Modern industrial production requires an expansion and digitalization of classical production flow control when it comes to smart approaches and networking. To do so, we must connect and integrate all levels of the automation pyramid with the aid of digital solutions and data processing systems.

Currently, there are numerous new technologies, such as artificial intelligence, digital twins and augmented reality, with a steadily growing significance for the smart production of the future. In order to use these innovative methods, they need to be linked to existing systems, albeit this has only been possible to a limited extent thus far. For example, there is no standardized approach to providing data for the use of artificial intelligence or for creating digital twins yet. Novel use cases, such as predictive maintenance, also require individual access to the required data.
New technologies and their application can only be successfully implemented by close cooperation between departments and with a clear integration strategy.
Feasibility in brownfield

Most digital transformation projects take place in brownfield production environments. This means that the production facilities are already in operation and, from an economic point of view, there is a need to find solutions that can be integrated with the existing machinery and software systems.
The development towards smart production requires new exchange channels that open up a third dimension of data flow and facilitate existing data to be made available centrally. It is economically inefficient to implement these new channels in every new project. Consequently, a generic approach should be taken, in which data is obtained from the respective production systems and made homogeneously accessible regardless of the individual use case. A central data platform, on which all existing production information is made accessible, is the basis of a flexible and scalable path for further development and optimization of production processes.
Advantages of a central data platform
- Democratic provision of existing machine data from the brownfield
- Fast integration of new technologies
- Implementation of innovative use cases
- Simple implementation of data transparency and data governance
- Access to historical and real-time data
- Scalable application development
- Increased efficiency and quality in data transfer
Challenges of data processing
There are defined interfaces for individual systems available that allow data to be easily read, e.g. from ERP or MES systems. The situation is different with a SCADA system, however, since it has a very heterogeneous and domain-specific build. Its interfaces and those of the subordinate machine control systems (PLC) are not uniformly defined. There are also no uniform industry access standards for direct access at sensor level, since this kind of use case has not yet been addressed by machine or sensor manufacturers. However, it is worthwhile to have direct access to the sensor system, as sensors deliver much valuable data beyond their actual functions, usually without exploiting the data.
Use case
 | Our example shows a classical inductive sensor, where usually only the “sensor on/off” signal is used. The following functions are already implemented at the factory and could also be evaluated: |
- Switch mode
- Switching cycle counter, reset counter
- Operating hours counter
- Absorption (analog measurement of the electric field)
- Indoor temperature
- Device information
- Application-specific identifier, system identifier, location code
Regardless of the existing exchange channel, there are challenges related to data at all levels. Examples include data protection, the creation of data silos, the processing of mass data, the interaction between humans and machines, and absent or non-standardized communication channels.
Given the highly heterogeneous infrastructure in production, solutions that are individually adapted to the existing conditions can provide a remedy and address the specific challenges at the individual levels. Data governance and data security as well as cybersecurity are taken into account.

Holistic approach

It is not only production flow control data that is relevant for optimal linkage of information and the associated benefits, such as efficient use of resources, increased productivity and quality. Companies have to take a large number of parameters into account, including: Deployment and maintenance planning, warehousing, availability of personnel and much more. The logical linking of this data can usually only be done manually. This information being available in digital form could save much time.
Due to the complexity of this topic and the strongly differing requirements of individual production environments, it is clear that standard solutions are insufficient for paving the way to unrestricted data availability, and thus to new technologies. It is therefore important to start by looking at the use cases that create the most added value.
The vision for more efficiency, flexibility and quality
Comprehensive plant-to-plant communication aimed at improving production processes and identifying the causes underlying quality issues can be realized using a central data platform. It allows the data provided to be exchanged across facilities via standardized interfaces. This fully automated exchange of information has many benefits for production. Production planning and control can react flexibly to information from suppliers and customers. Real-time data allow bottlenecks and problems to be identified and rectified more quickly. Quality deviations can also be traced back to their cause across facilities and recurring problems can be avoided through early anomaly detection. The exchange of data also reduces transportation and logistics costs. Moreover, direct communication between the facilities improves cooperation: The exchange of knowledge and experience can give rise to new ideas and innovations that further improve production.
Cross-factory communication in semiconductor and automotive production
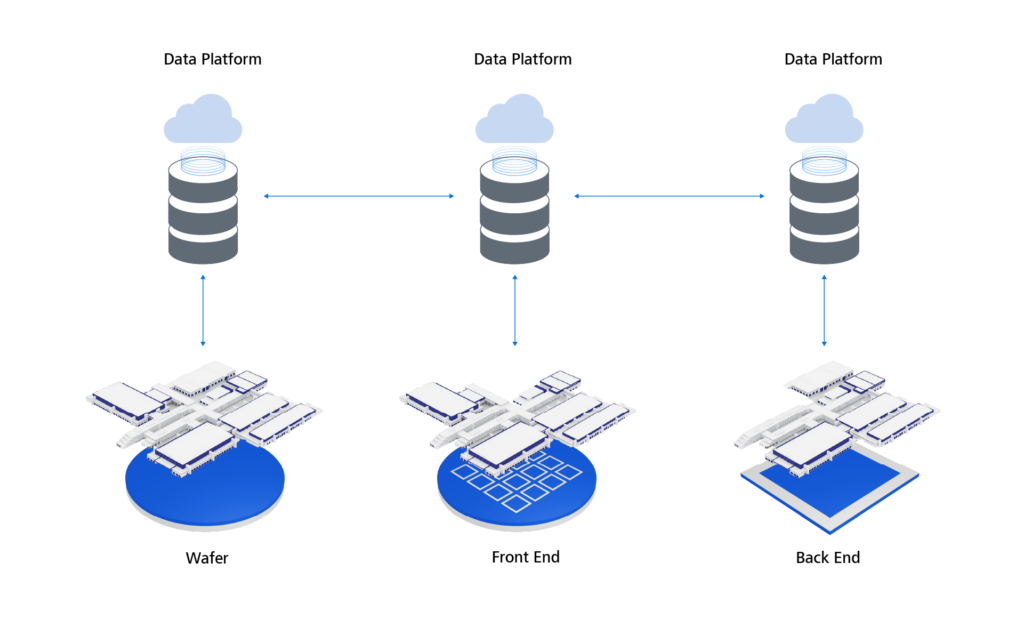

Maturity of the data platform
As described above, the availability of data is the foundation for future technologies. This access if provided by a central data platform. The real added value is created when the collected data can be used and put to good use in production. For this purpose, applications must be linked to the respective platform.

One future scenario describes a standardized data storage system that is accessed by all applications across different productions. By using the data platform, the applications can exchange data, thus rendering other storage locations obsolete.
With regard to the decision about transformation to a central data platform, we recommend taking an iterative approach and keep developing communication channels and systems at an appropriate pace. The advantage of customized software development is that it evolves in line with the requirements and needs of the company in question, always maintaining the necessary balance between evolution and revolution. In the first step, we therefore usually start with data engineering. However, we also consider future use cases in our architecture and take these into account in the continued development.
Conclusion
Merging data from different layers of the automation pyramid and other data silos onto a homogeneous platform allows companies to fully democratize and transform their data. Data management rules help to ensure the quality and security of the data. A cloud-based approach offers many benefits, such as scalability and flexibility. The utilization of a central data platform lets companies use their data more effectively and exploit the data’s full potential.
More information in our white paper: Industrial Data Platform