Databases, and relational databases in particular, play an important role in just about every business environment. They are used to manage both the master data of employees, clients, etc. and the constantly changing transaction data of the company. The requirements for the respective companies may change for a variety of reasons so that the changes in the transaction data, such as bookings in a system, have to be processed in real time in different processes and applications. Regular polling of a source table by an application is no longer sufficient for this purpose. Instead, the application has to be notified of change events in a table, and the information has to be provided to the application in processed form immediately.
Using Debezium and the Apache Kafka streaming platform makes this possible.
Capturing changes in the data
First, let us briefly lay out the basic possibilities of capturing changes in the data in relational databases. The relevant literature describes four methods summarized under the term Change Data Capture. These methods will be presented below.
The easiest way to capture changes is a line-by-line and column-by-column comparison of the database table with an older version of the same. Obviously, this algorithm is not particularly efficient, especially for larger tables, but easy to implement. Selecting only the changed datasets by means of a well-executed SQL query is another option. In practice, time stamps are most commonly used to indicate the data and time of the last change for each dataset. When you search for data changes in the table, you can select all the datasets where the time stamp is more recent than the date and time of the last comparison. A minimal SQL statement could, for example, look like this:
SELECT * FROM [source_table] WHERE last_updated < [datetime_of_last_comparison]
The problem with this approach is that the database table must already include a column for such time stamps, which will likely not always be the case. In other words, there are certain requirements for the data schema. Furthermore, it is very difficult to capture deleted datasets with this method because their time stamps are deleted as well.
A third option that can solve this problem is implementing a database trigger that is activated by every INSERT, UPDATE and DELETE on the table. In addition, monitoring changes to the database schema by means of a trigger is also conceivable. Such a trigger could then write the captured data changes to a table specifically dedicated for this purpose.
The fourth and last option, the so-called log scanning, plays a particularly important role in this blog post. Most database management systems (DBMS) keep a transaction log that records all the changes made to the database. This is primarily used to restore the consistent state of the database after a failure, e.g. due to a power outage or damage to the physical data carrier. For the change data capture, we have to somewhat repurpose the transaction log: By reading the log file, it is possible to capture changes in the datasets of a specific source table and to process them.
The big advantage of log scanning is the fact that reading the transaction log does not generate any overhead in the database the way querying or executing a trigger after each change does. Consequently, it does not compromise the performance of the database. Furthermore, all kinds of changes in the data can be captured: inserts, updates and deletions of datasets as well as changes to the data schema. Unfortunately, the structure of such transaction logs is not standardized. The look of the log files of different database vendors vary considerably, and sometimes even different versions of the same database management system differ. If you want to capture data changes from several databases provided by different vendors, several algorithms need to be implemented.
This is where Debezium comes in.
What is Debezium?
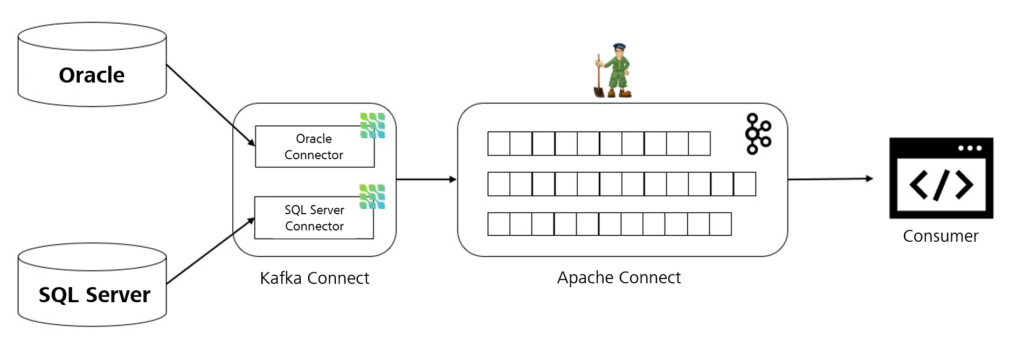
Debezium is not actually stand-alone software, but a platform for connectors that implement the change data capture for various databases. The connectors use log scanning to capture the data changes and forward them to the Apache Kafka streaming platform.
Each connector represents the software of a specific DBMS that is able to establish a connection to the database and read the change data there. The exact operating principle of each connector differs depending on the DBMS, but generally speaking, it first creates a snapshot of the current database and then waits for changes in the transaction log. To date, Debezium has developed connectors for the MongoDB, MySQL, PostgreSQL and SQL Server databases. Additional connectors for Oracle, Db2 and Cassandra are still at the development stage, but already available.
The most common way of using Debezium is in combination with Apache Kafka and the corresponding Kafka Connect framework. Apache Kafka is an open-source, distributed streaming platform that is based on the publisher-subscriber model. It enables applications to process data streams in real time and to exchange messages between several processes. With Kafka Connect, it is possible to implement matching connectors that can both write data to Kafka (source connectors) and read from Kafka (sink connectors). As you may have guessed, Debezium provides source connectors that stream the captured change events to Kafka. Applications that are interested in the change data can read them from the Apache Kafka logs and process them.
Recently, it has become possible to use Debezium not only in combination with Kafka Connect, but as a standalone application. This means that the users are no longer bound to Kafka and can now forward change events to other streaming platforms such as Kinesis, Google Cloud Pub/Sub, or Azure Event Hubs. The change data that Debezium captures from various databases have to be provided to the applications that want to process them (consumers) in a standardized format. Debezium uses the JSON format for this. Each change event comprises two parts: a payload part and a preceding schema that describes the structure of the payload. The payload part contains, for example, the operation that was carried out on the dataset and, optionally, the content of the line before and after the change occurred. The primary key of the database is given a specific designation which is important for the allocation of the event to a partition in Kafka. We will elaborate on this in the second part.
Furthermore, Debezium places a high value on fault tolerance for the change data capture: If a connector crashes, reading continues after the reboot at the position in the transaction log that has been processed last. Similarly, if the connection to Apache Kafka fails, the change data are stored in the cache until the connection has been reestablished. This concludes our overview of the basics of the use of Debezium. In the next part of the series, we will present a concrete example where Debezium streams change events from a sample table in the SQL Server.
1 The outline is based on the architecture outline provided in the Debezium documentation.