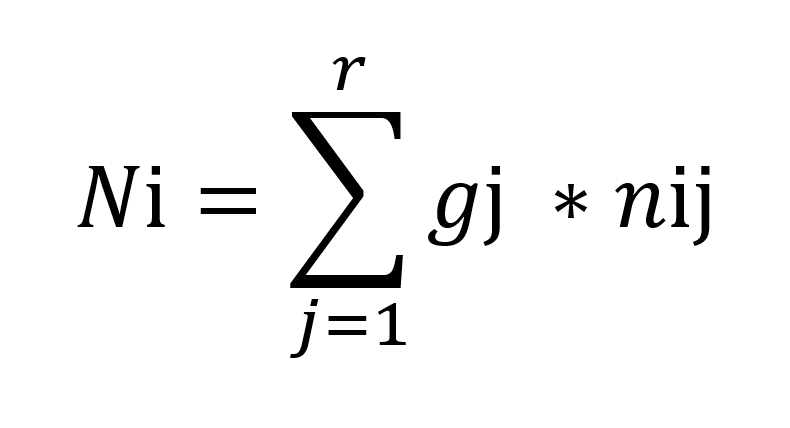Automatisiertes Testen von grafischen Oberflächen ist ein wichtiges Thema. Für jede GUI-Technologie gibt es mehrere Bibliotheken, die es sorgsam auszuwählen gilt, um zügig ein qualitativ hochwertiges und akkurates Ergebnis zu bekommen.
Im Bereich Web-Technologien gibt es viele bekannte Frameworks wie Selenium, Playwright, Cypress und viele mehr. Aber auch im Bereich WPF oder Winforms gibt es passende Vertreter und ich möchte heute FlaUI vorstellen.
FlaUI ist eine .NET-Klassenbibliothek für automatisiertes Testen von Windows Apps, insbesondere der UI. Sie baut auf den hauseigenen Microsoft Bibliotheken für UI Automation auf.
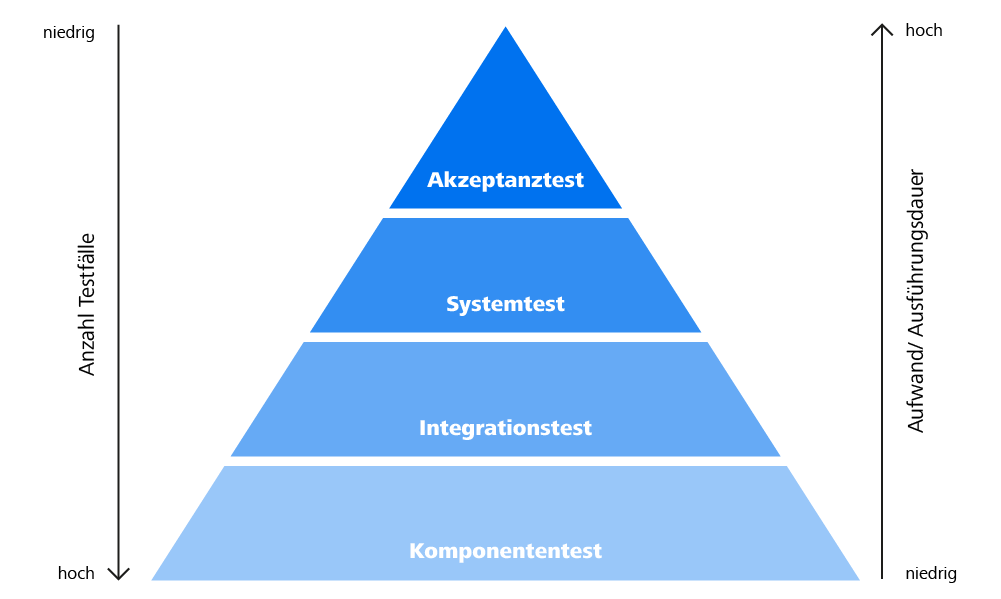
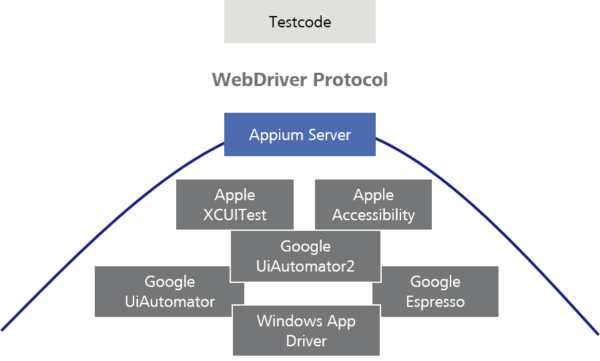
Abbildung: Pyramide der Test-Automatisierung
Geschichte
Am 20. Dezember 2016 hat Roman Roemer die erste Fassung von FlaUI auf Github veröffentlicht. Unter der Version 0.6.1 wurden die ersten Schritte in Richtung Klassenbibliothek für das Testen von .NET Produkten gelegt. Seitdem wurde diese konsequent und mit großem Eifer weiterentwickelt, um die Bibliothek mit neuen und besseren Funktionen zu erweitern. Die neueste Version trägt die Versionsnummer 4.0.0 und bietet Features wie z.B. das Automatisieren von WPF und Windows Store App Produkten sowie das Tool FlaUI Inspect, welches die Struktur von .NET Produkten ausliest und wiedergibt.
Installation
Über GitHub oder NuGet kann FlaUI geladen und installiert werden. Zudem werde ich für diesen Artikel und das nachfolgende Beispiel noch weitere Plugins / Frameworks sowie Klassenbibliotheken verwenden wie:
C# von OmniSharp
C# Extensions von Jchannon
NuGet Package Manager von Jmrog
.NET Core Test Explorer von Jun Han
Die neueste Windows SDK
NUnit Framework
Beispiel
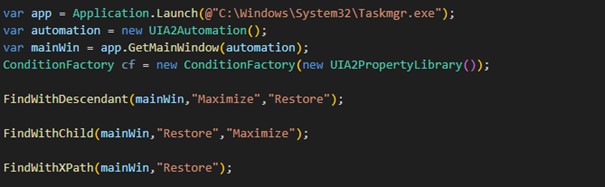
In diesem Beispiel werde ich mit mehreren unterschiedlichen Methoden eine typisches Windows-App, hier den Taskmanager, maximieren bzw. den Ausgangszustand wiederherstellen. Außerdem sollen unterschiedliche Elemente markiert werden.
Bei der Arbeit an diesem Artikel ist mir aufgefallen, dass Windows ein besonderes Verhalten aufweist: Wird ein Programm maximiert, ändert sich nicht nur der Name und andere Eigenschaften des Buttons, sondern auch die AutomationID. Das führte dazu, dass ich den Methodenaufrufen zwei verschiedene Übergabestrings für die AutomationID, „Maximize“ und „Restore“, mitgeben musste, die beide denselben Button ansprechen.
Code (C#)
Zuerst starten wir die gewünschte Anwendung und legen uns eine Instanz des Fensters für die weitere Verwendung an:
var app = Application.Launch(@"C:WindowsSystem32Taskmgr.exe"); var automation = new UIA2Automation(); var mainWin = app.GetMainWindow(automation);
Desweiteren benötigen wir noch die Helper Class ConditionFactory:
ConditionFactory cf = new ConditionFactory(new UIA2PropertyLibrary());
Diese Helper Class bietet uns die Möglichkeit, Objekte nach bestimmten Bedingungen zu suchen. Wie zum Beispiel, die Suche nach einem Objekt mit einer bestimmten ID.
In den folgenden Methoden wollen wir, wie oben erwähnt, das Programm maximieren und wieder den Ausgangszustand herstellen. Außerdem wollen wir Elemente hervorheben:
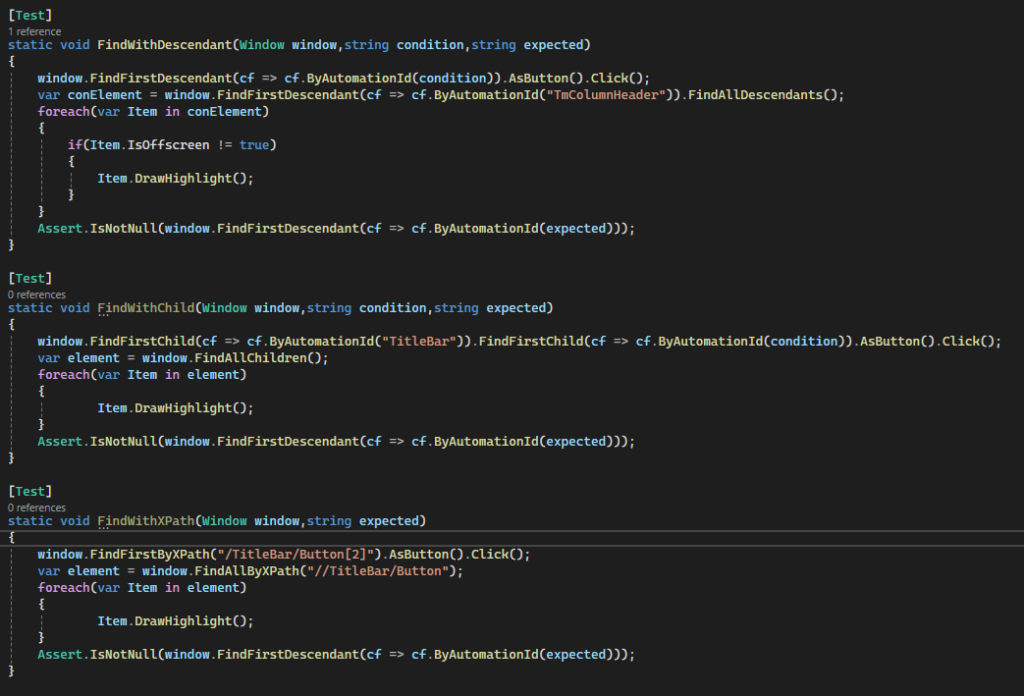
Für die erste Methode werden wir mit FindFirstDescendant und FindAllDescendant arbeiten. FindAllDescendant sucht sich alle Elemente, die unterhalb des Ausgangselements liegen. FindFirstDescendant findet das erste Element unterhalb des Ausgangselements, das mit der übergebenen Suchbedingung übereinstimmt und mit DrawHighlight wird ein roter Rahmen um das Element gelegt.
In der zweiten Methode nutzen wir FindFirstChild und FindAllChildren. Beide funktionieren fast gleich wie Descendant, nur dass hier nicht alle Elemente gefunden werden, sondern nur die, die direkt unter dem Ausgangselement liegen.
static void FindWithChild(Window window, string condition, string expected)
{
window.FindFirstChild(cf => cf.ByAutomationId("TitleBar")).FindFirstChild(cf =>
cf.ByAutomationId(condition)).AsButton().Click();
var element = window.FindAllChildren();
foreach(var Item in element)
{
Item.DrawHighlight();
}
Assert.IsNotNull(window.FindFirstDescendant(cf => cf.ByAutomationId(expected)));
}
Und für die dritte Methode nehmen wir FindFirstByXPath und FindAllByXPath. Hier müssen wir, wie der Name sagt, den Pfad angeben. Bei First sollte es der genaue Pfad zum gewünschten Element sein und bei FindAll werden alle Elemente gesucht, die in dem Pfad gefunden werden können. Solltet ihr ein Programm untersuchen, welches ihr nicht kennt, hilft es, FlaUI Inspect zu nutzen, welches Eigenschafen wie den Pfad anzeigen, aber auch andere Informationen über Elemente von Windows-Apps darstellen kann.
static void FindWithXPath(Window window, string expected)
{
window.FindFirstByXPath("/TitleBar/Button[2]").AsButton().Click();
var element = window.FindAllByXPath("//TitleBar/Button");
foreach(var Item in element)
{
Item.DrawHighlight();
}
Assert.IsNotNull(window.FindFirstDescendant(cf => cf.ByAutomationId(expected)));
}
Als letztes müssen wir nur noch die Methoden aufrufen und ihnen die gewünschten Werte übergeben. Zum einen das Fenster was wir uns am Anfang angelegt haben und zum anderen die AutomationID des Maximieren-Buttons, welche sich wie erwähnt ändert, sobald der Button betätigt wurde.
Ein Problem sind selbst gebaute Objekte z.B. hatten wir in einem Projekt mit selbsterstellten Polygonen Buttons angelegt. Diese konnten weder von FlaUI Inspect noch von FlaUI selbst gefunden werden, was die Nutzung dieser in unseren Autotests stark eingeschränkt hat. Für solche Objekte muss ein AutomationPeer (stellt Basisklasse bereit, die das Objekt für die UI-Automatisierung nutzbar macht) angelegt werden, damit diese gefunden werden können.
Fazit und Zusammenfassung
FlaUI unterstützt mit UIA2 Forms und Win 32 Anwendungen sowie mit UIA3 WPF und Windows Store Apps. Es ist einfach zu bedienen und übersichtlich, da es mit relativ wenig Grundfunktionen auskommt. Außerdem kann es jederzeit mit eigenen Methoden und Objekten erweitert werden.
Auch die Software-Entwickler:innen sind zufrieden, da sie keine extra Schnittstellen und damit keine potenziellen Fehlerquellen für die Testautomatisierung einbauen müssen. Gerade weil FlaUI uns die Möglichkeit gibt, direkt die Objekte des zu testenden Programmes abgreifen zu können, brauchen wir keine zusätzliche Arbeitszeit darauf zu verwenden, für das Testing größere und fehleranfällige Anpassungen an der bestehenden Programmstruktur vorzusehen und zu verwalten.
Andererseits muss man um jedes Objekt automatisiert ansprechen zu können, seine AutomationID im Testcode mindestens einmal hinterlegen, damit sie für den Test auch nutzbar ist. Dies bedeutet, dass man praktisch die ungefähre Struktur des zu testenden Programmes nachbilden muss, was gerade bei komplexeren Programmen aufwändig sein kann. Und um dabei die Übersichtlichkeit zu erhalten, sollte man diese geclustert in mehreren, namentlich Aussagekräftigen, Klassen hinterlegen.
Wir werden es auf alle Fälle weiterverwenden und auch unseren Kolleg:innen empfehlen.
Wir kennen die Situation sicherlich von schlecht geführten Restaurants. Am Tisch bekommen alle ihr Essen zu unterschiedlichen Zeiten, das Schnitzel ist wie eine Schuhsohle oder wir bekommen gar etwas, was wir gar nicht bestellt haben. Der Koch/die Köchin in der Küche ist völlig überfordert und kommt mit der Flut der Bestellungen und ständigen Änderungen am Rezept nicht zurecht.
Auch beim Softwaretest gibt es ähnliche Situationen. Dabei betrachten wir den Koch/die Köchin hier mal als Tester/in, der ein neues Rezept testet. Das heißt, das neue Rezept ist unser Testobjekt, welches vom Koch/Köchin, durch kochen überprüft wird. Das Testteam kommt mit der Flut an Änderungen nicht hinterher. Tests werden unnötig doppelt ausgeführt, andere werden vergessen oder übersehen. Fehler werden nicht entdeckt und können so in die Produktion gelangen. Das Chaos ist perfekt und die Qualität stimmt nicht. Doch was tun wir in so einem Fall? Den Koch/die Köchin antreiben, das Chaos automatisieren oder einfach mehr Tester/innen einsetzen? Nein! Denn was würde dann passieren?
Personal antreiben?
Da der Koch/die Köchin so schon durch das Chaos am Kollabieren ist, wird das Antreiben höchsten zu einer kurzzeitigen Verbesserung mit anschließendem K.O. führen. Damit erhalten wir also keine langfristige Optimierung der Situation.
Da wir erstmal einen Mehraufwand für die Automatisierung benötigen und in dem Chaos gar nicht klar ist, wo wir hier anfangen sollen, würde dies nur zu noch mehr Chaos und Überlastung in der Küche führen. Das ergibt somit eine noch schlechtere Qualität.
Einfach mehr Personal einsetzen?
Jeder kennt den Spruch „viele Köche verderben den Brei“. Wenn wir also einfach dem Koch/der Köchin noch weitere Hilfsköche/innen zur Seite stellen, heißt das nicht zwangsläufig damit sei alles gelöst. Hier ist nicht zu unterschätzen, dass das neue Personal erstmal eingearbeitet werden muss. Was wiederum zu Verzögerungen in den Arbeitsabläufen führen kann. Dies muss auf jeden Fall sorgfältig geplant werden, sonst führt dies zu noch mehr Chaos in der Küche.
Also was können wir tun?
Erstmal müssen wir analysieren, wieso es Chaos in der Küche gibt und welche Ursachen zu Grunde liegen. Oft stellt sich dann heraus, dass es an Stellen klemmt, an die zuvor gar nicht gedacht wurde. Zum Beispiel, dass der Kellner/die Kellnerin die Bestellungen nur unleserlich auf einen Zettel schreibt und nicht ersichtlich ist, was für welchen Tisch bestellt wurde. Das heißt, der Koch/die Köchin (Tester/in) muss ständig nachfragen. In diesem Vergleich betrachten wir den Kellner/Kellnerin als Analyst/in und die Bestellung, die der Kellner/die Kellnerin aufnimmt, als Teil-Anforderung. So können auch im Test (in der Küche) die Probleme bereits bei den aufgenommenen Anforderungen liegen und der Tester/die Testerin muss ständig nachfragen, wie die Anforderung gemeint ist.
Genauso könnte es sein, dass der Koch/die Köchin immer erst die Zutaten zusammensucht und mit den Vorbereitungen beginnt, wenn die Bestellung bereits da ist, also der Testende die Testfälle erst dann erstellt, wenn er das fertige Produkt vorliegen hat.
Wichtig ist auch, dass die Kommunikation in der Küche stimmt. Aber nicht nur in der Küche auch mit dem Kellner/der Kellnerin, dem Gast und dem Erstellenden des Rezeptes muss die Kommunikation stimmen. Das heißt im Test, dass die Kommunikation nicht nur im Testteam stimmen muss, sondern eben auch mit dem Analyst/Analystin, dem Product-Owner und dem Entwickler/Entwicklerin.
Ein weiteres Problem könnte darin bestehen, dass der Abstand zwischen Herd und Spüle zu weit ist. Für unsere Tester/innen übersetzt heißt das, dass sein Testwerkzeug einfach zu langsam ist und zur Testfallerstellung oder Testdurchführung zu viel Zeit benötigt wird.
Als Fazit muss also der Arbeitsprozess genauer unter die Lupe genommen werden:
Ausgangslage
Kommunikation
Arbeitsschritte
Verwendete Werkzeuge
Dokumentation
etc.
Anhand der Analyse können Schwachstellen identifiziert und entsprechende Maßnahmen ergriffen werden. Kurz um, diese Analyse mit entsprechenden Maßnahmen muss ein regelmäßiger Prozess werden. Richtig: ich spreche von einer regelmäßigen Retrospektive. Wichtig ist auch, dass in solch einer Retrospektive nicht nur die Probleme identifiziert werden, sondern auch Actionitems definiert werden, die dann umgesetzt und in der nächsten Retrospektive überprüft werden. Wenn nur analysiert wird, wo die Probleme liegen und keine Maßnahmen ergriffen werden, dann ändert sich auch nichts.
Auch in Hinsicht der Testautomatisierung ist es wichtig, dass die Arbeitsprozesse optimiert sind, sonst bringt auch diese keinen Erfolg. Also ohne Öl wird das Schnitzel schwarz – ob automatisiert oder nicht.
Es gibt leider kein Patentrezept, welches in jedem Projekt funktioniert. Es gibt jedoch einige Best Practices aus denen sich jeder für sein Projekt entsprechende Anregungen zur Verbesserung holen kann. Für den ersten Einstieg in den regelmäßigen Verbesserungsprozess können Sie sich gern von uns beraten lassen und die ersten Retrospektiven mit einem/einer erfahrenen Berater/Beraterin aus unserem Hause gemeinsam durchführen.
Lesen Sie auch meine anderen Artikel zum Thema Testautomatisierung:
Im ersten Teil der Blogserie haben wir die Herausforderungen bei der Wahl des geeigneten Werkzeugs für die Testautomatisierung skizziert. Im zweiten Teil ging es um die Relevanz und eine mögliche Klassifizierung von Auswahlkriterien der Werkzeuge, die sich zum Teil standardisieren lassen, aber fallweise auch variabel sein müssen. In diesem dritten Artikel stellen wir die Liste der Kriterien, den Kriterienkatalog, dessen Verprobung und die Ergebnisse daraus vor.
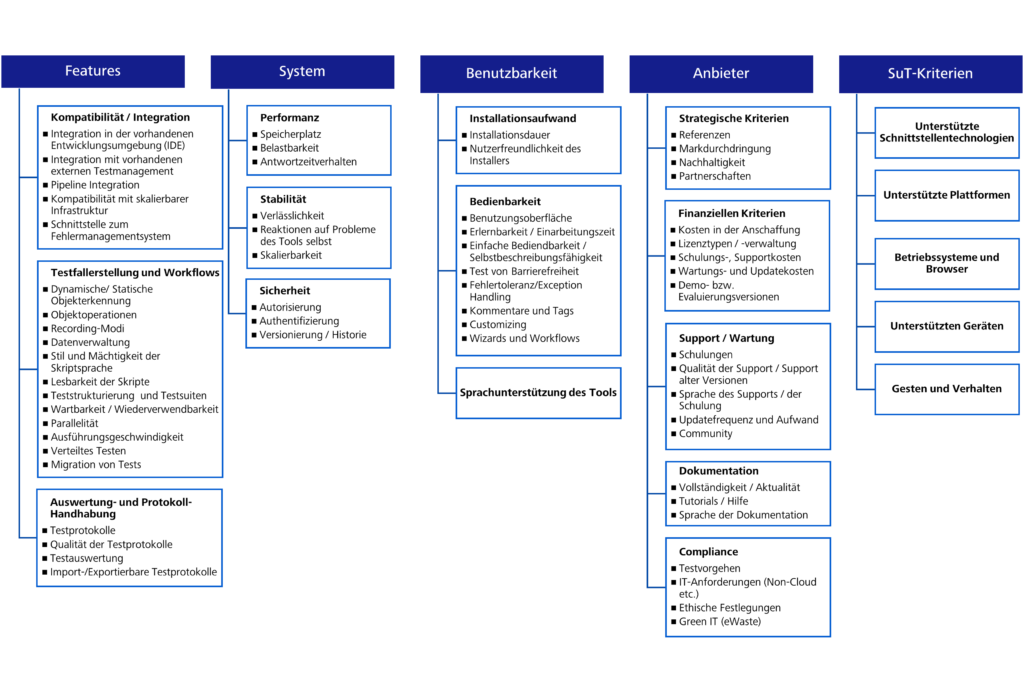
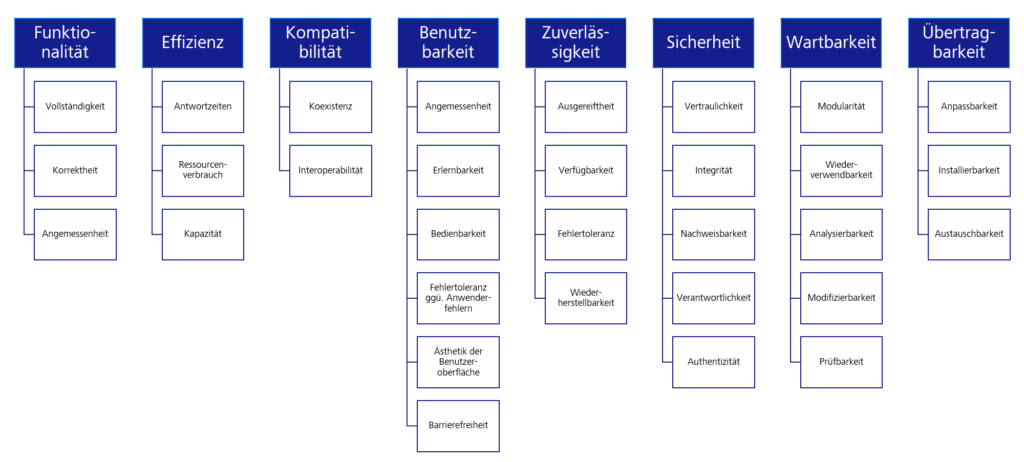
Die folgende Abbildung stellt die finale Liste der Auswahlkriterien dar. Dabei wurden die variablen Kriterien als „SuT-Kriterien“ gekennzeichnet. Die ermittelten Kriterien können angepasst, erweitert und aktualisiert werden.
Abbildung 1: Liste der Kriterien
Die Standardkriterien sind in vierzehn (14) Oberkriterien unterteilt, wie z.B. in Kompatibilität, Bedienbarkeit, Performance oder Dokumentation. Den Oberkriterien sind Unterkriterien zugeordnet. So hat das Oberkriterium Dokumentation beispielweise drei (3) Unterkriterien.
Kriterienkatalog
Nachdem die Kriterien feststanden, erstellten wir im nächsten Schritt den eigentlichen Kriterienkatalog. Da verschiedene, mehrdimensionale Ziele in die Entscheidungen einfließen, eignete sich dafür ein systematischer Ansatz. Er lässt eine multi-kriteriale Entscheidungsanalyse (auch Multi Criteria Decision Analysis oder MCDA genannt) zu. Eine dieser Anwendungsformen der multi-kriterialen Entscheidungsanalyse ist die sogenannte Nutzwertanalyse (Gansen 2020, S. 5). Die Nutzwertanalyse findet überall dort Anwendung, wo eine Bewertung vorgenommen oder eine Beurteilung getroffen wird, z. B. im Projektmanagement, im Controlling.
Abbildung 2: Beispieltabelle Nutzwertanalyse
Anforderungen an den Kriterienkatalog
Für die eigentliche Anfertigung des Kriterienkatalogs definierten wir zunächst die Anforderungen. Sie sind im Folgenden tabellarisch in Form von User Stories zusammengefasst und stellen alle notwendigen Arbeitsschritte dar.
Nr.
User Stories
1
Als Benutzer möchte ich die Projektstammdaten eingeben, damit ich besser nachvollziehen kann, von wem, wann und für welches Projekt der Katalog erstellt wurde.
2
Als Benutzer möchte ich einen neuen Katalog erstellen, um eine neue Nutzwertanalyse durchführen zu können.
3
Als Benutzer möchte ich eine Nutzwertanalyse durchführen, um eine objektive Entscheidung treffen zu können
4
Als Benutzer möchte ich die Kriterien gerecht und leicht gewichten, um die Relevanz für das Projekt besser steuern zu können.
5
Als Benutzer möchte ich einen Überblick über die Bewertungsgrundlage haben, um die Lösungsalternativen besser bewerten zu können.
6
Als Benutzer möchte ich einen klaren Überblick über die durchgeführte Nutzwertanalyse haben, damit ich schnell das Werkzeug mit dem höchsten Nutzen finden kann.
7
Als Benutzer möchte ich die zuletzt bearbeitete Nutzwertanalyse aufrufen, um sie weiter bearbeiten zu können.
8
Als Benutzer möchte ich den Katalog exportieren, damit ich diesen weiterleiten kann.
Tabelle 1: Anforderungen an den Kriterienkatalog
Aufbau des Kriterienkatalogs
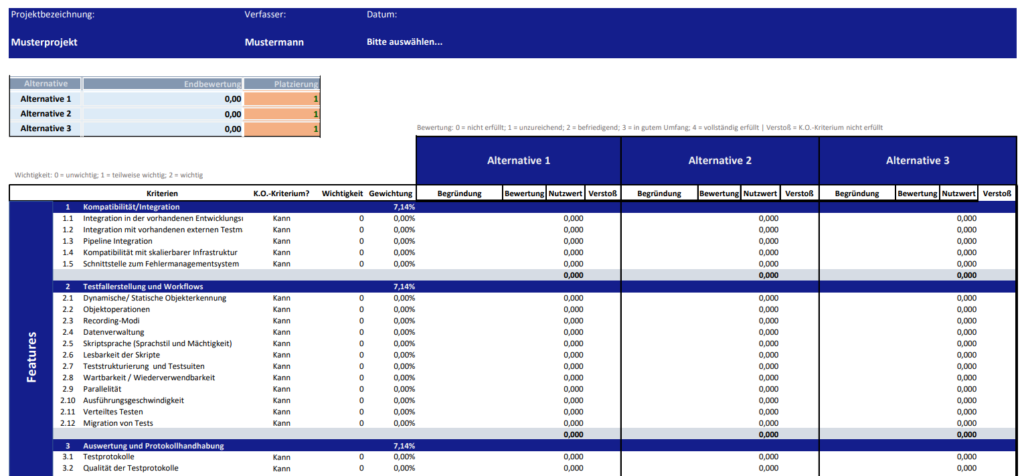
Der Kriterienkatalog wurde mit Excel, sowie Visual Basic for Applications (VBA) entwickelt. Das entwickelte Tool wurde in verschiedene Arbeitsmappen unterteilt, die jeweils eine spezifische Aufgabe widerspiegeln.
Die Einstiegsmaske
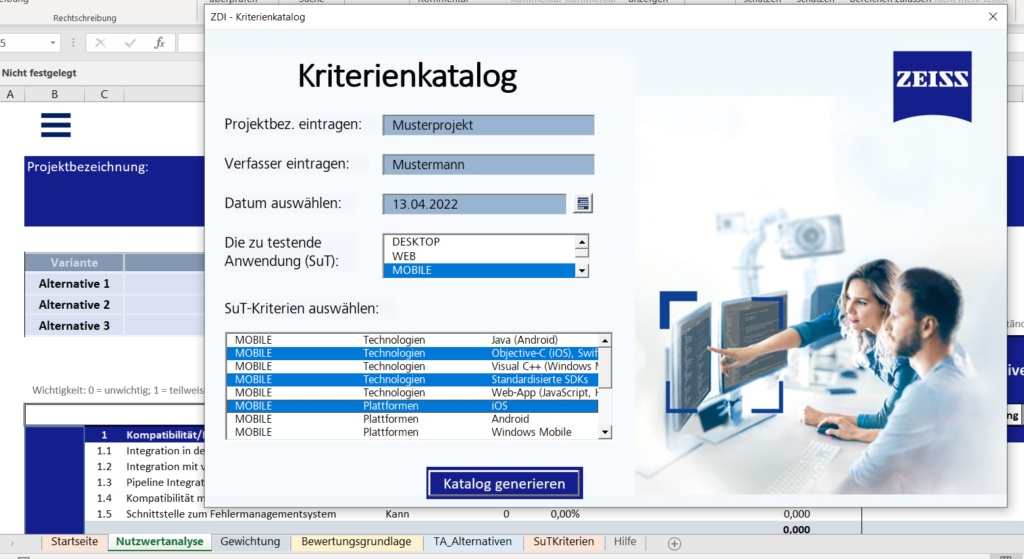
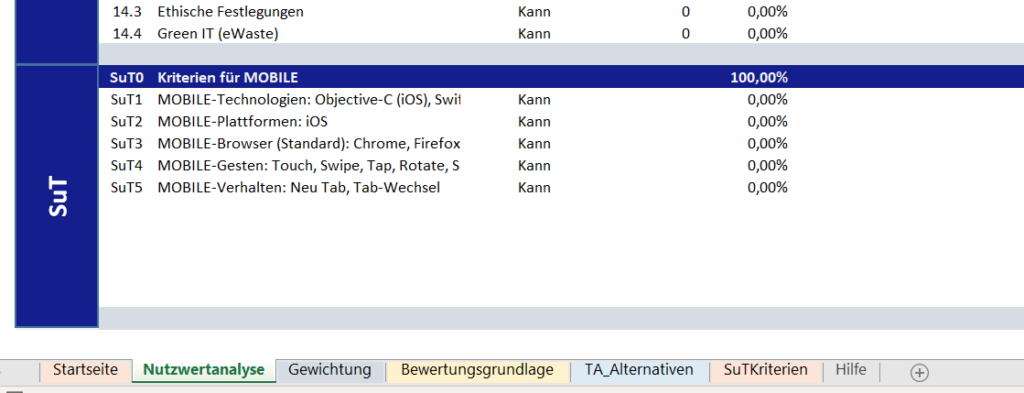
Beim Öffnen der Datei erscheint ein Dialogfenster (siehe Abbildung 3). Zunächst ist auszuwählen, ob der zuletzt bearbeitete Katalog aufgerufen oder ein neuer Katalog erstellt werden soll. Im Falle eines neuen Katalogs wird dann ein Formular angezeigt, das vom Benutzer ausgefüllt werden muss. Die Eingaben des Benutzers zu den SuT-Kriterien werden dem Katalog als variableKriterien hinzugefügt (siehe Abbildung 4).
Abbildung 3: Einstiegsmaske des Kriterienkatalogs
Abbildung 4: Angaben der SuT-Kriterien im Katalog
Die Nutzwertanalyse
Die Nutzwertanalyse wird in vier Schritten durchgeführt. Nach der Identifizierung der Kriterien folgt deren Gewichtung. Danach wird die Kriterienerfüllung gemessen und schließlich der Nutzwert jeder Alternative berechnet (Gansen 2020, S. 6). Sind die Bewertungskriterien sachgerecht beurteilt, kann mit Hilfe der Nutzwertanalyse eine objektive, rationale Entscheidung getroffen werden (Kühnapfel 2014, S. 4).
Gewichtung der Kriterien
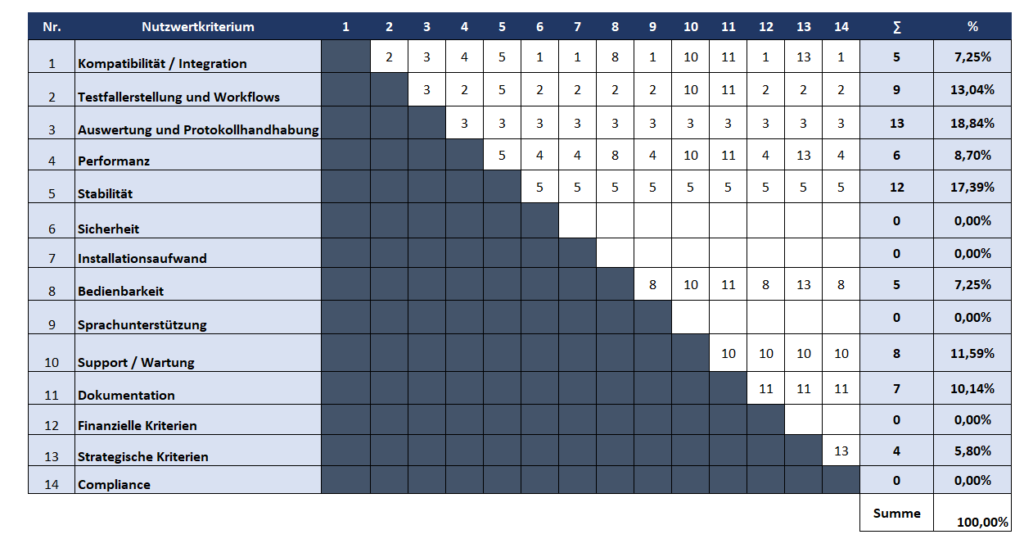
Nachdem die Kriterien, insbesondere die variablen Kriterien, ausgearbeitet worden sind, ist eine Gewichtung dieser Kriterien vorzunehmen. Entscheidend ist es, die Kriterien entsprechend ihrer Bedeutung für das spezielle Testautomatisierungsprojekt so zu gewichten, damit sie optimal zur Erreichung der Ziele des Projekts beitragen. Die Summe der Gewichtungen von Standardkriterien und variablen Kriterien soll jeweils 100% ergeben. Bei den Standardkriterien werden zuerst die Oberkriterien mit Hilfe der Paarvergleichsmethode gewichtet, in Form einer Matrix zusammengestellt und paarweise miteinander verglichen (Wartzack 2021, S. 315).
Abbildung 5: Paarweiser Vergleich der Oberkriterien für ein Beispielprojekts
Die vergebenen Punkte werden addiert und mit der entsprechenden Gewichtung des Oberkriteriums multipliziert. Daraus ergibt sich eine proportionale Gewichtung aller Standardkriterien. Entsprechend wird mit den anderen Ober- bzw. Unterkriterien verfahren. Am Ende beträgt die Summe aller Gewichtungen der Standardkriterien am Ende 100%.
Messung der Kriterienerfüllung
Ausgangspunkt ist die Beantwortung der Frage: „In welchem Maße ist das Kriterium bei der zu bewertenden Testautomatisierungswerkzeugen erfüllt?“. Für den Kriterienerfüllungsgrad wird ein 5-stufiges Modell verwendet, dargestellt in Tabelle 2 (Gansen 2020, S. 17).
0
Nicht erfüllt.
1
Ist unzureichend / kaum erfüllt.
2
Ist teilweise erfüllt.
3
Ist in gutem Umfang erfüllt.
4
Ist in sehr gutem Umfang erfüllt / vollständig erfüllt.
Tabelle 2: Bewertungsschema der Kriterienerfüllung
Wird die Note 4 vergeben, erfüllt das Tool ein Kriterium vollständig. Im Falle der Nichterfüllung wird die Note 0 vergeben. Auf diese Weise werden die entsprechenden Eigenschaften eines Testautomatisierungswerkzeugs zu einer messbaren Größe.
Aggregation der Bewertungen
Liegt der Erfüllungsgrad jedes Kriteriums vor, kann der Nutzwert berechnet werden. Für den Nutzwert gilt folgende Formel:
N i = Nutzwerte der Alternative i
Gj = Gewichtung des Kriterium j
nij = Teilnutzen der Alternative i in Bezug auf das Kriteriums j
Die Teilnutzen werden aufsummiert. Das Ergebnis stellt den tatsächlichen Wert eines Werkzeugs dar. Anhand der ermittelten Nutzwerte lässt sich schließlich eine Rangfolge der betrachteten Alternativen aufstellen und für die Entscheidungsfindung nutzen (Gansen 2020, S. 6). Es lässt sich die Werkzeuglösung wählen, die alle Anforderungen am besten erfüllt und die den größten Nutzwert aufweist.
Es gibt Kriterien, die sich als notwendig herausstellen. Diese werden als Ausschlusskriterien (K.O.-Kriterien) bezeichnet. Wenn ein Ausschlusskriterium (K.O.-Kriterium) nicht erfüllt ist (0), liegt ein Verstoß vor, der zum sofortigen Ausschluss einer Alternativlösung führt.
Abbildung 6: Bewertung und Auswahl
Navigationsleiste und Export
Die Navigationsleiste gibt dem Benutzer einen Überblick über die Struktur des Katalogs und ermöglicht es, sich mühelose darin zu bewegen.
Abbildung 7: Navigationsleiste des Kriterienkatalogs
Der Katalog kann als PDF- oder Excel-Datei exportiert und der Speicherort dafür frei gewählt werden.
Abbildung 8: Ausschnitt der leeren Vorlage des Kriterienkatalogs
Ergebnisse der Verprobung des Kriterienkatalogs
Aus der Verprobung konnten folgende relevante Erkenntnisse gewonnen werden:
Das Zielmodell zur Identifizierung der variablen Kriterien war hilfreich, um gemeinsam Ideen für die SuT-Kriterien zu sammeln.
Die Anwendung des paarweisen Vergleichs schaffte Klarheit über die wichtigen Faktoren bzw. Oberkriterien. Dank der Darstellung wurde die Vergleichbarkeit hergestellt. So konnten „Bauchentscheidungen“ deutlich reduziert werden.
Der Kriterienkatalog zeigte einen systematischen, verständlichen und nachvollziehbaren Weg auf, um sich ein geeignetes Werkzeug empfehlen zu lassen. Außerdem konnte festgestellt werden, wo die Stärken des empfohlenen Testautomatisierungsframeworks liegen. So wurde die Abdeckung der Auswahlkriterien mit höherer Relevanz durch das Framework überprüft. Das verringert den Bedarf an Diskussionen innerhalb des Teams, die die endgültige Entscheidung herauszögern würden.
Aufgrund des für die Bewertung verwendeten 5-Stufen-Modells war ein sehr detailliertes Know-how über Testautomatisierungswerkzeuge erforderlich, das in den meisten Fällen nicht vorhanden ist. Daher würden die Mitarbeiterinnen und Mitarbeiter einige Kriterien nach ihrem Empfinden bzw. Gefühl bewerten. Folglich wären die Bewertungen teilweise subjektiv und die gewählte Alternative letztlich nicht die optimale. Um in diesem Fall ein zuverlässigeres Ergebnis zu erhalten, sollte mindestens eine weitere Person mit Testexpertise zu der Bewertung hinzugezogen werden.
Fazit & Ausblick
In der vorliegenden Arbeit wurde ein strukturierter und systematischer Ansatz für den Auswahlprozess untersucht. Anhand dessen kann ein geeignetes GUI-Testautomatisierungswerkzeug ausgewählt werden, das sowohl den Projekt- als auch den Unternehmensanforderungen genügt. Dabei wurde ein entsprechender Kriterienkatalog entwickelt, der vor allem als Basis für die Transparenz und Nachvollziehbarkeit der Entscheidungsfindung dient.
Es ist geplant, den Kriterienkatalog in weiteren Projekten einzusetzen. Die dabei gesammelten Erfahrungen sollen in die nächste Version 2.0 des Kriterienkatalogs einfließen.
Dieser Beitrag wurde fachlich unterstützt von:
Kay Grebenstein
Kay Grebenstein arbeitet als Tester und agiler QA-Coach für die ZEISS Digital Innovation, Dresden. Er hat in den letzten Jahren in Projekten unterschiedlicher fachlicher Domänen (Telekommunikation, Industrie, Versandhandel, Energie, …) Qualität gesichert und Software getestet. Seine Erfahrungen teilt er auf Konferenzen, Meetups und in Veröffentlichungen unterschiedlicher Art.
Im ersten Artikel wurden die grundsätzlichen Herausforderungen und Einflussfaktoren bei der Auswahl von Testautomatisierungswerkzeugen, als Ergebnis aus verschiedenen Interviews, vorgestellt. Es wurde aufgezeigt, dass es bereits erste Ansätze von Checklisten, aber noch keine einheitliche Methode zur Auswahl von Testautomatisierungswerkzeugen gibt. Die Aufgabe der Abschlussarbeit war es daher, einen einfachen, zielführenden Ansatz zu finden, der die Suche nach geeigneten Testautomatisierungs-werkzeugen je nach Projekteinsatz anhand eines Kriterienkatalogs unterstützt.
Grundvoraussetzung für die Entwicklung eines Kriterienkataloges ist die Beantwortung der Frage, welche Kriterien bei der Auswahl eines Werkzeugs überhaupt relevant sind. Darauf gehe ich im zweiten Teil der Blogserie ein.
Relevanz der Auswahlkriterien
Die Frage nach geeigneten Kriterien zur Bestimmung der Qualität von Softwareprodukten und, daraus abgeleitet, von Testautomatisierungswerkzeugen wird in der Literatur ausführlich diskutiert. Die für den Kriterienkatalog ermittelten Kriterien wurden größtenteils auf der Basis von Literaturrecherchen entwickelt. Die verwendeten Literaturquellen stelle ich nachfolgend kurz vor:
Die Auflistung der Softwarequalitätsmerkmale ISO 25010 bietet eine hilfreiche Checkliste, um eine Entscheidung für oder gegen den Test jedes Kriteriums zu treffen. Vergleichbare Auflistungen von Qualitätsmerkmalen finden sich auch an anderer Stelle (Spillner/Linz 2019, S. 27). Die Autoren geben jeweils Hinweise, anhand derer für ein Projekt die Erfüllung der einzelnen Qualitätseigenschaften bestimmt werden kann. Im Bereich der Testautomatisierung finden sich Listen von Kriterien zum Beispiel in Baumgartner et al. 2021, Lemke/Röttger 2021, Knott, 2016. Diese Kriterien beziehen sich unter anderem auf die unterstützten Technologien, die Möglichkeiten der Testfallbeschreibung und Modularisierung, die Zielgruppe, die Integration in die Werkzeuglandschaft und die Kosten. Das Ziel ist hier jedoch lediglich das Identifizieren von relevanten Kriterien, nicht aber deren Bewertung. Zum anderen ergaben sich zusätzliche Kriterien aus den Experteninterviews und der Analyse der Projekte der ZDI.
Die in dieser Arbeit identifizierten Auswahlkriterien kombinieren daher Erkenntnisse und Erfahrungen aus bestehenden Schriften zu den Themen Qualität, Testautomatisierung sowie Erstellung und Prüfung von Anforderungen an Testautomatisierungswerkzeuge zu einem praktisch anwendbaren Ansatz.
Abbildung 1: Quellen des Kriterienkatalogs
Klassifizierung der Kriterien
Bei der Auswahl von Testautomatisierungswerkzeugen wurden Einflussfaktoren wie Erfahrung, Kosten oder Interessengruppen genannt. Die Kosten waren für viele der Schlüsselfaktor. Im Rahmen dieser Arbeit wurde erkannt, dass Kriterien wie Integration oder Compliance zwar je nach Rolle unterschiedlich ausgeprägt sind, aber in der Liste der Kriterien mehr oder weniger Standard sind. Und sie sind unveränderbar, unabhängig davon, welche Anwendung getestet wird. Es gibt jedoch einen kleinen Anteil von Kriterien, der je nach der zu testenden Anwendung variiert. Ein Szenario, um die Problemstellung zu veranschaulichen: In der Medizintechnikbranche wird eine neue, webbasierte Anwendung entwickelt – das Frontend mit Angular 8 und NodeJS und das Backend mit Java Microservices. Das auszuwählende Testautomatisierungswerkzeug muss primär zu den Rahmenbedingungen passen, die durch die zu testende Webanwendung vorgegeben sind. Bevor ein Automatisierungswerkzeug zum Einsatz kommen kann, müssen die Schnittstellentechnologien der Anwendung überprüft werden. In der Praxis verfügen Testautomatisierungswerkzeuge über spezifische Eigenschaften und werden daher für unterschiedliche Technologien verwendet. Einige sind eher auf Web-Tests spezialisiert, während andere mehr im Bereich der Desktop-Tests angesiedelt sind. Ob Webanwendung oder mobile Anwendung – es bestehen immer also auch bestimmte Erwartungen an das Testautomatisierungswerkzeug. Daher ist der kritischste Faktor das Testobjekt bzw. das System under Test (SuT). Es bildet die Basis, auf der die Werkzeugauswahl getroffen wird (Baumgartner et al. 2021, S. 45). Zusammenfassend lassen sich die Kriterien in zwei Arten unterteilen: in den Standard- und in den variablen Anteil.
Abbildung 2: Die zwei Arten von Kriterien
Die Standardkriterien hängen nicht von dem Testobjekt ab. In Anlehnung an die Qualitätskriterien wurden diese Kriterien in vier Kategorien gruppiert: Features, System, Benutzbarkeit und anbieterbezogene Kriterien. Im Unterschied dazu hängen die variablen Kriterien von dem zu testenden System ab. Zu den variablen Kriterien gehören beispielsweise die unterstützten Applikationstypen, Betriebssysteme, Schnittstellentechnologien, Browser und Geräte.
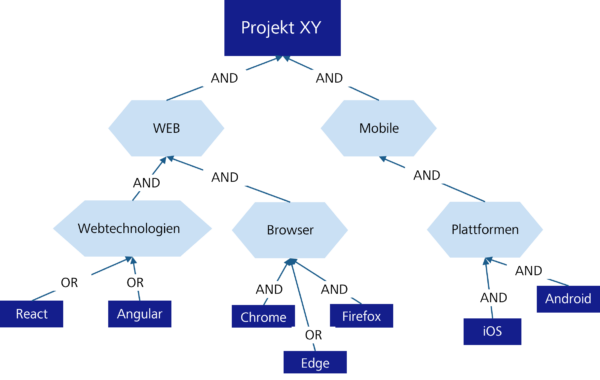
Strategie der Variablenauswahl
Variablenauswahl bedeutet, aus einer Anzahl von Variablen diejenigen auszuwählen, die in die Liste der Kriterien aufgenommen werden sollen. Zur Unterstützung der Auswahl variabler Kriterien wurde im Rahmen meiner Arbeit ein Zielmodell mit eine AND/OR-Zerlegung auf der Grundlage von GORE (Goal Oriented Requirements Engineering) und den Arbeiten von Lapouchnian (2005) und Liaskos et al. (2010) eingeführt. Es hatte sich als wirksam erwiesen, Alternativen oder Variabilitäten genau zu erfassen (Mylopoulos/Yu 1994, S. 159-168), um alternative Designs während des Analyseprozesses zu evaluieren (Mylopoulos et al. 2001, S. 92-96). Die Ziele und Anforderungen werden über AND/OR-Zerlegungen verknüpft. Durch die AND-Zerlegung wird ausgedrückt, dass die Erfüllung der jeweiligen notwendig ist. Bei einer OR-Verknüpfung bedeutet dies, dass ist die Erfüllung eines dieser Ziele oder Anforderungen ausreichend. Dadurch werden die ersten Erwartungen an das Werkzeug explizit formuliert und irrelevante Anforderungen vermieden.
Abbildung 3: Vereinfachtes Zielmodell für ein Beispielprojekt XY
Vorgehensweise bei der Werkzeugauswahl
Ausgehend von den identifizierten Kriterienarten und Spillner et al. (2011) wird in dieser Arbeit eine strukturierte Vorgehensweise für die Auswahl des passenden Testautomatisierungswerkzeugs entworfen. Die neue Vorgehensweise gliedert sich in fünf Schritte:
Erarbeitung der Projektanforderungen
Identifikation der variablen Kriterien mit Hilfe des AND/OR-Zielmodells
Gewichtung der Kategorien und Kriterien
Evaluierung der verschiedenen Werkzeuglösungen
Bewertung und Auswahl
Der nächste Blogartikel geht darauf ein, wie der Kriterienkatalog nach der beschriebenen Vorgehensweise aufgebaut wurde. Außerdem werden wir zeigen, wie die variablen Kriterien in den Katalog aufgenommen wurden, und die Ergebnisse der Verprobung des Kriterienkatalogs vorstellen.
Dieser Beitrag wurde fachlich unterstützt von:
Kay Grebenstein
Kay Grebenstein arbeitet als Tester und agiler QA-Coach für die ZEISS Digital Innovation, Dresden. Er hat in den letzten Jahren in Projekten unterschiedlicher fachlicher Domänen (Telekommunikation, Industrie, Versandhandel, Energie, …) Qualität gesichert und Software getestet. Seine Erfahrungen teilt er auf Konferenzen, Meetups und in Veröffentlichungen unterschiedlicher Art.
Der König ist tot, es lebe der König! Aber welcher? Nachdem das Team von Angular im April angekündigt hat, die Entwicklung seines e2e-Testing-Frameworks Protractor Ende 2022 einzustellen, stellt sich für viele Entwicklerinnen und Entwickler nun die Frage, wie es weiter geht. Welches Tool zur Testautomatisierung sollte man verwenden? Der Markt hält hierfür zahlreiche Alternativen bereit, von denen einige in diesem Beitrag beleuchtet werden sollen.
Die Testkandidaten
Cypress
Bei Cypress handelt es sich wohl um den bekanntesten Kandidaten im Testfeld. Laut einer Umfrage in der Angular Community vom Januar 2021 handelt es sich mit über 60% der Stimmen um das am weitesten verbreitete Tool für automatisierte UI-Tests. Das erste Stable-Release erschien bereits 2017, gegenwärtig befindet sich die Anwendung in Version 10. Cypress beschreibt sich selbst als schnell, einfach und verlässlich und setzt dabei auf ein eigenes Ökosystem an Tools, das im Gegensatz zu Protractor unabhängig von Selenium und WebDriver ist. Unterstützt werden derzeit Chrome, Firefox und Edge, jedoch (noch) nicht Safari. Die Möglichkeit, die Tests gegen verschiedene Browser-Versionen auszuführen, kann durch die Anbindung von BrowserStack oder durch das Austauschen der Binaries für die lokale Ausführung erreicht werden.
Pro
Contra
+ schnell + stabil + große Community + umfangreiche, verständliche Dokumentation
– Noch kein Support für Safari
Tabelle 1: Vor- und Nachteile des Tools Cypress
Playwright
Das seit 2020 von Microsoft entwickelte Playwright stellt den jüngsten Kandidaten im Feld der Automatisierungstools dar. Laut eigener Beschreibung soll die Bibliothek aktuell, schnell, zuverlässig und leistungsfähig sein, um gängige Probleme des UI-Testens wie Flakiness und langsame Ausführungsgeschwindigkeiten zu beseitigen. Mit dieser Zielsetzung im Hintergrund verwundert es nicht, dass Playwright im Gegensatz zu den anderen Testing-Tools nicht auf Selenium Webdriver aufsetzt, sondern über eine eigene Implementierung zur Browser-Steuerung verfügt. Unterstützt werden dabei die aktuellen Browser Engines von Chromium, Firefox und WebKit, jeweils auf Windows, Linux und MacOS. Ältere Versionen können unter Verwendung älterer Playwright-Versionen eingebunden werden, seit Kurzem können auch generische Chromium-Builds (Edge und Chrome) verwendet werden. Support für Mobilgeräte ist aktuell nur per Emulation bestimmter Gerätekonfigurationen wie Auflösung und User-Agent möglich, ein Testen auf echten Geräten ist derzeit nicht möglich.
Das Feature Set umfasst neben Standardoperationen auch Funktionen, die in anderen Frameworks fehlen oder nur per Workaround realisiert werden können. So stehen neben Clicks, Scrolling, Selections usw. auch Drag-and-Drop, Interaktionen im Shadow-Dom und Synchronisierung mit Animationen zur Verfügung.
Im Hinblick auf Performance und Ausführungsgeschwindigkeit verhält sich Playwright wesentlich schneller als Protractor und andere seleniumbasierte Testframeworks. In unseren Tests konnten wir auch bei mehreren Testinstanzen im Parallelbetrieb keine Probleme in Hinblick auf Flakiness oder unerwartete Abbrüche feststellen. Abschließend lässt sich sagen, dass Microsoft mit Playwright ein modernes und auf die Anforderungen modernen UI-Testings ausgerichtetes Framework vorgelegt hat, das trotz seiner kurzen Zeit am Markt bereits viele Fürsprecher gewonnen hat und wohl auch in Zukunft noch an Bedeutung gewinnen wird.
Pro
Contra
+ schnell + stabil + großes Featureset
– Aktuell nur eingeschränkter Support für BrowserStack – Kein Support für echte Mobilgeräte
Tabelle 2: Vor- und Nachteile des Tools Playwright
Webdriver.io
Webdriver.io ist mit über sieben Jahren am Markt eines der langlebigsten Automatisierungstools im Testfeld. Die Macher beschreiben das Design ihres Testframeworks als erweiterbar, kompatibel und reich an Features, was sich bei genauer Begutachtung auch bewahrheitet:
Bei Webdriver.io handelt es sich um ein Selenium-basiertes Testframework, welches die darauf beruhende WebDriver API des W3C implementiert. Dadurch wird die Kompatibilität mit allen modernen Browsern (und IE) gewährleistet, die eine eigene Treiberimplementierung bereitstellen. Darüber hinaus wird auch das Testen von Webanwendungen auf mobilen Geräten sowie nativen Apps ermöglicht.
Im tagtäglichen Einsatz zeigen sich weitere Stärken des Frameworks: Ein großer Fundus an Hilfsmethoden und syntactic sugar macht das Formulieren von Testschritten und Erwartungen deutlich einfacher und lesbarer, als man es von Protractor gewöhnt war. Hervorzuheben sind dabei u. a. der Zugriff auf ShadowRoot-Komponenten via shadow$, die vielseitigen Einstellungsmöglichkeiten der Konfiguration (u. a. automatische Testwiederholungen im Fehlerfall) und das Warten auf erscheinende bzw. verschwindende DOM-Elemente. Sollte dennoch mal eine Funktion nicht verfügbar sein, lässt sich diese als custom command implementieren und anschließend genauso wie die mitgelieferten Funktionen verwenden.
Bei aller Lobpreisung gibt es dennoch einen Wermutstropfen: Im Vergleich zu anderen Frameworks ist die Testausführung aufgrund der Selenium-basierten Implementierung recht langsam, jedoch kann die Ausführung auch parallelisiert werden.
Pro
Contra
+ Vielseitige Kompatibilität + Ausgezeichnete Dokumentation + Zahlreiche Hilfsmethoden und syntactic sugar
– Testausführung langsamer als in andere Frameworks
Tabelle 3: Vor- und Nachteile des Tools Webdriver.io
TestCafé
Bei TestCafé handelt es sich um einen weniger verbreiteten Kandidaten im Testfeld. Die bereits erwähnte Umfrage in der Angular Community ergab einen Nutzungsanteil von unter 1%. Das erste Stable-Release erschien 2018, gegenwärtig befindet sich die Anwendung in Version 1.19. Das Versprechen eines einfachen Setups und die Unabhängigkeit von WebDriver war für uns ein Grund, etwas genauer unter die Haube zu schauen. Stattdessen verwendet TestCafé einen umgeschriebenen URL-Proxy namens Hammerhead, der Befehle mithilfe der DOM-API emuliert und JavaScript in den Browser injiziert.
Unterstützt werden derzeit alle gängigen Browser und die mobilen Versionen von Chrome und Safari. Hervorzuheben ist dabei die Möglichkeit, Tests auf echten Mobilgeräten im gleichen Netzwerk auszuführen zu können. Die Testausführung mit BrowserStack ist ebenfalls möglich. Zu erwähnen ist an dieser Stelle auch, dass zusätzlich eine dezidierte Entwicklungsumgebung (TestCafé Studio) existiert, in der es auch möglich ist, mit wenig Programmierkenntnis Testfälle zu erstellen und aufzunehmen.
Pro
Contra
+ schnell + Vielseitige Kompatibilität (auch für mobile Browser und Endgeräte) + großes Featureset
– Geringe Verbreitung – Testrecorder-Tool nur kostenpflichtig
Tabelle 4: Vor- und Nachteile des Tools TestCafe
Gegenüberstellung
Bei der Wahl eines Testframeworks ist es zunächst wichtig, die eigenen Projektanforderungen zu kennen. Hierbei können folgende Fragestellungen nützlich sein:
Welche Browser sollen unterstützt werden?
Sollen verschiedene Browserversionen getestet werden?
Ist Unterstützung für mobile Geräte erforderlich?
Können die Kernfunktionen der Anwendung mittels des Frameworks getestet werden?
Die folgende Tabelle kann bei der Orientierung der Wahl eines Testframeworks helfen.
Kriterium
Cypress
Playwright
Webdriver.io
TestCafé
Browser-Support (und Versionen)
o
+
+ +
+ +
Mobile Support
+ +
+
+ +
+ +
Funktionsumfang
+
+ +
+ +
+
Testgeschwindigkeit
+
+
o
+
Migration von Protractor
o
o
+ +
–
Zukunftssicherheit
+ +
+
+
o
Tabelle 5: Vergleich der Test-Tools nach verschiedenen Kriterien
Fazit
Die Landschaft an Testframeworks ist sehr vielseitig und es ist oft nicht einfach, die richtige Entscheidung zu treffen. Für Projekte mit beispielsweise geringen Testanforderungen, das Testen gegen wenige und ausschließlich aktuelle Browser, bei denen eine schnelle Testausführung von Vorteil ist, empfehlen wir die Verwendung von Playwright.
Handelt es sich allerdings um ein Projekt, in dem eine Migration von Protractor durchgeführt werden muss und es wichtig ist, gegen viele Browser, in unterschiedlichen Versionen und auf mobilen Endgeräten zu testen, empfehlen wir Webdriver.io.
Stefan Heinze arbeitet seit 2011 als Software-Entwickler bei der ZEISS Digital Innovation in Dresden. Derzeit beschäftigt er sich mit Angular-Anwendungen und Azure-Backend-Entwicklung im Medizinbereich. Dabei gilt ein erhöhtes Augenmerk auf die Automatisierung von Oberflächentests zur Sicherstellung der Softwarequalität.
Softwaresysteme werden durch die stetig wachsende Anzahl von Anwendungen auf unterschiedlichen Plattformen immer komplexer. Ein entscheidender Faktor für den Erfolg eines Softwareprodukts ist dessen Qualität. Daher führen immer mehr Unternehmen systematische Prüfungen und Tests möglichst auf den verschiedenen Plattformen durch, um einen vorgegebenen Qualitätsstandard sicherstellen zu können. Um trotz des höheren Testaufwands kurze Release-Zyklen einhalten zu können, wird es notwendig, die Tests zu automatisieren. Dies wiederum führt dazu, dass eine Testautomatisierungsstrategie definiert werden muss. Einer der ersten Schritte bei der Einführung einer Testautomatisierungsstrategie ist die Evaluierung von geeigneten Testautomatisierungswerkzeugen. Da jedes Projekt einzigartig ist, variieren sowohl die Anforderungen als auch die Wahl der Werkzeuge. Diese Blogreihe soll eine Hilfestellung bei der Auswahl der passenden Lösung geben.
Abbildung 1: Zur Einführung einer Testautomatisierungsstrategie gehört auch die Evaluierung geeigneter Testautomatisierungswerkzeuge
Einführung
Im Rahmen meiner Abschlussarbeit übernahm ich die Aufgabe, den Scrum-Teams der ZEISS Digital Innovation (ZDI) ein Hilfsmittel an die Hand zu geben, mit dem sie das passende Testautomatisierungswerkzeug schnell und flexibel finden können. Die Herausforderung bestand dabei darin, dass die Projekte spezifische Szenarien besitzen und die Anforderungen gegebenenfalls gesondert gewichtet werden müssen. Den Stand der Arbeit und die Ergebnisse möchte ich euch in diesem und den nächsten Blogartikeln vorstellen.
Die Softwareentwicklung ist schon seit langem ein Bereich, der sich schnell verändert. Doch während diese Entwicklungen in der Vergangenheit vor allem auf technologischer Ebene stattgefunden haben, beobachten wir derzeit größere Veränderungen im Bereich der Prozesse, der Organisation und der Werkzeuge in der Softwareentwicklung. Diese neuen Trends sind jedoch mit Herausforderungen verbunden wie z. B. Änderungen im Anforderungsmanagement, verkürzten Timelines und speziell den gestiegenen Anforderungen an die Qualität. Durch die Entwicklung bedarfsgerechter Lösungen und die Optimierung der Qualität werden heute sowohl die Effizienz als auch die Effektivität innerhalb der Softwareentwicklung gesteigert.
Zudem werden Softwaresysteme durch die stetig wachsende Anzahl von Anwendungen auf unterschiedlichen Plattformen immer komplexer. Da die Qualität ein entscheidender Faktor für den Erfolg eines Softwareprodukts ist, führen immer mehr Unternehmen systematische Prüfungen und Tests möglichst auf den verschiedenen Plattformen durch, um einen vorgegebenen Qualitätsstandard sicherzustellen. Eine Anfang 2021 durchgeführte SmartBear-Umfrage ergab, dass viele Unternehmen, unabhängig von der Branche, bereits verschiedene Arten von Tests durchführen, wobei das Testen von Webanwendungen mit 69 % an erster Stelle und das Testen von API/Webdiensten mit 61 % an zweiter Stelle steht. Das Desktop-Testing wird von 42 % der Befragten durchgeführt. Insgesamt 62 % der Befragten geben an, dass sie mobile Tests durchführen, davon 29 % für native Applikationen (Apps) (SmartBear, 2021, S. 12). Um trotz des höheren Testaufwands kurze Release-Zyklen einhalten zu können, wird es notwendig, die Tests zu automatisieren.
Als ZDI unterstützen wir unsere Kunden innerhalb und außerhalb der ZEISS Gruppe bei ihren Digitalisierungsprojekten. Zusätzlich bieten wir individuelle Testservices an. Darum gibt es bei uns eine Vielzahl von Projekten mit unterschiedlichen Technologien und unterschiedlichen Lösungen. Als kleine Auswahl sind hier Schlagwörter wie Java, .Net, JavaFX, WPF, Qt, Cloud, Angular, Embedded etc. zu nennen. Bei solchen komplexen Projekten steht die Qualitätssicherung immer im Vordergrund und die Projekte sind abhängig vom Einsatz moderner Testwerkzeuge, welche die Projektbeteiligten bei den manuellen, aber besonders bei den automatisierten Tests unterstützen. Dabei wäre ein Werkzeug wünschenswert, das diese Automatisierung effektiv und effizient unterstützt. Testerinnen und Tester stehen jedoch bei der Auswahl eines Testautomatisierungswerkzeugs vor einer Vielzahl von Herausforderungen.
Herausforderungen
Bei der Recherche und den Interviews im Rahmen meiner Arbeit wurden als größte Herausforderungen bei der Testautomatisierung die Vielfalt der verfügbaren Testwerkzeuge und die fortschreitende Fragmentierung des Marktes genannt. Aufgrund dieser Fragmentierung stehen für den gleichen Einsatzzweck eine Vielzahl von Werkzeugen bereit.
Die Auswahl wird noch schwieriger, da sich die Werkzeuge nicht nur in der Technologie unterscheiden, die sie testen können, sondern auch im Arbeitsansatz. Wenn von Automatisierung die Rede ist, wird sie immer mit Skripting in Verbindung gebracht. In den letzten Jahren wurde jedoch ein neuer Ansatz für GUI-Tests entwickelt, der als NoCode/LowCode bezeichnet wird. Dieser Ansatz erfordert grundsätzlich keine Programmierkenntnisse und ist daher auch bei Automatisierungseinsteigern beliebt. Trotzdem bleibt das Skripting die dominierende Methode, obwohl manchmal beide Ansätze verwendet werden, um möglichst viele aus dem Qualitätssicherungsteam einzubeziehen (SmartBear, 2021, S. 33).
Die Art und Weise des Testautomatisierungsansatzes und damit der Einsatz eines Testautomatisierungswerkzeugs sind abhängig von den Anforderungen im Projekt. Dies bedeutet, dass die Anforderungen bei jedem neuen Projekt immer wieder neu geprüft werden müssen.
Bestandsaufnahme
Im Rahmen der Interviews, der Analyse des aktuellen Vorgehens und der Auswertung einer internen Umfrage konnte ich folgende Vorgehensweisen für die Auswahl der Werkzeuge in den Projekten identifizieren, die sich als „Quasi-Standard“ etabliert haben:
Das Werkzeug ist Open Source und kostet nichts.
Es wurde mit dem Werkzeug schon einmal gearbeitet und es wurde als vertrauenswürdig eingestuft.
Ein Ziel der Umfrage war es, herauszufinden inwieweit die Projektsituation einen Einfluss auf die Toolauswahl hat. Darum wurden im nächsten Schritt die Projekt-Situationen bzw. die verwendeten Vorgehensmodelle der Projekte und deren Einfluss untersucht. Es zeigte sich, dass nicht die Vorgehensmodelle einen direkten Einfluss auf die Toolauswahl haben, sondern die Personen oder Gruppen, die als zukünftige Anwender das Werkzeug nutzen oder die den Einsatz freigeben.
Bei der Überprüfung des Einflusses dieser operativ-eingebundenen Beteiligten zeigte sich, dass es noch weitere Interessengruppen gibt, die direkt oder indirekt einen Einfluss auf die Auswahl eines Werkzeuges haben. Dies sind z. B.:
Softwarearchitektinnen und Softwarearchitekten, die die Technologie oder Tool-Ketten innerhalb des Projektes definieren,
das Management, das Vorgaben festlegt für den Einkauf oder die Verwendung der Werkzeuge (OpenSource, GreenIT, strategische Partnerschaften etc.) oder
die IT des Unternehmens, die durch die verwendete Infrastruktur den Einsatz bestimmter Werkzeuge verhindert (FireWall, Cloud etc.).
Darüber hinaus fanden sich bei den Recherchen bereits erste Ansätze von Checklisten für die Auswahl von Testwerkzeugen. Sie basierten meist auf wenigen funktionalen Kriterien und wurden in Workshops durch die Projektmitglieder bestimmt. Die Auswertung zeigte, dass es keine einheitliche Methode gibt und dass die so ausgewählten Tools sehr oft später durch andere Werkzeuge ersetzt wurden. Dies wurde notwendig, da bei der Auswahl notwendige Anforderungen an das Werkzeug übersehen wurden.
In der Mehrzahl der Fälle waren die vergessenen Anforderungen nicht-funktionaler Natur, wie z. B. Kriterien der Usability oder Anforderungen an die Performance. Darum war ein nächster Schritt bei der Prüfung relevanter Kriterien, die ISO/IEC 25000 Software Engineering (Qualitätskriterien und Bewertung von Softwareprodukten) heranzuziehen.
Nicht immer, aber sehr oft, waren die übersehenen Anforderungen nicht-funktionaler Natur. Darum war ein nächster Schritt bei der Prüfung relevanter Kriterien, die ISO/IEC 25000 Software Engineering (Qualitätskriterien und Bewertung von Softwareprodukten) heranzuziehen.
Abbildung 2: Kriterien für Software nach ISO/IEC 25010
Im nächsten Blogartikel dieser Reihe wird aufgezeigt, wie der Kriterienkatalog aufgebaut ist und wie sich die finale Liste der Kriterien zusammensetzt.
Literatur
SmartBear (2021): State of Software Quality | Testing.
Dieser Beitrag wurde fachlich unterstützt von:
Kay Grebenstein
Kay Grebenstein arbeitet als Tester und agiler QA-Coach für die ZEISS Digital Innovation, Dresden. Er hat in den letzten Jahren in Projekten unterschiedlicher fachlicher Domänen (Telekommunikation, Industrie, Versandhandel, Energie, …) Qualität gesichert und Software getestet. Seine Erfahrungen teilt er auf Konferenzen, Meetups und in Veröffentlichungen unterschiedlicher Art.
In den folgenden drei Blogartikeln möchte ich Ihnen Appium vorstellen: Ein Testautomatisierungs-Tool, welches speziell für den Test mobiler Anwendungen entwickelt wurde. Appium bietet uns die Möglichkeit, mobile-spezifische Anwendungsfälle wie z. B. Gestensteuerung, SMS oder eingehende Anrufe zu simulieren und entsprechende Testfälle zu automatisieren. Neben virtuellen Geräten bietet uns Appium als zusätzliches Feature die Möglichkeit, automatisierte Testfälle auf realen mobilen Endgeräten auszuführen.
Wieso auf mobilen Geräten automatisieren?
Aber wieso sollten wir unsere Testautomatisierung auf realen Endgeräten ausführen? Wieso sollten wir nicht die virtuellen Geräte der Entwicklungstools Xcode (iOS) und Android Studio (Android) nutzen? Dies sind berechtigte Fragen, denn die Anschaffung von Endgeräten verursacht Kosten.
Das erste Argument für eine Automatisierung auf realen Endgeräten mag banal klingen, fällt jedoch schwer ins Gewicht: Ihre Anwenderinnen und Anwender nutzen keine virtuellen Geräte.
Man könnte annehmen, dass virtuelle Geräte reale Endgeräte eins zu eins widerspiegeln. Diese Annahme ist jedoch falsch. Der Hauptgrund dafür ist, dass virtuelle Geräte keine eigene Hardware besitzen. Sie nutzen die Hardware des Rechners, auf dem sie installiert sind. Die Erfahrung zeigt auch, dass Fehler, die auf einem realen Endgerät entdeckt wurden, in virtuellen Geräten nicht immer zuverlässig reproduziert werden können.
Das Automatisieren auf realen Endgeräten ermöglicht Ihnen außerdem, die Performance Ihrer Anwendung zu überprüfen. Selbst wenn alle Funktionen in Ihrer Anwendung einwandfrei funktionieren, kann eine schlechte Performance auf dem Endgerät dazu führen, dass Ihre Anwendung unbrauchbar ist. Tests auf virtuellen Geräten liefern uns diesbezüglich keine verlässlichen Daten.
Auch das Problem der Hardware- und Software-Fragmentierung ist als ein Argument für die Automatisierung auf realen Endgeräten zu verstehen.
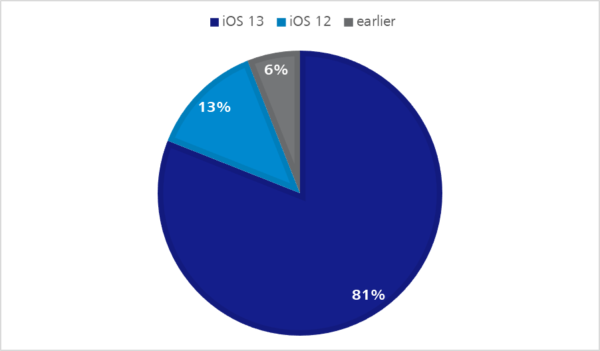
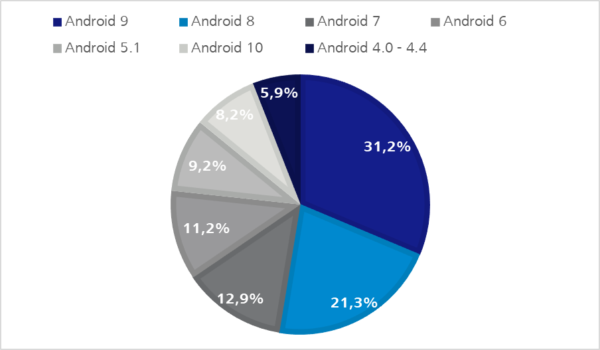
Sowohl bei iOS- als auch bei Android-Geräten entsteht durch immer größere Produktpaletten sowie Betriebssystemversionen, die immer länger im Umlauf bleiben, eine Art natürliche Fragmentierung – wie die folgenden Statistiken zeigen.
Abbildung 1: iOS Verteilung auf Apple-Geräten – Q2 2020 | https://developer.apple.com/support/app-store/Abbildung 2: Android OS Verteilung – Q2 2020 | https://9to5google.com/2020/04/10/google-kills-android-distribution-numbers-web
Bei Android-Geräten können wir eine weitere Software-Fragmentierung beobachten. Den Herstellern ist es möglich, das Android-Betriebssystem in einem gewissen Rahmen zu verändern. So können System-Apps wie die virtuelle Tastatur unterschiedlich funktionieren.
Nehmen wir als Beispiel das Gboard von Google und die virtuelle Tastatur OneU von Samsung. Beide unterstützen Swipe-Steuerelemente oder die Eingabe von Gesten, unterscheiden sich jedoch in der Ausführung.
Googles virtuelle Tastatur zeigt Ihnen das Wort, das gebildet wird, wenn Sie über die Tastatur gleiten. Samsungs Tastatur hingegen zeigt Ihnen das Wort erst, wenn Ihre Finger nicht mehr gleiten. Man sollte nicht davon ausgehen, dass die virtuellen Geräte von xCode oder Android Studio diese Unterschiede simulieren.
Natürlich können wir keinen unendlich großen Pool mit mobilen Endgeräten aufbauen. Wir können jedoch eine Auswahl von Geräten treffen, die bei Ihren Anwenderinnen und Anwendern stark vertreten sind.
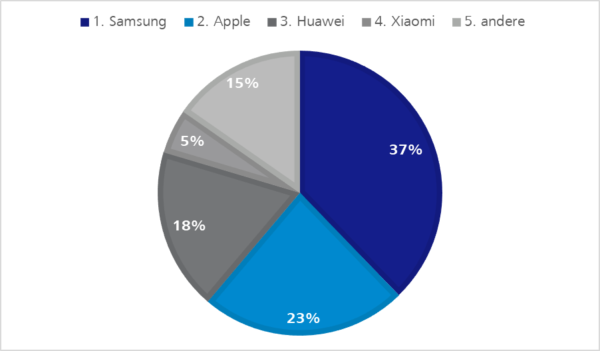
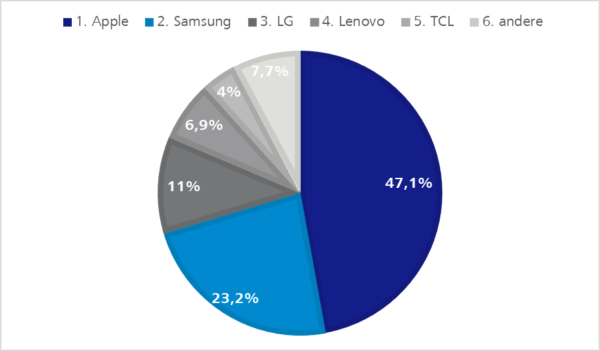
Endgeräte von Apple, Samsung und Huawei sind sicher entscheidender für einen Endgeräte-Pool als Geräte anderer Hersteller, wie die folgenden Statistiken zeigen.
Abbildung 3: Hersteller Marktanteile Deutschland Q2 2020 | de.statista.comAbbildung 4: Hersteller Marktanteile USA Q2 2020 | https://www.canalys.com/newsroom/canalys-us-smartphones-shipments-Q2-2020
Problematik – Testautomation Tool-Fragmentierung
Nachdem ich nun auf die Vorteile der Testautomatisierung auf realen Endgeräten eingegangen bin, stellt sich natürlich noch immer die grundsätzliche Frage für Projekte mit einer vorhandenen Testautomatisierung: Wieso sollte Appium als zusätzliches Testautomatisierungstool eingeführt werden?
Das Problem der Software-Fragmentierung lässt sich auch in der Testfallautomatisierung beobachten. Es gibt immer mehr Tools, die bestimmte Funktionen und Umgebungen unterstützen, untereinander jedoch nur bedingt kompatibel sind. Im Idealfall wollen wir aber nur ein einziges Testautomatisierungstool nutzen, um die Hürden in der Testfallautomatisierung gering zu halten.
Um die zuletzt gestellte Frage zu klären, lassen Sie uns von einem Multiplattformprojekt ausgehen.
Unsere Anwendung wurde als Desktop-Webseite, native iOS-App und hybride Android-App programmiert. Zusätzlich haben wir eine responsive Web-App erstellt, denn Ihre Webseite besitzt bereits eine gute Abdeckung an automatisierten Testfällen durch Selenium.
Die folgenden Statistiken zeigen, dass eine Testfallautomatisierung, welche sich lediglich auf die Webseite beschränkt, für unser Multiplattformprojekt nicht mehr ausreicht.
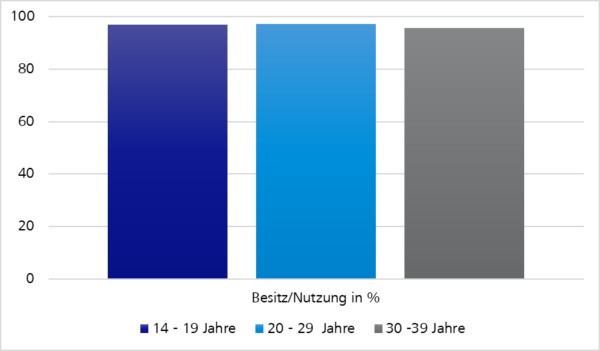
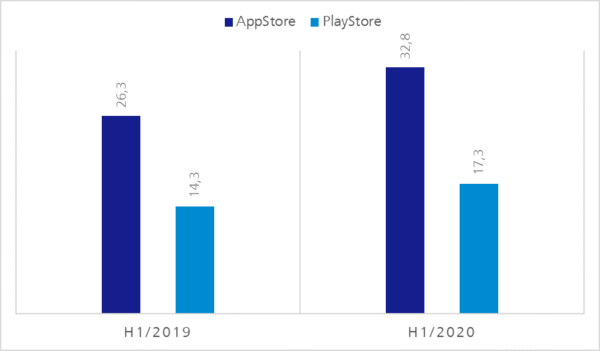
Abbildung 5: Besitz und Nutzung von Smartphones nach Altersgruppen in Deutschland 2019 | de.statista.comAbbildung 6: Umsatz Mobile Stores in Mrd. US$ | https://sensortower.com/blog/app-revenue-and-downloads-1h-2020
Wir sollten davon ausgehen, dass alle relevanten Zielgruppen unsere Anwendung auch auf mobilen Endgeräten nutzen.
Appium vs. Selenium
Ein kurzer Blick zurück auf die Ursprünge der Testautomatisierungstools zeigt, wieso die Einführung von weiteren Tools in unserem Beispiel sinnvoll ist.
Die ersten Applikationen, für die Testfälle auf Endgeräten automatisiert wurden, waren unter anderem Webseiten. Durch das Aufkommen von immer mehr Browsern wurde eine Automatisierung von Testfällen auch im Frontendbereich notwendig.
Eines der erfolgreichsten Testautomatisierungs-Tools in diesem Bereich ist Selenium. Den Ursprüngen entsprechend ist Selenium allerdings auf die Testfallautomatisierung von Webseiten ausgerichtet. Mobile spezifische Anwendungsfälle wie Gestensteuerung werden ohne Weiteres nicht unterstützt.
Doch gehen wir in unserem Multiplattformprojekt einmal davon aus, dass nur ein kleiner Teil der User die mobilen Anwendungen nutzt. Der Großteil nutzt die Desktop-Webseite und diese besitzt, wie wir wissen, eine gute automatisierte Testfallabdeckung durch Selenium. Lohnt sich dennoch die Einführung von Appium?
Nachdem ich das Problem der Tool-Fragmentierung kurz erläutert habe, wäre die Einführung von Appium eventuell mit mehr Kosten als Nutzen verbunden. Man könnte annehmen, unsere in der Selenium-Automatisierung erfahrenen Teams können die wichtigsten Testfälle mit Selenium und ein paar Workarounds für unsere mobilen Anwendungen automatisieren. Doch schauen wir uns Appium etwas genauer an, um zu überprüfen, ob diese Behauptung zutrifft.
Automatisierung mobile-spezifischer Anwendungsfälle mit Appium
Gehen wir zunächst auf die Problematik der mobile-spezifischen Anwendungsfälle ein. Lassen Sie uns einen Blick auf einige Anwendungsfälle werfen, die Appium unterstützt, bei denen sich für unsere Experten für Testautomatisierung mit Selenium sicher schnell Hürden aufbauen.
Gestensteuerung
In unserer Anwendung existiert eine Liste, deren Ende unsere Benutzerinnen und Benutzer gerne erreichen würde. In der Desktop-Browser-Version nutzen die User dafür sicher das Mausrad, den Scrollbalken oder die Pfeiltasten auf der Tastatur. In den mobilen Anwendungen werden sie allerdings auf diverse Gesten zurückgreifen, um das Ende der Liste zu erreichen.
Sie könnten den Finger auf den unteren Bildschirmbereich setzen, ihn halten, nach oben ziehen und wieder lösen, um nur einen bestimmten Teil der Liste zu bewegen. Eine weitere Möglichkeit wäre, den Finger auf den unteren Bildschirmrand zu setzen und mit einer schnellen Wischgeste nach oben ein automatisches Scrollen nach unten auszulösen. Für diese Fälle können wir auf die TouchAPI von Appium zurückgreifen.
Anrufe und SMS
Eingehende Anrufe und SMS wirken sich auf mobilen Endgeräten viel schwerer auf die Nutzung unserer Anwendung aus. Wo sich auf dem Desktop bei einem Anruf meistens nur ein weiteres Fenster öffnet, wird auf mobilen Endgeräten die laufende Anwendung meist unterbrochen und die jeweilige Anwendung für Telefonanrufe in den Vordergrund geholt. Auch eingehende SMS lösen meist eine Benachrichtigung über der laufenden Anwendung aus. Für diese Fälle können wir auf die Phone-Call-API von Appium zurückgreifen.
Systemanwendungen
Auf mobilen Endgeräten kommt unsere Anwendung wahrscheinlich viel häufiger in Verbindung mit Systemanwendungen. Sei es der Kalender, die Fotogalerie oder die hauseigene Kartenanwendung. Appium bietet uns an dieser Stelle – abhängig davon, welchen Appium Driver wir nutzen – die Möglichkeit diese Systemanwendungen ebenfalls in unsere Testautomatisierung zu integrieren.
Automatisierung von hybriden Apps
Betrachten wir nun die Problematik der Tool-Fragmentierung in der Testfallautomatisierung. Ein Teil des Problems besteht in den verschiedenen Entwicklungsarten von mobilen Applikationen. In unserem Beispielprojekt sind die üblichen Arten vertreten.
Werfen wir einen genaueren Blick darauf, wie Appium mittels der Context API, mit den komplexeren hybriden Anwendungen umgeht.
Um Elemente zu finden oder mit ihnen zu interagieren, geht Appium standardmäßig davon aus, dass sich all unsere Befehle auf native UI-Komponenten beziehen, die auf dem Bildschirm angezeigt werden. Unsere Testsession befindet sich also noch im sogenannten Native Context.
Nutzen wir z. B. den Appium-Befehl getPageSource im Rahmen einer hybriden Anwendung, werden wir in der Ausgabe bezüglich der Web Views nur Elemente finden wie <XCUIElementType…>. Wichtige Elemente wie Anchor Tags oder Divs werden uns zunächst nicht angezeigt.
Solange wir uns also im Native Context bewegen, sind alle Web Views oder sogenannter Web Context eine Blackbox für Appium. Wir sind zwar in der Lage, Web View UI-Elemente auszumachen und eventuell auch einige Buttons, die zum Beispiel iOS mit sich bringt. Elemente anhand von CSS-Selektoren auszumachen, wird jedoch nicht möglich sein.
Um besseren Zugriff auf den Web Context zu bekommen, müssen wir unsere Appium Session in den Web Context bringen. Dies können wir tun, indem wir zunächst den Namen des Web Contexts mit dem Befehl driver.getContextHandlesausmachen. Dieser gibt ein Array aller Context-Namen zurück, die Appium erstellt hat, um sie dem verfügbaren Context zuzuordnen. In unserem Fall wird uns ein Web Context namens WebView1 und ein Native Context namens NativeElement1 ausgegeben.
Um unsere Appium Session nun in den Web Context zu bringen, nutzen wir den Befehl driver.setContext(WebView1). Wenn dieser Befehl ausgeführt wurde, nutzt Appium die Context-Umgebung, die dem angegebenen Context entspricht.
Alle weiteren Befehle operieren nun innerhalb des Web Context und beziehen sich auf WebView1. Um wieder das native Element ansprechen zu können, nutzen wir den gleichen Befehl erneut mit dem Namen des Native Context, den wir ansprechen wollen. In unserem Fall also driver.setContext(NativeElement1). Wenn wir herausfinden möchten, in welchem Context wir uns aktuell befinden, können wir den folgenden Befehl nutzen: String currentContext = driver.getContext();
Nachdem wir nun kurz auf die Context API von Appium eingegangen sind, lassen Sie uns einen Blick auf die Funktionsweise werfen.
Auf iOS nutzt Appium das sogenannte „remote Debugger Protocol“, welches von Safari unterstützt wird. Dieses „remote Debugger Protocol“ ermöglicht es uns, Information über die in Safari angezeigten Seiten zu erhalten oder das Browserverhalten zu kontrollieren. Eine Methode, auf die wir zurückgreifen können, ist die Möglichkeit, JavaScript in die aktuelle Webseite einzufügen.
Appium verwendet diese Funktion, um alle in der WebDriver API verfügbaren Befehle durchzuführen.
Unterstützung von Codesprachen
Mit Appium können Sie Tests in verschiedenen Codesprachen schreiben. Dies ist ein Vorteil des Client-Server-Modells. Das Appium-Entwicklungsteam kann alle Appium-Funktionen in nur einer Server-Codebasis implementieren, welche in JavaScript geschrieben ist (Appium Server = NodeJS Plattform). Dennoch können die Nutzerinnen und Nutzer, die Code in einer anderen Programmiersprache schreiben, Zugriff auf diese Funktionen erhalten. Der Zugriff erfolgt über die Appium Client Libraries, die uns Appium zur Verfügung stellt. Wenn wir zum Bespiel unsere automatischen Tests in Java schreiben möchten, müssen wir die entsprechenden Appium Java Libraries in unseren Appium Client integrieren.
Appium Client-Server-Modell
Wie bereits beschrieben senden wir unseren Testcode (Befehle/Requests) über den Appium Client mit den entsprechenden Libraries an den Appium Server. Als Appium Client kann zum Bespiel das Entwickler-Tool Eclipse dienen. Der Appium Server wiederum schickt unseren Testcode (Befehle/Requests) an das mobile Endgerät, auf dem dieser dann ausgeführt wird. Doch gehen wir etwas mehr ins Detail.
Damit der Appium Server den Appium Client Testcode (Befehle/Requests) interpretieren kann, nutzt er das WebDriver Protocol oder das ältere JSON Wire Protocol, welche unseren Testcode in einen HTTP RESTful request konvertieren.
Danach schickt der Appium Server unseren Testcode, je nachdem welches Endgerät wir ansprechen wollen, an das plattformspezifische Testframework, welches wiederum den Testcode auf dem Endgerät ausführt. Der Appium Server ist an dieser Stelle in der Lage, mit den unterschiedlichen Testframeworks zu kommunizieren.
Damit der Appium Server entscheiden kann, mit welchem dieser plattformspezifischen Testframeworks bzw. mit welchem Endgerät er kommunizieren soll, muss unser Testcode sogenannte „Desired Capabilities“ als JSON Object an den Appium Server mitschicken. In den Desired Capabilities geben wir zum Beispiel den Gerätenamen, die Plattform (iOS, Android…) und die Plattformversion an.
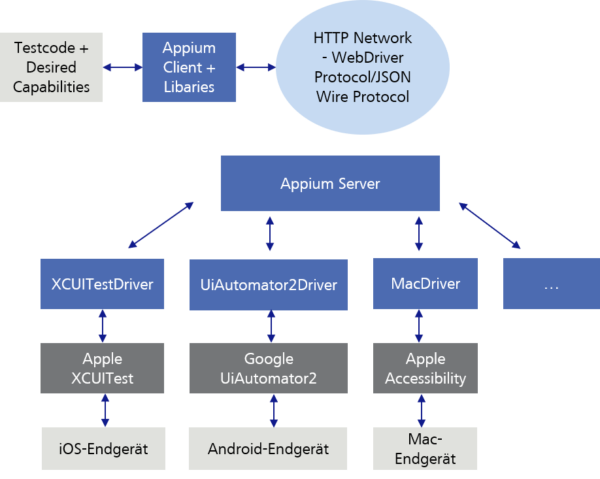
Abbildung 7: Appium Client-Server-Modell
Es gibt nicht unbedingt nur ein Testframework pro Plattform. So gibt es beispielsweise unter Android drei verschiedene Automatisierungstechnologien von Google. Die älteste, UiAutomator, wurde von UiAutomator2 abgelöst. UiAutomator2 hat eine Vielzahl neuer Automatisierungsfunktionen hinzugefügt.
Das neueste Testframework heißt Espresso und funktioniert mit einem ganz anderen Modell als UiAutomator2, bietet jedoch eine viel größere Stabilität und Testgeschwindigkeit.
Sie können Ihre Appium-Tests anweisen, sich auf eine dieser Testframeworks zu beziehen, basierend auf deren spezifischen Funktionen und der Plattformunterstützung.
Theoretisch könnten Sie die Testframeworks auch direkt einsetzen. Appium bietet jedoch einen praktischen Rahmen für die verschiedenen Testframeworks, stellt sie mit demselben WebDriver-Protocol zur Verfügung und versucht, Verhaltensunterschiede zwischen den verschiedenen Testframeworks auszugleichen.
Abbildung 8: Appium als Rahmen für Testframeworks
Wenn neue Testframeworks erscheinen, kann das Appium-Team ein Kommunikationsprotokoll (Driver) für diese erstellen, sodass Sie auf diese zugreifen können, ohne all Ihre Testskripte neu schreiben zu müssen. Dies ist die Stärke der Verwendung eines Standardprotokolls und der Client-Server-Architektur.
Es ermöglicht auch die plattformübergreifende Automatisierung. Anstatt zwei verschiedene Testframeworks in zwei verschiedenen Sprachen zu lernen, können Sie in vielen Fällen ein Appium-Skript schreiben und dieses auf unterschiedlichen Plattformen ausführen.
Wer Appium nutzt, für den ist es nicht erforderlich, viel über diese zugrunde liegenden Testframeworks zu wissen, da sie sich nur mit der Appium API befassen und beispielsweise keinen XCUITest- oder Espresso-Test schreiben.
Zusammenfassung
Zusammenfassend ist zu sagen: Appium ist ein Tool zur Automatisierung mobiler Anwendungen, welches von Selenium inspiriert wurde. Tatsächlich basieren Appium-Tests auf demselben Protocol wie Selenium-Tests. Selenium bietet seinen Nutzerinnen und Nutzern die Möglichkeit, Webbrowser zu steuern. Aus historischen Gründen wird es daher manchmal als „WebDriver“ oder „Selenium/WebDriver“ bezeichnet.
Wie Sie eventuell bereits am Namen erkennen können, wurde Appium so konzipiert, dass es so gut wie möglich mit Selenium kompatibel ist. Appium übernahm das gleiche Protocol wie Selenium, so dass Appium- und Seleniumtests größtenteils gleich aussehen und sich gleich „anfühlen“.
Tatsächlich wurden die Appium Client Libraries auf den Selenium Client Libraries aufgebaut. Es gab jedoch ein Problem: Das Selenium Protocol wurde nur zur Automatisierung von Webbrowsern entwickelt. Daher musste Appium dem Protocol Befehle hinzufügen, um mobilspezifische Automatisierung zu unterstützen. Dies bedeutet, dass Appium-Befehle eine Erweiterung der Selenium-Befehle sind.
Die zuvor aufgestellte Behauptung, dass die Einführung von Appium in unser Beispielprojekt aufgrund des Kosten-Nutzen-Faktors nicht sinnvoll wäre, ist also falsch. Es ist sogar davon auszugehen, dass eine Einführung, neben einer besseren Abdeckung hinsichtlich der Testautomatisierung, auch zu einer Prozessverbesserung beitragen kann.
Ich hoffe, dieser kurze Exkurs in die Welt der Testautomatisierung und in den technischen Hintergrund von Appium hat Ihnen etwas Freude bereitet.
In meinem zweiten Blog zum Thema Appium zeige ich Ihnen, wie wir Appium einrichten. Zusätzlich werde ich anhand konkreter Codebeispiele zeigen, was wir mit Appium in unserem Multiplattformprojekt leisten können. Dabei gehen wir auf die bereits angesprochenen Fälle ein.
Ich würde mich freuen, wenn Sie auch in den nächsten Beitrag dieser Blogreihe wieder reinschauen. Bis dahin, happy testing.
Im agilen Umfeld tragen Regressionstests dazu bei, die Qualität aufrecht zu erhalten. Mit jeder User Story kommen neu entwickelte Funktionalitäten hinzu, alte Funktionalitäten müssen weiterhin funktionieren. Spätestens nach zehn Sprints ist der Regressionsaufwand so hoch geworden, dass man mit manuellen Tests nicht mehr alles nachtesten kann. Also bleibt nur eines: Testautomatisierung.
Ein Projekt, das auf der grünen Wiese entsteht, ermöglicht es, von Anfang an die Testautomatisierung sauber zu integrieren. Gleichzeitig findet man sich im Testumfeld oft als Einzelkämpfer mehreren Entwicklern gegenüber. Wie lässt sich also eine zeitintensive Automatisierung der Funktionalitäten im alltäglichen Doing eines Test Analysten realisieren?
Umfeld in unserem Projekt
In unserem Projekt erstellen wir eine neue Software im JavaScript-Umfeld. Umgesetzt wird diese mit dem Electron Framework. Für die Automatisierung von Testfällen ist dadurch Spectron als Mittel der Wahl gesetzt. Als Projektplattform wird Jira genutzt und das Projekt wird nach dem SCRUM-Modell durchgeführt. Das Projektteam besteht aus (bezogen auf Vollzeit-Tätigkeit):
6 Entwicklern inkl. 1 Architekt
1 Scrum Master
1 Business Analyst
1 ½ Testern
Ansatz
Bereits zum Kick-off des Projektes war absehbar, dass die Testautomatisierung durch die Tester nicht geleistet werden kann. Daher hat sich das Team folgende Lösung überlegt:
die Testautomatisierung erfolgt durch die Entwickler
der Review für die Testfälle erfolgt durch die Tester
die Erstellung und die Abnahme der Spectron-Testfälle wird in der Definition of Done festgeschrieben
Vorteile
Zeiteinsparung Test: Der eigentliche Grund für dieses Vorgehen ist die Ressourcenknappheit seitens der Tester. Hätten diese auch die Automatisierung übernehmen müssen, wäre das Ganze nicht möglich gewesen.
Perspektivwechsel Test: Die Tester können im Gespräch und im Review einiges lernen. So wird bei Fragen, warum ein Test so geschrieben wurde, die Umsetzung verständlicher. Dadurch entstehen auch Testfälle, an die man sonst nicht gedacht hätte.
Know-how-Entwicklung: Da es zum Alltag des Programmierers dazugehört, entwicklungsbegleitende Tests zu schreiben, ist das Grundverständnis für die Erstellung der automatisierten Tests sehr hoch. Bei unserem Projekt ist dies bereits mehrfach von Nutzen gewesen:
Teile der Anwendung konnten mit technischen Kniffen abgedeckt werden, die ein Tester nicht ohne Weiteres hätte liefern können. Ein Beispiel hierfür ist die automatisierte Prüfung der korrekten Darstellung einer Punktewolke in einem Chart und die Anzeige der Details eines gewählten Punktes.
Über technische Refinements konnten die Performanz und die Stabilität der Spectron-Tests deutlich verbessert werden.
Nach veränderter Toolauswahl dauerte die Ausführung eines kompletten Spectron-Durchlaufes eine halbe Stunde weniger (25% Zeiteinsparung).
Perspektivwechsel Entwicklung: Dadurch, dass der Entwickler sich mit der Sichtweise eines Nutzers auf die Funktionalität und die Oberfläche der Software beschäftigt hat, konnte eine Vielzahl von Fehlern vermieden werden und das Grundverständnis stieg durch den regen Austausch mit den Testern.
Nachteile
Erhöhter Zeitaufwand Entwickler: Was an einer Stelle an Zeit eingespart wird, wird an anderer Stelle wieder benötigt. Der Aufwand kann aber in diesem Fall auf mehrere Schultern verteilt werden.
Gliederung: Entwickler gliedern Testfälle in technisch logische Bereiche. Da dies nicht immer identisch zur fachlichen Logik ist, kann es für die Tester schwer werden, bestimmte Testfälle wiederzufinden und zu überprüfen.
Herausforderungen und Lösungen
Traceability DEV-QA: Der Review findet im Projekt im git (Diff-Tool) statt. Im Projekt wurden angepasste und angelegte Spectron-Testfälle durch das Test-Team gereviewed, gelöschte Testfälle aber nicht – in der Annahme, dass diese bei der Anpassung ersetzt wurden. Dadurch waren Requirements nicht mehr abgedeckt. Lösung: Um den Problemen im Review entgegenzutreten, ist ein Training für den Umgang mit git für alle, die im git arbeiten und reviewen müssen, besonders hilfreich. Auch ein Walkthrough zwischen Test- und Entwicklungsteam bei großen Anpassungen bring einen Mehrwert, damit die Tester besser verstehen, was die Entwickler umgesetzt haben.
Abbildung 1: Beispiel für Git-Review
Traceability-Spectron-Anforderungen: Diese Herausforderung ist speziell in unserem Projektumfeld entstanden. Das agile Team verwendet für das Anforderungs- und Testmanagement Jira, während im Umfeld des Kunden aus rechtlichen Gründen die Anforderungen und Testfälle in einer separaten Anforderungsmanagementsoftware spezifiziert werden müssen. Da die Systeme sich nicht kennen, ist eine automatische Traceability nicht gewährleistet. Lösung: Um dieser Hürde entgegenzuwirken wurde eine direkte Zuweisung der Req-ID in die Spectron Cluster eingeführt.
Abbildung 2: Beispiel für direkte Zuweisung
Fazit
Abschließend lässt sich sagen, dass sich in unserem Projekt der Ansatz bewährt hat, den Test Analysten automatisierte Testfälle nur reviewen zu lassen, statt sie selbst zu schreiben. Die Aufgabenteilung zwischen Testern und Entwicklern fügt sich sehr gut in die agile Vorgehensweise (Scrum) ein. Die Vorteile überwiegen die Nachteile somit bei Weitem.
Dieser Ansatz ist sehr gut geeignet für ein agiles Projekt mit schmalem Staffing und hohem Qualitätsanspruch, das auf der grünen Wiese startet. Man sollte diesen Ansatz aber von Beginn an verfolgen. Ein nachträgliches Aufsetzen ist kaum noch möglich, da eine sukzessive Erweiterung der Testfälle nach jeder User Story deutlich übersichtlicher und einfacher ist als Testfälle en bloc zu erstellen. Des Weiteren werden bereits zu Beginn Entscheidungen in der Umsetzung, der Gliederung, der Architektur und vor allem in den Prozessen (Definition of Done, …) getroffen.
Mit Selenium lassen sich wie bei den meisten Testautomatisierungswerkzeugen Ergebnisprotokolle erzeugen. Diese maschinenlesbaren Dokumente in Formaten wie XML oder JSON sind nicht sehr benutzerfreundlich, aber sie können leicht in andere Werkzeuge eingebunden und damit lesbarer gemacht werden. Mit dieser Blogreihe möchte ich zeigen, wie sich mit einfachen Mitteln wichtige Funktionen in Selenium erweitern oder ausbauen lassen. Im ersten Teil habe ich vorgestellt, was Selenium 4 bringt und wie Screenshots eingesetzt werden können. Im zweiten Teil erstellten wir ein Video der Testdurchführung und im dritten Teil geht es um Reports. Dabei versuche ich die Ansätze nach ihrem Mehrwert (The Good) und ihren Herausforderungen (The Bad) zu bewerten und ggf. nützliche Hinweise (… and the Useful) zu geben.
Warum benötigen wir Reports?
Um die Frage nach dem “Warum“ zu beantworten, fange ich mit dem „schlimmsten“ Fall an: Die Auswertung und revisionssichere Ablage aller Testergebnisse ist in manchen Projekten verpflichtend vorgeschrieben, da hier gesetzliche oder andere Vorgaben eingehalten werden müssen. Bei Auftragsentwicklung kann das eine Forderung des Kunden sein. Bei Soft- und Hardwareentwicklung im Medizinbereich ist es eine Pflichtvorgabe für die Genehmigung und Zulassung durch die Behörden. Aber auch ohne diese Vorgaben bieten Reports und übersichtliche Protokolle einen Mehrwert für das Projekt. So lassen sich aus ihnen Kennzahlen und Trends ableiten, die das Team für seine Retrospektiven oder Weiterentwicklung benötigt.
Einfach mal ein Protokoll…
Es gibt viele Wege, einfache maschinenlesbare Testprotokolle zu erzeugen. Bei der Nutzung von automatisierten Tests (Selenium, JUnit) in Java-Projekten lässt sich über Maven das Plugin maven-surefire einbinden, welches während des Buildvorganges eine XML-Datei erzeugt, die die Ergebnisse eines Testlaufes aufzeichnet. Die XML-Datei beinhaltet den Namen der Testklasse und aller Testmethoden, die Gesamtdauer der Testdurchführung, die Dauer jedes Testfalles / jeder Testmethode sowie die Testergebnisse (tests, errors, skipped, failures).
… und was macht man damit.
Die maschinenlesbaren Protokolle werden meist automatisch im Buildwerkzeug erzeugt und in den Ergebnisbericht des Buildwerkzeuges eingebunden. So bindet Jenkins alle Ergebnisse der automatisierten Tests für Projekte ein, die mit Maven organisiert wurden. Darüber hinaus stehen in den meisten Buildwerkzeugen Plugins bereit, die die Testprotokolle einbinden oder sogar grafisch aufbereiten.
Die Projekte, die all ihre Testergebnisse dokumentieren müssen, stehen meist vor dem Problem, dass die Testergebnisse der verschiedenen Testarten (manuell, automatisiert etc.) in unterschiedlichen Werkzeugen erzeugt werden und damit in unterschiedlichen Formaten vorliegen. Darum bieten verschiedene Testmanagementwerkzeuge die Möglichkeit, die maschinenlesbaren Reports einzulesen. Damit stehen die Testergebnisse der automatisierten neben den manuellen Tests und können in einem Testbericht / Testreport zusammengefasst werden.
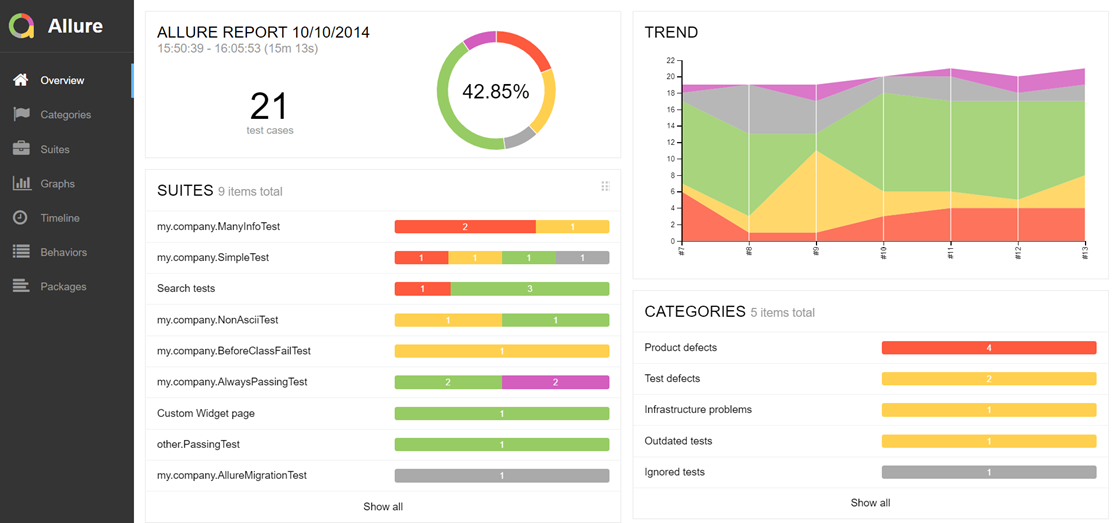
Sofern kein passendes Testmanagementwerkzeug vorhanden ist oder man eine Stand-alone-Variante benötigt, möchte ich noch das Werkzeug Allure Test Report vorstellen. Das Allure-Framework ist ein flexibles, leichtes und mehrsprachiges Testberichtstool mit der Möglichkeit, Screenshots, Protokolle usw. hinzuzufügen. Es bietet eine modulare Architektur und übersichtliche Webberichte mit der Möglichkeit, Anhänge, Schritte, Parameter und vieles mehr zu speichern. Dabei werden verschiedene Testframeworks unterstützt: JUnit4, JUnit5, Cucumber, JBehave, TestNG, …
Um eine bessere Auswertung und Übersichtlichkeit in den Reports zu erzeugen, setzt das Allure-Framework eigene Annotations ein. Damit lassen sich die Ergebnisse der Testklassen und Testmethoden mit Features, Epics oder Stories verknüpfen. Über die Annotationen wie @Story, @Feature oder @Epic lassen sich zum Beispiel Testklassen oder Testmethoden mit den Anforderungen (Story, Epic, Feature) verknüpfen. Diese Verknüpfungen lassen sich dann in der Reportansicht auswerten und damit Aussagen zur Testabdeckung bzw. zum Projektfortschritt treffen.
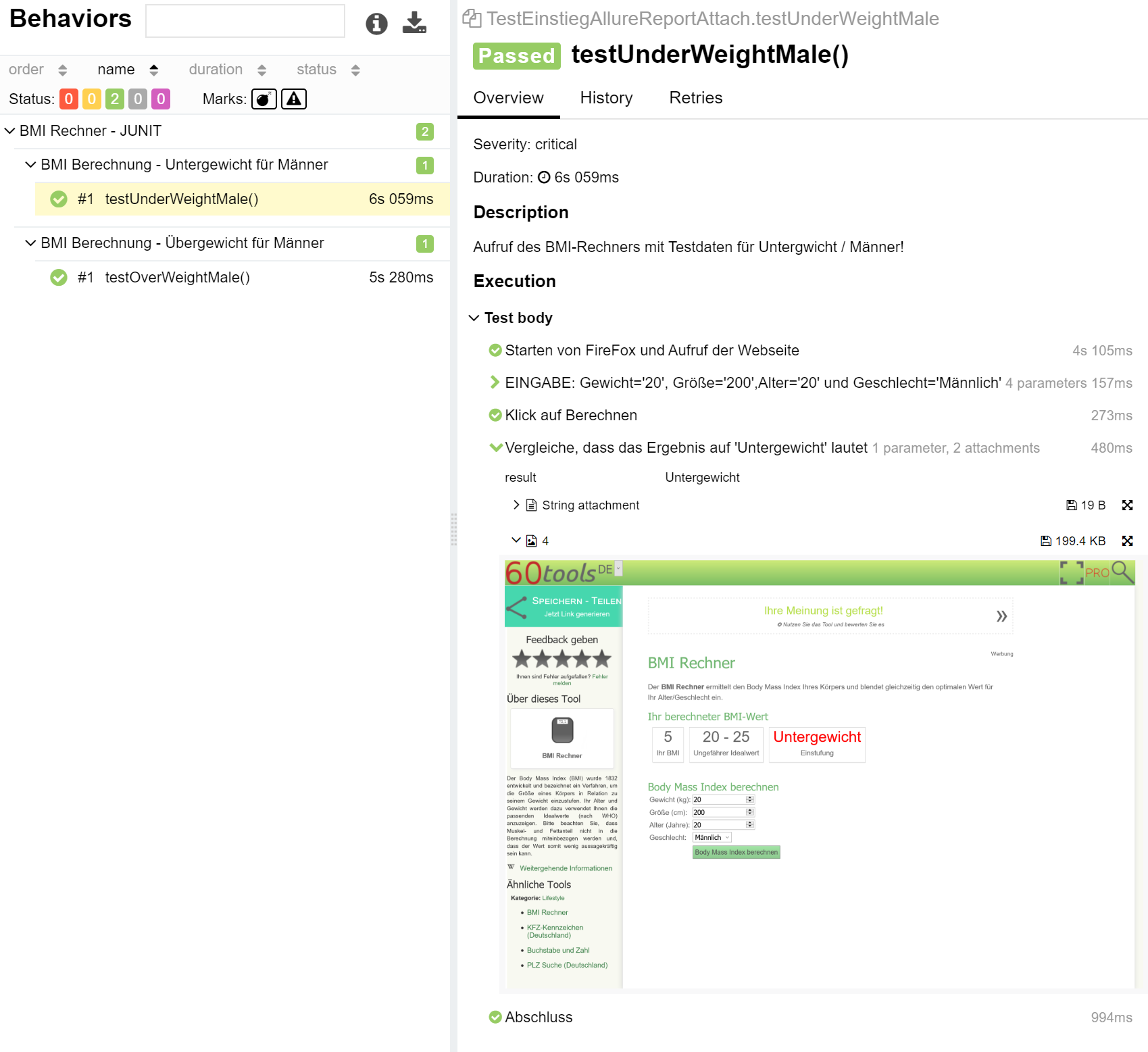
Darüber hinaus lässt sich die Lesbarkeit der Testfälle durch die Annotation @Step und @Attachment verbessern. Wir können unseren Tesftfall (@Test) in einzelne Testmethoden aufteilen, um die Lesbarkeit und Wiederverwendbarkeit zu erhöhen. Mit der Annotation @Step des Allure-Frameworks lassen sich diese Testmethoden bzw. Testschritte im Testprotokoll anzeigen. Dabei unterstützt @Step die Anzeige einer Testschrittbeschreibung der verwendeten Parameter, die Schrittergebnisse sowie Attachments. Denn Testschritten lassen sich Texte in Form von String und Bilder in Form von byte[] anfügen. Siehe dazu das Codebeispiel …
Annotationen von Allure
@Feature("BMI Rechner - JUNIT")
public class TestAllureReport {
@Test
@Description("Aufruf des BMI-Rechners mit Testdaten für Untergwicht / Männer!")
@Severity(SeverityLevel.CRITICAL)
@Story("BMI Berechnung - Untergewicht für Männer")
public void testUnderWeightMale() {
inputTestdata("20", "200", "20", "Männlich");
clickButtonCalc();
compareResult("Untergewicht");
}
@Step("EINGABE: Gewicht='{0}', Größe='{1}',Alter='{2}' und Geschlecht='{3}'")
private void inputTestdata(String weight, String size, String age, String sex) {
...
}
@Step("Klick auf Berechnen")
private void clickButtonCalc() {
...
}
@Step("Vergleiche, dass das Ergebnis auf '{0}' lautet")
private void compareResult(String result) {
...
// attach text
attachment(str2);
//make a screenshot and attach
screenShot(driver, ".\\screenshots\\" ,"test_Oversized");
...
}
@Attachment(value = "String attachment", type = "text/plain")
public String attachment(String text) {
return "<p>" + text + "</p>";
}
@Attachment(value = "4", type = "image/png")
private static byte[] screenShot(FirefoxDriver driver, String folder, String filename) {
...
return new byte[0];
}
}
… und das Ergebnis im Testprotokoll:
Fazit
Mit Testprotokollen und Reports lassen sich sehr einfach automatisierte Testläufe erzeugen und in die eigene Toolkette einbinden. Dies ist zwar meist mit etwas Mehraufwand verbunden, aber dadurch werden Trends und Probleme schneller und besser erkannt.
Ergebnisprotokolle und Reports
The Good
The Bad
… and the Useful
• Visualisierung des aktuellen Status • Es lassen sich Trends und Probleme erkennen
• Mehr Aufwand • Neue Werkzeuge und Schnittstellen • höhere Komplexität
Mit dieser Blogreihe möchte ich zeigen, wie sich mit einfachen Mitteln wichtige Funktionen in Selenium einbauen lassen. Im ersten Teil habe ich vorgestellt, was Selenium 4 bringt und wie Screenshots eingesetzt werden können. Im zweiten Teil erstellen wir ein Video der Testdurchführung. Dabei versuche ich, die Ansätze nach ihrem Mehrwert (The Good) und ihren Herausforderungen (The Bad) zu bewerten und ggf. nützliche Hinweise (… and the Useful) zu geben.
Warum?
Aber zum Anfang stellen wir uns kurz die Frage: Warum ein Video bzw. einen Screencast der Testdurchführung aufzeichnen?
Mit einem Video haben wir eine Aufnahme des gesamten Testlaufs. Anders als mit einem Screenshot können wir so nicht nur das Testergebnis festhalten, sondern es lässt sich auch der Weg dorthin nachvollziehen.
Wie Screenshots können auch die Videos zum Debugging dienen und auf Probleme während des Testlaufes hinweisen. Darum ist es wie beim Screenshot sinnvoll, nur dann Videos zu erzeugen, wenn Probleme auftreten. Nach diesem Ansatz sollte die Video-Funktionalität um einen flexiblen und globalen Schalter erweitert werden, der sich je nach Notwendigkeit setzen lässt.
Aber die Videos können auch der Dokumentation der Testergebnisse dienen. In manchen Projekten ist eine ausführliche Dokumentation sogar verpflichtend vorgeschrieben, da hier gesetzliche oder andere Vorgaben eingehalten werden müssen.
Videos aufnehmen leicht gemacht
Da ich Selenium mit der Java-Ausprägung nutze, war mein erster Ansatz, Videos mit den „hauseigenen“ Funktionen von Java aufzunehmen bzw. ein passendes Framework zu nutzen. Meine erste Wahl fiel auf das Framework MonteCC, da sich hier mit der Hilfe von nur zwei Methoden der Bildschirm während der Testdurchführung aufnehmen ließ. In einer Methode vor dem Test wird die Videoaufnahme gestartet und in einer Methode nach dem Test wird die Aufnahme gestoppt und das Video im passenden Verzeichnis abgelegt.
Damit dies vor jedem Test passiert, nutzen wir die Annotations von JUnit:
@Test
Die Methode mit der Annotation @Test ist ein Testfall und wird bei der Testausführung gestartet und das Ergebnis im Testprotokoll erfasst.
@BeforeEach
Diese Methode wird vor jeder Testaufführung aufgerufen (siehe @Test).
@AfterEach
Diese Methode wird nach jeder Testaufführung aufgerufen (siehe @Test).
Wer eine komplette Aufzeichnung aller Testfälle benötigt, kann auch die Annotations @Before und @After nutzen, die vor allen bzw. nach allen Tests einer Testsuite (Testklasse) aufgerufen werden.
Große Nachteile von MonteCC sind, dass zum einen das letzte Release bereits mehr als sechs Jahre zurückliegt und zum anderen, dass die Videos im Format QuickTime vorliegen.
Als Alternative bot sich JavaCV (https://github.com/bytedeco/javacv) an. Die Bibliothek wird in GitHub fleißig gepflegt und speichert Videos im Format MPEG. Auch hier gibt es bei der Videoerzeugung zwei Methoden, die sowohl vor als auch nach dem Test aufgerufen werden können. Aber die JavaCV benötigt weitere Methoden, da parallel zum Testlauf in kurzen Abständen Screenshots erstellt und diese dann nach dem Test zu einem Video zusammenstellt werden. Eine ausführliche Anleitung findet ihr unter folgenden Link: https://cooltrickshome.blogspot.com/2016/12/create-your-own-free-screen-recorder.html.
Für den Einsatz beim automatisierten Testen habe ich folgende Änderungen vorgenommen:
/**
*
* https://github.com/bytedeco/javacv
* https://cooltrickshome.blogspot.com/2016/12/create-your-own-free-screen-recorder.html
*/
public class RecordSeleniumJavaCV {
// The WebDriver is a tool for writing automated tests of websites.
FirefoxDriver driver;
public static boolean videoComplete=false;
public static String inputImageDir= "videos" + File.separator + "inputImgFolder"+File.separator;
public static String inputImgExt="png";
public static String outputVideoDir= "videos" + File.separator;
public static String outputVideo;
public static int counter=0;
public static int imgProcessed=0;
public static FFmpegFrameRecorder recorder=null;
public static int videoWidth=1920;
public static int videoHeight=1080;
public static int videoFrameRate=3;
public static int videoQuality=0; // 0 is the max quality
public static int videoBitRate=9000;
public static String videoFormat="mp4";
public static int videoCodec=avcodec.AV_CODEC_ID_MPEG4;
public static Thread t1=null;
public static Thread t2=null;
public static boolean isRegionSelected=false;
public static int c1=0;
public static int c2=0;
public static int c3=0;
public static int c4=0;
/**
* Explanation:
* 1) videoComplete variables tells if user has stopped the recording or not.
* 2) inputImageDir defines the input directory where screenshots will be stored which would be utilized by the video thread
* 3) inputImgExt denotes the extension of the image taken for screenshot.
* 4) outputVideo is the name of the recorded video file
* 5) counter is used for numbering the screenshots when stored in input directory.
* 6) recorder is used for starting and stopping the video recording
* 7) videoWidth, videoFrameRate etc define output video param
* 8) If user wants to record only a selected region then c1,c2,c3,c4 denotes the coordinate
*
* @return
* @throws Exception
*/
public static FFmpegFrameRecorder getRecorder() throws Exception
{
if(recorder!=null)
{
return recorder;
}
recorder = new FFmpegFrameRecorder(outputVideo,videoWidth,videoHeight);
try
{
recorder.setFrameRate(videoFrameRate);
recorder.setVideoCodec(videoCodec);
recorder.setVideoBitrate(videoBitRate);
recorder.setFormat(videoFormat);
recorder.setVideoQuality(videoQuality); // maximum quality
recorder.start();
}
catch(Exception e)
{
System.out.println("Exception while starting the recorder object "+e.getMessage());
throw new Exception("Unable to start recorder");
}
return recorder;
}
/**
* Explanation:
* 1) This method is used to get the Recorder object.
* 2) We create an object of FFmpegFrameRecorder named "Recorder" and then set all its video parameters.
* 3) Lastly we start the recorder and then return the object.
*
* @return
* @throws Exception
*/
public static Robot getRobot() throws Exception
{
Robot r=null;
try {
r = new Robot();
return r;
} catch (AWTException e) {
System.out.println("Issue while initiating Robot object "+e.getMessage());
throw new Exception("Issue while initiating Robot object");
}
}
/**
* Explanation:
* 1) Two threads are started in this module when user starts the recording
* 2) First thread calls the takeScreenshot module which keeps on taking screenshot of user screen and saves them on local disk.
* 3) Second thread calls the prepareVideo which monitors the screenshot created in step 2 and add them continuously on the video.
*
* @param r
*/
public static void takeScreenshot(Robot r)
{
Dimension size = Toolkit.getDefaultToolkit().getScreenSize();
Rectangle rec=new Rectangle(size);
if(isRegionSelected)
{
rec=new Rectangle(c1, c2, c3-c1, c4-c2);
}
while(!videoComplete)
{
counter++;
BufferedImage img = r.createScreenCapture(rec);
try {
ImageIO.write(img, inputImgExt, new File(inputImageDir+counter+"."+inputImgExt));
} catch (IOException e) {
System.out.println("Got an issue while writing the screenshot to disk "+e.getMessage());
counter--;
}
}
}
/**
* Explanation:
* 1) If user has selected a region for recording then we set the rectangle with the coordinate value of c1,c2,c3,c4. Otherwise we set the rectangle to be full screen
* 2) Now we run a loop until videoComplete is false (remains false until user press stop recording.
* 3) Now we capture the region and write the same to the input image directory.
* 4) So when user starts the recording this method keeps on taking screenshot and saves them into disk.
*
*/
public static void prepareVideo()
{
File scanFolder=new File(inputImageDir);
while(!videoComplete)
{
File[] inputFiles=scanFolder.listFiles();
try {
getRobot().delay(500);
} catch (Exception e) {
}
//for(int i=0;i<scanFolder.list().length;i++)
for(int i=0;i<inputFiles.length;i++)
{
//imgProcessed++;
addImageToVideo(inputFiles[i].getAbsolutePath());
//String imgToAdd=scanFolder.getAbsolutePath()+File.separator+imgProcessed+"."+inputImgExt;
//addImageToVideo(imgToAdd);
//new File(imgToAdd).delete();
inputFiles[i].delete();
}
}
File[] inputFiles=scanFolder.listFiles();
for(int i=0;i<inputFiles.length;i++)
{
addImageToVideo(inputFiles[i].getAbsolutePath());
inputFiles[i].delete();
}
}
/**
* Explanation:
* 1) cvLoadImage is used to load the image passed as argument
* 2) We call the convert method to convert the image to frame which could be used by the recorder
* 3) We pass the frame obtained in step 2 and add the same in the recorder by calling the record method.
*
* @return
*/
public static OpenCVFrameConverter.ToIplImage getFrameConverter()
{
OpenCVFrameConverter.ToIplImage grabberConverter = new OpenCVFrameConverter.ToIplImage();
return grabberConverter;
}
/**
* Explanation:
* 1) We start a loop which will run until video complete is set true (done only when user press stop recording)
* 2) We keep on monitoring the input Image directory
* 3) We traverse each file found in the input image directory and add those images to video using the addImageToVideo method. After the image has been added we delete the image
* 4) Using the loop in step1 we keep on repeating step 2 and 3 so that each image gets added to video. We added a delay of 500ms so that this module does not picks a half created image from the takeScreenshot module
* 5) When user press stop recording the loop gets broken. Now we finally traverse the input image directory and add the remaining images to video.
*
* @param imgPath
*/
public static void addImageToVideo(String imgPath)
{
try {
getRecorder().record(getFrameConverter().convert(cvLoadImage(imgPath)));
} catch (Exception e) {
System.out.println("Exception while adding image to video "+e.getMessage());
}
}
/**
* Explanation:
* 1) We make a JFrame with the button for staring and stopping the recording. One more button is added for allowing user to record only a selected portion of screen
* 2) If user clicks to select only certain region then we call a class CropRegion method getImage which helps in retrieving the coordinate of the region selected by user and update the same in variable c1,c2,c3,c4
* 3) If user clicks on start recording then startRecording method is called
* 4) If user clicks on stoprecording then stopRecording method is called
*/
@BeforeEach
public void beforeTest() {
System.out.println("this.screenRecorder.start()");
SimpleDateFormat dateFormat = new SimpleDateFormat("yyyyMMdd_HHmmss");
String timestamp = dateFormat.format(new Date());
outputVideo= outputVideoDir + "recording_" + timestamp + ".mp4";
try {
t1=new Thread()
{
public void run() {
try {
takeScreenshot(getRobot());
} catch (Exception e) {
System.out.println("Cannot make robot object, Exiting program "+e.getMessage());
System.exit(0);
}
}
};
t2=new Thread()
{
public void run() {
prepareVideo();
}
};
t1.start();
t2.start();
System.out.println("Started recording at "+new Date());
} catch (Exception e) {
System.out.println("screenRecorder.start " + e.getMessage());
}
}
@AfterEach
public void afterTest() {
System.out.println("this.screenRecorder.stop()");
try {
videoComplete=true;
System.out.println("Stopping recording at "+new Date());
t1.join();
System.out.println("Screenshot thread complete");
t2.join();
System.out.println("Video maker thread complete");
getRecorder().stop();
System.out.println("Recording has been saved successfully at "+new File(outputVideo).getAbsolutePath());
} catch (Exception e) {
System.out.println("screenRecorder.stop " + e.getMessage());
}
}
@Test
public void testMe() {
//toDo
}
}
Gibt es einen Haken?
Somit haben wir nun mehrere Möglichkeiten, den automatischen Testlauf in einem Video festzuhalten, um bei Problemen diese nachvollziehen oder die Dokumentationspflichten erfüllen zu können.
Aber die Aufnahme während des Testdurchlaufes ist mit einem Risiko verbunden, dass der Tester / Testautomatisierer beachten sollte: Es ist ein Eingriff den normalen Testablauf, da wir ggf. die Timings der Geschwindigkeit ändern. Unser modifizierter Testlauf mit Videoaufnahme kann sich anders verhalten als ein Testlauf ohne Videoaufnahme.
Videos der Testdurchführung
The Good
The Bad
… and the Useful
• Aufnahme des gesamten Testlaufs • Neben dem Testergebnis lässt sich auch der Weg dorthin nachvollziehen
• Es wird der Testlauf beeinflusst • Verschiedene alte und kostenpflichtige Frameworks zur Videoaufnahme • Codecs Probleme (nur QuicktimeView)