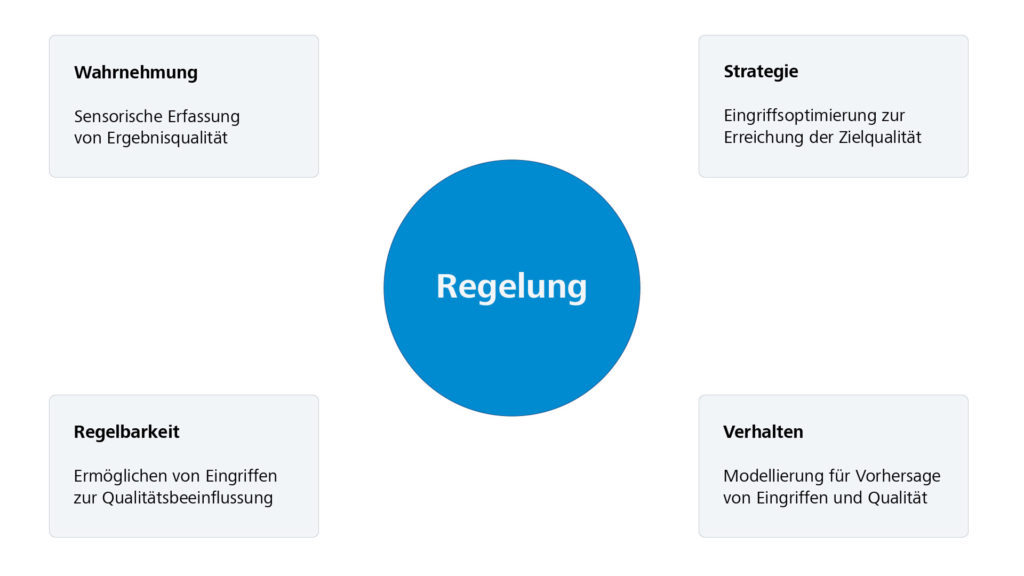
Dieser dritte und letzte Teil der Artikelserie zur datengetriebenen Prozessregelung liefert eine Einführung in Ansätze zur Regelung von Systemen. Im Mittelpunkt steht dabei das klassische „Model-Predictive-Control“ Schema, welches mit den Ergebnissen zur Systemmodellierung aus dem zweiten Artikel zu einer rein datengetriebenen Regelungsstrategie kombiniert wird.
Für die Regelung von Systemen existieren zahlreiche theoretische wie praktische Ansätze. Eine der einfachsten stellen sogenannte PID Regler dar, die in Anwendungen wie Motor- und Temperaturreglungen, Laderegelungen für Solaranlagen oder Reglern für Leistungselektronik zum Einsatz kommen.
Wir wollen uns allerdings mit einer fortgeschritteneren Regelungsstrategie für ein breiteres Anwendungsspektrum befassen, dem „Model Predictive Control (MPC)“ (siehe [3] und [4]). Wie aus der Bezeichnung zu entnehmen ist, setzt diese Strategie die Fähigkeit zur Vorhersage des Systemverhaltens voraus. Eine Anforderung, die durch Modellbildung im Sinne des vorangegangenen Abschnittes aber auch durch den vorgestellten databasierten Ansatz erfüllt werden kann.
Gegenstand der Regelungsstrategie ist die Steuerung der Ausgangszielgrößen durch Modifikation der Eingriffsgrößen, so dass erstere in einem durch Referenzdaten bestimmten Korridor verbleiben.

Die MPC Strategie stellt einen iterativen Prozess dar, der aus den drei folgenden Phasen besteht (siehe auch Abbildung 1).
- Ausgangspunkt bilden historische Daten des zu regelnden Systems. Diese bestehen zum einen aus den Werten der Eingriffsparameter in zurückliegenden Regelschritten und zum anderen aus den zugehörigen, vom System gelieferten Ausgabedaten. Da auch die Referenzdaten sich mit der Zeit verändern können, stellen auch sie einen Teil der historischen Daten dar. Diese Datenbasis repräsentiert also den Status quo des betrachteten Systems. Jede Vorhersage des Systemverhaltens muss sich nahtlos an diese Historie anfügen.
- Ausgehend vom bestehenden Systemzustand wird das Modell des Systems dazu verwendet, eine optimale Vorhersage von zukünftigen Eingriffsgrößen und zugehörigen Ausgaben zu berechnen. Das entscheidende Optimierungskriterium stellt dabei die Forderung dar, dass sich die Ausgabe des Systems im betrachteten Vorhersagezeitraum bestmöglich den gewünschten Referenzwerten annähert (siehe „Mathematischer Hintergrund“). Dabei gilt es zusätzlich, die technischen Rand- und Grenzbedingungen der Eingriffsparameter zu berücksichtigen.
- Der dritte und letzte Schritt besteht in der Anwendung der berechneten Eingriffsgrößen im System selbst. Dies entspricht einem Praxistest des zur Vorhersage verwendeten Modells. Darüber hinaus werden die vorhergesagten Eingriffsgrößen nicht über den gesamten festgelegten Vorhersagehorizont angewendet sondern nur für einige wenige Schritte. Dies erfolgt in dem Wissen, dass vom Modell unberücksichtigte Einflüsse das Feedback verfälschen und damit die Genauigkeit der Vorhersagen einschränken. Gleichzeitig sichert das Feedback die Stabilität der Strategie, da die neu gewonnenen Daten in die Datenhistorie eingehen und so die aktualisierte Basis für die nächste Vorhersage bilden.
Diese drei beschriebenen Phasen werden zyklisch durchlaufen. Die Frequenz dieses Prozesses hängt unmittelbar von den Erfordernissen des jeweiligen Anwendungsfalles ab. Insbesondere bei der Regelung von Echtzeitsystemen wie Fahr- und Flugzeugen sind hier Frequenzen von einigen 10Hz notwendig.
Mathematischer Hintergrund
Das „Model Predictive Control“ Schema beinhaltet als zentrales Element die Vorhersage der
zukünftigen Eingabeparameter  und Ausgabegrößen
und Ausgabegrößen  , welche den Abstand zu einer Referenztrajektorie
, welche den Abstand zu einer Referenztrajektorie im Vorhersagezeithoriziont
im Vorhersagezeithoriziont  minimieren. Zusätzlich sind historische Daten in Form einer Anfangstrajektorie
minimieren. Zusätzlich sind historische Daten in Form einer Anfangstrajektorie  der Länge
der Länge  gegeben, welche durch die gesuchte Trajektorie
gegeben, welche durch die gesuchte Trajektorie  fortzusetzen ist.
fortzusetzen ist.

Da die algebraische Repräsentation  des zeitbeschränkten Verhaltens
des zeitbeschränkten Verhaltens  es erlaubt, für jedes
es erlaubt, für jedes  einen Vektor
einen Vektor  zu bestimmen, für den
zu bestimmen, für den  gilt, können wir folgendes restringierte Optimierungsproblem für
gilt, können wir folgendes restringierte Optimierungsproblem für  aufstellen
aufstellen
![\[\begin{aligned} &\underset{g}{\text{minimize}} \quad \| H_{T_f} \ g - w_r \|^2_2 & \\[1.0em] &\text{subject to} \quad H_{T_\text{ini}} \ g = w_\text{ini}, & \end{aligned}\]](https://blogs.zeiss.com/digital-innovation/de/wp-content/ql-cache/quicklatex.com-12225d16ba56e218dc2d961a2e71ea00_l3.png "Rendered by QuickLaTeX.com")
unter Verwendung der Zerlegung
![\[H_L \, g = w \quad \Longleftrightarrow \quad \begin{bmatrix} H_{T_\text{ini}} \\[0.5em] H_{T_f} \end{bmatrix} \, g= \begin{bmatrix} w_\text{ini} \\[0.5em] w_f \end{bmatrix}\]](https://blogs.zeiss.com/digital-innovation/de/wp-content/ql-cache/quicklatex.com-c87146b5ba83a9fa6121cb53b383b30e_l3.png "Rendered by QuickLaTeX.com")
Die Nebenbedingung sichert dabei die Einhaltung der Anfangsbedingung und die Verwendung von  im Minimierungfunktional erzwingt, dass die ermittelte zukünftige Trajektorie
im Minimierungfunktional erzwingt, dass die ermittelte zukünftige Trajektorie  zulässig ist für das System
zulässig ist für das System  . Zusätzlich können Nebenbedingungen an formuliert werden, was aus Gründen der Übersichtlichkeit hier nicht erfolgte. Weitere Details sind in [2] und [7] ausgeführt.
. Zusätzlich können Nebenbedingungen an formuliert werden, was aus Gründen der Übersichtlichkeit hier nicht erfolgte. Weitere Details sind in [2] und [7] ausgeführt.
Die Robustheit dieses Schemas gegenüber Störungen in Form nicht modellierten Systemverhaltens kann mathematisch nachgewiesen werden. Insbesondere ist gesichert, dass das im Schritt 2 gestellte Optimierungsproblem in jedem folgenden Zyklus lösbar bleibt, sofern es im ersten lösbar war. Damit ist die unbeschränkte Ausführbarkeit des Verfahrens gesichert (siehe [5] und [6]).
Zusammenfassung
Die Regelung von physikalischen Systemen erfordert a-priori Wissen, welches durch Systemmodelle
in die Regelungsaufgabe eingeführt wird. Die üblichen Ansätze zur Modellbildung stoßen dabei auf
prinzipielle Grenzen mit wachsender Komplexität des Systems. Sie liefern allerdings während ihrer Erstellung
wesentliche theoretische Einblicke in die Struktur des Systems und benötigen nur wenig experimentelles Vorwissen.
Der vorgestellte datenbasierte Ansatz hingegen generiert eine Systemrepräsentation aus einer einzigen
Beobachtungsreihe, zu deren Gewinnung das System einer spezifischen Anregung ausgesetzt wird.
Die Vollständigkeit der erzeugten Systemrepräsentation kann anhand der bereits gewonnenen Daten
geprüft werden, was eine für ein Lernverfahren bemerkenswerte Eigenschaft darstellt.
Durch dieses Vorgehen unterliegt das Verfahren keinerlei prinzipiellen Einschränkungen hinsichtlich der Systemkomplexität, benötigt stattdessen aber spezielle empirische Daten zur Systembeschreibung.
Obwohl der neue Ansatz kein Modell im eigentlichen Sinne liefert, ist es mit der von ihm erzeugten
Systemrepräsentation möglich, spezifische Vorhersagen zum Systemverhalten zu treffen. Dabei wird nicht nur die Konvergenz gegen einen gewünschten Zielzustand realisiert, sondern werden gleichzeitig eingabe- wie ausgabeseitig technische und physikalische Restriktionen umsetzt. Dies stellt einen signifikanten Vorteil gegenüber anderen Lernverfahren dar und ermöglicht sicherheitskritische Anwendungen im Zusammenspiel mit etablierten Regelungsstrategien wie dem „Model Predictive Control“.
Ausblick
Die Darstellung des neuen datenbasierten Ansatzes hat die Behandlung zweier wesentlicher Probleme ausgespart.
Der erste Aspekt betrifft die Anwendung auf nichtlineare Systeme. Den theoretischen Voraussetzungen nach ist der datenbasierte Ansatz auf lineare zeitinvariante Systeme beschränkt. Einerseits gibt es in jüngster Zeit Versuche wie in [1] oder [4], diese Einschränkung aufzuheben. Andererseits sind die Gründe für die beobachtete erfolgreiche Regelung nichtlinearer Systeme durch das datenbasierte Vorgehen bisher noch nicht verstanden und daher Gegenstand aktueller Forschung, siehe [2].
Der zweite Aspekt bezieht sich auf die Verwendung verrauschter Beobachtungsdaten bei der Rekonstruktion des Systemverhaltens. Auch hier sind bereits wesentliche Fortschritte zur Stabilisierung datenbasierter Ansätze erzielt worden, siehe [2]. Allerdings zeigen sich andere Ansätze zur Systemidentifikation noch als deutlich unempfindlicher gegenüber Rauscheinflüssen.
Insgesamt zeichnet sich das Bild ab, dass aktuelle datenbasierte Verfahren robust gegenüber Bias-Datenfehlern sind, also Daten aus nicht linearen Systemen, und anfälliger hinsichtlich Varianz-Datenfehlern, also Datenrauschen.
Literatur
[1] Ezzat Elokda, Jeremy Coulson, Paul N. Beuchat, John Lygeros, and Florian Dörfler, „Data-enabled predictive control for quadcopters“, International Journal of Robust and Nonlinear Control, 2021
[2] Florian Dörfler, Jeremy Coulson, and Ivan Markovsky, „Bridging direct and indirect data-driven control formulations via regularizations and relaxations“, IEEE Transactions on Automatic Control, 2022
[3] James B. Rawlings, David Q. Mayne, and Moritz M. Diehl, „Model predictive control – theory, computation, and design“, Nob Hill Publishing, 2022
[4] Julian Berberich, Johannes Köhler, Matthias A. Müller, and Frank Allgöwer, „Data-driven model predictive control – closed-loop guarantees and experimental results“, at-Automatisierungstechnik, 2021
[5] Joscha Bongard, Julian Berberich, Johannes Kohler, and Frank Allgower, „Robust stability analysis of a simple data-driven model predictive control approach“, IEEE Transactions on Automatic Control, 2022
[6] Julian Berberich, Johannes Köhler, Matthias A. Müller, and Frank Allgöwer, „Stability in data-driven MPC – an inherent robustness perspective“, IEEE Conference on Decision and Control, 2022
[7] Ivan Markovsky and Florian Dörfler, „Behavioral systems theory in data-driven analysis, signal processing, andcontrol“, Annual Reviews in Control, 2021
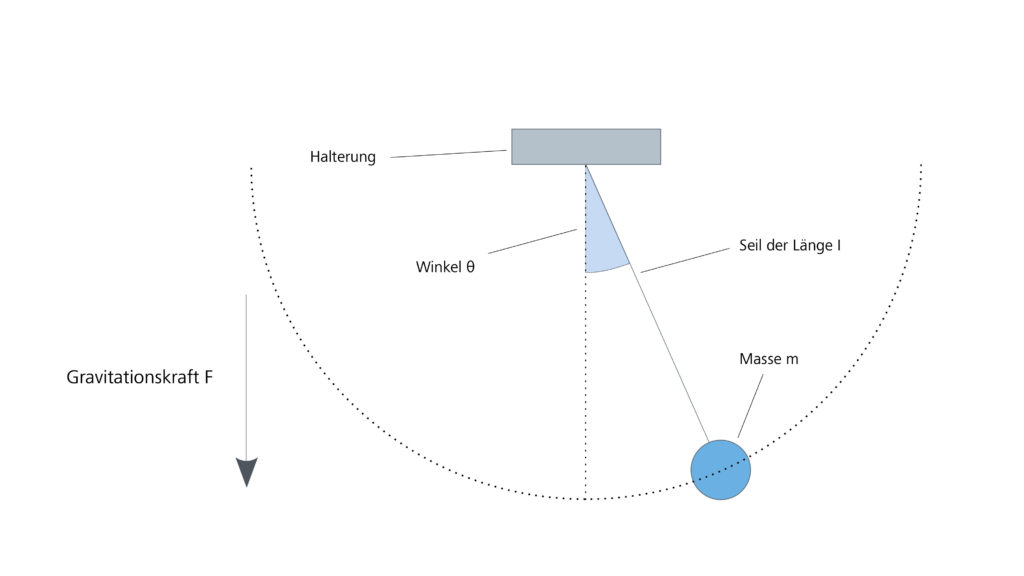
 sowie das Gravitationsgesetz Newtons spezialisiert für Körper nahe der Erdoberfläche
sowie das Gravitationsgesetz Newtons spezialisiert für Körper nahe der Erdoberfläche ![F = m \, g \, [\, 0, -1 \,]^T](https://blogs.zeiss.com/digital-innovation/de/wp-content/ql-cache/quicklatex.com-3a132a5c1402d5e00e2bbd9d9b52e617_l3.png "Rendered by QuickLaTeX.com") .
. zu betrachten, da die radiale Komponente durch das Seil kompensiert wird. Aus dem gleichen Grund ist lediglich die Tangentialbeschleunigung
zu betrachten, da die radiale Komponente durch das Seil kompensiert wird. Aus dem gleichen Grund ist lediglich die Tangentialbeschleunigung  relevant. Unter Verwendung des zeitabhängigen Ablenkungswinkels
relevant. Unter Verwendung des zeitabhängigen Ablenkungswinkels  und der Winkelbeschleunigung
und der Winkelbeschleunigung  (siehe Abbildung 3) sind die Größen
(siehe Abbildung 3) sind die Größen ![\[F_T = -m \ g \sin \theta(t) \quad \text{und} \quad a_T(t) = l \, \ddot{\theta}(t)\]](https://blogs.zeiss.com/digital-innovation/de/wp-content/ql-cache/quicklatex.com-a9fee8ecb13bc0eb877e5496c385c50f_l3.png "Rendered by QuickLaTeX.com")
 des Pendelseils und
des Pendelseils und  als der Fallbeschleunigung auf der Erde. Damit ergibt sich aus
als der Fallbeschleunigung auf der Erde. Damit ergibt sich aus  folgende Differentialgleichung für den Ablenkungswinkel
folgende Differentialgleichung für den Ablenkungswinkel  :
:

 und jede Anfangsgeschwindigkeit
und jede Anfangsgeschwindigkeit  vorherzusagen.
vorherzusagen.![x(t) = [\, \theta(t), \dot{\theta}(t) \, ]^T](https://blogs.zeiss.com/digital-innovation/de/wp-content/ql-cache/quicklatex.com-00042eeb0e6082a618959354ce55d057_l3.png "Rendered by QuickLaTeX.com") mit dem Ablenkungswinkel
mit dem Ablenkungswinkel  können die Anfangsbedingungen für die beiden Experimente angesetzt werden zu
können die Anfangsbedingungen für die beiden Experimente angesetzt werden zu![\[ x_1(0) = \left[ \begin{array}{c} 1 \\ 0 \end{array} \right] \quad \text{und} \quad x_2(0) = \left[ \begin{array}{c} 0 \\ 1 \end{array} \right]\]](https://blogs.zeiss.com/digital-innovation/de/wp-content/ql-cache/quicklatex.com-8ae5720fb4b30c8d2d1637a17bf1a007_l3.png "Rendered by QuickLaTeX.com")
 des Pendels zum Startwinkel
des Pendels zum Startwinkel  und verschwindender Startgeschwindigkeit zu diskreten Zeitpunkten
und verschwindender Startgeschwindigkeit zu diskreten Zeitpunkten  auf. Das zweite Experiment verwendet für die Aufzeichung von
auf. Das zweite Experiment verwendet für die Aufzeichung von  das dazu inverse Setting.
das dazu inverse Setting. zu den Anfangsbedingungen
zu den Anfangsbedingungen ![x(0) = [\, \theta_0, \dot{\theta}_0 \,]^T](https://blogs.zeiss.com/digital-innovation/de/wp-content/ql-cache/quicklatex.com-7f25c83af7999fc84d73631b119d374a_l3.png "Rendered by QuickLaTeX.com") mittels der Beziehung
mittels der Beziehung![\[x(t) = \theta_0 \ x_1(t) + \dot{\theta}_0 \ x_2(t)\]](https://blogs.zeiss.com/digital-innovation/de/wp-content/ql-cache/quicklatex.com-558a75ea4ad9d035368aec0945cdc0e8_l3.png "Rendered by QuickLaTeX.com")
![\[B \, x(0) = x \quad \text{mit} \quad B = \begin{bmatrix} x_1(t_1) & x_2(t_1) \\ \vdots & \vdots \\ x_1(t_n) & x_2(t_n) \end{bmatrix} \quad \text{und} \quad x = \begin{bmatrix} x(t_1) \\ \vdots \\ x(t_n) \end{bmatrix}\]](https://blogs.zeiss.com/digital-innovation/de/wp-content/ql-cache/quicklatex.com-d2ec2307253c3ed22c545ce356f552bc_l3.png "Rendered by QuickLaTeX.com")
 bezeichnen wir als algebraische Repräsentation des Pendelverhaltens.
bezeichnen wir als algebraische Repräsentation des Pendelverhaltens.



![\[\begin{aligned} x(k+1) &= A \, x(k) + B \, u(k) \\[0.5em] y(k) &= C \, x(k) + D \, u(k) \end{aligned}\]](https://blogs.zeiss.com/digital-innovation/de/wp-content/ql-cache/quicklatex.com-02b73328e934d0f914e1e0db3165e64b_l3.png "Rendered by QuickLaTeX.com")
 ,
,  , and
, and  erfüllt.
erfüllt.

![\[\dim B_L = m L + n.\]](https://blogs.zeiss.com/digital-innovation/de/wp-content/ql-cache/quicklatex.com-43143e97938da991c676d94a21b6de13_l3.png "Rendered by QuickLaTeX.com")