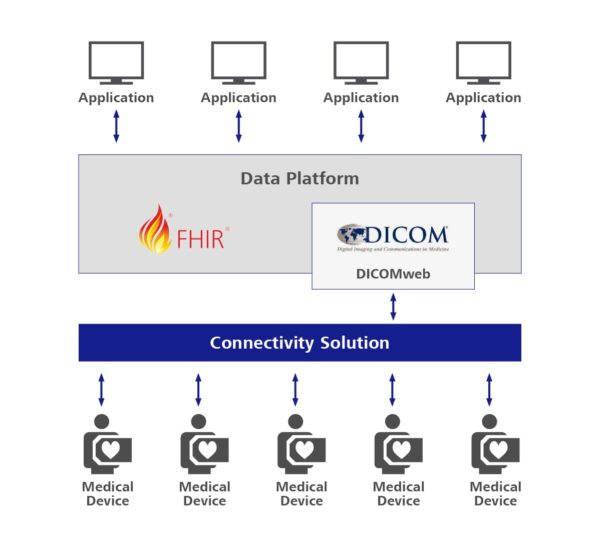
As the Industry 4.0 concepts mature, we will look at the Azure edition of Digital Twins. The definition of Digital Twins assumes the digital representation of real-world things’ (or people’s) properties, either in real time (for control and predictive maintenance) or in simulations to acquire and test behaviors before actual deployment. As such, Azure Digital Twins are closely related to Azure IoT services; however, they could do a bit more, as we will see below.

How are models created and deployed?
Azure Digital Twins relies on Digital Twins Definition Language (DTDL), which follows JavaScript Object Notation for Linked Data (JSON-LD), making it language-agnostic and connected to certain ontology standards. Root structure is declared as interface, which can contain properties, relationships, and components. Properties can contain telemetries (event-based, like temperature readings) or values (e.g., name or aggregate consumption), relationships describe connection between Twins (for example, floor contains room), and finally, components are also models referenced in interface per id (e.g., phone has camera component).
Models support inheritance, thus one can already think of these models as serverless (POCOs) classes. Indeed, from these models, instances are created which live in Azure Digital Twins. The logical question arises, if these are somehow classes, what about methods? This is where serverless Azure Functions find its use very well, as all events from Digital Twins can be captured and processed with Azure Functions. Hence, Azure Digital Twins, paired with Azure Functions, create powerful serverless infrastructure which can implement very complex event-driven scenarios by utilizing provided REST API for model and data manipulation. The price for this flexibility is a rather steep learning curve, and one must write functions for data input and output from scratch.
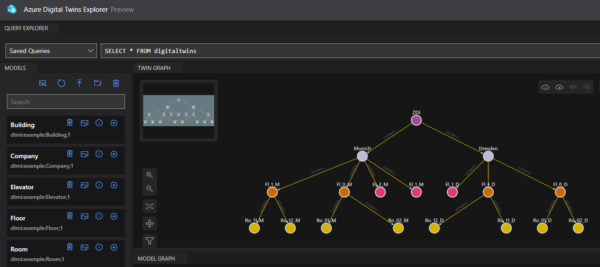
Json models can be created by hand, or even easier, Microsoft provides sample ontologies (prefabricated domain models) available in Excel that can be extended or adapted. Using Digital Twins Explorer (currently on preview in Azure Portal), these models can be uploaded in Azure with already prescribed instance and relationship creation automatization. Underneath Azure Digital Twins Explorer is REST API, so one can also programmatically do this as well.
In our sample smart building implementation (depicted in Image 1) we created and uploaded models (shown on the left) and instances with relations (shown on the graph on the right). There is a company model instance for ZEISS Digital Innovation (ZDI), which has two buildings Dresden and Munich each containing floors, rooms, and elevators.
How data come into the system?
In our smart building implementation (depicted in Image 2) we utilize IoT Hub to collect sensor data from rooms (temperature, energy consumption, number of people in the rooms, etc.), as well as OPC UA converted data from elevators.
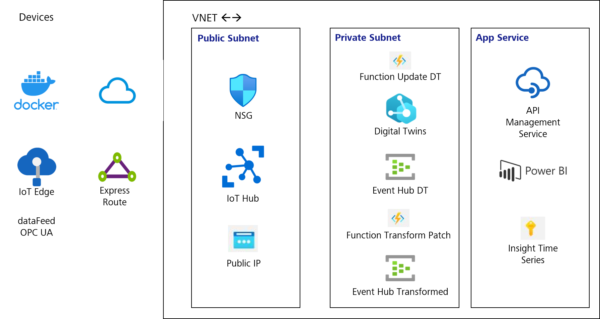
Normally, IoT Hub easily integrates with Insight Time Series with a couple of clicks out of the box, but some functions are necessary to intercept this data with Digital Twins. The first function reacts to IoT Hub Event Grid changes and propagates updates to Digital Twins, which can then trigger other functions, for example calculating and updating the aggregate energy consumption in the room and propagating this to all parents. All these changes in Digital Twins are streamed to the Event Hub in an update patch format that is not readable by Insight Time Series. Here comes another function which converts these patch changes and streams them to another Event Hub to which Insight Time Series can subscribe and save the data. Sounds over-engineered? It is! As mentioned, there is a lot of heavy lifting that needs to be done from scratch, but once familiar with the concepts, the prize is flexibility in implementing almost any scenario. From vertical hierarchies with data propagations (such as heat consumption aggregations) to horizontal interactions between twins based on relationships (as in when one elevator talks and influences the other elevators’ performance in the same building based on an AI model) can be implemented.
Another powerful feature is that we can stream and mix data from virtually any source in Digital Twins to extend their use for business intelligence. From ERP and accounting systems, to sensors and OPC UA Servers, data can be fed and cross-referenced in real time to create useful information streams – from tea bags that will run out in the kitchen on a snowy winter day to whether the monetary costs for elevator maintenance are proportional to the number of trips in year.
How are the data analyzed and reported?
In many industrial systems, and thanks to increasing cheap storage, all telemetry data usually land in a time series for analytics and archiving.
However, data alarms, averages, and aggregations can be a real asset in reporting in real time. Digital Twins offer full REST API where twins can be queried based on relations, hierarchies, or values. These APIs can be also composed and exposed to third parties in API Management Services for real-time calls.
Another way is to utilize Time Series Insights for a comprehensive analysis on complete data sets or using time series dumps to create interactive reports using Power BI.
Both real-time and historical reporting has its place and optimal usage determination should be based on concrete scenarios.
Summary
Azure Digital Twins offer language-agnostic modeling that can accept a myriad of data types and support various ontologies. In conjunction with serverless functions, very complex and powerful interactive solutions can be produced. However, this flexibility comes with high costs for manual implementation in data flow using events and functions. For this reason, it is reasonable to expect that Microsoft (or an open source) will provide middleware with generic functions and libraries for standard data flows in the future.