Das Journal “Harvard Business Review” kürte vor ein paar Jahren “Data Scientist“ zum “Sexiest Job” des 21. Jahrhunderts [1], nicht zuletzt, weil datengetriebene Unternehmen wie Google, Amazon und Facebook enorme Gewinne verzeichnen können. Seitdem basteln moderne Unternehmen an ihrer Daten-Infrastruktur, wodurch Begriffe wie Machine Learning, Data Science und Data Mining in aller Munde sind. Aber was genau steckt hinter diesen ganzen Begriffen? Was haben sie gemeinsam, was unterscheidet sie? Und was macht eigentlich ein Data Scientist? Diese Fragen sollen nachfolgend beantwortet werden.

Buzzwords
Zunächst wollen wir versuchen, die Bedeutung einiger Schlagworte zu klären. Doch vorher sei zu beachten: Da das Themengebiet noch im Entstehen ist und sich schnell weiterentwickelt, sind viele Begriffe noch im Fluss und werden manchmal unterschiedlich verwendet. Die Begriffe werden wir am Beispiel eines fiktiven, global agierenden Logistikunternehmens „OrderNow“ veranschaulichen.
Data Science versucht, Wissen aus Daten zu generieren. Das Vorgehen von Data Scientists ist vergleichbar mit dem von Naturwissenschaftlern, die aus vielen Messdaten allgemeine Erkenntnisse ableiten. Dazu benutzen sie verschiedene Algorithmen, die im akademischen Kontext entwickelt und im industriellen Umfeld angewendet werden.
Ein wichtiges Beispiel hierzu ist die Vorhersage von Bestellungen. Aus der Buchhaltung von OrderNow weiß man, zu welchem Zeitpunkt welche Kunden was und in welcher Stückzahl bestellt haben. Ein Algorithmus eines Data Scientists analysiert diese Bestelldaten statistisch und kann dann vorhersagen, wann in der Zukunft welche Produkte in welchen Stückzahlen nachgefragt werden. Darauf vorbereitet kann OrderNow schon frühzeitig bei seinen Lieferanten bestellen und dann die eigenen Kunden schneller beliefern.
Big Data sind Datenmengen, welche zu groß, zu komplex, zu schnelllebig oder zu schwach strukturiert sind, um sie mit manuellen, herkömmlichen Methoden der Datenverarbeitung auszuwerten.
In unserem Beispiel könnten das die ständig wachsenden Bestelldaten der Vergangenheit sein.
Data Lake ist ein System von Daten, die unstrukturiert im Rohdatenformat gespeichert sind. Es werden dabei mehr Daten gespeichert als akut benötigt. In anderen Worten: ein Data Lake ist ein „Big Data“-Repository.
OrderNow besteht aus vielen Subunternehmen mit gewachsenen Strukturen. Die Bestelldaten sind manchmal Excel-Dateien und manchmal Einträge in SQL-Datenbanken.
Machine-Learning-Algorithmen lernen, ähnlich wie der Mensch, anhand von Beispielen Muster in Daten zu erkennen. Nach Abschluss der Lernphase können diese Muster in neuen Daten erkannt werden. Man spricht dabei auch von der künstlichen Generierung von Wissen aus Erfahrung. Bei der Anwendung dieser Algorithmen werden oft neuronale Netze verwendet.
Bei OrderNow wird diese Technik in der Kunden-App eingesetzt. Der Nutzer kann Objekte fotografieren, die App erkennt, um welches Produkt es sich handelt und es kann direkt bestellt werden. Ein Machine-Learning-Algorithmus hat dazu aus unzähligen kategorisierten Bilddateien gelernt, wie ein bestimmtes Produkt aussieht und kann dieses in neuen Bildern wiedererkennen.
Deep Learning ist eine spezielleMethode des Machine Learning, welche neuronale Netze mit vielen Zwischenschichten (Hidden Layers) benutzt.
Data Mining ist der Versuch, neue Querverbindungen und Trends in großen Datenbeständen zu finden. Dabei werden statistische Methoden benutzt. Aufgrund der verschiedenen Herangehensweise ist Data Mining komplementär zu Machine Learning.
Bei OrderNow nutzt man Data Mining, um seinen Kunden Produkte zu empfehlen.
Was macht ein Data Scientist?
Unter diesen Schlagworten kann Data Science als der umfassendste Begriff gesehen werden. Ein Data Scientist nutzt unter anderem Methoden wie Machine Learning oder Data Mining, um aus Daten Wissen zu generieren.
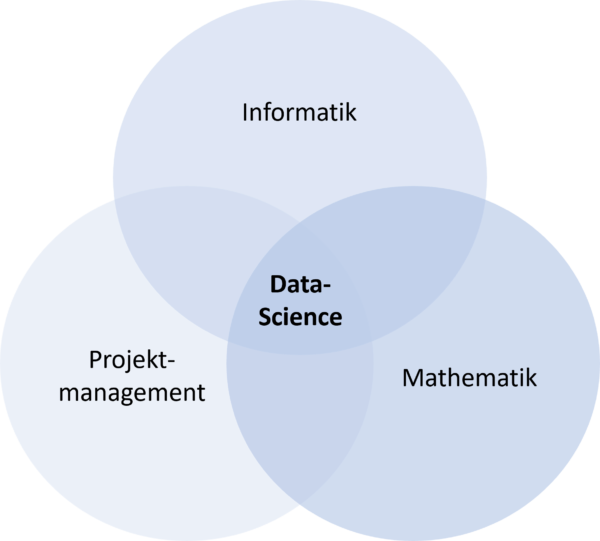
Abbildung 1: Einen Data Scientist zeichnen Wissen und Fertigkeiten aus den Bereichen Informatik, Mathematik und Projektmanagement aus.
Dazu bedarf es verschiedener Fähigkeiten, die in Abbildung 1 zusammengefasst sind. Data Scientists programmieren häufig in den Sprachen Python oder R, kennen sich mit Datenbanken aus und wissen, wie man effizient Daten verarbeitet. Sie haben ein gutes Verständnis von Mathematik und Statistik. Der wissenschaftliche Teil ihrer Arbeit besteht nicht nur im Vorgehen beim Generieren von Wissen, sondern auch darin, dass sie die Fragestellungen, die mit der Datenbasis beantwortet werden sollen, selbst formulieren. Data Scientists müssen sich außerdem mit Projektmanagement auskennen. Sie arbeiten im Team mit Experten aus der Daten-Domäne, müssen die Ergebnisse gut im Unternehmen kommunizieren und schließlich mithelfen, ihre Erkenntnisse in die Praxis zu überführen, um Mehrwerte zu schaffen.
Mit Daten Mehrwerte schaffen
Was können solche Mehrwerte sein? Erkenntnisse für Entscheidungen des Managements einerseits, Optimierungen von bestehenden Produkten anderseits – das eigentliche Ziel ist jedoch häufig die Entwicklung neuer Produkte. Damit das gelingt, müssen Softwareentwickler und Data Scientists eng zusammenarbeiten. Die Zukunft wird zeigen, wie gut es uns gelingt, dies in die Tat umzusetzen.
References
[1] Davenport and Patil, Havard Business Review, October 2012