This third and last part of the article series on data-driven process control provides an introduction to approaches for controlling systems. The focus is on the classic “model-predictive-control” scheme, which is combined with the results for system modeling from the second article to form a purely data-driven control strategy.
There are numerous theoretical and practical approaches to controlling systems. One of the simplest is the PID controller, which is used in applications such as motor and temperature control, charge control for solar systems or control units for power electronics.
However, we want to look at a more advanced control strategy for a wider range of applications, namely “Model Predictive Control (MPC)” (see [3] and [4]). As is evident from the name, this strategy presupposes the ability to predict the behaviour of the system. A requirement that can be fulfilled by modelling as described in the previous section, but also by the data-based approach presented.
The purpose of the control strategy is to control the output target variables by modifying the intervention variables so that the former remain in a range determined by reference data.
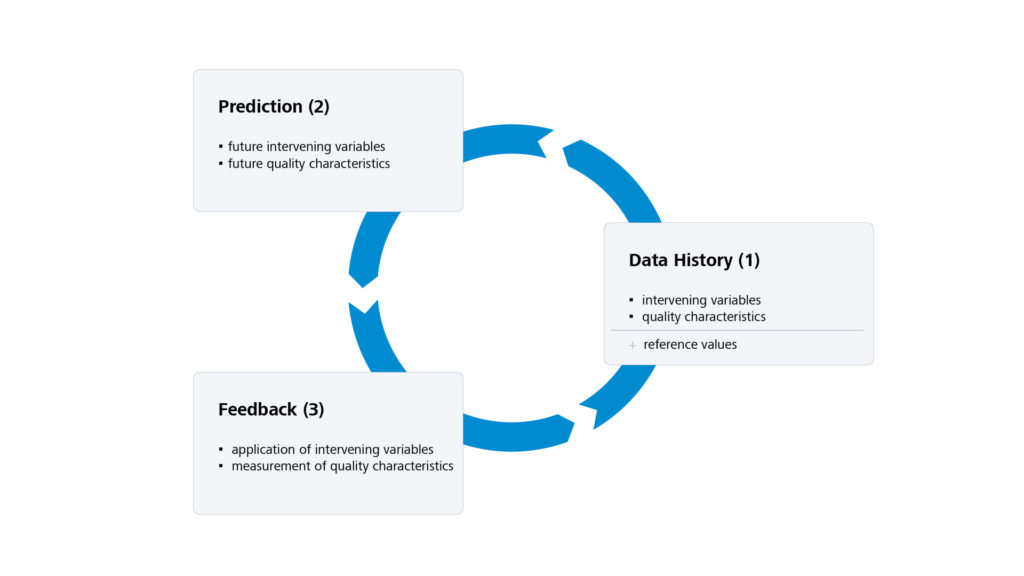
The MPC strategy is an iterative process consisting of the following three phases (see also Figure 1).
- The starting point is the historical data of the system to be controlled. This consists, firstly, of the values of the intervention parameters in previous control steps and, secondly, of the associated output data provided by the system. Since the reference data can also change over time, this makes up part of the historical data as well. This data base represents the status quo of the system under consideration. Any prediction of system behaviour must fit seamlessly into this history.
- Starting with the existing system state, the model of the system is used to calculate an optimal prediction of future intervention variables and associated outputs. In this context, the decisive optimisation criterion is the requirement that the output of the system approximates the desired reference values as closely as possible in the prediction period under consideration (see “Mathematical background”). In addition, the technical boundary and limit conditions of the intervention parameters must be taken into account.
- The third and final step is to apply the calculated intervention variables in the system itself. This takes the form of a practical test of the model used for prediction. Furthermore, the predicted intervention variables are not applied over the entire prediction horizon, but only for a few steps. This is done in the knowledge that any influences not taken into account by the model will falsify the feedback and thus limit the accuracy of the predictions. At the same time, the feedback ensures the robustness of the strategy, as the newly acquired data is incorporated into the data history and thus forms the updated basis for the next prediction.
The three phases described are run through cyclically. The frequency of this process is directly dependent on the requirements of the particular application. Especially in the case of controlling real-time systems such as vehicles and aircraft, frequencies in the 10 Hz range or beyond are necessary.
Mathematical background
The central element of the “Model Predictive Control” scheme is the prediction of future input parameters  and output variables
and output variables  , which minimise the distance to a reference trajectory
, which minimise the distance to a reference trajectory  in the prediction time horizon
in the prediction time horizon  . In addition, historical data is given in the form of an initial trajectory
. In addition, historical data is given in the form of an initial trajectory  of length
of length  , which is to be extended by the sought trajectory
, which is to be extended by the sought trajectory  .
.

Since the algebraic representation  of the time-restricted behaviour
of the time-restricted behaviour  allows to determine a vector
allows to determine a vector  for each
for each  , to which
, to which  applies, we can formulate the following constrained optimisation problem for
applies, we can formulate the following constrained optimisation problem for 
![\[\begin{aligned} &\underset{g}{\text{minimize}} \quad \| H_{T_f} \ g - w_r \|^2_2 & \\[1.0em] &\text{subject to} \quad H_{T_\text{ini}} \ g = w_\text{ini}, & \end{aligned}\]](https://blogs.zeiss.com/digital-innovation/en/wp-content/ql-cache/quicklatex.com-12225d16ba56e218dc2d961a2e71ea00_l3.png "Rendered by QuickLaTeX.com")
using the decomposition
![\[H_L \, g = w \quad \Longleftrightarrow \quad \begin{bmatrix} H_{T_\text{ini}} \\[0.5em] H_{T_f} \end{bmatrix} \, g= \begin{bmatrix} w_\text{ini} \\[0.5em] w_f \end{bmatrix}\]](https://blogs.zeiss.com/digital-innovation/en/wp-content/ql-cache/quicklatex.com-c87146b5ba83a9fa6121cb53b383b30e_l3.png "Rendered by QuickLaTeX.com")
The constraint ensures compliance with the initial condition and the use of  in the minimisation functional ensures that the determined future trajectory
in the minimisation functional ensures that the determined future trajectory  is permissible for the system
is permissible for the system  . In addition, constraints on can be formulated, which was not done in this case for reasons of clarity. Further details are provided in [2] and [7].
. In addition, constraints on can be formulated, which was not done in this case for reasons of clarity. Further details are provided in [2] and [7].
The robustness of this scheme to disturbances in the form of non-modelled system behaviour can be proven mathematically. In particular, it is ensured that the optimisation problem posed in step 2 remains solvable in each subsequent cycle, provided it was solvable in the first cycle. This guarantees that the procedure can be carried out without any restrictions (see [5] and [6]).
Summary
Control of physical systems requires a priori knowledge, which is introduced into the control task by system models. Conventional approaches to modelling encounter fundamental limits as the complexity of the system increases. However, they provide essential theoretical insights into the structure of the system during their creation and require only little prior experimental knowledge.
The data-based approach presented here, on the other hand, generates a system representation from a single series of observations obtained by subjecting the system to a specific type of stimulation. The completeness of the system representation generated can be checked against the data already obtained, which is a remarkable feature for a learning procedure. This approach means that the method is not subject to any fundamental restrictions with regard to system complexity, but instead requires special empirical data for system description purposes.
Although the new approach does not deliver a model in the true sense, the system representation it generates allows specific predictions to be made about the system’s behaviour. Not only is convergence towards a desired target state achieved, but technical and physical restrictions are also implemented on the input and output sides. This represents a significant advantage over other learning methods and facilitates safety-critical applications in conjunction with established control strategies such as “Model Predictive Control”.
Outlook
The presentation of the new data-based approach has left out the treatment of two major problems.
The first aspect concerns the application to non-linear systems. According to theoretical requirements, the data-based approach is limited to linear time-invariant systems. On the one hand, there have been recent attempts, as in [1] or [4], to overcome this limitation. On the other hand, the reasons why the data-based approach has proven successful in controlling non-linear systems are not yet understood and are therefore the subject of current research, see [2].
The second aspect relates to the use of noisy observation data in the reconstruction of system behaviour. Here, too, significant progress has already been made towards stabilising data-based approaches, see [2]. Nevertheless, other approaches to system identification are still proving to be far less sensitive to noise influences.
Overall, the picture emerges that current data-based methods are robust against bias data errors, i.e. data from non-linear systems, and more vulnerable to variance data errors, i.e. data noise.
Literature
[1] Ezzat Elokda, Jeremy Coulson, Paul N. Beuchat, John Lygeros, and Florian Dörfler, “Data-enabled predictive control for quadcopters”, International Journal of Robust and Nonlinear Control, 2021
[2] Florian Dörfler, Jeremy Coulson, and Ivan Markovsky, “Bridging direct and indirect data-driven control formulations via regularizations and relaxations”, IEEE Transactions on Automatic Control, 2022
[3] James B. Rawlings, David Q. Mayne, and Moritz M. Diehl, “Model predictive control – theory, computation, and design”, Nob Hill Publishing, 2022
[4] Julian Berberich, Johannes Köhler, Matthias A. Müller, and Frank Allgöwer, “Data-driven model predictive control – closed-loop guarantees and experimental results”, at-Automatisierungstechnik, 2021
[5] Joscha Bongard, Julian Berberich, Johannes Kohler, and Frank Allgower, “Robust stability analysis of a simple data-driven model predictive control approach”, IEEE Transactions on Automatic Control, 2022
[6] Julian Berberich, Johannes Köhler, Matthias A. Müller, and Frank Allgöwer, “Stability in data-driven MPC – an inherent robustness perspective”, IEEE Conference on Decision and Control, 2022
[7] Ivan Markovsky and Florian Dörfler, “Behavioral systems theory in data-driven analysis, signal processing, andcontrol”, Annual Reviews in Control, 2021

 and Newton’s law of gravitation, specifically for bodies near the Earth’s surface
and Newton’s law of gravitation, specifically for bodies near the Earth’s surface ![F = m \, g \, [\, 0, -1 \,]^T](https://blogs.zeiss.com/digital-innovation/en/wp-content/ql-cache/quicklatex.com-3a132a5c1402d5e00e2bbd9d9b52e617_l3.png "Rendered by QuickLaTeX.com") . In terms of the motion of the pendulum, only the force
. In terms of the motion of the pendulum, only the force  acting tangentially on the pendulum mass is to be considered, since the radial component is compensated by the cord. For the same reason, only the tangential acceleration
acting tangentially on the pendulum mass is to be considered, since the radial component is compensated by the cord. For the same reason, only the tangential acceleration  is relevant. Using the time-dependent deflection angle
is relevant. Using the time-dependent deflection angle  and the angular acceleration
and the angular acceleration  (see Figure 3), the variables
(see Figure 3), the variables ![\[F_T = -m \ g \sin \theta(t) \quad \text{and} \quad a_T(t) = l \, \ddot{\theta}(t)\]](https://blogs.zeiss.com/digital-innovation/en/wp-content/ql-cache/quicklatex.com-f7a94bdf0c3db04d6cdec2913372bc18_l3.png "Rendered by QuickLaTeX.com")
 of the pendulum cord and
of the pendulum cord and  as the gravitational acceleration on Earth. Therefore,
as the gravitational acceleration on Earth. Therefore,  results in the following differential equation for the deflection angle
results in the following differential equation for the deflection angle 
![\[\ddot{\theta} (t) = - \frac{g}{l} \ \sin \theta(t)\]](https://blogs.zeiss.com/digital-innovation/en/wp-content/ql-cache/quicklatex.com-364ff111e2b16dbb65b1a5b9e5922561_l3.png "Rendered by QuickLaTeX.com")
![\[\ddot{\theta} (t) = - \frac{g}{l} \ \theta(t)\]](https://blogs.zeiss.com/digital-innovation/en/wp-content/ql-cache/quicklatex.com-28f90592f6b8c256665c4aa05158a64e_l3.png "Rendered by QuickLaTeX.com")
 and any initial velocity
and any initial velocity  .
.![x(t) = [\, \theta(t), \dot{\theta}(t) \, ]^T](https://blogs.zeiss.com/digital-innovation/en/wp-content/ql-cache/quicklatex.com-00042eeb0e6082a618959354ce55d057_l3.png "Rendered by QuickLaTeX.com") with the deflection angle
with the deflection angle  , the initial conditions for the two experiments can be taken as
, the initial conditions for the two experiments can be taken as![\[x_1(0) = \begin{bmatrix} 1 \\ 0 \\ \end{bmatrix} \quad \text{and} \quad x_2(0) = \begin{bmatrix} 0 \\ 1 \\ \end{bmatrix}\]](https://blogs.zeiss.com/digital-innovation/en/wp-content/ql-cache/quicklatex.com-df54785fc76d8f96d442f82d79463531_l3.png "Rendered by QuickLaTeX.com")
 of the pendulum at the starting angle
of the pendulum at the starting angle  and vanishing starting velocity at discrete points in time
and vanishing starting velocity at discrete points in time  . The second experiment uses the inverse setting for recording
. The second experiment uses the inverse setting for recording  .
.
![x(0) = [\, \theta_0, \dot{\theta}_0 \,]^T](https://blogs.zeiss.com/digital-innovation/en/wp-content/ql-cache/quicklatex.com-7f25c83af7999fc84d73631b119d374a_l3.png "Rendered by QuickLaTeX.com")
![\[x(t) = \theta_0 \ x_1(t) + \dot{\theta}_0 \ x_2(t)\]](https://blogs.zeiss.com/digital-innovation/en/wp-content/ql-cache/quicklatex.com-558a75ea4ad9d035368aec0945cdc0e8_l3.png "Rendered by QuickLaTeX.com")
![\[B \, x(0) = x \quad \text{with} \quad B = \begin{bmatrix} x_1(t_1) & x_2(t_1) \\ \vdots & \vdots \\ x_1(t_n) & x_2(t_n) \end{bmatrix} \quad \text{and} \quad x = \begin{bmatrix} x(t_1) \\ \vdots \\ x(t_n) \end{bmatrix}\]](https://blogs.zeiss.com/digital-innovation/en/wp-content/ql-cache/quicklatex.com-623ed99891a8562a9cb17562bca8acb7_l3.png "Rendered by QuickLaTeX.com")
 an algebraic representation of the pendulum behavior.
an algebraic representation of the pendulum behavior.
 input parameters,
input parameters,  output variables and
output variables and  internal states and satisfies a difference equation of the form
internal states and satisfies a difference equation of the form![\[\begin{aligned} x(k+1) &= A \, x(k) + B \, u(k) \\[0.5em] y(k) &= C \, x(k) + D \, u(k) \end{aligned}\]](https://blogs.zeiss.com/digital-innovation/en/wp-content/ql-cache/quicklatex.com-02b73328e934d0f914e1e0db3165e64b_l3.png "Rendered by QuickLaTeX.com")
 ,
,  , and
, and  .
. , the time-restricted version
, the time-restricted version  , is identified with a finite-dimensional vector space of the dimension
, is identified with a finite-dimensional vector space of the dimension![\[\dim B_L = m L + n.\]](https://blogs.zeiss.com/digital-innovation/en/wp-content/ql-cache/quicklatex.com-43143e97938da991c676d94a21b6de13_l3.png "Rendered by QuickLaTeX.com")