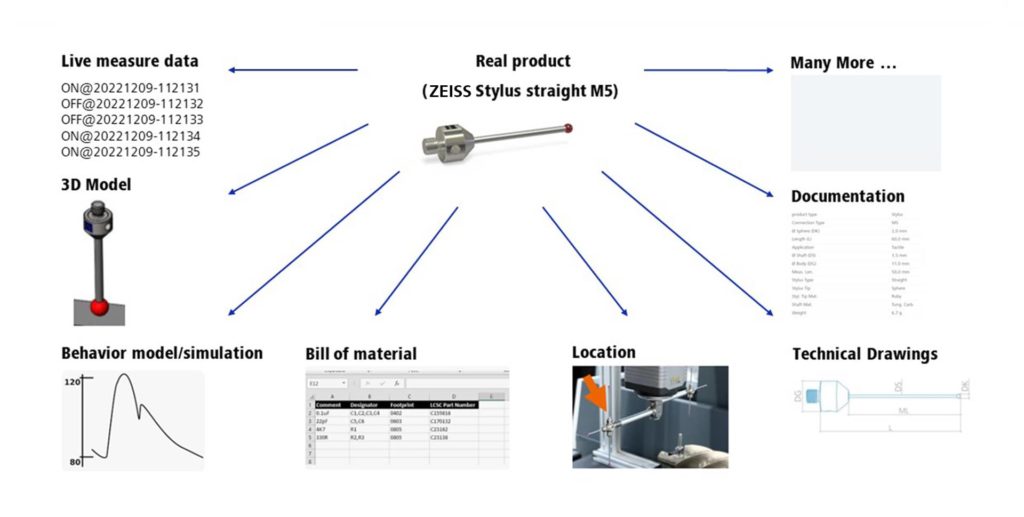
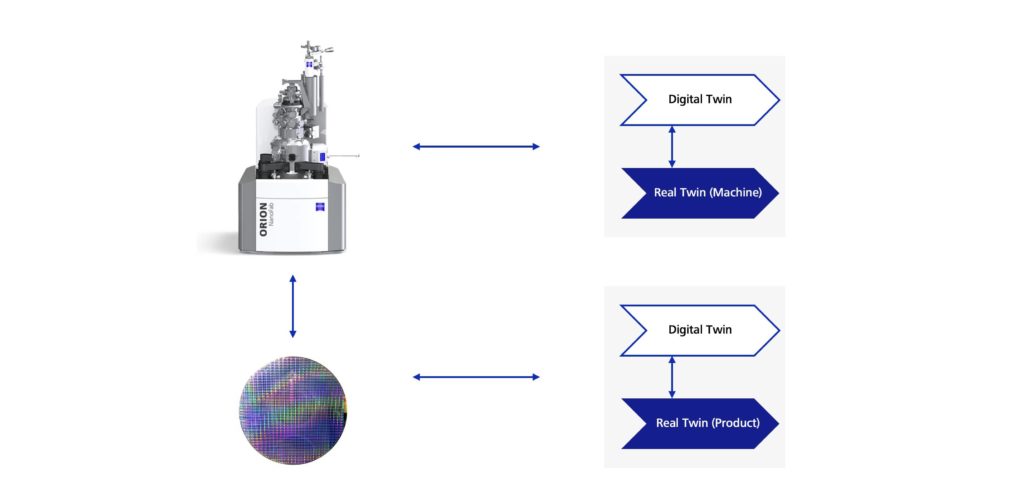
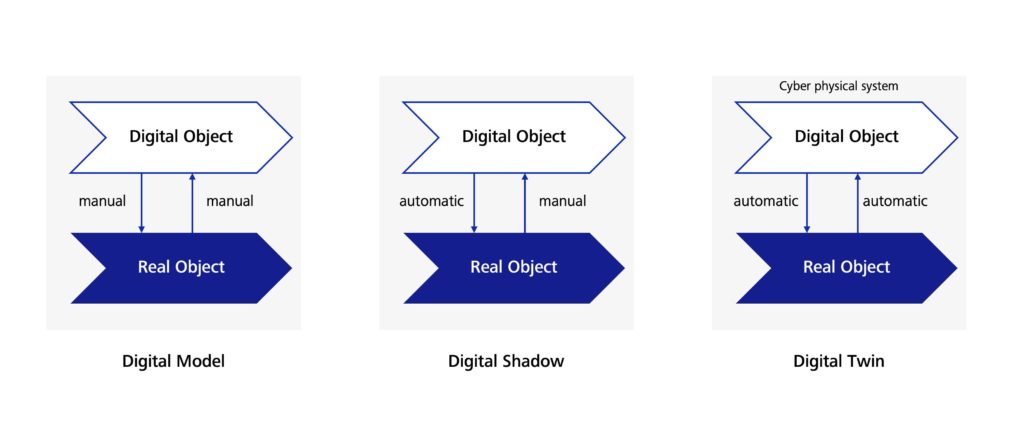
Die Asset Administration Shell (AAS) ist ein aufstrebendes Konzept im Zusammenhang mit der Datenhaltung eines Digitalen Zwillings. Es handelt sich dabei um eine virtuelle Repräsentation einer physischen oder logischen Einheit, wie beispielsweise einer Maschine oder eines Produkts. Die AAS ermöglicht es, relevante Informationen über diese Einheit zu sammeln, zu verarbeiten und zu nutzen, um eine effiziente und intelligente Produktion zu gewährleisten. Die Architekturstandardisierung der AAS ermöglicht die Kommunikationen zwischen digitalen Systemen und ist damit die Grundlage für Cyber Physical Systems (CPS). Die Herleitung des Bedarfs eines Digitalen Zwillings in der Industrie finden Sie hier: ZEISS Digital Innovation Blog – Der digitale Zwilling als eine Säule von Industrie 4.0
Dieser Artikel beschäftigt sich mit der konkreten Implementierung eines Beispiels. In einem Szenario wollen wir mit Hilfe einer Referenzimplementierung des Fraunhofer-Institut für Experimentelles Software Engineering IESE (BaSyx Implementierung der AAS v3) einen Austausch von Informationen zwischen zwei beteiligten Partnern herstellen. Beide Beteiligten sind dabei einfachheitshalber innerhalb eines Unternehmens angesiedelt und teilen sich die Infrastruktur.
Hinweis: Auch über Unternehmensgrenzen hinweg kann diese Anwendung verteilt werden. Die dabei zu berücksichtigenden sicherheitskritischen Aspekte sind nicht Teil dieses Szenarios.
Szenario
Werk A ist Hersteller von Messkopfzubehör und stellt u. a. Taster her.
Werk B stellt Messköpfe her und möchte Taster von Werk A an ihrem Messkopf verbauen.
Zusätzlich zur physischen Weitergabe des Tasters müssen Informationen ausgetauscht werden. Die Verkaufsabteilung von Werk A stellt Kontaktinformationen zur Verfügung, damit der technische Einkauf von Werk B Preise sehen und verhandeln kann. Weiterhin muss Werk A z. B. ebenfalls eine Dokumentation zur Verfügung stellen.
Für diesen Austausch der beiden Informationen:
- Kontaktdaten und
- Dokumentation
soll das Konzept der AAS zum Einsatz kommen.
Infrastruktur
Für unser Szenario wollen wir den Typ 2 der Asset Administration Shell verwenden. Dabei wird die AAS auf Servern zur Verfügung gestellt und es findet nicht ein Austausch von AASX-Dateien statt, sondern eine Kommunikation zwischen den unterschiedlichen Services via REST-Schnittstellen.
In unserem Szenario laufen die unterschiedlichen Services innerhalb eines Kubernetes Clusters in Docker Containern.
Services
Wir nehmen die BaSyx Implementierung her, um die AAS zur Verfügung zu stellen. Genauer gesagt, folgende Komponenten:
- AAS Repository,
- Submodel Repository,
- ConceptDescription Repository,
- Discovery Service,
- AAS Registry sowie
- eine Submodel Registry.
AAS Repository, Submodel Repository und ConceptDescription Repository werden dabei innerhalb eines Containers zur Verfügung gestellt – dem AAS environment.
Technische Umsetzung
Die Kommunikation erfolgt dabei nur mittels API-Aufrufen an die entsprechenden REST-Schnittstellen der Services.
Wir werden dabei einfache Python-Skripte nutzen, um eine Kommunikation darzustellen, bei dem das Herstellerwerk B Informationen zu einem Produkt (hier: ein Taster für einen Sensor) des Komponentenwerks A erhalten will.
Ablauf
Werk B kennt nur eine Asset ID von einem Taster, aber weiß sonst nichts über diese Komponente.
- Werk B fragt mit der Asset ID den Discovery Service an, um an eine AAS ID zu gelangen.
- Mit dieser AAS ID wird die zentrale AAS Registry angefragt, die den AAS Repository Endpunkt des Werk A zur Verfügung stellt.
- Über diesen Endpunkt und die AAS ID erhält Werk B die komplette Asset Administration Shell inkl. der relevanten Submodel-IDs.
- Mit diesen Submodel-IDs (u.a. für Kontaktinformationen und Dokumentation) fragt B die Submodel Registry von A an und erhält die Submodel Repository Endpunkte.
- B fragt die Submodel-Endpunkte an und erhält die kompletten Submodel-Daten. Zu diesen Daten gehört die gewünschte KontaktiInformation für den Einkäufer und eine komplette Dokumentation zu dem Taster-Asset.
Im Folgenden wird der Ablauf noch einmal im Detail mittels UML-Sequenz-Diagrammen dargestellt.
UML-Sequenz: Erstellung Registrierung AAS im Komponenten-Werk A
Das Werk A ist für die Registrierung ihrer eigenen Komponente zuständig.

Abbildung 1: UML-Sequenz: Erstellung Registrierung AAS im Komponentenwerk A
UML-Sequenz: Anfordern der Komponentendaten
Das Werk B benötigt Daten zu der Komponente und fragt entsprechend in der AAS-Infrastruktur an. Hierbei steht dem Werk B ggf. nur die Asset ID der Komponente zur Verfügung, in unserem Fall die des Tasters.

Abbildung 2: UML-Sequenz: Anfordern der Komponentendaten
Implementierung
Damit der oben beschriebene Ablauf funktioniert, müssen zum einen die erwähnten Services zur Verfügung gestellt werden. Zum anderen müssen Shells und Submodelle angelegt werden und zusätzlich in den Registries hinterlegt werden.
Bereitstellung der Services
Die Bereitstellung erfolgt via Docker Container, die innerhalb eines Kubernetes Clusters laufen. Hierbei bekommt jedes BaSyx Image ein Kubernetes Deployment welches via Kubernetes Replica-Sets die entsprechenden Pods starten.
Mittels z. B. Port-Forwarding werden die entsprechenden Ports vom Host erreichbar gemacht. Dieses ist notwendig um die APIs entsprechend von den Beispiel-Python-Skripten anzusprechen.
Die Kubernetes Deployment Konfiguration schaut folgendermaßen aus und ist dabei relativ einfach gehalten. Es existieren vier Deployments mit jeweils einem Replica-Set.

Abbildung 3: Kubernetes-Deployment-Konfiguration
Erzeugen der AAS von Werk A
Werk A möchte z. B. die Kontaktinformationen zu seiner Taster-Komponente zur Verfügung stellen.
Dazu werden Submodelle im AAS Repository erzeugt (hier: im AAS-Environment) und in der Submodel Registry registriert.
Danach wird die Asset Administration Shell im AAS Repository erzeugt und der AAS Registry registriert.
Anschließend wird im AAS Repository die Referenz der Shell hinzugefügt.
Hiermit ist der Registrierungs-Prozess vom Komponentenwerk abgeschlossen.
Anfragen von Kontakt-Informationen vom Werk B
Werk B möchten die Kontakt-Informationen erhalten und fragt entsprechend dem oben beschriebenen Workflow die unterschiedlichen AAS-Services an. Am Ende wird der Submodel-Datensatz abgerufen, der die gewünschten Werte enthält und kann dann z. B. innerhalb eines User-Interfaces zur Verfügung gestellt werden.
Fazit
Die Asset Administration Shell vom Typ 2 ist ein verteiltes System, welches auf die entsprechenden Repositories, Registries und den Discovery Service baut. In unserem Beispiel haben wir nur ein einfaches Submodel-Template für Kontaktdaten verwendet. Allerdings stehen weitaus mehr Templates für viele Anwendungsfälle zur Verfügung.
Die Kommunikation zwischen den Services zur Bereitstellung und zum Abruf der Daten ist relativ unkompliziert möglich, wobei in diesem Szenario Aspekte wie z. B. Sicherheit nicht im Fokus waren.
Die in diesem Artikel beschriebene Beispielimplementierung lässt das enorme Potential des AAS-Konzepts erahnen und regt dazu an, konkrete Umsetzungen zu starten.
Dieser Beitrag wurde verfasst von:

Daniel Brügge
Daniel Brügge arbeitet als Softwareentwickler bei ZEISS Digital Innovation mit dem Fokus auf Cloud-Entwicklung und verteilte Anwendungen.