Computers and automation technology began to gain a foothold in the production industry in the 1970s, making it possible to set up flexible mass production options in locations away from physical assembly lines. With the advent of this technology, machines were optimised to ensure maximum workpiece throughput. This process, which continued into the 2000s, is generally known as the third industrial revolution.
Industry 4.0 – as it was coined by the German government and others in the 2010s – has different aims, however. Since machine uptimes and entire production lines in many industries are already being optimised as much as they possibly can, attention is now turning to the methods that can be used to optimise downtimes – a term that is primarily used to refer to points in production when machines are at a standstill or are producing reject parts.
Two major approaches to optimising downtimes
100% capacity utilisation as a goal for every machine
If my production machines aren’t doing what they were purchased and installed for, they are not being productive and are not adding any value. There are two types of downtime to consider: planned and unplanned. To ensure that no time is wasted even when downtimes are taking place as planned, machines can be deployed flexibly at several points in the production chain – resulting in more of their capacity being used overall. A good example of this is a six-axis robot with a gripper that can be moved from one workstation to another as needed, working on the basis of where it can be put to good use at that point in time. This approach uses the concept of changeable production. Unplanned downtimes, meanwhile, usually happen as a result of component or assembly failures within a machine. In these cases, machine maintenance needs to be scheduled so that it is only performed at the times when planned maintenance is due to take place anyway (as part of predictive maintenance measures).
Reducing rejects
Another major approach involves reducing the amount of rejects produced: this also makes it easier to perform the process monitoring stages that take place after a production cycle (or perhaps even during it). Process control builds on the process monitoring stage, feeding the findings it gains back into the production cycle (process) in order to improve the outcomes of the next cycle. It is easy to visualise how this could take place in a single milling cycle, for example: after a circle outline has been milled, the diameter of the circle is measured and then evaluated. If there are any deviations, the milling programme can then be adapted for the next part undergoing the process. More complex approaches aim to manage process monitoring across multiple steps – or perhaps even multiple steps distributed across multiple subcontractors.
Data: the key to more efficient planning
Improved planning and control over processes are important elements in both of these approaches to optimising production. To improve planning, it is vital to have a significantly increased pool of data that is highly varied and needs to be analysed in specific ways, but the sheer volume and level of detail involved in this kind of data far exceed the capacity of humans to perform the analyses. Instead, complex software solutions are needed to derive added value from data.
Depending on the level of maturity of both the data and the analyses, software can be a useful tool – and is increasingly being called upon – in supporting the work of humans in production environments. The level of input that software has can range all the way up to fully autonomous production. The data analytics maturity model shown in Figure 1 can help you map out what is happening in your own production scenario. It provides an overview of the relationship between data maturity and the potential impact of software on the development process.
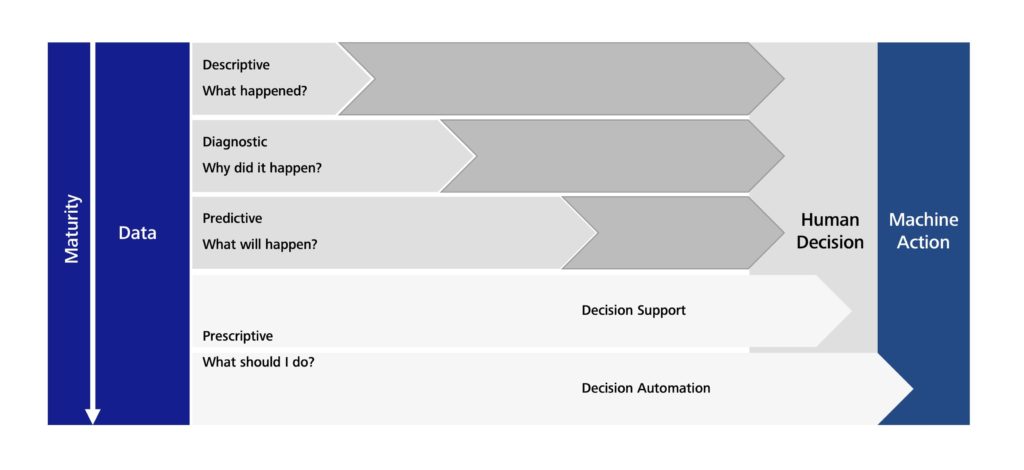
At the lowest level of the model (Descriptive), the data only provides information about events on a machine or production line that have happened in the past. A lot of human interaction, diagnostics and – ultimately – human decisions are required to initiate the necessary machine actions and put them into practice. The more mature the data (at the Diagnostic and Predictive levels), the less human interaction is needed. At the highest level (Prescriptive), which is what useful systems aim to achieve, it is possible for software to plan and execute every production process fully autonomously.
Aspects of data in digital twins
As soon as data of any kind starts to be collected, questions concerning how it needs to be sorted and organised quickly come about. Let’s take the example of a simple element or component as shown in Figure 2. Live data is produced cyclically while this component is being operated within a production machine; however, data of other kinds – such as the bill of materials and technical drawings – may be more pertinent during other stages in the component’s life (during its manufacture, for example). If the component is not actually present but you still want to collect data about it, you can draw on a 3D model and a functioning behaviour model that can be used to simulate statuses and functions.
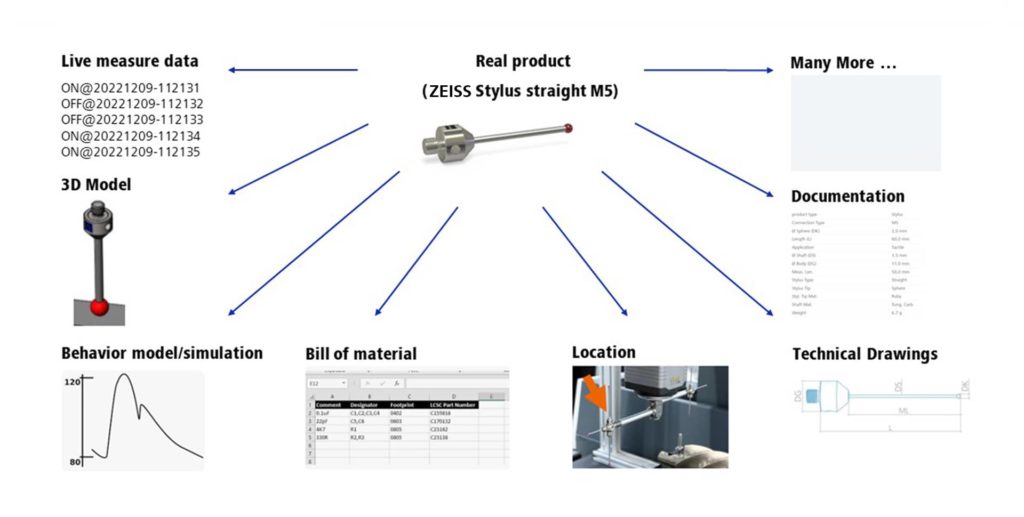
On encountering the term “digital twin”, most people’s minds simply jump straight to a 3D model that has been augmented with behaviour data and can be used for simulation purposes. However, this is only one side of the story in an Industry 4.0 context.
Germany’s Plattform Industrie 4.0 initiative defines a digital twin as follows:
A digital twin is a digital representation of a product* that is sufficient for fulfilling the requirements of a range of application cases.
Under this definition, a digital twin is even considered to exist in the specific scenario I outlined above – which indicates that there are lots of different ways of defining what a digital twin is, depending on your perspective and application. The most important thing is that you and the party you are working with agree on what constitutes a digital twin.
Digital twin: type and instance
To gain a better understanding of the digital twin concept, we need to look at two different states in which it can exist: type and instance.
A digital twin type describes all the generic properties of all product instances. The best comparison in a software development context is a class. Digital twin types are mostly used in the life cycle stages that take place before a product is manufactured – that is, during the engineering phase. Digital twin types are often linked to test environments in which efforts are made to optimise the properties of the digital twin, so that an improved version of the actual product can then be manufactured later on.
A digital twin instance describes the digital twin of exactly one specific product, and is linked explicitly with that product. There is only one of this digital twin instance anywhere in the world. However, it is also completely possible for this instance of a digital twin to represent just one specific aspect of the actual product – which means that multiple digital twins, all representing different aspects, can exist alongside each other. The closest comparison for this in a software development context is an object. Digital twin instances are usually encountered in the context of operating actual products. In many cases, digital twin instances are derived from types (in a similar way to objects being derived from classes in software development).
Digital twins in the manufacturing process
In the context of Industry 4.0 and, therefore, the manufacturing process, it is important to be constantly aware of whether a digital twin is referring to the production machine or the workpiece (product) to avoid any misunderstandings. Both can have a digital twin, but the applications in which each is involved are very different.
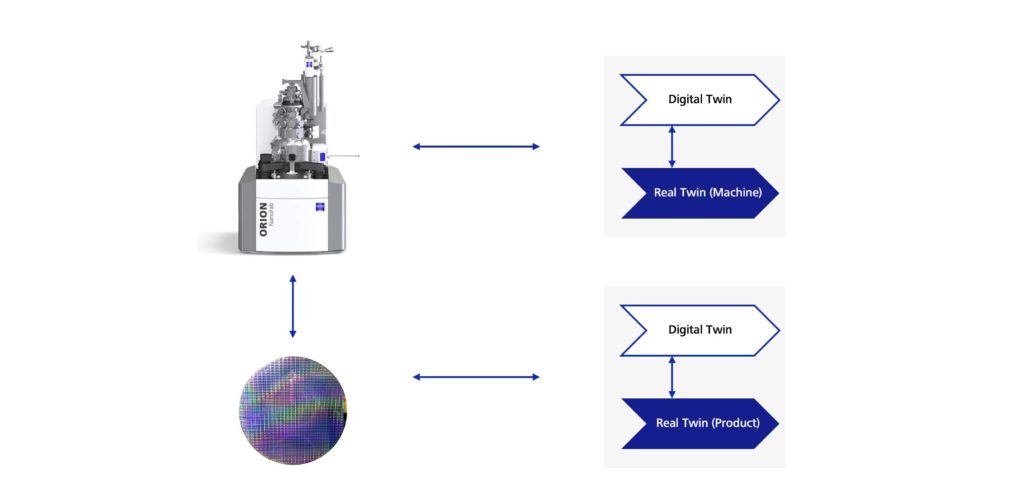
If the process of planning the actual production work were the most important aspect of the scenarios I am presenting here, I would be more likely to deal with digital twins of my production machines. If my focus were on augmenting data for my workpiece, and therefore for my product, I would be more likely to turn to a digital twin for the product. There is no clear distinction in how these aspects are used: both approaches can be used for me and my production work, but may also be beneficial for the users of my products.
Categorising digital twins according to the flow of information
To gain a better understanding of how a digital model evolves into a digital twin, it is possible to consider aspects relating to the flow of information that leads from a real-life object to a digital object[2].
Today, digital models of objects are already an industry standard. A 3D model of a component provides a succinct example of this: it is augmented by information from a 3D CAD program, for example, and can be used to visualise pertinent scenarios (such as collision testing using other 3D models). When a digital model is cyclically and automatically enhanced with data during the production process, the result is what is known as a digital shadow. A simple example of this is an operating hours counter for an object: the counter is automatically triggered by the actual object and the data is stored in the digital object. Analyses would continue to be conducted manually in this case. Now and again, the term digital footprint is also used to mean the same thing as a digital shadow. If the digital shadow then automatically feeds information back to the actual object and affects how it works, the result is a digital twin. Plattform Industrie 4.0 contexts still refer to cyber-physical systems, involving digital twins and real twins that are linked to one another via data streams and have an impact on one another.
![Definition of digital model, shadow and twin based on flows of information[2]](https://blogs.zeiss.com/digital-innovation/en/wp-content/uploads/sites/3/2023/06/Folie1-1024x442.jpeg)
It is only really useful to break things down based on flows of information in the case of digital twin instances. The same breakdown is not used for digital twin types because the actual object simply does not exist. If a digital twin encompasses multiple aspects, a breakdown of this kind should be applied to each separate aspect, since different definitions are applied to the various aspects.
From digital twin to improved production planning
The definitions and categorisations introduced up to this point should be enough to establish a common language for describing digital twins. While it is not possible to come up with a single definition that covers digital twins, we do not actually need one either.
So why do we need digital twins anyway?
Considering the essential role that data and evaluations play in improving production efficiency, there are some steps that can be taken to achieve good results:
- Centralise all data collected to date
All the data that a machine, for example, has accumulated up to a certain point is currently stored according to aspect in most companies’ systems. For instance, maintenance data is compiled in an Excel sheet that the maintenance manager possesses, but quality control data concerning the workpieces is kept in a CAQ database. There are no logical links between the two aspects of data even though they could have a direct or indirect relationship with one another. But it also take some effort to assess whether there actually is a relationship between them. The only way to identify relationships (with the help of software) is to store the data in a central location with logical links. As a result, it may then be possible to generate added value from the data. - Use standardised interfaces
When data is stored centrally, it is useful for it to be accessible via standardised interfaces. Once this has been established, it is very easy to program automatic flows of information, in turn making it easier to manage the transition from simple model to cyber-physical system. The resulting digital twin of a component or a machine forms the basis for subsequent analyses. - Creating business logic
Once all the conditions for automated data analyses have been put in place, it is easier to use software (business logic) that assists in making better decisions – or is able make decisions all on its own. This is where the added value that we are aiming for comes in.
While stages 1 and 2 create only a little added value, or none at all, they form the basis for stage 3.
While I always advocate for changing or improving production processes instead of applications, it is clear that there is a certain amount of fundamental work that has to be put in first. Creating digital twins is an essential stepping stone on the road to future success – and therefore an important pillar in an Industry 4.0 context.
Practical solutions
Plattform Industrie 4.0’s Asset Administration Shell concept is a useful tool that allows you to start on an extremely small scale but then benefit from agile expansion. The concept predefines general interfaces, with specific interfaces then able to be added later. It provides a basis for creating a standardised digital twin for any given component. Whether you choose to use this concept as a starting point or program an information model that is all your own is up to you – however, the advantage of using widespread standards is that data may be interoperable, something that is particularly useful in customer/supplier relationships. We can also expect to see the market introduce reusable software that is able to handle these exact standards. As of 2022, the Asset Administration Shell concept is a suitable tool for creating digital twins in industry contexts – and this is improving all the time. Now, the task is to use it in complex projects.
Sources:
[1] J. Hagerty: 2017 Planning Guide for Data and Analytics. Gartner 2016
[2] W. Kritzinger, M. Karner, G. Traar, J. Henjes and W. Sihn: 2018 Digital Twin in manufacturing: A categorical literature review and classification.
*The original definition uses the word asset rather than product. The word I have chosen here is simpler, even if it does not cover all bases.
[…] The digitized data for workpieces, machines and other manufacturing elements can be grouped under the term digital twin, which was presented in the blog article “Digital twins: a central pillar of Industry 4.0” by Marco Grafe. […]
[…] Versionsstand. Fraunhofer-Institute und Industrieanwender treiben dieses Konzept seit Jahren voran. ZEISS dokumentiert die Brücke zwischen Messtechnik und digitalem Zwilling als zentralen […]