Nachdem der erste Artikel der Serie sich mit den allgemeinen Grundbausteinen von Regelungssystemen beschäftigt hat, widmet sich der zweite Artikel der Modellierung des Verhaltens von Systemen. Dabei steht die Differenzierung verschiedener Modellierungsarten im Vordergrund. Den Hauptteil des Artikels bildet die Einführung eines speziellen datengetriebenen Ansatzes, der in jüngster Zeit wachsendes wissenschaftliches Interesse auf sich gezogen hat.
Die Kenntnis des Systemverhaltens, d. h. das Wissen um die quantitative Veränderung der Ausgaben bei Veränderung der Eingaben des Systems, ist eine Grundvoraussetzung für die Systemregelung. Dieses Wissen wird durch Verhaltensmodelle repräsentiert, deren Entwicklung wir in diesem Artikel näher untersuchen wollen.
Ein physikalisches Bespielsystem
Als einfaches physikalisches Beispiel betrachten wir ein sogenanntes ideales ebenes Pendel. Die Pendelmasse wird als punktförmig und an einem masselosen Seil aufgehängt angenommen, alle Reibungskräfte bleiben unberücksichtigt. Die einzige auf die Masse wirkende Kraft ist die Gravitationskraft der Erde (siehe Abbildung 3).
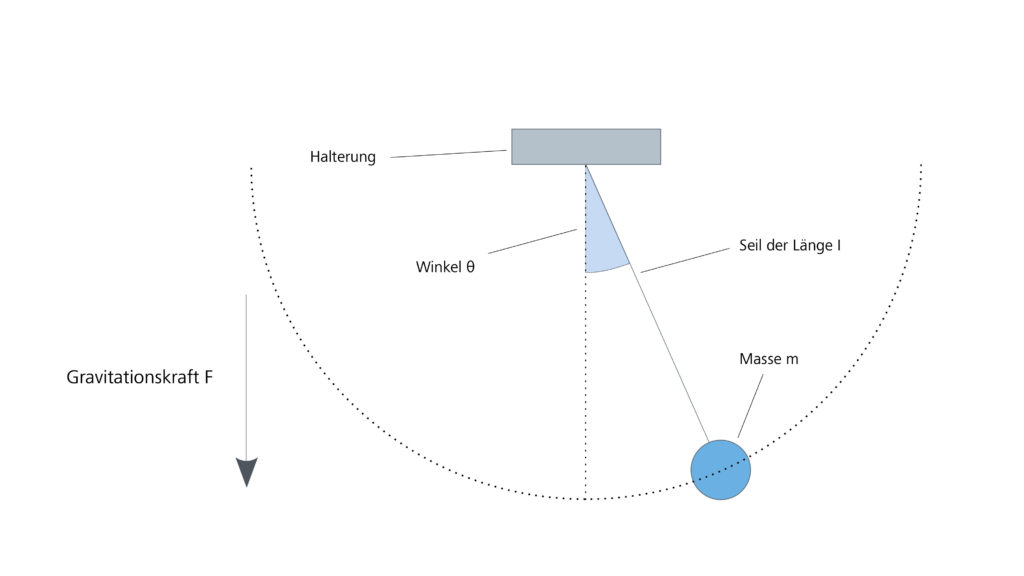
An diesem Beispiel werden wir drei grundlegende Modellierungsarten beschreiben.
Whitebox Modellierung
Bei dieser Art der Modellierung wird das Systemverhalten durch Differentialgleichungen repräsentiert, deren Parameter vollständig bekannt sind. Der Ansatz ist hochgradig anwendungsfallspezifisch und erfordert ein hohes Maß an Detailwissen zum betrachteten System. Die Komplexität realer Systeme setzt der Anwendung dieses Ansatzes natürlicherweise Grenzen. Zusätzlich ist die Herangehensweise schwer automatisierbar und die erhaltenen Modelle sind nur mit großem Aufwand an veränderte Anforderungen anpassbar.
Beispiel – Whitebox Modellierung des Pendelsystems
Ausgangspunkt bilden das zweite Newtonsche Gesetz  sowie das Gravitationsgesetz Newtons spezialisiert für Körper nahe der Erdoberfläche
sowie das Gravitationsgesetz Newtons spezialisiert für Körper nahe der Erdoberfläche ![F = m \, g \, [\, 0, -1 \,]^T](https://blogs.zeiss.com/digital-innovation/de/wp-content/ql-cache/quicklatex.com-3a132a5c1402d5e00e2bbd9d9b52e617_l3.png "Rendered by QuickLaTeX.com") .
.
Für die Bewegung des Pendels ist lediglich die tangential an die Pendelmasse angreifende Kraft  zu betrachten, da die radiale Komponente durch das Seil kompensiert wird. Aus dem gleichen Grund ist lediglich die Tangentialbeschleunigung
zu betrachten, da die radiale Komponente durch das Seil kompensiert wird. Aus dem gleichen Grund ist lediglich die Tangentialbeschleunigung  relevant. Unter Verwendung des zeitabhängigen Ablenkungswinkels
relevant. Unter Verwendung des zeitabhängigen Ablenkungswinkels  und der Winkelbeschleunigung
und der Winkelbeschleunigung  (siehe Abbildung 3) sind die Größen und gegeben als
(siehe Abbildung 3) sind die Größen und gegeben als
![\[F_T = -m \ g \sin \theta(t) \quad \text{und} \quad a_T(t) = l \, \ddot{\theta}(t)\]](https://blogs.zeiss.com/digital-innovation/de/wp-content/ql-cache/quicklatex.com-a9fee8ecb13bc0eb877e5496c385c50f_l3.png "Rendered by QuickLaTeX.com")
mit der Länge  des Pendelseils und
des Pendelseils und  als der Fallbeschleunigung auf der Erde. Damit ergibt sich aus
als der Fallbeschleunigung auf der Erde. Damit ergibt sich aus  folgende Differentialgleichung für den Ablenkungswinkel
folgende Differentialgleichung für den Ablenkungswinkel  :
:

Wenn wir zusätzlich den Winkel als klein annehmen, erhalten wir als weitere Vereinfachung

Diese Differentialgleichung kann dazu verwendet werden, das Verhalten des Pendels für jeden Anfangswinkel  und jede Anfangsgeschwindigkeit
und jede Anfangsgeschwindigkeit  vorherzusagen.
vorherzusagen.
Grey- and Blackbox Modellierung
Dieser Modellierungszugang führt ebenfalls auf Differential- oder Differenzengleichungen, die allerdings lediglich die grundlegende Struktur des Systems vorgeben und daher freie Parameter enthalten. Fließt in das Systemmodell Vorwissen, z. B. in Form von physikalischen Prinzipien ein, so handelt es sich um ein Grey-Box Model, anderenfalls wird von einem Black-Box Model gesprochen.
Die freien Parameter des Modells werden in einem Adaptionsschritt aus Beobachtungsdaten des Systems bestimmt, wobei dieser Schritt der Modellbildung weitgehend automatisiert werden kann. Die Auswahl der Modellstruktur hingegen erweist sich als kritisch für die Qualität des Modells, erfordert aufgrund seiner Komplexität ein hohes Maß an Erfahrung und kann daher nur bedingt automatisiert werden. Darüber hinaus können Grey- und Blackbox Modelling im Gegensatz zum White-Box Ansatz auf beliebig komplexe Systeme angewendet werden.
Daten basierte Modellierung
Dieser neue Ansatz zieht seit einigen Jahren zunehmend Aufmerksamkeit auf sich. Ausgangspunkt ist der Gedanke, ein System ausschließlich mit seinem von außen verifizierbaren Verhalten zu identifizieren. Eine ausführliche Darstellung des systemtheoretischen Hintergrundes für diesen Ansatz findet sich in [1]. Mit der zunehmenden Verfügbarkeit von Prozessdaten technischer Systeme wandelte sich die Sicht auf diese datengetriebene Betrachtungsweise. Es wurde erkannt, dass die Beschreibung des Systemverhaltens rein auf der Basis von Beobachtungen die Tür zu neuen Modellen und Algorithmen öffnete (siehe [2] und [3]). Diese Entwicklung ist vergleichbar mit den Entwicklungen bei der Anwendung von neuronalen Netzen in den vergangenen Jahren.
Da es sich um ein nicht-überwachtes Lernverfahren für nicht-parametrische Modelle handelt, wird im Gegensatz zum White-, Grey- und Black-Box Modelling kein Modell des Systems konstruiert. Damit unterliegt die Anwendbarkeit dieser Herangehensweise weder einer komplexitätsbedingten Einschränkung, noch verhindert die Notwendigkeit einer Strukturentscheidung seine Automatisierung. Allerdings ist es dem Ansatz nach zunächst auf sogenannte lineare und zeitinvariante Systeme beschränkt (siehe „Mathematischer Hintergrund“).
Beispiel – Datenbasierte Modellierung des Pendelsystems
Um eine datenbasierte Repräsentation für das Pendelsystem zu erhalten, benötigen wir lediglich zwei Experimente. Unter Verwendung der Bezeichnung ![x(t) = [\, \theta(t), \dot{\theta}(t) \, ]^T](https://blogs.zeiss.com/digital-innovation/de/wp-content/ql-cache/quicklatex.com-00042eeb0e6082a618959354ce55d057_l3.png "Rendered by QuickLaTeX.com") mit dem Ablenkungswinkel und der Winkelgeschwindigkeit
mit dem Ablenkungswinkel und der Winkelgeschwindigkeit  können die Anfangsbedingungen für die beiden Experimente angesetzt werden zu
können die Anfangsbedingungen für die beiden Experimente angesetzt werden zu
![\[ x_1(0) = \left[ \begin{array}{c} 1 \\ 0 \end{array} \right] \quad \text{und} \quad x_2(0) = \left[ \begin{array}{c} 0 \\ 1 \end{array} \right]\]](https://blogs.zeiss.com/digital-innovation/de/wp-content/ql-cache/quicklatex.com-8ae5720fb4b30c8d2d1637a17bf1a007_l3.png "Rendered by QuickLaTeX.com")
Das erste Experiment zeichnet die Bewegung  des Pendels zum Startwinkel
des Pendels zum Startwinkel  und verschwindender Startgeschwindigkeit zu diskreten Zeitpunkten
und verschwindender Startgeschwindigkeit zu diskreten Zeitpunkten  auf. Das zweite Experiment verwendet für die Aufzeichung von
auf. Das zweite Experiment verwendet für die Aufzeichung von  das dazu inverse Setting.
das dazu inverse Setting.
Aus den Aufzeichnungen der beiden Experimente kann dann jede andere Pendelbewegung  zu den Anfangsbedingungen
zu den Anfangsbedingungen ![x(0) = [\, \theta_0, \dot{\theta}_0 \,]^T](https://blogs.zeiss.com/digital-innovation/de/wp-content/ql-cache/quicklatex.com-7f25c83af7999fc84d73631b119d374a_l3.png "Rendered by QuickLaTeX.com") mittels der Beziehung
mittels der Beziehung
![\[x(t) = \theta_0 \ x_1(t) + \dot{\theta}_0 \ x_2(t)\]](https://blogs.zeiss.com/digital-innovation/de/wp-content/ql-cache/quicklatex.com-558a75ea4ad9d035368aec0945cdc0e8_l3.png "Rendered by QuickLaTeX.com")
zu den Zeitpunkten berechnet werden, wofür die lineare Unabhängigkeit der Vektoren der beiden Anfangsbedingungen die Grundlage darstellt. In kompakter Form erhalten wir weiter die Darstellung
![\[B \, x(0) = x \quad \text{mit} \quad B = \begin{bmatrix} x_1(t_1) & x_2(t_1) \\ \vdots & \vdots \\ x_1(t_n) & x_2(t_n) \end{bmatrix} \quad \text{und} \quad x = \begin{bmatrix} x(t_1) \\ \vdots \\ x(t_n) \end{bmatrix}\]](https://blogs.zeiss.com/digital-innovation/de/wp-content/ql-cache/quicklatex.com-d2ec2307253c3ed22c545ce356f552bc_l3.png "Rendered by QuickLaTeX.com")
Die Matrix  bezeichnen wir als algebraische Repräsentation des Pendelverhaltens.
bezeichnen wir als algebraische Repräsentation des Pendelverhaltens.
Die Zielstellung, das vollständige Systemverhalten allein aus Beobachtungsdaten zu rekonstruieren, wirft drei wesentliche Fragen auf:
- Welche Daten eignen sich zur Verhaltensrepräsentation?
- Wie kann diese Eignung überprüft werden?
- Welchen Umfang müssen die gesammelten Daten besitzen?
Die mathematische Theorie gibt hier eindeutige Antworten (siehe „Mathematischer Hintergrund“). Wir wollen uns an dieser Stelle auf die Feststellung beschränken, dass die erhobenen Daten eine mathematisch exakt definierte Unabhängigkeit besitzen müssen (siehe Beispiel – Datenbasierte Modellierung des Pendelsystems). Solche Daten lassen sich nur gewinnen, indem das System in systematischer Art und Weise angeregt wird, da physikalische Systeme natürlicherweise dazu tendieren, ohne solche Störungen nach einiger Zeit in einen Gleichgewichtszustand überzugehen.
Die notwendige Vorgehensweise besteht daher darin, im Beobachtungszeitraum das System mittels zufälliger Eingaben anzuregen und damit ein möglichst breit gefächertes Verhalten in den Ausgaben zu induzieren (siehe Abbildung 4). Dabei ist zu beachten, dass diese Systemanregung unter Einhaltung der technischen Rand- und Grenzbedingungen des Systems erfolgen muss, um eine Destabilisierung mit ggf. schwerwiegenden Konsequenzen zu vermeiden.

In regelmäßigen Abständen wird mittels eines Dimensionskriteriums geprüft, ob die gesammelten Daten die Gesamtheit der möglichen Systemreaktionen bereits erfassen. Diese Prüfung erfordert die Angabe der gewünschten bzw. vermuteten Systemkomplexität (siehe „Mathematischer Hintergrund“), was die Möglichkeit beinhaltet, diese auf ein gewünschtes Maß zu begrenzen. Besitzt die bisher gesammelte Datenmenge noch nicht die geforderte Komplexität, so werden erneut Zufallseingabedaten erzeugt und das Experiment wiederholt.
Im Ergebnis dieses Vorgehens wird aus den gesammelten Beobachtungsdaten eine Systemrepräsentation erzeugt. Neben der dynamischen Anpassbarkeit der Komplexität der Systemrepräsentation ist der entscheidende Vorteil dieses Verfahrens, dass der beschriebene Vorgang vollständig automatisiert und damit bei Bedarf autonom wiederholt werden kann.
Die gewonnene Repräsentation des Systemverhaltens kann nun analog zu dem im Beispiel „Datenbasierte Modellierung des Pendelsystems“ angedeuteten Vorgehen dazu verwendet werden, Vorhersagen zum Systemverhalten zu treffen. Ein Beispiel für die Anwendung des Verfahrens zur Lageregelung von Quadcoptern findet sich in [4].
Mathematischer Hintergrund
Der betrachtete Prozess wird als lineares und zeitinvariantes dynamisches System 



![\[\begin{aligned} x(k+1) &= A \, x(k) + B \, u(k) \\[0.5em] y(k) &= C \, x(k) + D \, u(k) \end{aligned}\]](https://blogs.zeiss.com/digital-innovation/de/wp-content/ql-cache/quicklatex.com-02b73328e934d0f914e1e0db3165e64b_l3.png "Rendered by QuickLaTeX.com")
mit  ,
,  , and
, and  erfüllt.
erfüllt.
Das Verhalten 


![\[\dim B_L = m L + n.\]](https://blogs.zeiss.com/digital-innovation/de/wp-content/ql-cache/quicklatex.com-43143e97938da991c676d94a21b6de13_l3.png "Rendered by QuickLaTeX.com")
Im Rahmen des Identifikationsprozesses wird durch Beobachtung und Anregung des Systems eine Matrix  gebildet, deren Spalten Trajektorien der Länge entsprechen. Das Wissen um die Dimension von ermöglicht die Einscheidung zum Stopp der Datenakquise
gebildet, deren Spalten Trajektorien der Länge entsprechen. Das Wissen um die Dimension von ermöglicht die Einscheidung zum Stopp der Datenakquise
durch die Überprüfung, ob die bereits gesammelten Spalten von einen hinreichend hochdimensionalen
Unterraum aufspannen.
Die Anzahl der inneren Zustände des Systems gilt als ein Komplexitätsmaß für das zu identifizierende
System und kann dazu verwendet werden, die Komplexiät der empirisch bestimmten Systemrepräsentation von zu begrenzen, um die Genauigkeit der Approximation den Erfordernissen anzupassen.
Nachdem wir uns mit der Entwicklung von Systemmodellen insbesondere für den rein datengetriebenen Fall vertraut gemacht haben, werden wir uns im folgenden Artikel dem Thema Regelung zuwenden. Dabei wird speziell eine Strategie im Vordergrund stehen, die sich besonders für die Regelung hochkomplexer Systeme eignet, d. h. für Systeme mit einer großen Anzahl an Eingriffs- und Zielgrößen.
Literatur
[1] Jan C. Willems, „Paradigms and puzzles in the theory of dynamical systems“, IEEE Transactions on Automatic Control, 1991
[2] Ivan Markovsky, Linbin Huang, and Florian Dörfler, „Data driven control based on the behavioral approach – from theory to applications in power systems“, IEEE Control Systems, 2022
[3] Ivan Markovsky and Florian Dörfler, „Behavioral systems theory in data-driven analysis, signal processing, and control“, Annual Reviews in Control, 2021
[4] Ezzat Elokda, Jeremy Coulson, Paul N. Beuchat, John Lygeros, and Florian Dörfler, „Data-enabled predictive control for quadcopters“, International Journal of Robust and Nonlinear Control, 2021