Im ersten Beitrag dieser Blogartikelreihe wird eine leichtgewichtige Methode beschrieben, um Abweichungen zwischen dem vorgegebenen User Interface Design und der implementierten Anwendung zu beseitigen. Dabei arbeiten Entwicklerinnen und Entwickler sowie Spezialistinnen und Spezialisten für User Interface (UI) / User Experience (UX) mittels Pair Programming eng zusammen, um die Usability und das Erscheinungsbild einer Anwendung unkompliziert zu optimieren.
In unserem Projekt führen wir regelmäßig solche „UI-Dev-Sessions“ durch. In diesem Blogbeitrag möchte ich von unseren Erfahrungen berichten – weg von der Theorie, hin zur Praxis.
Wieso sind die UI-Dev-Sessions für uns wichtig?
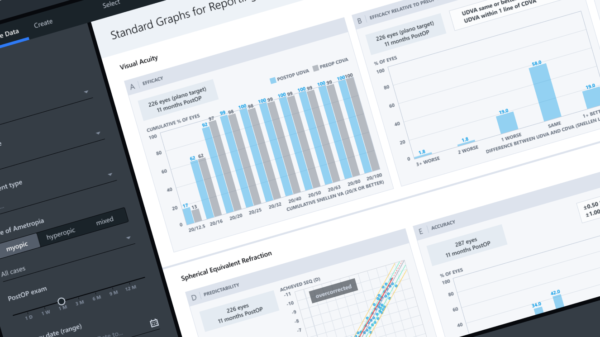
Im Rahmen des Projektes wird eine Standalone-Software entwickelt, welche Fachleuten der Augenheilkunde als Unterstützungstool zur Erhebung von Patientendaten sowie zur Analyse der Ergebnisse von operativen Laser-Sehkorrekturen dient. Auch im medizinischen Umfeld entwickelt sich User Experience immer mehr zu einem wichtigen Kaufkriterium. Neben Sicherheit, dem wohl wichtigsten Kriterium für Medizinprodukte, gewinnen weiche Kriterien wie “Joy of Use” und das Erscheinungsbild an Bedeutung. Die UI-Dev-Sessions sind für uns eine Möglichkeit, unserer Anwendung den Feinschliff zu verleihen.
„The details are not the details. They make the design.”
Charles Eames, Designer
Wie laufen die UI-Dev-Sessions bei uns ab?
Unser Projektteam arbeitet agil und nutzt Scrum als Rahmenwerk für sein Vorgehen. Wie ein Großteil der Teams bei ZEISS Digital Innovation (ZDI) arbeiten die Teammitglieder verteilt, das heißt sie befinden sich nicht am selben Standort und damit auch nicht im selben Büro. Unser Projektteam ist über vier Standorte in zwei Ländern verteilt. Dabei sind die Rollen Scrum Master, Entwickler, Tester, Business Analyst und UI-/UX-Spezialist vertreten.
An einer UI-Dev-Session nehmen bei uns meist jeweils Personen aus den Bereichen UI/UX sowie Entwicklung teil. Die Spezialistinnen und Spezialisten für UI/UX haben ihren Fokus auf zwei verschiedenen Aspekten, wodurch sie sich optimal ergänzen: einerseits auf dem visuellen Design des UI sowie andererseits auf dem Verhalten der UI-Komponenten. Die teilnehmenden Entwicklerinnen und Entwickler besitzen eine hohe Affinität für Frontend-Entwicklung. Eine von diesen Personen nimmt an jeder UI-Dev-Session teil und hat den Überblick über die zu erledigenden Punkte. Einige Tage vorher erinnern die Spezialistinnen und Spezialisten für UI/UX im Daily daran, dass eine UI-Dev-Session stattfinden wird und dass noch eine Person aus dem Entwicklungsteam als Unterstützung benötigt wird. Je nach Verfügbarkeit wird dann abgestimmt, wer unterstützen kann. Es gilt damit das Vier-Augen-Prinzip auf beiden Seiten (Design und Entwicklung) wodurch Fehler und umfangreiche Review-Runden vermieden werden können.
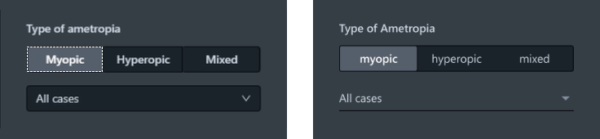
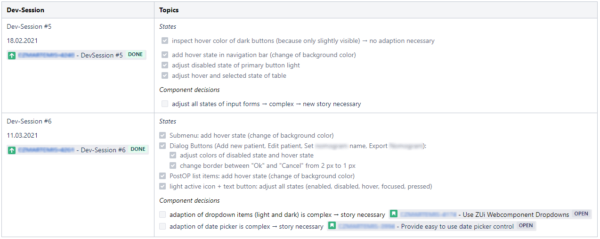
Die Liste mit den zu lösenden UI-Fehlern wird im Projekt-Wiki von den Expertinnen und Experten für UI/UX gepflegt, strukturiert und priorisiert und ist jedem Teammitglied zugänglich. Dazu wird Confluence von Atlassian als Tool eingesetzt. Ein Ausschnitt der Themen ist in Abbildung 2 dargestellt.

Da unsere Liste mit möglichen Themen aktuell recht umfangreich ist, sind regelmäßige Sessions notwendig. Eine UI-Dev-Session findet einmal pro Sprint – das heißt einmal alle drei Wochen – für zwei Stunden statt. Haben andere Themen im Sprint Priorität, kann der Termin auch kurzfristig verschoben werden, bestenfalls jedoch innerhalb des gleichen Sprints. Der Termin wird remote mit Hilfe von Microsoft Teams durchgeführt, da die Teilnehmenden über die Standorte Dresden, Leipzig und Miskolc verteilt sind.
Ein bis zwei Tage vor der UI-Dev-Session suchen sich die Entwicklerinnen und Entwickler aus der Liste im Projekt-Wiki einige Punkte heraus und beginnen, diese vorzubereiten. Dazu zählt beispielsweise, die entsprechenden Stellen im Code mit To-dos zu markieren, um die Zeit in der UI-Dev-Session effizient für die eigentlichen Anpassungen zu nutzen.
Zu Beginn der UI-Dev-Session gehen alle Teilnehmenden gemeinsam kurz die ausgewählten UI-Fehler durch, welche im Termin verbessert werden sollen. Anschließend werden die Themen von oben nach unten erledigt. Eine Person aus dem Bereich Entwicklung überträgt den Bildschirm und hat die Entwicklungsumgebung sowie den Styleguide in Figma geöffnet. Die weiteren Teilnehmenden haben ebenfalls den Styleguide geöffnet. Einer der Vorteile von Figma besteht darin, dass die Anwesenden sehen können, wo die anderen Beteiligten sich gerade im Styleguide befinden. So können die relevanten Stellen von allen schnell gefunden werden. Die Spezialistinnen und Spezialisten für UI/UX helfen den Entwicklerinnen und Entwicklern dabei, sich schneller im Styleguide zu orientieren und die relevanten Informationen zu finden. Wichtig dabei ist, dass sich die Personen aus dem Entwicklungsteam die relevanten Stellen selbst ansehen können und z. B. Farbwerte nicht einfach nur “vorgesagt” werden. So wird auch der Umgang mit dem Styleguide trainiert.
Die ausgewählten Punkte werden nach und nach erledigt. Werden die ausgewählten UI-Fehler schneller behoben als vermutet, werden innerhalb des Termins neue Themen nachgezogen. Bleiben ausgewählte Themen offen, werden diese zu Beginn des nächsten Termins erledigt.
Während der Vorbereitung oder in der UI-Dev-Session stellt sich hin und wieder heraus, dass Themen aufwändiger sind als zunächst angenommen. Die Entwicklerinnen und Entwickler teilen das den Spezialistinnen und Spezialisten für UI/UX mit. Diese verschieben das Thema dann aus dem Projekt-Wiki in ein eigenes Backlog Item in Jira, beispielsweise als Improvement oder neue User Story.
In einem Anschlusstermin, der meist ein bis zwei Tage nach der UI-Dev-Session stattfindet und maximal 30 Minuten dauert, werden die Ergebnisse den Testerinnen und Testern vorgestellt. Das ist wichtig, um festzustellen, ob Testfälle von den Änderungen betroffen sind. Anschließend wird die Themenliste im Projekt-Wiki von den Spezialistinnen und Spezialisten für UI/UX aktualisiert. Die erledigten Punkte werden in Tabellenform dokumentiert, um das Nachvollziehen der durchgeführten Änderungen zu ermöglichen.
Es muss nicht überall einen Haken geben
In unserem Projekt hat sich der Einsatz der UI-Dev-Sessions bewährt, um das Erscheinungsbild der Anwendung schnell und unkompliziert zu optimieren. Für uns bringen die Sessions primär folgende Vorteile mit sich:
- Es werden UI-Fehler beseitigt, welche schon lange bekannt sind, denen aber gegenüber der Entwicklung neuer Features nur eine geringe Priorität beigemessen wurde.
- Die leichtgewichtige Methode mit geringem Dokumentationsaufwand lässt sich unkompliziert in unsere Sprints integrieren.
- Wir erreichen eine hohe Compliance mit dem ZEISS Styleguide für User Interfaces.
Darüber hinaus stärken die Sessions die Kollaboration und die Wissensverteilung im Team:
- Durch die Zusammenarbeit zwischen den Bereichen Entwicklung und UI/UX können UI-Fehler effizient behoben werden, da die Entwicklerinnen und Entwickler sich auf die Implementierung konzentrieren können und die UI-/UX-Spezialistinnen und -Spezialisten die designspezifischen Vorgaben (z. B. Schriftfarbe, Abstand) direkt mündlich weitergeben können.
- Die Expertinnen und Experten für UI/UX lernen Implementierungsprobleme der Entwicklerinnen und Entwickler kennen, welche beispielsweise aus den eingesetzten Technologien resultieren.
- Mit den gesammelten Erfahrungen aus den UI-Dev-Sessions können die UI-/UX-Spezialistinnen und -Spezialisten zukünftige Designentscheidungen noch besser anhand des Entwicklungsaufwandes treffen.
- Das Entwicklungsteam lernt das Design-Tool Figma inklusive des Styleguides besser kennen.
- Das Team aus in UI/UX spezialisierten Personen hat die Gelegenheit, Designentscheidungen zu erklären und den Entwicklerinnen und Entwicklern einen Einblick zu geben, worauf es bei den Designs ankommt.
- Das Entwicklungsteam arbeitet ein besseres Bewusstsein für Feinheiten im Design aus und kann so zukünftig UI Defects eher vermeiden.
Die Liste der Vorteile, welche die Methode für uns mit sich bringt, ist somit lang. Doch wo ist der Haken? Für uns gibt es aktuell keinen und wir sind von der Methode überzeugt. Wir empfehlen sie daher jedem Team, bei welchem sich über die Zeit eine Vielzahl kleinerer UI-Fehler im Projekt angesammelt haben. Das Vorgehen ist flexibel und lässt sich je nach Bedarf des Teams adaptieren. Beispielsweise kann der Teilnehmerkreis minimiert oder das Zeitfenster erweitert werden.
Ausblick
Unser Ziel ist es, mit Hilfe der UI-Dev-Sessions die Liste der bestehenden UI-Fehler kontinuierlich zu verkleinern. Um die Anzahl neu hinzukommender UI-Fehler möglichst gering zu halten, wollen wir zukünftig die UI-Dev-Sessions schon während der Implementierung einer User Story in den Sprint integrieren. So können neue Abweichungen vom Design von vornherein vermieden werden.