Nachdem wir in Teil 1 die Vorteile und Herausforderungen von Microservices in Monorepos diskutiert haben, konzentrieren wir uns nun darauf, wie Nx diese Struktur für AWS CDK-basierte Anwendungen unterstützt.
Was ist Nx?
Nx ist ein JavaScript basiertes Buildsystem für Monorepos. Es ermöglicht die effiziente Ausführung aller Aufgaben wie Build und Test über mehrere Projekte in einem Monorepo, unabhängig davon, ob NPM, Yarn oder PNPM als Paketmanager verwendet wird. Nx bietet auch einen vollständig integrierten Modus, der keine separaten package.json Dateien für jedes Projekt benötigt. Dies ermöglicht eine tiefere Integration und ist besonders interessant für UI-Anwendungen mit AngularJS oder React.
Beginnen wir mit einem einfachen Beispiel. Wenn wir das Build-Skript für Service A ausführen wollen, können wir dies wie folgt tun:
npx nx build service-a
Nun gibt es in unserem Beispiel Repository (siehe Abbildung 1, Teil 1) auch die Services B und C. Wenn wir das Build-Skript für alle Projekte im Repo ausführen wollen, gehen wir wie folgt vor:
npx nx run-many -t build
Es ist interessant zu sehen, dass dies schneller funktioniert, als wenn wir es einzeln ausführen würden. Das liegt daran, dass Nx sie parallel ausführt, wenn unsere Services so konzipiert sind, dass sie zur Build-Zeit unabhängig voneinander sind (was sie bei einem guten Design auch sein sollten).
Die Stärke von Nx zeigt sich besonders im Zusammenspiel mit der Versionsverwaltung des Git-Repositories. Es ist möglich, nur die Target Scripts der Projekte und deren Abhängigkeiten auszuführen, bei denen im Vergleich zwischen Head und Base Änderungen festgestellt wurden. Angenommen, es gibt nur Änderungen im Service B in einem Branch für einen Pull Request zum Basis-Branch „dev“. Im folgenden Beispiel würde das Build-Skript nur für Service B ausgeführt werden. Die Scripts der anderen Projekte werden nicht ausgeführt.
npx nx affected -t build
Kehren wir zum Beispiel-Repository aus Teil 1 zurück. Die package.json jedes Service enthält das entsprechende CDK deploy Skript. Für Service A sieht dieses vereinfacht so aus:
"name": "service-a ",
"version": "0.1.0",
"scripts": {
"deploy": "cdk deploy ServiceAStack …",
},
"dependencies": {
"custom-lib": "*"
}Zusätzlich haben wir eine Abhängigkeit zu einer benutzerdefinierten Bibliothek, die von allen drei Services verwendet wird. Angenommen, wir nehmen eine Änderung an dieser Bibliothek vor und führen anschließend folgenden Befehl aus:
npx nx affected -t deploy
In diesem Fall werden die Deployment-Skripte aller drei Services ausgeführt. Dies geschieht, weil sich die Bibliothek geändert hat und somit indirekt alle drei Services betroffen sind. Nx berücksichtigt also den Abhängigkeitsgraphen zwischen den einzelnen Projekten innerhalb des Monorepos. Um hier den Überblick zu behalten, bietet Nx eine nützliche Visualisierung aller im Repository enthaltenen Module und deren Abhängigkeiten. Mit dem Befehl
npx nx graph
wird lokal eine WebApp gestartet, mit deren Hilfe die Modulstrukturen und deren Abhängigkeiten untereinander im Browser untersucht werden können.
Das alles zusammen ist sehr mächtig, wenn man bedenkt, dass für praktisch jede Aufgabe wie Build, Unit Tests, Code Style Checks, Integrationstests, Audit, Deployment und vieles mehr in den Projekten entsprechende Target-Skripte in der package.json definiert werden können. Durch die konsistente Benennung dieser Skripte über die Projekte hinweg können für jede dieser Aufgaben separate automatisierte Workflows (z.B. mit GitHub Actions) bereitgestellt werden. Diese sind so allgemeingültig, dass sie nicht einmal angepasst werden müssen, wenn weitere Projekte wie Services oder Bibliotheken hinzugefügt werden. Damit haben wir ein effektives Mittel, um möglichen Problemen eines monolithischen CI/CD Prozesses zu begegnen.
Nx und AWS CDK: Passt das zusammen?
Mit AWS CDK steht uns ein Framework für Infrastructure as Code zur Verfügung, das es ermöglicht, die gesamte serverlose Infrastruktur in TypeScript zu definieren. Bei der Strukturierung wird empfohlen, sowohl den Infrastrukturcode als auch den Businesscode in einer Applikation zu vereinen. Jeder Service wird somit zu einer separaten CDK-Applikation mit eigenen Stacks.
Nx ermöglicht die einfache Organisation von AWS CDK-Applikationen in separaten Paketen. Dieses Zusammenspiel ermöglicht eine übersichtliche und gut organisierte Entwicklung von Cloud-Anwendungen, bei der AWS CDK die Infrastrukturaspekte effizient handhabt und Nx die Flexibilität bietet, die verschiedenen Teile der Anwendung in einem Monorepo zu verwalten.
Für unser Beispiel-Repository würde dies stark reduziert wie folgt aussehen:
monorepo/
├── apps/
│ ├── service-a/
│ │ ├── bin/
│ │ │ └── service-a-app.ts
│ │ ├── lib/
│ │ │ └── service-a-stack.ts
│ │ ├── cdk.json
│ │ └── package.json
│ ├── service-b/
│ │ └── …
│ ├── service-c/
│ │ └── …
│ └── ui/
│ └── …
├── libs/
│ └── custom-lib/
│ ├── index.ts
│ └── package.json
├── nx.json
└── package.jsonIn dieser Struktur gibt es auf der obersten Ebene zwei verschiedene Workspaces. Einen für alle Applikationen (service-a, service-b, service-c und ui) unterhalb des apps-Ordners. Jede Applikation folgt der empfohlenen Struktur für eine einzelne CDK-Applikation. Der zweite Workspace libs enthält die gemeinsame Bibliothek custom-lib mit ihrer eigenen Struktur und package.json. Die Datei nx.json dient zur Konfiguration von Nx und enthält lediglich Standardeinstellungen für das gesamte Monorepo.
Diese Struktur kann beliebig um weitere Services, Libraries und ganze Workspaces erweitert werden, indem einfach neue Packages hinzugefügt werden.
CI/CD leicht gemacht
In der bisherigen Struktur haben wir das Monorepo für eine Architektur aus mehreren Cloud-Native Microservices definiert, die als separate CDK-Applikationen existieren. Nx ermöglicht uns eine effiziente Verwaltung dieser Anwendungen.
Allerdings reicht es in der Praxis oft nicht aus, ein Deployment-Skript nur für ausgewählte Services effizient auszuführen. Ein gängiger Ansatz ist es, die einzelnen CDK-Stacks der Applikationen über eine AWS CodePipeline zu erstellen und in die gewünschten Ziel-Accounts der verschiedenen Stages bereitzustellen. Dieser Ansatz ist mit dem Monorepo-Ansatz vereinbar, führt jedoch dazu, dass für jede Service-Applikation eine separate Pipeline verwaltet werden muss. Dieses Vorgehen ähnelt einem Multi-Repo-Ansatz, und der Verwaltungsaufwand wächst mit der Anzahl der Services.
Eine alternative Variante besteht darin, eine einzige Pipeline aufzubauen, die alle Stacks aller Services erstellt, testet und bereitstellt. Dabei besteht jedoch das Risiko eines monolithischen, zeitaufwändigen CI/CD-Prozesses, wie im Teil 1 beschrieben. Zusätzlich gehen die Vorteile von Nx verloren, da AWS CodePipeline bisher keine Integration dafür bietet.

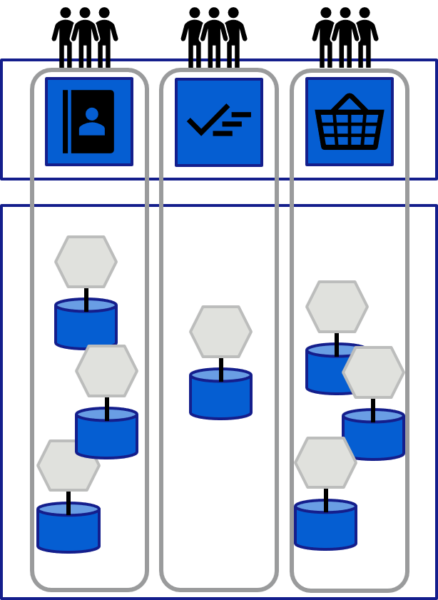
Daher möchten wir an dieser Stelle eine weitere Variante betrachten, die in Abbildung 2 dargestellt ist. Mit diesem Ansatz versuchen wir, die oben genannten Möglichkeiten zu kombinieren. Insbesondere während der Entwicklung profitieren wir stark vom Monorepo-Ansatz in Verbindung mit Nx und können viele Entwicklungsschritte automatisieren. Da wir GitHub als Repository verwenden, können viele Aufgaben für unser Monorepo als GitHub Actions implementiert werden, unter anderem das Deployment der einzelnen Service CDK Stacks in einen AWS Dev-Account. All dies basiert auf dem Nx affected-Feature und ermöglicht so eine sehr automatisierte und effiziente Entwicklungsumgebung.
Für das Deployment der Gesamtapplikation in die weiteren notwendigen Stages (QA, STG, PROD) haben wir im Monorepo zusätzlich ein Pipeline-Projekt aufgesetzt, das alle notwendigen Stacks verbindet und konfiguriert, in welche Ziel-Accounts diese je nach Stage deployt werden sollen. Dabei ist uns die atomare und native Bereitstellung innerhalb des AWS Kosmos über eine AWS CodePipeline wichtiger als die Effizienz.
Schlussfolgerung
Unsere Betrachtung hat gezeigt, dass der Entwicklungsprozess von mehreren Microservices in Monorepos mit Nx auch für CDK-Applikationen sehr effizient sein kann. Insbesondere einzelne Teams profitieren von den klaren Vorteilen des vereinfachten Dependency Managements, der erleichterten Zusammenarbeit und der einfachen Möglichkeit, umfangreiche Refactorings durchzuführen, was Monorepos zu einer attraktiven Option macht. Bei teamübergreifenden Projekten hängt der Erfolg stark davon ab, wie gut die Teams zusammenarbeiten können. Eine effektive Abstimmung auf gemeinsame Richtlinien und Patterns ist entscheidend.
Trotz der offensichtlichen Vorteile von Monorepos bleibt die Gestaltung von CI/CD-Prozessen eine Herausforderung. Durch den geschickten Einsatz geeigneter Werkzeuge können jedoch schlanke und klare Prozesse geschaffen werden. Der Monorepo-Ansatz in Kombination mit den richtigen Werkzeugen kann eine vielversprechende Möglichkeit bieten, die Entwicklung und Bereitstellung von Cloud-nativen Microservices effizient zu gestalten. Dabei gilt es, die Vorteile zu maximieren und mögliche Herausforderungen gezielt anzugehen.