitpunkt geltenden Standard 9126. Er definiert acht Haupteigenschaften von Software, die sich in weitere Untereigenschaften aufteilen.
Abbildung 1: Qualitätskriterien für Software – definiert in der ISO 25010
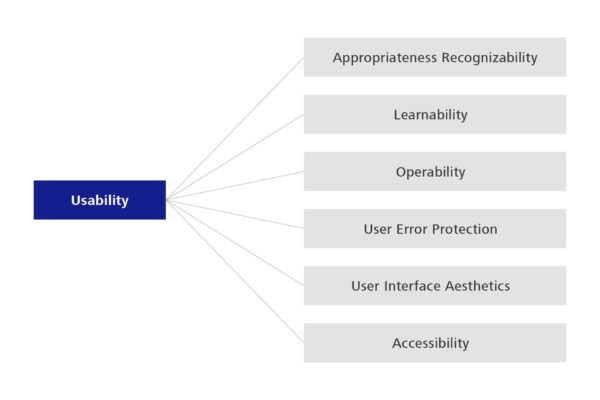
Eine weithin bekannte Eigenschaft ist zum Beispiel die Usability, zu Deutsch auch Benutzbarkeit. Mit ihr wird beschrieben, inwiefern die Software ihre Nutzer bei der Umsetzung von deren Arbeitsabläufen unterstützt. Wichtige Unterkategorien sind dabei zum einen, wie leicht die Software zu erlernen ist, zum anderen aber auch inwiefern sie die Nutzer vor Eingabefehlern schützt. Außerdem relevant ist der Umgang der Software mit möglichen Bedienungseinschränkungen, im Sinne von Seh- und Hörbeeinträchtigungen der Nutzer.
Abbildung 2: Untermerkmale für das Qualitätskriterium Usability
Dank der detaillierten Beschreibung des Standards ist es damit unterschiedlichen Projektbeteiligten wie Softwarearchitekten, Softwaretestern oder Produkt Ownern möglich, entsprechende Qualitätseigenschaften zu priorisieren sowie diese mit entsprechenden Anforderungsbeschreibungen zu versehen.
Änderungen am Standard?
ISO-Standards unterliegen einem Reviewprozess, durch den sie aller fünf Jahre auf ihre Aktualität geprüft werden. Für die ISO 25010 geschah dies in den Jahren 2016 und 2021. Bei der letzten Prüfung wurden verschiedene Änderungspotentiale offensichtlich. Beispielsweise findet sich bisher die Eigenschaft der Skalierbarkeit nicht im Standard, obwohl sie ausschlaggebend dafür ist, ob eine Applikation tatsächlich in der Cloud oder On-Premise umgesetzt werden sollte. Auch die Frage, ob die Software als Monolith oder in Form von Micro-Services umgesetzt werden sollte, ist maßgeblich von der notwendigen Skalierbarkeit abhängig.
Änderungswünsche wie diese konnten von den Standardisierungseinheiten bis zum 15. November 2022 vorgeschlagen werden, wodurch nun ein Vorschlag vorliegt, über den in den nächsten drei Monaten abgestimmt wird. Folgt die 2. Edition auch weiterhin dem üblichen Prozess, ist damit zu rechnen, dass die neue Edition etwa Mitte 2023 als bindend gilt und breitflächig veröffentlicht wird. Aber welche Änderungen sind konkret zu erwarten?
Mögliche ISO 25010 – 2. Edition
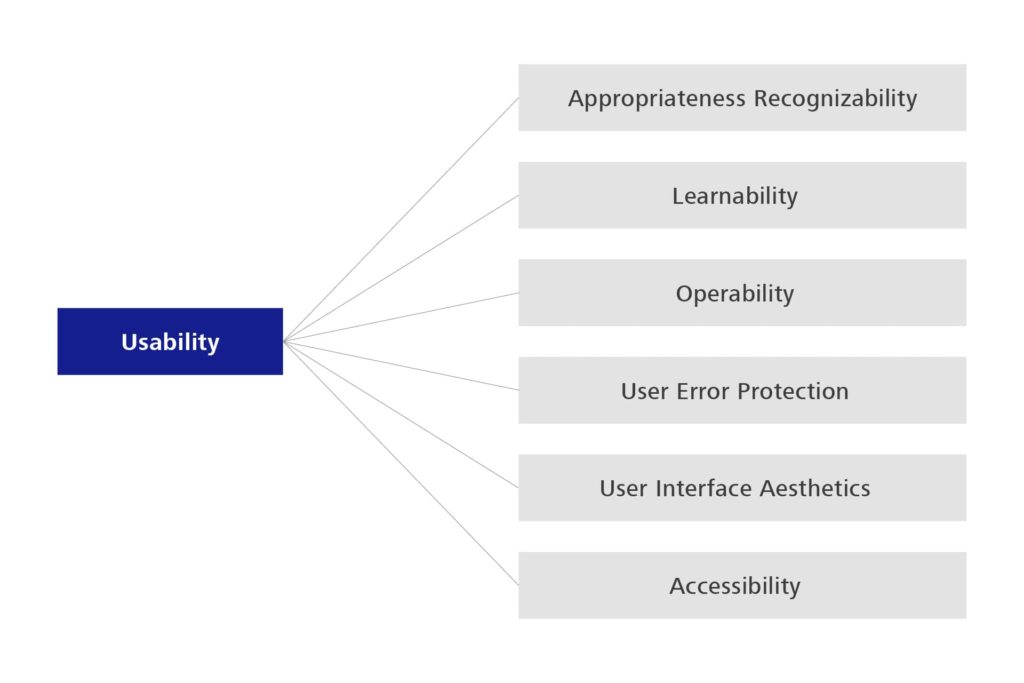
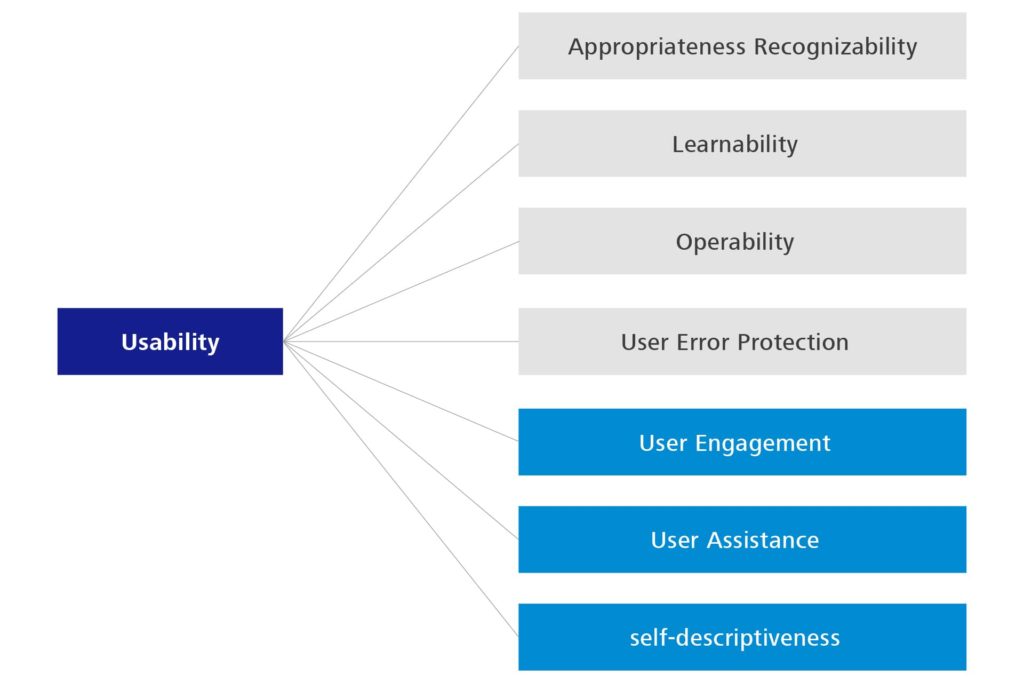
Bezogen auf die Usability ergeben sich einige Änderungen, so haben sich Astethics und Accessbility in User Engagement, User Assistance und Self-Descriptiveness gewandelt. Damit wurden die zuvor vorhandenen Beschreibungen im Grunde nur näher erläutert bzw. deutlicher getrennt.
Abbildung 3: Untermerkmale der Usability – 1. Edition
Abbildung 4: Untermerkmale der Usability – 2. Edition
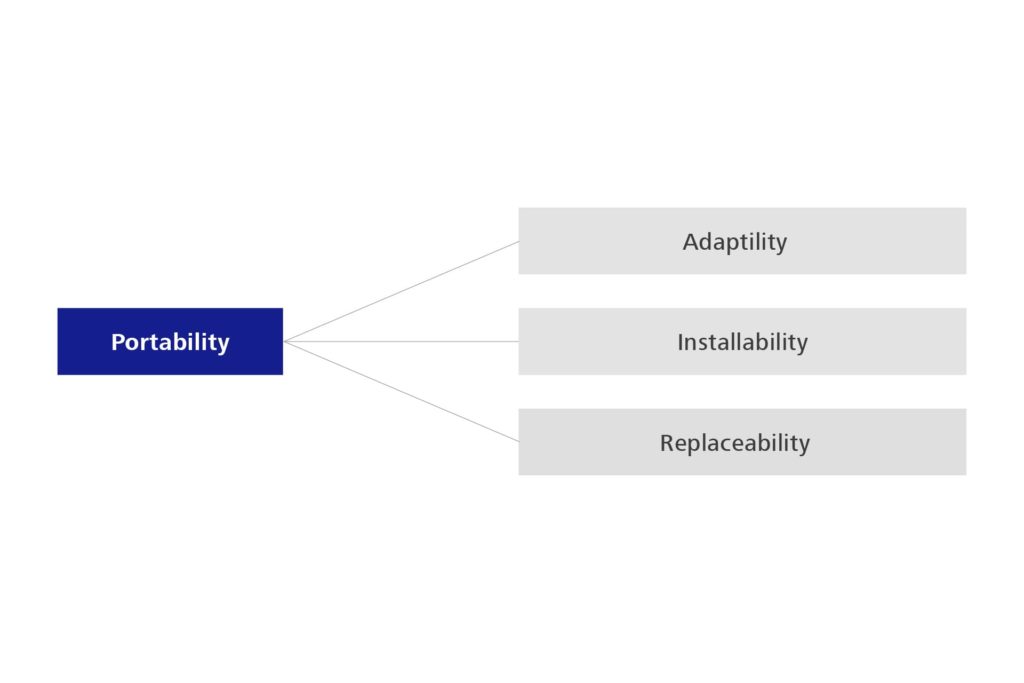
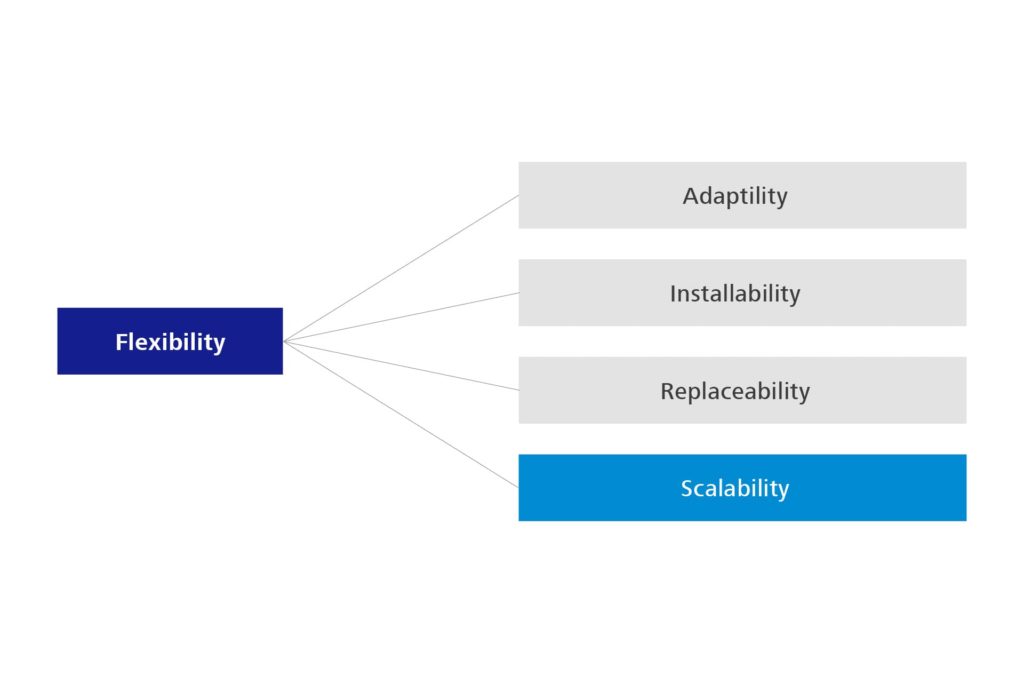
Eine weitere Änderung ergibt sich für die Portabilität. Sie wandelt sich in Flexibilität, was ihrem eigentlichen Charakter auch viel näherkommt und sie deutlicher von der Kompatibilität unterscheidet. Unter der Flexibilität findet sich dann auch die schon länger vermisste Skalierbarkeit.
Abbildung 5: Aspekte der Portability – 1. Edition
Abbildung 6: Aspekte der Portability – 2. Edition
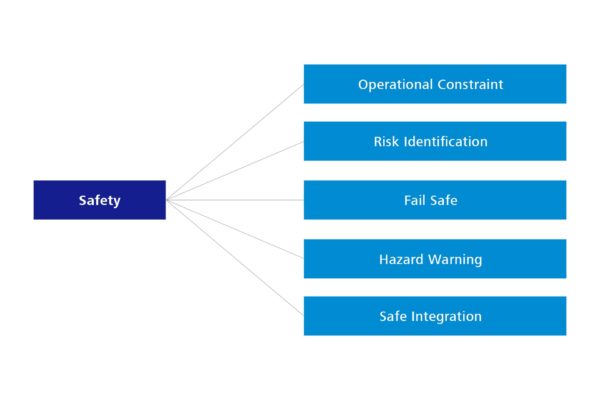
Die größte Änderung betrifft eine neue Eigenschaft, die bisher noch gar nicht betrachtet wurde. Hierbei handelt es sich um Safety. Mit Safety ist dabei die Betriebssicherheit gemeint. Ihre Einführung als wichtiges Qualitätsmerkmal spiegelt daher auch die deutliche Verbreitung von Software im Kontext der Hardware wider. Denn nicht zuletzt steuert Software in vielen Fällen auch Hardware und kann daher auch in der realen Welt zu Schäden an Mensch und Material führen.
Abbildung 7: Neues Qualitätsmerkmal – Safety
Fazit
Änderungen an Standards sind zu einem gewissen Teil auch immer etwas kritisch, da der Standard damit etwas weniger gut zu verstehen ist. So ist beispielsweise damit zu rechnen, dass in der Übergangszeit, durch die Namensgleichheit der verschiedenen Editionen, zunächst etwas Verwirrung entlang der verschiedenen Begriffe herrschen wird. Andererseits sind die Änderungen nachvollziehbar und sinnvoll. Inwiefern es überhaupt zu den Änderungen kommt, steht darüber hinaus auch noch nicht ganz fest, da die Abstimmung über jene Änderungen aktuell noch nicht abgeschlossen ist.
Dieser Blogbeitrag befasst sich mit den hohen Ansprüchen an Security und Compliance, die wir an jedes Softwareprojekt stellen. Dafür verantwortlich ist in jedem Projekt ein ausgebildeter Security Engineer. Dabei stellen ihn insbesondere die unzähligen Dependencies in Softwareprojekten, welche in ihrer Vielzahl von Versionen unter Kontrolle gebracht werden müssen, vor große Herausforderungen.
Abbildung 1: Ein Ausschnitt aus dem Abhängigkeits-Graph eines npm Paketes, aus npmgraph.js.org/?q=mocha
Herausforderungen in Softwareprojekten
Große Softwareprojekte bestehen schon seit langer Zeit aus kleineren Teilen, die für ihr jeweiliges Gebiet wiederverwendet werden können. Komponenten, bei denen es nicht um geheime Funktionalität geht, werden zunehmend als „FOSS (Free and Open Source Software)“ veröffentlicht. Das bedeutet „quelloffen“ (Open Source) und mit einer freien Lizenz zur Weiterverwendung.
Dabei ist es für die Einschätzung und Prävention von Sicherheitslücken äußerst wichtig, eine vollständige Übersicht über alle eingebundenen Drittbibliotheken zu haben. Denn jedes unserer importierten Module kann ebenfalls mit mehreren Abhängigkeiten verbunden sein. Schnell steigt dann die Anzahl an zu beobachtenden Abhängigkeiten in die Tausende und es ist nicht einfach, zwischen allen Versionen den Überblick über Lizenzen und Sicherheitslücken zu behalten.
Die Auswirkung der Problematik wird z. B. klar, wenn man Fälle von „Supply chain attacks“ und „Dependency Hijacking“ der letzten Jahre liest. Eine interessante Meta-Analyse ist „What Constitutes a Software Supply Chain Attack? “ von Ax Sharma (https://blog.sonatype.com/what-constitutes-a-software-supply-chain-attack). Den Umgang mit diesen Komponenten in großen wie kleinen Softwareprojekten aus Sicht eines Security Engineers möchten wir weiter erläutern.
Lösungsmöglichkeiten mittels FOSS Scanner
Über die Zeit haben sich einige Projekte dem Problem der Kenntlichmachung von FOSS-Komponenten gewidmet. Es gibt Programme zum Erstellen von Bill of Material (BOM) und Übersichten zu Sicherheitsrisiken, welche wir verprobt haben.
Weiter gibt es große Kataloge wie den „Node Paketmanager“ (npm), die selbst ausführliche Informationen zu den jeweils angebotenen Komponenten geben.
Auch wenn es diese freien und quelloffenen Komponenten gratis gibt, so sind sie nicht ohne Aufwand, besonders in langlebigen und wichtigen Softwareprojekten.
Wir haben für die Evaluierung den OWASP-Dependency Check (DC) und das OSS Review Toolkit als kombinierte Lösung für das Auffinden von Sicherheitsproblemen mit DC und Überprüfung der Einhaltung der Lizenzbestimmungen eingesetzt. Im Vergleich zu kommerziellen Lösungen wie BlackDuck bieten diese frei und kostenlos die Möglichkeit einer Übersicht über die FOSS-Komponenten in Projekten und die Bewertung von Risiken.
Das war aber unserer Erfahrung nach mit Mehraufwand sowohl in der Konfiguration als auch bei der kontinuierlichen Überprüfung, d. h. neuen Scans auf neue Sicherheitsprobleme, verbunden.
Verantwortung als Software Engineer
Unsere Richtlinien für sichere Entwicklung und den Einsatz von Open Source geben die notwendigen Prozesse und Ziele vor, an dem sich unsere Security Engineers in Vertretung der Projekte orientieren. Der vielleicht wichtigste Ausschnitt daraus wird im folgenden Abschnitt aufgeführt:
It is our responsibility that the following so called Essential FOSS Requirements are fulfilled:
All included FOSS components have been identified and the fitness for purpose has been confirmed.
All licenses of the included FOSS have been identified, reviewed and compatibility to the final product/service offering has been verified. Any FOSS without a (valid) license has been removed.
All license obligations have been fulfilled.
All FOSS are continuously – before and after release – monitored for security vulnerabilities. Any relevant vulnerability is mitigated during the whole lifecycle.
The FOSS Disclosure Statement is available to the user.
The Bill of Material is available internally.
For that it must be ensured that
the relevant FOSS roles are determined and nominated.
the executing development and procurement staff is properly trained and staffed.
Anhand dieser Richtlinien werden verpflichtende Trainings, Wissensträger und Qualitätskontrollen gebildet.
Vorstellung der Abläufe
Untersuchen vor Einbindung (Lizenzen, Operational Risk wie Update-Häufigkeit)
Überwachen von Updates (Operational Risks)
Irgendwann soll eine neue Funktion zu einem Softwareprojekt hinzugefügt werden. Oft kennen Entwickler bereits mögliche FOSS Software, die bei der Funktionalität hilft.
Ein wichtiger Aspekt ist, dass möglichst jeder Entwickler den Umgang mit Paketmanagern und mögliche Implikationen kennt, um Ergebnisse aus den Tools oder Analysen richtig einordnen zu können. Es ist z. B. sehr wichtig, sich zu veranschaulichen, aus wie vielen Teilen eine Top-Level-Abhängigkeit besteht – oder verschiedene Abhängigkeiten gleicher Funktionalität im Hinblick auf zukünftige sichere Entwicklung (Operationelle Risiken) zu bewerten. Immer öfter sehen wir das Ziel, die Zahl an Abhängigkeiten klein zu halten. Das sollte bei der Auswahl von Komponenten berücksichtigt werden, um möglichst nur das wirklich notwendige an Funktionalität von zusätzlichen Abhängigkeiten zu erhalten.
Bereits vor dem Einbinden sind durch den Security Engineer potenzielle Imports auf ihre kompatible Lizenz und bestehende Sicherheitslücken zu überprüfen. Ebenso wichtig ist aber auch der Blick auf das, was unter operationale Risiken fällt wie z. B.:
Aktualität
Lebendige Community oder aktive Instandhaltung
Update-Zyklus ausreichend agil, um auftretende Sicherheitslücken zu beseitigen
Wird Wert auf den sicheren Umgang mit Abhängigkeiten gelegt?
Ist die Anzahl an weiteren Abhängigkeiten sinnvoll und wird wenn möglich reduziert?
Im laufenden Entwicklungsprozess und später im Betrieb muss das Projektteam auch informiert werden, wenn neue Sicherheitslücken entdeckt oder geschlossen werden. Dafür können periodische Scans oder eine Datenbank mit Alerts für Sicherheitslücken eingesetzt werden. Für periodische Scans spricht die größere Unabhängigkeitvon der einen Datenbank – dafür müssen Hardware und Alerts selbst bereitgestellt werden. Diese wiederum sind einer der Mehrwerte einer Software-Composition-Analysis-Lösung wie BlackDuck.
Da der Anteil an gut gekennzeichneter FOSS steigt, wird bei neuen Versionen der Zeitaufwand für manuelle Kuration vergleichsweise geringer. Dazu zählen das Deklarieren einer Lizenz – und leicht auffindbare und formatierte Copyright-Angaben in den Komponenten, was in älteren Komponenten oft sehr individuell formatiert oder ganz weggelassen wurde. Ist keine Lizenz angegeben, so darf dies nicht fälschlicherweise als „Freibrief“ verstanden werden. Ohne eine Lizenz darf eine Komponente nicht ohne Einverständnis der Autoren benutzt werden!
Beispiel einer Sicherheitslücke
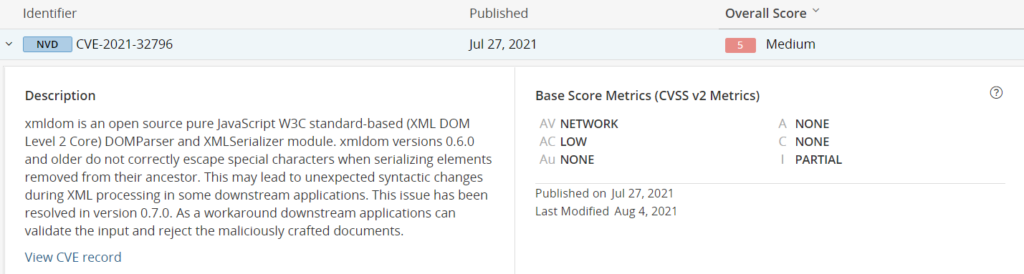
Ein Beispiel für eine komplizierte Sicherheitslücke ist unter dem CVE-2021-32796 veröffentlicht worden. Eingebunden wird das problematische Modul xmldom indirekt über zwei weitere Abhängigkeiten in unserem Beispielprojekt.
BlackDuck zeigt uns zu dem Modul folgende Sicherheitswarnung:
Abbildung 2: BlackDuck: Beispiel Zusammenfassung einer Schwachstelle
Damit kann der Security Engineer bereits eine grobe Einschätzung zur Tragweite der Sicherheitslücke vornehmen. Auch ist ein Hinweis auf dem Patch in Version 0.7.0 angegeben.
Wichtigkeit von Vorlauf für Updates/Austausch von Kompetenzen
Wir haben in der Zeit bis zu der „frischen Veröffentlichung“ unter @xmldom/xmldom bereits überprüfen können, welchen Aufwand es bedeuten würde, ohne diese Abhängigkeit auszukommen.
Um diese Zeit zu haben, ist es sehr nützlich, bereits im Entwicklungsprozess – und mit genügend Vorlauf zu einer Produktveröffentlichung – eine Übersicht über mögliche Probleme zu bekommen.
Das erleichtert den Entwicklern das Evaluieren von Ausweichlösungen für problematische Software-Bibliotheken, sei es wegen Sicherheitslücken, inkompatiblen Lizenzen oder anderer operativer Risiken.
Fazit
Dieser Beitrag hat einen Überblick über unsere Arbeit mit der großen Vielfalt an Open Source in unseren Projekten und die Aufgaben als Security Engineer im Umgang mit Open Source gegeben. Damit bringen wir mittels moderner Werkzeuge die Vielfalt an Abhängigkeiten unter Kontrolle und schaffen die notwendige Transparenz und Sicherheit. Bereits vor Einbinden von Abhängigkeiten sollte eine Evaluierung dieser von einem geschulten Team durchgeführt werden, und danach während des ganzen Software-Lebenszyklus überwacht und auf Probleme reagiert werden.
Im Bereich der Application Security gibt es verschiedene Konzepte, um das Ziel zu erreichen, zuverlässige und sichere Software zu entwickeln. In diesem Beitrag werden das Static Application Security Testing (SAST) und die Software Composition Analysis (SCA) als wichtige Bestandteile der Application Security vorgestellt. Zur Umsetzung dieser Konzepte und Erhöhung der Application Security können entsprechende Tools eingesetzt werden.
SAST Tools
Static Application Security Testing dient dazu, den Code einer Software auf Schwachstellen und Sicherheitslücken zu untersuchen.
Funktionsweise der SAST Tools
Als ein Teil der statischen Codeanalyse fokussiert SAST die Einhaltung von Secure Coding Richtlinien und generellen Programmierstandards. Beispielsweise können Entwicklerinnen und Entwickler dabei unterstützt werden, Schwachstellen, die in der Top 10 des Open Web Application Security Project (OWASP) oder der Top 25 der Common Weakness Enumeration (CWE) aufgelistet sind, zu vermeiden.
SAST Tools sind Teil des White-Box Testings, denn sie benötigen Zugriff auf den Quellcode einer Applikation. Idealerweise wird SAST an zwei Stellen in der Softwareentwicklung eingesetzt. Zunächst in der Entwicklungsumgebung (IDE) der Softwareentwicklerinnen und Softwareentwickler, um möglichst zeitnah potenzielle Sicherheitslücken während des Schreibens von Programmcode aufzuspüren. Außerdem ist es sinnvoll, das eingesetzte SAST-Tool in den Prozess zur Continuous Integration/Continuous Delivery (CI/CD) zu integrieren. Auf diese Weise kann eine statische Sicherheitsanalyse des gesamten Quellcodes erfolgen. Zusätzlich kann sichergestellt werden, dass nur ein durch das SAST-Tool geprüfter Code die weiteren Stufen des Entwicklungsprozesses wie Test und Deployment erreicht. Je früher im Softwareentwicklungsprozess eine Schwachstelle oder Sicherheitslücke gefunden wird, desto kostengünstiger ist es, sie zu beheben.
Einige SAST Tools stellen weitere Funktionalitäten bereit, wie die Ausführung von Unit- und Integrationstests. Der Vollständigkeit halber muss erwähnt werden, dass SAST nur ein einzelner Baustein zu einer sicheren Applikation ist und durch weitere Überprüfungs- und Testmethoden wie Code Reviews, Dynamic Application Security Testing (DAST), Interactive Application Security Testing (IAST) und manuelle Tests unbedingt ergänzt werden sollte.
SCA Tools
Software Composition Analysis dient dazu, den Einsatz von freier und Open Source Software in Softwareentwicklungsprojekten zu vereinfachen und sicher zu gestalten. Free and Open Source Software (FOSS) ist seit Langem ein wichtiger Bestandteil in vielen Softwareprojekten, um wiederkehrende Aufgaben durch zuverlässige und einsatzerprobte Softwarekomponenten abzubilden.
Herausforderungen beim Einsatz von FOSS
Allerdings ergeben sich durch den Einsatz von FOSS verschiedene Risiken, die den applikations- und rechtssicheren Betrieb der entwickelten Software betreffen. Auch FOSS-Komponenten haben Sicherheitsschwachstellen, die erst im Laufe der Entwicklung oder des Betriebs einer Software entdeckt werden. Des Weiteren ist FOSS durch rechtlich bindende Lizenzen geschützt, die teils erhebliche Einschränkungen für die Verwendung mit sich bringen.
Unter anderem aus diesen Gründen ist es wichtig zu wissen, welche FOSS man in welcher Version einsetzt und unter welcher Lizenz diese veröffentlicht wurde. Hierbei unterstützen SCA Tools, indem sie diesen Prozess automatisieren.
Gründe für den Einsatz von SCA Tools
Umfangreiche und empfehlenswerte SCA Tools sind in der Lage, mehrere Millionen FOSS-Komponenten zu identifizieren. Dadurch ist es möglich, detaillierte Bill of Materials (BoM) zu erstellen, die einen exakten Einblick in die verwendete FOSS gewährleisten. Anhand dieser Informationen können nachfolgend Schwachstellen und Sicherheitslücken aus vielen verschiedenen Quellen ermittelt werden. Im Anschluss erstellen gute SCA Tools Risiko- und Dringlichkeitsbewertungen, die durch Empfehlungen zur Problemlösung (FOSS-Update oder Workaround) ergänzt werden. Somit kann innerhalb kürzester Zeit auf neue Bedrohungen für die eigene Applikation reagiert werden.
Viele SCA Tools lassen sich in stark automatisierte Prozesse wie Continuous Integration/Continuous Delivery (CI/CD) oder DevSecOps einbinden. Damit ist es möglich, bereits während der Applikationsentwicklung auf FOSS-Schwachstellen zu reagieren. Durch automatisierte Scans, die Teil des Build-Prozesses sind, besteht auch hier die Nachbesserungsmöglichkeit, bevor die Applikation getestet oder deployed wird. Aus Security-Sicht ist es dringend zu empfehlen, dass die im Betrieb befindliche Software in regelmäßigen Abständen durch das eingesetzte SCA-Tool gescannt wird. So kann auch in dieser Phase des Software-Lebenszyklus die Sicherheit der Applikation in Bezug auf die integrierten FOSS-Komponenten gewährleistet werden.
Lizenzen, unter denen FOSS bereitgestellt wird, sind oftmals komplex und können den Einsatz oder Vertrieb der Applikation einschränken. Ein professionelles SCA-Tool erkennt mehrere tausend Lizenzen und unterstützt bei der Identifizierung von Lizenzbedingungen und deren Auswirkungen. Zusätzlich sollten Konflikte zwischen unterschiedlichen FOSS-Lizenzen ermittelt und als Warnung ausgegeben werden können. Weiterhin kann die Unterstützung bei der Generierung des FOSS Disclosure Statements zum Funktionsumfang gehören.
Fazit
Sichere Software zu entwickeln, ist ein zeit- und arbeitsintensiver Prozess. Durch die Integration von SAST- und SCA Tools in den Entwicklungsprozess können viele manuelle Tätigkeiten automatisiert und gleichbleibend gründlich durchgeführt werden. Aus diesen und den vielen anderen oben genannten Gründen ist der Einsatz solcher Werkzeuge ein elementarer Bestandteil der Application Security. Deshalb ist er – auch in unseren Softwareentwicklungsprojekten bei der ZEISS Digital Innovation – unerlässlich, um zuverlässige, qualitativ hochwertige und vor allem sichere Software zu entwickeln.
Der Einsatz eines SAST Tools und eines eines SCA Tools ist ein elementarer Bestandteil der Application Security. Somit ist er – auch in unseren Softwareentwicklungsprojekten bei der ZEISS Digital Innovation – unerlässlich, um zuverlässige, qualitativ hochwertige und v. a. sichere Software zu entwickeln.
In diesem Beitrag werde ich auf eine Angriffsmethode eingehen, die seit mehreren Jahren auf Platz 1 der OWASP Top 10 Sicherheitsrisiken für Webanwendungen steht: Die SQL Injection. Viele Entwickler schütteln weiterhin noch die Köpfe, wie eine so simpel aufgebaute Angriffsmethode an der Spitze der Sicherheitslücken stehen kann. Einer der Gründe, warum SQL Injections bei den Hackern so beliebt sind, ist die einfache und schnelle Nutzung dieser Sicherheitslücke. Dies folgt durch den hohen Zeitdruck in den Entwicklungsphasen von Applikationen, bei denen die Funktionalität an erster Stelle steht und die Sicherheitsvorkehrungen erst zum Schluss kommen.
Bei der SQL Injection nutzt der Hacker die unzureichende Überprüfung der Eingabedaten ins System aus. Hierbei werden die Standard-Datenbank-Queries zu Gunsten des Angreifers umgeschrieben, um auf sensible Informationen des Servers zuzugreifen. In schlimmeren Fällen ist es einem Angreifer sogar möglich, Datenbanken umzuschreiben und eigene Inhalte hochzuladen. Der Zugangspunkt für solche Injections kann von externen sowie von registrierten Benutzern ausgenutzt werden. Daher kommt auch der Leitspruch „Never Trust The User!“.
Damit Ihre Systeme vor SQL Injections geschützt werden können, werde ich versuchen, ein Grundverständnis über die Funktionsweise von Injections zu vermitteln. Wie der Name der Injections bereits verrät, handelt es sich hierbei um manipulierte SQL-Abfragen. Zu diesem Zweck müssen die Angriffsvektoren genauer betrachtet werden. Klassische Beispiele für SQL-Abfragen auf Websites sind:
Authentifikation (Login-Fenster)
Suchfelder (Extrahieren die relevanten Informationen aus der Datenbank)
URL (Weblink anpassen)
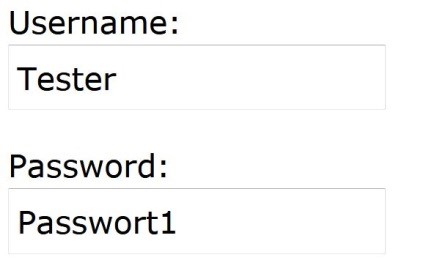
Im Bereich des Login-Fensters werden zwei Felder für die Eingabe der User-Informationen bereitgestellt. Die eingetragenen Informationen werden an den Server weitergeleitet, woraufhin die Datenbank nach einem passenden User durchsucht wird.
Abbildung 1: Login-Maske zur User-Abfrage
Wird kein passender User gefunden, schlägt der Login fehl. Auf Quellcode-Ebene wird der String von „Username“ und „Password“ dazu genutzt, eine SQL-Query aufzubauen, die wiederum dafür genutzt wird, auf die Datenbank zuzugreifen. Der Code würde in etwa so aussehen:
var User = getName("Tester");
var Password = getPass("Passwort1");
sql_cmd = 'SELECT * FROM Users WHERE Name ="' + User + '" AND Password ="' + + '"'
Resultierende SQL-Query: → SELECT * FROM Users WHERE Name = “Tester” AND Password = “Passwort1”
In diesem Beispiel wird die Eingabe des Nutzers ohne Überprüfung angenommen und dazu verwendet, die Query zu bauen. Der Eingabe des Nutzers wird vertraut. Handelt es sich nun um einen Hacker, der diese Schwachstelle sieht, könnte er sie folgendermaßen ausnutzen.
Abbildung 2: Login ohne Überprüfung
Es werden Sonderzeichen und Befehle in die Login-Felder hinzugefügt, um die SQL-Query zu ergänzen. Mit den abgebildeten Eingaben würde solch eine Query entstehen:
Resultierende SQL-Query: → SELECT * FROM Users WHERE Name =”” or “”=“” AND Password =”” or “”=””‘
Das ergänzende OR in der Query, welches in diesem Fall immer TRUE zurückgibt, führt dazu, dass jeder Eintrag aus der Tabelle angezeigt wird. Prüft das System beim Login nur, ob der User mit dem entsprechenden Passwort in der Datenbank vorhanden ist, würde er bei dieser Abfrage immer eine positive Antwort bekommen. Somit wäre die Eingabe für ein ungeschütztes System ein universaler Schlüssel für alle Angreifer.
Dies ist ein Beispiel, wie eine SQL Injection in Login-Felder durchgeführt werden kann. Die Injection kann aber auch über die URL einer Internetseite durchgeführt werden. Aufgebaut ist die URL aus der Adresse der Internetseite und einem Pfad, der das Verzeichnis des Servers darstellt. In diesem Dateipfad sind auch PHP- oder HTML-Parameter vorhanden, welche die Abfrage des Nutzers widerspiegeln.
Diese Parameter in den URL-Pfaden könnten für Injections verwendet werden. Ähnlich wie beim ersten Beispiel kann der String so ausgetauscht werden, dass eine SQL-Query für Zwecke des Angreifers manipuliert wird.
Veränderte URL: http://testmysql.com/report.php?id=105; DROP TABLE items; —
Resultierende Query: → SELECT * FROM items WHERE id = 105; DROP TABLE items; —
Durch das Hinzufügen des DROP TABLES wird der Query ein weiterer SQL-Befehl hinzugefügt und nach Aufbau der Verbindung zur Datenbank ausgeführt. Zuerst wird die erwünschte Standard-Abfrage ausgeführt. Es wird nach der ID 105 gesucht, aber direkt danach die komplette Tabelle mit allen darin befindlichen Daten gelöscht.
Ich hoffe, ich konnte mit diesen beiden Beispielen zeigen, wie kritisch sich Injections auf eine Datenbank auswirken können. Hier muss natürlich auch dazugesagt werden, dass es sich bei diesen Injections um sehr einfache Beispiele handelt. Solche Injections können nicht auf jeder Seite direkt aufgerufen werden. In der Praxis müssen sich potenzielle Angreifer mehr anstrengen. Es sind zwar via Google Internetseiten zu finden, die einen solchen URL-Pfad besitzen – wie z.B.:
inurl:”product.php?id=” site:.de
Diese sind aber in vielen Fällen gesichert. Des Weiteren muss sich ein Angreifer zuerst einmal einen Überblick über das System verschaffen. Jede Datenbank ist mit anderen Strukturen aufgebaut und besitzt andere Namen für die Tabellen, beispielsweise für die Benutzerinformationen. Aktiv kann man sein System durch die Verwendung von Standard-Frameworks schützen. Diese haben sich bewährt und werden ständig weiterentwickelt. Sofern man solch ein Framework für das eigene System zusätzlich anpasst, erhöht sich der Aufwand für einen Angreifer weiter. Der Angreifer muss mehrere Versuche starten, um herauszufinden inwiefern die Queries überprüft und was für Input-Formate genutzt werden. Entsprechend der Fehlermeldungen, die bei diesen Test-Injections angezeigt werden, bekommt der Angreifer mitunter leider Informationen, die er für seinen Angriff benötigt. Darum ist es sehr wichtig, Fehlermeldungen, die dem Benutzer angezeigt werden, auf ihren Inhalt zu überprüfen. In einem schlechten Fall sagt die Fehlermeldung aus, in welcher Datenbank-Tabelle mit welchen Spalten sich bestimmte Informationen befinden. Mit diesen Informationen ist es dann sehr einfach, eine passende Injection aufzubauen. Eine weitere wichtige Schutzmaßnahme ist es, für den Zugriff auf die Datenbank einen User zu nutzen, dessen Rechte beschränkt sind. Damit verhindert man Befehle wie das Löschen oder Ändern von Daten in den Tabellen. Weiterhin sollten „Stored Procedures“ verwendet werden, damit die Möglichkeiten zum Zugriff auf die Datenbank zusätzlich eingeschränkt werden.
Im Zuge einer umfassenden Qualitätssicherung kann man potenziell gefährliche Schwachstellen natürlich auch durch Tests erkennen und anschließend beseitigen.
Zum Testen solcher Sicherheitslücken gibt es mehrere Tools, welche die üblichen Schwachstellen ausnutzen, um die Systeme auf Schwachstellen zu testen. Diese Tools werden fortlaufend weiterentwickelt und können nicht nur von Entwicklern, sondern auch von Testern verwendet werden. Dies betrifft z.B. folgende Tools:
BSQL Hacker
SQLmap
SQLNinja
Safe3 SQL Injector
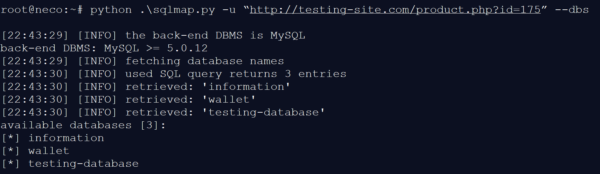
Nachdem die Grundlagen erklärt wurden, werde ich jetzt ein praktisches Beispiel unter Verwendung eines der genannten Tools vorführen. Das SQLmap-Tool ermöglicht es sowohl einem Angreifer als auch einem Tester, mit wenigen Kommandozeilen die Datenbank einer Internetseite zu durchforsten. Handelt es sich z.B. um eine PHP-Anwendung, welche den “php?id”-String im URL-Pfad besitzt, kann dieser als Schnittstelle für die Injection genutzt werden.
Abbildung 3: Abfrage verbundener Datenbanken
Das Tool überprüft mit Hilfe seiner Standard-Abfragen, mit welchen Datenbanken die Internetseite verbunden ist. Für dieses Beispiel überprüfen wir die selbsterstellte Website „testing-site.com“. Durch die Injection lässt sich einfach in Erfahrung bringen, dass die Datenbanken INFORMATION, WALLET und TESTING-DATABASE mögliche Ziele für einen Angriff sind. Nachdem man erfahren hat, welche Datenbanken zu Auswahl stehen, ist es möglich, die nächste Ebene zu analysieren.
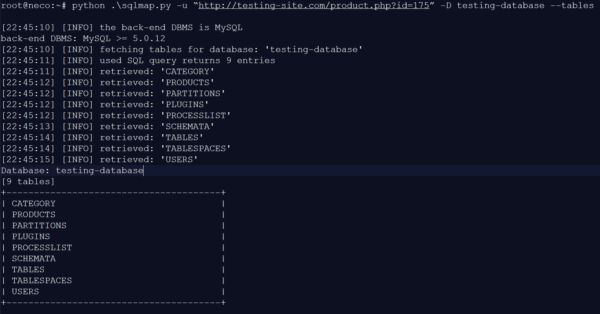
Abbildung 4: Tabellen der TESTING Database
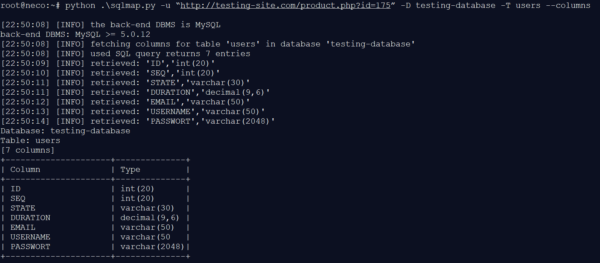
In der TESTING-Database sind neun Tabellen implementiert. Als nächstes wird die Tabelle USERS genauer betrachtet, um die Informationen herauszulesen.
Abbildung 5: Analyse der USERS-Tabelle
Mit der genaueren Analyse der USERS-Tabelle weiß der Angreifer nun, welche Spalten ausgelesen werden müssen, um an die gewünschten Daten zu kommen. Mit den gesammelten Informationen ist man nun in der Lage, eine spezifische Injection zu schreiben, um der Datenbank Informationen über die Benutzer zu entziehen.
Abbildung 6: Nutzer-Informationen im Klartext
Der USERNAME und die EMAIL sind innerhalb der Datenbank im Klartext gespeichert. Das PASSWORT wurde verschlüsselt. Nun wäre der nächste Schritt z.B. anhand von Rainbow-Tabellen die Passwörter zu entschlüsseln, um daraufhin einen User verwenden zu können.
Ich hoffe, ich konnte mit diesem Blogbeitrag einen kleinen Einblick in SQL Injections geben und auf die entsprechenden Sicherheitslücken aufmerksam machen. Denn leider werden diese viel zu oft ausgenutzt, um auf fremde Systeme zuzugreifen und dagegen sollte man entsprechende Schutzmaßnahmen ergreifen.
Im letzten Beitrag hat Sebastian Sicher eine Login-Maske für seine Schlüsseldienst-Website erstellt. Dort bin ich auf bekannte Sicherheitslücken sowie mögliche Vorkehrungen gegen diese eingegangen. Es sollte nur Nutzern der Zugriff auf das System gestattet sein, denen diese Rechte bei der Registrierung auf der Website zugeordnet wurden.
Nun kümmert sich Sebastian darum, dass die Nutzer die gewünschten Funktionalitäten der Website nutzen können. Die Internetseite ist in der Lage, Bilder, Dateien oder Texte auf den Server hochzuladen. Die hochgeladenen Dateien werden daraufhin vom System weiterverarbeitet und auf entsprechenden Server-Pfaden abgelegt. Sebastian geht davon aus, dass nur „auserkorene“ Nutzer Zugriff auf das System haben und vernachlässigt die Sicherheitsvorkehrungen nach dem Login. Es muss jedoch davon ausgegangen werden, dass diese Nutzer unbewusst Schadsoftware besitzen und diese ungewollt in das System hochladen. Aus diesem Grund muss jeder Nutzer als potenzielle Gefahr eingestuft werden. Auf Sebastians Website muss daher der Datenverkehr kontrolliert und verifiziert werden. Hier rückt der Punkt „Validate All Input“ oder zu Deutsch „Validierung aller Eingaben“ in den Fokus.
Das Ziel der Validierung ist es zu verifizieren, dass die in das System eingehenden Daten keinen Schaden anrichten oder dafür sorgen, dass Informationen hinausgeleitet werden. Die Validierung sollte so früh wie möglich geschehen, damit die Daten des externen Systems Sebastians Seite so wenig wie möglich manipulieren können. Selbst wenn es sich um Systeme handelt, denen vertraut wird, müssen die eingehenden Informationen überprüft werden. Dies gilt zum Beispiel auch für Partner, deren Daten zur Weiterverarbeitung notwendig sind. Es gibt keine hundertprozentige Versicherung, dass die Partnersysteme nicht korrumpiert sind. Die Validierung sollte zuallererst auf der semantischen und syntaktischen Ebene durchgeführt werden. Die Datei sollte den logischen Aufbau des entsprechenden Dateiformates besitzen und der Inhalt sollte mit der geforderten Eingabe übereinstimmen. Auf folgende Punkte sollte bei der Validierung geachtet werden.
1. Black- und Whitelisting
Dies ist die einfachste Methode, die von Sebastian implementiert werden kann. Für den Upload eines Bildes muss überprüft werden, ob es wirklich nur möglich ist, Bild-Formate hochzuladen. In einem Bilder-Upload-Feld sollte es nicht möglich sein, Skripte, welche im Nachhinein von innen heraus angreifen können, auf das System hochzuladen. Es wäre allerdings möglich, Dateien hochzuladen, die äußerlich das korrekte Format, im Inhalt jedoch <SCRIPT>-Tags besitzen. Solche Dateien können Skripte ausführen, obwohl das Datei-Format geprüft wurde. Ein solches Vorgehen nennt man Cross-Site-Scripting (XSS), dabei handelt es sich um eine Art Injection, mit dem Angreifer sich Zugriff auf das System verschaffen können. Daher sollte nicht nur eine kurze Sichtprüfung stattfinden, sondern auch der Inhalt der jeweiligen Datei überprüft werden.
2. Begrenzungen (Min & Max)
Es sollte auch festgelegt werden, in welchem Werte-Bereich die Eingaben und Dateien sich befinden. Es muss sich nicht immer um den Upload einer Datei handeln. Es können auch Strings verschickt werden, die im Nachhinein in der Datenbank gespeichert werden. Dementsprechend sollte bei der Eingabe eines Datums oder einer Zahl darauf geachtet werden, dass sie beispielsweise die richtige Länge besitzen. Beim Upload von Dateien sollte darauf geachtet werden, dass keine Gigabyte-großen Dateien importiert werden, wenn es sich nur um ein einfaches Profilbild handelt. Sämtliche dieser Min- und Max-Grenzen-Betrachtungen sind klassische Testszenarien, die von jedem professionellen QA-Team beobachtet werden. Ein spezielles Beispiel für solche Größenbegrenzungen ist der „Billion-Laughs-Attack“. Dabei handelt es sich um XML-Dateien, die eine Entität im Header definieren. Diese bestehen aus mehreren „LOL“-Strings, die sich selbst durch den verschachtelten Aufruf verzehnfachen.
Bei diesem Beispiel wird 1.000.000.000 mal der String „LOL“ in den Speicher des Systems geladen. Je nach Hardwarestärke des Systems kann dies zum Zusammenbruch führen, wenn diese Datei gelesen wird. Die Menge und Größe des Strings können noch gesteigert werden und es könnten mehrere solcher Dateien gleichzeitig hochgeladen werden. In solchen Situationen ist es daher notwendig, dass Systeme ab einer gewissen Größe den Prozess beenden, um sich selbst zu schützen. Dies wäre keine Sicherheitslücke, die Informationen leakt, allerdings kann sie dazu verwendet werden, das System zum Absturz zu bringen. Und dieser kann wiederum dazu genutzt werden, weitere Maßnahmen zum Eindringen in unser System zu ergreifen.
Für die Tester unter euch ist der „Billions-Laugh-Attack“ vielleicht eine interessante Testmöglichkeit für eure Testsysteme.
3. Client- und Server-Verifikation
Es muss sichergestellt werden, dass die Eingabevalidierung nicht nur auf dem Client, sondern auch auf dem Server stattfindet. Auf Web-Applikationen ist es möglich, die JavaScripts mit Hilfe eines Proxys oder Direktanfragen zum Server zu umgehen. Daher ist eine beidseitige Sicherung die empfohlene Variante. Wenn vom Client überprüft wird, dass es sich um eine JPG-Datei handeln muss und erst nach dieser Überprüfung die Datei hochgeladen wird, dann könnte von der Serverseite die Überprüfung vernachlässigt werden. Doch wenn der Angreifer die genauen Adressen und den Aufbau dieser Upload-Anfrage an den Server mit Netzwerküberwachungstools ausliest, ist es ihm möglich, mit REST-Tools eine eigene Upload-Anfrage zu erstellen, die ihn die Client-seitige Überprüfung übergehen lässt. Somit wäre ein Angreifer in der Lage, direkt auf dem Server gewünschte Skripte abzulegen, die dazu genutzt werden, Zugriff auf den Server zu bekommen oder Informationen auszulesen. Darum müssen vor und nach dem Upload die Dateien überprüft werden.
4. Serverseitige Steuerung
Ein weiterer Punkt, der beachtet werden sollte, ist die Speicherort-Bestimmung. Diese sollte dem Server überlassen werden und nicht dem Client. Je nachdem wie viel der Angreifer aus den Skripten des Clients herauslesen konnte, kann er mit diesen Informationen einen Überblick vom Server-Aufbau bekommen und hat somit eine größere Angriffsfläche. Des Weiteren sollte eine Datei auch vom Server umbenannt werden, sobald diese auf dem konfigurierten Speicherpfad abgelegt wird. Dies sorgt dafür, dass Skriptinhalte, falls sie in der Datei übersehen wurden und auf den eigenen Dateinamen zugreifen würden, nicht ausgeführt werden könnten, da die gewünschte Datei in diesem Falle nicht vorhanden wäre.
\server\test\uploads\Testupload.JPG
—
\server\test\uploads\TE123ST321UPZEZELOAUIUID.JPG
Diese Punkte können QA-seitig leicht geprüft werden, indem die Server-Verzeichnisse nach einem Test-Upload überprüft und die sich dort befindenden Upload-Dateien analysiert werden.
Außerdem gibt es Software, die auf den Servern nach Malware sucht und die hochgeladenen Daten direkt untersucht. Testseitig kann hier Schadsoftware auf den Server hochgeladen werden, um solche Sicherheitslücken zu verifizieren. Solche Tests sollten allerdings vorher mit dem Systemverantwortlichen abgesprochen werden.
5. Regular-Expressions
Die Erstellung von Regular-Expressions für eine spezifische Aufgabe ist eine große Hilfe für das Schließen von Sicherheitslücken. Man erlaubt für die gewünschten Eingaben nur die Characters, die das System verarbeiten kann. Es ist nicht notwendig, den kompletten UTF-16 zu erlauben, wenn für eine Postleitzahl nur die Ziffern benötigt werden. Somit grenzt man für jedes Eingabefeld die möglichen Risiken ein. Diese sollten dann auch wieder Client- und Server-seitig überprüft werden. Auch ein wichtiger Leitsatz für die Sicherheit bei Regular-Expressions ist es, KEINE Wildcards zu verwenden.
Einfache Expression für E-Mail-Adresse:
[a-zA-Z]@[a-zA-Z].[a-zA-Z]
Hier wird eine einfache Regular-Expression für E-Mail-Adressen verwendet, die allerdings noch viel weiter verfeinert werden könnte.
Da man bei E-Mail-Adressen eine sehr große Auswahl hat, ist es schwer, eine sehr eingrenzende Regular-Expression hierfür zu schreiben, allein wegen der großen Menge an Sonderzeichen. Zum Glück existieren viele Frameworks, die solche Funktionen bereits implementiert haben und einem bei der Überprüfung helfen.
Dies waren nur ein paar der Punkte, die bei der Schließung von Sicherheitslücken beachtet werden sollten. Es sollte auch vermerkt werden, dass es meist besser ist, bekannte Frameworks zu verwenden, als sich selbst Funktionalitäten auszudenken. Einerseits weil diese Frameworks erprobt und über die Zeit gewachsen sind und andererseits weil sie sich updaten, sobald neue Sicherheitslücken auftauchen.
Bekannte Frameworks für Input Validation:
Django Validators
FluentValidation
Apache Commons Validators
Express Validator
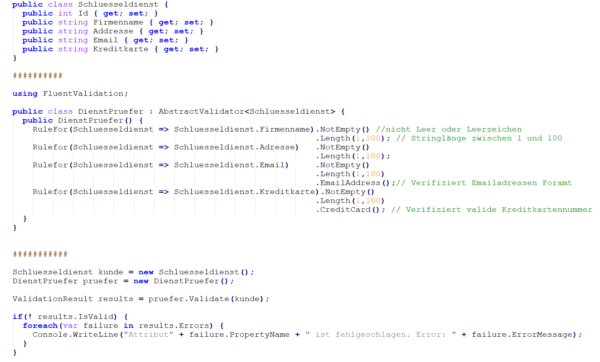
In dem Framework „FluentValidation“ wird dem Entwickler die Validierung von Regular-Expression, String-Eingaben u.v.m. sehr vereinfacht. Das Framework ist so aufgebaut, dass man für die Variablen einer Klasse, die von einem Nutzer auf der Oberfläche der Website eingegeben werden, einfache und übersichtliche Verifikationsfunktionen nutzen kann. Sebastian hat eine kleine Klasse für seine Schlüsseldienst-Kunden erstellt, diese nennt er „Schluesseldienst“. Die registrierten Nutzer tragen über ein Anmeldeformular die nötigen Informationen für diese Klasse ein. Dabei handelt es sich um den Firmennamen, Adresse, Email-Adresse und Kreditkartennummer. Diese Informationen werden dazu genutzt, die Klasse zu erstellen. Doch bevor die Klasse dazu verwendet wird, die Informationen in der Datenbank zu speichern, in der die ungeprüften Daten Schaden anrichten könnten, werden sie über die Funktionalitäten des Frameworks überprüft.
Abbildung 2: FluentValidation
Sollten bei der Überprüfung Fehler auftauchen, werden uns diese dokumentiert ausgegeben. Somit sichert man vor dem Speichern der Daten den korrekten Inhalt der Informationen.
Damit schließe ich den zweiten Teil meines Sicherheits-Talks ab. Ich hoffe, ich konnte euch mit diesem Blogbeitrag einen kleinen Überblick für die Validierung von Eingaben auf euren Systemen geben.
In der ersten Novemberwoche fand in München die W-JAX statt und die Saxonia Systems AG (seit 03/2020 ZEISS Digital Innovation) war als Gold Partner mit einem Stand und drei Speakern dabei. Die Themen reichten in diesem Jahr vom klassischen Java Enterprise über Microservice Architekturen, REST, Reactive Programming, DevOps und Continuous Delivery zu Testing und Security.
Für die Saxonia Systems AG sprachen Alexander Casall, Manuel Mauky und Kay Grebenstein zu verschiedenen Themen rund um JavaFX. Schade war, dass der Vortrag von Alexander und Manuel am Mittwoch parallel zum Vortrag von Kay angesetzt war, so teilte sich die JavaFX interessierte Zuhörerschaft auf beide Vorträge auf.
Ein Thema, welches in diversen Vorträgen im Vordergrund stand, waren RESTful Webservices. Da ich in den letzten Jahren in Projekten immer öfter auf diese Thematik gestoßen bin, habe ich ein paar dieser Vorträge besucht, um Wissen zu erweitern, zu vertiefen oder auch einfach nur abzugleichen, wie gut oder schlecht man vielleicht selbst in der Vergangenheit an dieses Thema gegangen ist.
REST – ein Überblick
Einen Überblick über das Thema lieferte Silvia Schreier (innoQ) mit ihrem Vortrag „REST 2015“. REST – der REpresentational State Transfer – ist prinzipiell nichts Neues, wurden die Grundlagen dafür schon Mitte der 90er Jahre von Roy Fielding definiert. Doch erst in den letzten Jahren sind RESTful Webservices verstärkt im Kommen. Hierbei werden die Ressourcen des Dienstes – beispielsweise Bücher und Autoren bei einem Bücherservice – per eindeutiger URI zugreifbar gemacht. Zum Beispiel würde GET /books/123 eine Repräsentation eines speziellen Buches liefern, GET /books eine Liste aller Bücher.
Operationen auf diesen Ressourcen werden mit HTTP Verben abgebildet. Anstelle einer speziellen URI zum Ändern eines Datensatzes wie /authors/456/update, wird die Ressource verändert, indem beispielsweise ein PUT oder PATCH Request auf sie ausgeführt wird. Ebenso dient DELETE zum Löschen und POST zum Erzeugen neuer Ressourcen. Für die Antwort bietet HTTP dem REST Service eine einfache Möglichkeit, den Aufrufer über den Status der Anfrage zu informieren. Die 200er Status Codes bedeuten eine erfolgreiche Anfrage, 300er Weiterleitungen, 400er Fehler des Clients und 500er Fehler auf Server Seite. Zusätzlich dazu gibt es eine Vielzahl standardisierter Header, welche Client und Server nutzen können und sollten, um beispielsweise den Typ des Inhalts auszuhandeln, Informationen über Autorisierung und Caching anzugeben und vieles mehr.
Ein wesentliches Architekturprinzip für gute RESTful Webservices ist HATEOAS – Hypermedia as the Engine of Application State. Hier erfolgt die Navigation des Clients ausschließlich über URLs, die entweder in den Ressourcen oder den Header-Informationen vom Server bereitgestellt werden. Hierdurch wird eine lose Kopplung erreicht, was es dem Schnittstellenanbieter erleichtert, Änderungen an dieser zu machen.
Neben diesen grundsätzlichen Informationen wurden noch eine Reihe von Best Practices zu weiteren Themen rund um RESTful Webservices gegeben. Beispielsweise lassen sich alle Mechanismen gleichermaßen nutzen, um auch die Dokumentation der eigenen Schnittstelle als spezielle Ressourcen verfügbar zu machen. Der Überblick wurde abgerundet durch das Thema Sicherheit. Hier gibt es viele Möglichkeiten der Authentifizierung und Autorisierung wie Basic Auth, Cookie basierte Mechanismen, OAuth 1 und 2, OpenID Connect und weitere Verfahren. Welches sich in der jeweiligen Anwendung eignet oder genutzt werden sollte, kommt auf den Anwendungsfall und die Art der Clients an.
Spring Data REST
Nach der Theorie stellt sich die Frage, wie sich nun REST-konforme Schnittstellen mit Java entwickeln lassen. Da in meinen bisherigen Projekten immer Implementierungen des JAX-RS Standards zum Einsatz kamen, war es interessant sich den Ansatz von Spring anzuschauen. Den hierzu passenden Vortrag „Spring Data REST – Repositories meet Hypermedia“ gab es von Oliver Gierke (Pivotal Software, Inc.). Out of the Box generiert Spring Data REST HATEOAS-konforme Ressource-Repräsentationen im HAL-Format aus den Domänenobjekten. Das HAL – Hypertext Application Language – Format definiert die Art und Weise wie Hyperlinks in Ressourcen dargestellt werden. Bei einer HAL-konformen Schnittstelle kann der Client allein durch die gegebenen Links und deren Relationen durch die komplette Schnittstelle navigieren. Spring kümmert sich automatisch, um die Übersetzung des Domänenmodells, indem beispielsweise aggregierte Objekte direkt als Sub-Ressourcen, Relationen zwischen Objekten als Links oder IDs als URIs abgebildet werden. Spring Data REST bietet bereits vieles, was – zumindest bis jetzt – bei JAX-RS noch händisch gemacht werden muss. Je nachdem, worauf der Fokus im Projekt gelegt wird, kann sich der Umstieg auf das Spring Ökosystem durchaus lohnen.
Dokumentation von REST Schnittstellen
Ein Thema welches gern mal ignoriert oder zumindest stiefmütterlich behandelt wird, ist die Dokumentation. Doch gerade bei Schnittstellen ist diese oft unverzichtbar für die Anwender der Schnittstelle bzw. die Entwickler, welche diese Schnittstelle nutzen sollen. Welche Möglichkeiten es gibt, sich mit Hilfe von Open Source Werkzeugen Dokumentationen von REST Schnittstellen generieren zu lassen, war Thema in Martin Walters (Deutsche Welle) Vortrag „REST-Architekturen erstellen und dokumentieren“. Hierbei gibt es verschiedene Ansätze, wie apiary.io zum Schreiben von Dokumentationen in einer Wiki-Syntax oder Javadoc basierten Lösungen wie SpringDoclet und apidoc.js, bei denen spezielle Kommentare im Quellcode genutzt werden für die automatische Generierung von Dokumentationen. Das umfangreichste Werkzeug bzw. Sammlung von Werkzeugen bietet Swagger. Dokumentationen können hier mittels Annotationen aus dem Code heraus erzeugt, mit JSON oder YAML geschrieben oder mit Hilfe von Editoren erzeugt werden. Aus der JSON Definition können wiederum Client- und Serverendpunkte in verschiedensten Sprachen generiert werden. Des Weiteren bietet Swagger ein UI zur Darstellung der Schnittstelle mit der Möglichkeit, diese direkt auszutesten.
Fazit
Für mich war es die erste W-JAX Teilnahme und ich wurde nicht enttäuscht. Es gab viele Themen und wirklich gute Vorträge. Neben den bereits im Detail erwähnten Vorträgen rund um REST möchte ich hier auf jeden Fall noch Axel Fontaine (Boxfuse GmbH) mit seinem Vortrag „Immutable Infrastructure auf AWS“ und Steffen Müller (Incloud GmbH) mit „Cross-Plattform-App-Entwicklung“ nennen. Beide Vorträge waren sowohl inhaltlich als auch vom Stil her sehr interessant und erfrischend. Was ich persönlich ein wenig schade fand, war die große Anzahl von jeweils 10 parallelen Vorträgen. So blieb vieles auf der Strecke, da es oft zwei oder drei parallele Themen gab, die ich gern besucht hätte. Trotz allem komme ich gern wieder!