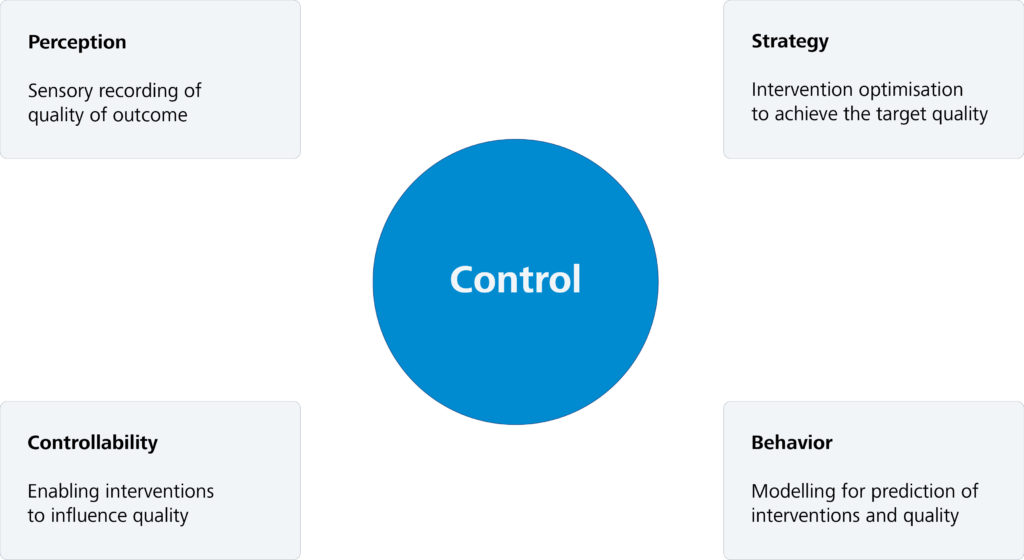
The Asset Administration Shell (AAS) is an emerging concept in connection with the digital twin data management. It is a virtual representation of a physical or logical unit, such as a machine or a product. The AAS enables relevant information about this unit to be collected, processed and used to ensure efficient and intelligent production. The architectural standardization of the AAS enables communication between digital systems and is therefore the basis for Cyber Physical Systems (CPS). You can find out more about the need for digital twins in the industry here: ZEISS Digital Innovation Blog – The digital twin as a pillar of Industry 4.0
The following article focuses on the actual implementation of an example. In one scenario, we will use a reference implementation from the Fraunhofer Institute for Experimental Software Engineering IESE (BaSyx implementation of AAS v3) to establish an information exchange between two participating partners. For the sake of simplicity, both parties are based within one company and share the infrastructure.
Note: This application is also suitable for cross-company distribution. The respective security aspects are not part of this scenario.
Scenario
Factory A is a manufacturer of measuring head accessories and produces pushbuttons, among other products.
Factory B manufactures measuring heads and would like to install pushbuttons from factory A on its measuring head.
In addition to the physical forwarding of the pushbutton, information must also be exchanged. The sales department of factory A provides contact information so that the technical purchasing department of factory B can access and negotiate prices. Moreover, factory A must also provide documentation, etc.
For this exchange of information:
- Contact details and
- documentation
the AAS concept is to be used.
Infrastructure
In our scenario, we want to use type 2 of the Asset Administration Shell. Here, the AAS is provided on servers and there is no exchange of AASX files, but rather communication between the different services via REST interfaces.
In our scenario, the different services run within a Kubernetes cluster in Docker containers.
Services
To provide the AAS, we use the BaSyx implementation (https://github.com/eclipse-basyx/basyx-java-server-sdk). To be specific, we use the following components:
- AAS repository,
- submodel repository,
- ConceptDescription repository,
- discovery service,
- AAS registry as well as
- a Submodel Registry.
AAS repository, submodel repository and ConceptDescription repository are provided within one container – the AAS environment.
Technical implementation
The communication is only done via API calls to the corresponding REST interfaces of the services.
For this, we will use simple Python scripts to represent a communication in which the manufacturing factory B wants to receive information about a product (here: a pushbutton for a sensor) from the component factory A.
Procedure
Factory B only knows the asset ID of one pushbutton, but knows nothing else about this component.
- Factory B uses the Asset ID to request the discovery service in order to obtain an AAS ID.
- This AAS ID is used for requesting the central AAS registry, which provides the AAS repository endpoint of factory A.
- Via this endpoint and the AAS ID, factory B receives the complete Asset Administration Shell including the relevant submodel IDs.
- With these submodel IDs (e.g., for contact details and documentation), factory B requests the submodel registry of A and receives the submodel repository endpoints.
- Factory B requests the submodel endpoints and receives the complete submodel data. This data includes the desired contact information for the buyer and complete documentation for the pushbutton asset.
The process is illustrated in detail below using UML sequence diagrams.
UML sequence: Creation of AAS registration in component factory A
Factory A is responsible for registering its own component.

Figure 1: UML sequence: Creation of the AAS registration in component factory A
UML sequence: Requesting the component data
Factory B requires data about the component and requests it from the AAS infrastructure. Here, factory B may only have access to the asset ID of the component, in our case that of the pushbutton.

Figure 2: UML sequence: Requesting the component data
Implementation
For the process described above to work, the services mentioned must be made available. Secondly, shells and submodels must be created and also stored in the registries.
Service deployment
Deployment takes place via Docker containers that run within a Kubernetes cluster. For this, each BaSyx image receives a Kubernetes deployment which starts the corresponding pods via Kubernetes replica sets.
By means of port forwarding, for example, the corresponding ports are made accessible by the host. This is necessary to address the APIs according to the example Python scripts.
A relatively simple Kubernetes deployment configuration looks like this. There are four deployments, each with a replica set.

Figure 3: Kubernetes deployment configuration
Creating the AAS from factory A
Factory A would like to provide the contact details for its pushbutton component, for example.
For this, submodels are created in the AAS repository (here: in the AAS environment) and registered in the submodel registry.
Subsequently, the Asset Administration Shell is created in the AAS repository and registered in the AAS registry.
The shell reference is then added to the AAS repository.
This completes the registration process from the component factory.
Contact details requests from factory B
Factory B would like to receive the contact details and requests the various AAS services according to the workflow described above. Ultimately, the submodel data set containing the required values is obtained and can then be made available within a user interface, for example.
Conclusion
The Type 2 Asset Administration Shell is a distributed system that is based on the corresponding repositories, registries and the discovery service. In our example, we have only used a simple submodel template for contact data. However, there are far more templates available for many applications.
Communication between the services for the provision and retrieval of data is relatively straightforward, although aspects such as security were not a focus in this scenario.
The example implementation described in this article gives an idea of the immense potential of the AAS concept and encourages users to start concrete implementations.
This post was written by:

Daniel Bruegge
Daniel Brügge works as a software developer at ZEISS Digital Innovation with a focus on cloud development and distributed applications.

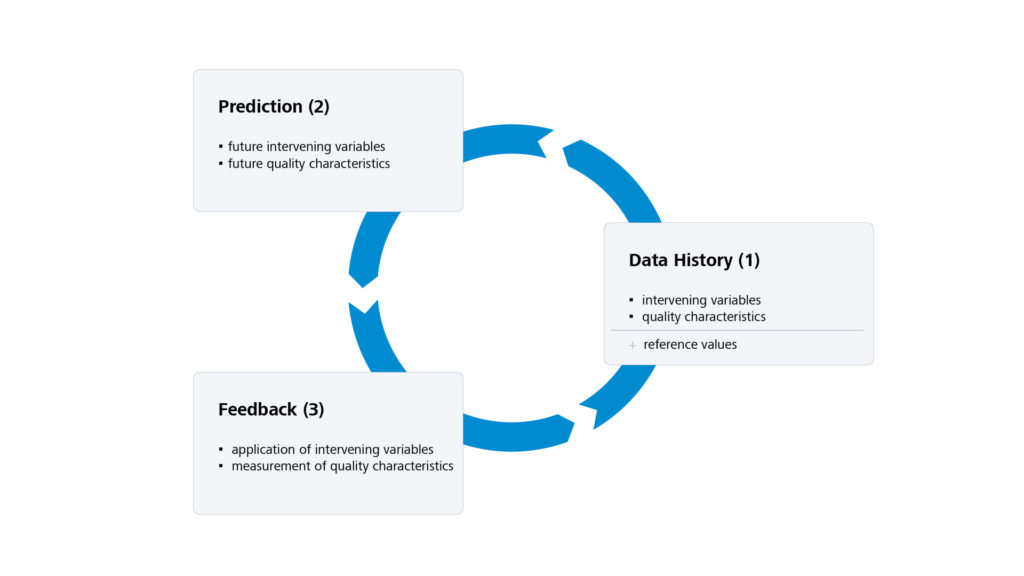
 and output variables
and output variables  , which minimise the distance to a reference trajectory
, which minimise the distance to a reference trajectory  in the prediction time horizon
in the prediction time horizon  . In addition, historical data is given in the form of an initial trajectory
. In addition, historical data is given in the form of an initial trajectory  of length
of length  , which is to be extended by the sought trajectory
, which is to be extended by the sought trajectory  .
.
 of the time-restricted behaviour
of the time-restricted behaviour  allows to determine a vector
allows to determine a vector  for each
for each  , to which
, to which  applies, we can formulate the following constrained optimisation problem for
applies, we can formulate the following constrained optimisation problem for 
![\[\begin{aligned} &\underset{g}{\text{minimize}} \quad \| H_{T_f} \ g - w_r \|^2_2 & \\[1.0em] &\text{subject to} \quad H_{T_\text{ini}} \ g = w_\text{ini}, & \end{aligned}\]](https://blogs.zeiss.com/digital-innovation/en/wp-content/ql-cache/quicklatex.com-12225d16ba56e218dc2d961a2e71ea00_l3.png "Rendered by QuickLaTeX.com")
![\[H_L \, g = w \quad \Longleftrightarrow \quad \begin{bmatrix} H_{T_\text{ini}} \\[0.5em] H_{T_f} \end{bmatrix} \, g= \begin{bmatrix} w_\text{ini} \\[0.5em] w_f \end{bmatrix}\]](https://blogs.zeiss.com/digital-innovation/en/wp-content/ql-cache/quicklatex.com-c87146b5ba83a9fa6121cb53b383b30e_l3.png "Rendered by QuickLaTeX.com")
 in the minimisation functional ensures that the determined future trajectory
in the minimisation functional ensures that the determined future trajectory  is permissible for the system
is permissible for the system  . In addition, constraints on
. In addition, constraints on 
 and Newton’s law of gravitation, specifically for bodies near the Earth’s surface
and Newton’s law of gravitation, specifically for bodies near the Earth’s surface ![F = m \, g \, [\, 0, -1 \,]^T](https://blogs.zeiss.com/digital-innovation/en/wp-content/ql-cache/quicklatex.com-3a132a5c1402d5e00e2bbd9d9b52e617_l3.png "Rendered by QuickLaTeX.com") . In terms of the motion of the pendulum, only the force
. In terms of the motion of the pendulum, only the force  acting tangentially on the pendulum mass is to be considered, since the radial component is compensated by the cord. For the same reason, only the tangential acceleration
acting tangentially on the pendulum mass is to be considered, since the radial component is compensated by the cord. For the same reason, only the tangential acceleration  is relevant. Using the time-dependent deflection angle
is relevant. Using the time-dependent deflection angle  and the angular acceleration
and the angular acceleration  (see Figure 3), the variables
(see Figure 3), the variables ![\[F_T = -m \ g \sin \theta(t) \quad \text{and} \quad a_T(t) = l \, \ddot{\theta}(t)\]](https://blogs.zeiss.com/digital-innovation/en/wp-content/ql-cache/quicklatex.com-f7a94bdf0c3db04d6cdec2913372bc18_l3.png "Rendered by QuickLaTeX.com")
 of the pendulum cord and
of the pendulum cord and  as the gravitational acceleration on Earth. Therefore,
as the gravitational acceleration on Earth. Therefore,  results in the following differential equation for the deflection angle
results in the following differential equation for the deflection angle 
![\[\ddot{\theta} (t) = - \frac{g}{l} \ \sin \theta(t)\]](https://blogs.zeiss.com/digital-innovation/en/wp-content/ql-cache/quicklatex.com-364ff111e2b16dbb65b1a5b9e5922561_l3.png "Rendered by QuickLaTeX.com")
![\[\ddot{\theta} (t) = - \frac{g}{l} \ \theta(t)\]](https://blogs.zeiss.com/digital-innovation/en/wp-content/ql-cache/quicklatex.com-28f90592f6b8c256665c4aa05158a64e_l3.png "Rendered by QuickLaTeX.com")
 and any initial velocity
and any initial velocity  .
.![x(t) = [\, \theta(t), \dot{\theta}(t) \, ]^T](https://blogs.zeiss.com/digital-innovation/en/wp-content/ql-cache/quicklatex.com-00042eeb0e6082a618959354ce55d057_l3.png "Rendered by QuickLaTeX.com") with the deflection angle
with the deflection angle  , the initial conditions for the two experiments can be taken as
, the initial conditions for the two experiments can be taken as![\[x_1(0) = \begin{bmatrix} 1 \\ 0 \\ \end{bmatrix} \quad \text{and} \quad x_2(0) = \begin{bmatrix} 0 \\ 1 \\ \end{bmatrix}\]](https://blogs.zeiss.com/digital-innovation/en/wp-content/ql-cache/quicklatex.com-df54785fc76d8f96d442f82d79463531_l3.png "Rendered by QuickLaTeX.com")
 of the pendulum at the starting angle
of the pendulum at the starting angle  and vanishing starting velocity at discrete points in time
and vanishing starting velocity at discrete points in time  . The second experiment uses the inverse setting for recording
. The second experiment uses the inverse setting for recording  .
.
![x(0) = [\, \theta_0, \dot{\theta}_0 \,]^T](https://blogs.zeiss.com/digital-innovation/en/wp-content/ql-cache/quicklatex.com-7f25c83af7999fc84d73631b119d374a_l3.png "Rendered by QuickLaTeX.com")
![\[x(t) = \theta_0 \ x_1(t) + \dot{\theta}_0 \ x_2(t)\]](https://blogs.zeiss.com/digital-innovation/en/wp-content/ql-cache/quicklatex.com-558a75ea4ad9d035368aec0945cdc0e8_l3.png "Rendered by QuickLaTeX.com")
![\[B \, x(0) = x \quad \text{with} \quad B = \begin{bmatrix} x_1(t_1) & x_2(t_1) \\ \vdots & \vdots \\ x_1(t_n) & x_2(t_n) \end{bmatrix} \quad \text{and} \quad x = \begin{bmatrix} x(t_1) \\ \vdots \\ x(t_n) \end{bmatrix}\]](https://blogs.zeiss.com/digital-innovation/en/wp-content/ql-cache/quicklatex.com-623ed99891a8562a9cb17562bca8acb7_l3.png "Rendered by QuickLaTeX.com")
 an algebraic representation of the pendulum behavior.
an algebraic representation of the pendulum behavior.
 input parameters,
input parameters,  output variables and
output variables and  internal states and satisfies a difference equation of the form
internal states and satisfies a difference equation of the form![\[\begin{aligned} x(k+1) &= A \, x(k) + B \, u(k) \\[0.5em] y(k) &= C \, x(k) + D \, u(k) \end{aligned}\]](https://blogs.zeiss.com/digital-innovation/en/wp-content/ql-cache/quicklatex.com-02b73328e934d0f914e1e0db3165e64b_l3.png "Rendered by QuickLaTeX.com")
 ,
,  , and
, and  .
. , the time-restricted version
, the time-restricted version  , is identified with a finite-dimensional vector space of the dimension
, is identified with a finite-dimensional vector space of the dimension![\[\dim B_L = m L + n.\]](https://blogs.zeiss.com/digital-innovation/en/wp-content/ql-cache/quicklatex.com-43143e97938da991c676d94a21b6de13_l3.png "Rendered by QuickLaTeX.com")