In nahezu jedem Unternehmensumfeld spielen Datenbanken, insbesondere relationale Datenbanken, eine große Rolle. In ihnen werden sowohl die Stammdaten von Mitarbeitern, Kunden etc. als auch die sich ständig ändernden Bewegungsdaten des Unternehmens verwaltet. Aus den verschiedensten Gründen können sich nun für betreffende Firmen neue Anforderungen ergeben, so dass die Änderungen der Bewegungsdaten in Echtzeit in anderen Prozessen und Applikationen weiterverarbeitet werden müssen – wie bspw. bei Buchungen in einem System. Dafür reicht es nicht mehr aus, dass eine Anwendung durch Polling regelmäßig eine Quelltabelle abfragt. Vielmehr wird es notwendig, dass die Anwendung über Change-Events in einer Tabelle benachrichtigt wird und die Informationen sofort aufbereitet zur Verfügung gestellt bekommt.
Und genau das ist mit dem Einsatz von Debezium und der Streaming-Plattform Apache Kafka möglich.
Datenänderungen erkennen
Zu Beginn sollte einmal kurz geklärt werden, welche grundlegenden Möglichkeiten es zum Erfassen von Datenänderungen in relationalen Datenbanken gibt. In der Fachliteratur finden sich dazu unter dem Begriff Change Data Capture vier Methoden, die im folgenden Abschnitt vorgestellt werden.
Die einfachste Möglichkeit zur Erkennung von Änderungen ist der zeilen- und spaltenweise Vergleich einer Datenbanktabelle mit einer älteren Version von ihr. Es ist offensichtlich, dass dieser Algorithmus gerade für größere Tabellen nicht besonders effizient, dafür aber leicht zu implementieren ist. Eine weitere Idee ist es, nur die geänderten Datensätze anhand einer geschickten SQL-Abfrage auszuwählen. Dafür kommen in der Praxis meist Zeitstempel zur Anwendung, die für jeden Datensatz angeben, wann dieser zuletzt geändert wurde. Sucht man nun nach Datenänderungen in der Tabelle, selektiert man alle Datensätze, deren Zeitstempel jünger sind als der Zeitpunkt des letzten Vergleichs. Ein minimales SQL-Statement könnte so aussehen:
SELECT * FROM [source_table] WHERE last_updated < [datetime_of_last_comparison]
Problematisch an diesem Ansatz ist, dass eine solche Zeitstempel-Spalte in der Datenbanktabelle schon vorhanden sein muss, was wohl nicht immer der Fall sein wird. Es werden also Anforderungen an das Datenschema gestellt. Weiterhin lassen sich mit dieser Methode gelöschte Datensätze nur sehr schwer erkennen, da ihre Zeitstempel ebenfalls gelöscht werden.
Eine dritte Möglichkeit, die dieses Problem lösen kann, ist die Implementierung eines Datenbanktriggers, der nach jedem INSERT, UPDATE und DELETE auf der Tabelle ausgelöst wird. Weiterhin wäre es auch denkbar, Änderungen am Datenbankschema mithilfe eines Triggers zu überwachen. Ein solcher Trigger könnte dann die erfassten Datenänderungen in eine extra dafür vorgesehene Tabelle schreiben.
Zu guter Letzt gibt es noch eine vierte Methode, das sogenannte Log-Scanning, welches in diesem Blogpost eine besonders wichtige Rolle spielt. Die meisten Datenbankmanagementsysteme (DBMS) führen ein Transaktionslog, das alle Änderungen, die an der Datenbank vollzogen wurden, aufzeichnet. Dies dient vor allem dazu, die Datenbank nach einem Ausfall, sei es bedingt durch einen Stromausfall oder einen Schaden am physischen Datenträger, wieder zurück in einen konsistenten Zustand zu bringen. Für das Change Data Capture wird nun das Transaktionslog etwas zweckentfremdet: Durch das Auslesen der Logdatei ist es möglich, Änderungen an den Datensätzen einer bestimmten Quelltabelle zu erkennen und diese dann weiter zu verarbeiten.
Der große Vorteil des Log-Scannings ist es, dass durch das Auslesen des Transaktionslogs kein Overhead auf der Datenbank erzeugt wird, wie es beim Stellen von Abfragen oder beim Ausführen eines Triggers nach jeder Änderung der Fall ist. Damit wird die Performance der Datenbank nicht weiter beeinträchtigt. Weiterhin können alle Arten von Datenänderungen erfasst werden: das Einfügen, Aktualisieren und Löschen von Datensätzen und auch das Ändern des Datenschemas. Problematisch ist aber, dass der Aufbau solcher Transaktionslogs nicht genormt ist. Die Logdateien der einzelnen Datenbankhersteller sehen vollkommen unterschiedlich aus und unterscheiden sich teilweise auch zwischen den einzelnen Versionen ein und desselben Datenbankmanagementsystems. Möchte man also Datenänderungen aus mehreren Datenbanken unterschiedlicher Hersteller erfassen, müssen mehrere Algorithmen implementiert werden.
Und genau an dieser Stelle kommt Debezium ins Spiel.
Was ist Debezium?
Debezium ist an sich keine eigenständige Software, sondern eine Plattform für Konnektoren, die das Change Data Capture für verschiedene Datenbanken implementieren. Dabei nutzen die Konnektoren das Log-Scanning, um die Datenänderungen zu erfassen und sie an die Streaming-Plattform Apache Kafka weiterzureichen.
Jeder Konnektor repräsentiert eine Software für ein bestimmtes DBMS, welche in der Lage ist, eine Verbindung zur Datenbank aufzubauen und dort die Änderungsdaten auszulesen. Die genaue Funktionsweise eines Konnektors unterscheidet sich zwischen den DBMS, im Allgemeinen wird aber zunächst ein Snapshot vom bestehenden Datenbestand erzeugt und danach auf Änderungen im Transaktionslog gewartet. Bisher hat Debezium Konnektoren für die Datenbanken MongoDB, MySQL, PostgreSQL und SQL Server entwickelt. Weitere für Oracle, Db2 und Cassandra befinden sich aktuell noch in der Entwicklungsphase, sind aber schon verfügbar.
Die gängigste Variante, Debezium einzusetzen, ist in Kombination mit Apache Kafka und dem dazugehörigen Framework Kafka Connect. Apache Kafka ist eine quelloffene, verteilte Streaming-Plattform, die auf dem Publisher-Subscriber-Modell basiert. Es bietet Applikationen die Möglichkeit, Datenströme in Echtzeit zu verarbeiten und Nachrichten zwischen mehreren Prozessen auszutauschen. Mit Kafka Connect lassen sich passend dazu Konnektoren implementieren, die sowohl Daten nach Kafka schreiben (Quell-Konnektoren) als auch aus Kafka lesen können (Sink-Konnektoren). Debezium stellt, wie man schon vermutet, solche Quell-Konnektoren zur Verfügung, die die ermittelten Change-Events an Kafka streamen. Applikationen, die nun an den Änderungsdaten interessiert sind, können diese aus den Logs von Apache Kafka lesen und verarbeiten.
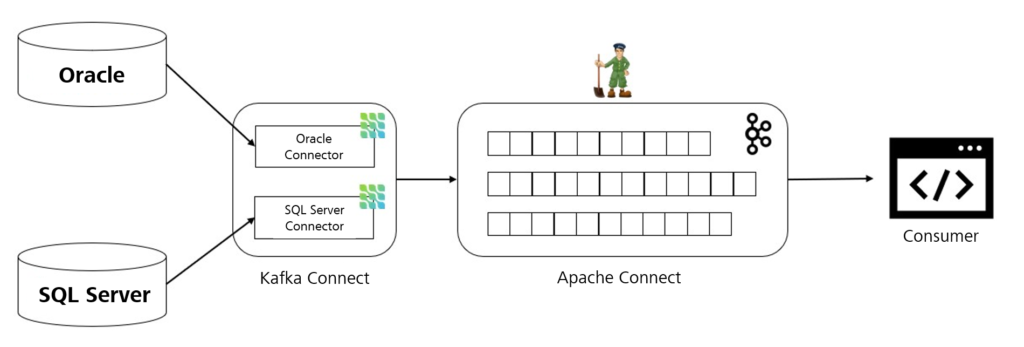
Seit kurzem gibt es auch die Möglichkeit, Debezium nicht mehr in Verbindung mit Kafka Connect, sondern auch als Standalone-Applikation zu verwenden. Damit sind Anwender nicht mehr an Kafka gebunden und können Change-Events auch an weitere Streaming-Plattformen, wie z. B. Kinesis, Google Cloud Pub/Sub oder Azure Event Hubs weiterreichen. Die Änderungsdaten, die Debezium aus unterschiedlichen Datenbanken ermittelt, müssen für Applikationen, die diese weiterverarbeiten wollen (Consumer), in einem einheitlichen Format zur Verfügung gestellt werden. Das realisiert Debezium über das JSON-Format. Ein Change-Event hat dabei immer zwei Teile: einen Payload-Teil und ein vorangehendes Schema, das den Aufbau des Payloads beschreibt. Im Payload-Teil befinden sich u. a. die Operation, die auf dem Datensatz ausgeführt wurde bzw. auch die Inhalte der Zeile vor und nach der Änderung. Besonders gekennzeichnet wird auch der Primärschlüssel des Datensatzes, was wichtig für die Zuordnung des Events zu einer Partition in Kafka ist. Doch dazu mehr im zweiten Teil.
Weiterhin legt Debezium beim Change Data Capture einen großen Wert auf Fehlertoleranz: Sollte mal ein Konnektor abstürzen, wird nach seinem Neustart an der letzten verarbeiteten Position im Transaktionslog weitergelesen. Auch bei einer fehlenden Verbindung zu Apache Kafka werden die Änderungsdaten so lange zwischengespeichert, bis wieder eine Verbindung hergestellt werden konnte. Damit wären zunächst einmal die Grundlagen für die Nutzung von Debezium geklärt. Im nächsten Teil des Blogposts wird ein konkretes Beispiel vorgestellt, bei dem Debezium Change-Events aus einer Beispieltabelle im SQL Server streamt.
1 Die Skizze ist in ihrer Art an die Architektur-Skizze in der Dokumentation von Debezium angelehnt.