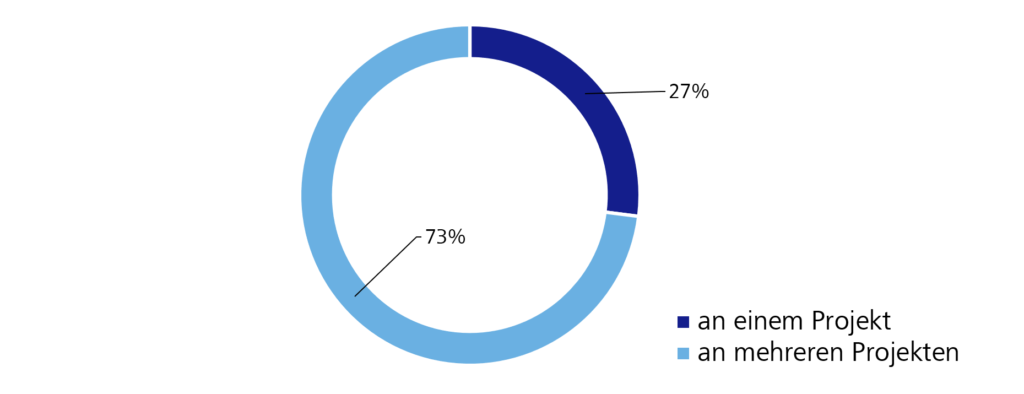Nachdem wir in Teil 1 die Vorteile und Herausforderungen von Microservices in Monorepos diskutiert haben, konzentrieren wir uns nun darauf, wie Nx diese Struktur für AWS CDK-basierte Anwendungen unterstützt.
Was ist Nx?
Nx ist ein JavaScript basiertes Buildsystem für Monorepos. Es ermöglicht die effiziente Ausführung aller Aufgaben wie Build und Test über mehrere Projekte in einem Monorepo, unabhängig davon, ob NPM, Yarn oder PNPM als Paketmanager verwendet wird. Nx bietet auch einen vollständig integrierten Modus, der keine separaten package.json Dateien für jedes Projekt benötigt. Dies ermöglicht eine tiefere Integration und ist besonders interessant für UI-Anwendungen mit AngularJS oder React.
Beginnen wir mit einem einfachen Beispiel. Wenn wir das Build-Skript für Service A ausführen wollen, können wir dies wie folgt tun:
npx nx build service-a
Nun gibt es in unserem Beispiel Repository (siehe Abbildung 1, Teil 1) auch die Services B und C. Wenn wir das Build-Skript für alle Projekte im Repo ausführen wollen, gehen wir wie folgt vor:
npx nx run-many -t build
Es ist interessant zu sehen, dass dies schneller funktioniert, als wenn wir es einzeln ausführen würden. Das liegt daran, dass Nx sie parallel ausführt, wenn unsere Services so konzipiert sind, dass sie zur Build-Zeit unabhängig voneinander sind (was sie bei einem guten Design auch sein sollten).
Die Stärke von Nx zeigt sich besonders im Zusammenspiel mit der Versionsverwaltung des Git-Repositories. Es ist möglich, nur die Target Scripts der Projekte und deren Abhängigkeiten auszuführen, bei denen im Vergleich zwischen Head und Base Änderungen festgestellt wurden. Angenommen, es gibt nur Änderungen im Service B in einem Branch für einen Pull Request zum Basis-Branch „dev“. Im folgenden Beispiel würde das Build-Skript nur für Service B ausgeführt werden. Die Scripts der anderen Projekte werden nicht ausgeführt.
npx nx affected -t build
Kehren wir zum Beispiel-Repository aus Teil 1 zurück. Die package.json jedes Service enthält das entsprechende CDK deploy Skript. Für Service A sieht dieses vereinfacht so aus:
Zusätzlich haben wir eine Abhängigkeit zu einer benutzerdefinierten Bibliothek, die von allen drei Services verwendet wird. Angenommen, wir nehmen eine Änderung an dieser Bibliothek vor und führen anschließend folgenden Befehl aus:
npx nx affected -t deploy
In diesem Fall werden die Deployment-Skripte aller drei Services ausgeführt. Dies geschieht, weil sich die Bibliothek geändert hat und somit indirekt alle drei Services betroffen sind. Nx berücksichtigt also den Abhängigkeitsgraphen zwischen den einzelnen Projekten innerhalb des Monorepos. Um hier den Überblick zu behalten, bietet Nx eine nützliche Visualisierung aller im Repository enthaltenen Module und deren Abhängigkeiten. Mit dem Befehl
npx nx graph
wird lokal eine WebApp gestartet, mit deren Hilfe die Modulstrukturen und deren Abhängigkeiten untereinander im Browser untersucht werden können.
Das alles zusammen ist sehr mächtig, wenn man bedenkt, dass für praktisch jede Aufgabe wie Build, Unit Tests, Code Style Checks, Integrationstests, Audit, Deployment und vieles mehr in den Projekten entsprechende Target-Skripte in der package.json definiert werden können. Durch die konsistente Benennung dieser Skripte über die Projekte hinweg können für jede dieser Aufgaben separate automatisierte Workflows (z.B. mit GitHub Actions) bereitgestellt werden. Diese sind so allgemeingültig, dass sie nicht einmal angepasst werden müssen, wenn weitere Projekte wie Services oder Bibliotheken hinzugefügt werden. Damit haben wir ein effektives Mittel, um möglichen Problemen eines monolithischen CI/CD Prozesses zu begegnen.
Nx und AWS CDK: Passt das zusammen?
Mit AWS CDK steht uns ein Framework für Infrastructure as Code zur Verfügung, das es ermöglicht, die gesamte serverlose Infrastruktur in TypeScript zu definieren. Bei der Strukturierung wird empfohlen, sowohl den Infrastrukturcode als auch den Businesscode in einer Applikation zu vereinen. Jeder Service wird somit zu einer separaten CDK-Applikation mit eigenen Stacks.
Nx ermöglicht die einfache Organisation von AWS CDK-Applikationen in separaten Paketen. Dieses Zusammenspiel ermöglicht eine übersichtliche und gut organisierte Entwicklung von Cloud-Anwendungen, bei der AWS CDK die Infrastrukturaspekte effizient handhabt und Nx die Flexibilität bietet, die verschiedenen Teile der Anwendung in einem Monorepo zu verwalten.
Für unser Beispiel-Repository würde dies stark reduziert wie folgt aussehen:
In dieser Struktur gibt es auf der obersten Ebene zwei verschiedene Workspaces. Einen für alle Applikationen (service-a, service-b, service-c und ui) unterhalb des apps-Ordners. Jede Applikation folgt der empfohlenen Struktur für eine einzelne CDK-Applikation. Der zweite Workspace libs enthält die gemeinsame Bibliothek custom-lib mit ihrer eigenen Struktur und package.json. Die Datei nx.json dient zur Konfiguration von Nx und enthält lediglich Standardeinstellungen für das gesamte Monorepo.
Diese Struktur kann beliebig um weitere Services, Libraries und ganze Workspaces erweitert werden, indem einfach neue Packages hinzugefügt werden.
CI/CD leicht gemacht
In der bisherigen Struktur haben wir das Monorepo für eine Architektur aus mehreren Cloud-Native Microservices definiert, die als separate CDK-Applikationen existieren. Nx ermöglicht uns eine effiziente Verwaltung dieser Anwendungen.
Allerdings reicht es in der Praxis oft nicht aus, ein Deployment-Skript nur für ausgewählte Services effizient auszuführen. Ein gängiger Ansatz ist es, die einzelnen CDK-Stacks der Applikationen über eine AWS CodePipeline zu erstellen und in die gewünschten Ziel-Accounts der verschiedenen Stages bereitzustellen. Dieser Ansatz ist mit dem Monorepo-Ansatz vereinbar, führt jedoch dazu, dass für jede Service-Applikation eine separate Pipeline verwaltet werden muss. Dieses Vorgehen ähnelt einem Multi-Repo-Ansatz, und der Verwaltungsaufwand wächst mit der Anzahl der Services.
Eine alternative Variante besteht darin, eine einzige Pipeline aufzubauen, die alle Stacks aller Services erstellt, testet und bereitstellt. Dabei besteht jedoch das Risiko eines monolithischen, zeitaufwändigen CI/CD-Prozesses, wie im Teil 1 beschrieben. Zusätzlich gehen die Vorteile von Nx verloren, da AWS CodePipeline bisher keine Integration dafür bietet.
Abbildung 2: Monorepo CI/CD
Daher möchten wir an dieser Stelle eine weitere Variante betrachten, die in Abbildung 2 dargestellt ist. Mit diesem Ansatz versuchen wir, die oben genannten Möglichkeiten zu kombinieren. Insbesondere während der Entwicklung profitieren wir stark vom Monorepo-Ansatz in Verbindung mit Nx und können viele Entwicklungsschritte automatisieren. Da wir GitHub als Repository verwenden, können viele Aufgaben für unser Monorepo als GitHub Actions implementiert werden, unter anderem das Deployment der einzelnen Service CDK Stacks in einen AWS Dev-Account. All dies basiert auf dem Nx affected-Feature und ermöglicht so eine sehr automatisierte und effiziente Entwicklungsumgebung.
Für das Deployment der Gesamtapplikation in die weiteren notwendigen Stages (QA, STG, PROD) haben wir im Monorepo zusätzlich ein Pipeline-Projekt aufgesetzt, das alle notwendigen Stacks verbindet und konfiguriert, in welche Ziel-Accounts diese je nach Stage deployt werden sollen. Dabei ist uns die atomare und native Bereitstellung innerhalb des AWS Kosmos über eine AWS CodePipeline wichtiger als die Effizienz.
Schlussfolgerung
Unsere Betrachtung hat gezeigt, dass der Entwicklungsprozess von mehreren Microservices in Monorepos mit Nx auch für CDK-Applikationen sehr effizient sein kann. Insbesondere einzelne Teams profitieren von den klaren Vorteilen des vereinfachten Dependency Managements, der erleichterten Zusammenarbeit und der einfachen Möglichkeit, umfangreiche Refactorings durchzuführen, was Monorepos zu einer attraktiven Option macht. Bei teamübergreifenden Projekten hängt der Erfolg stark davon ab, wie gut die Teams zusammenarbeiten können. Eine effektive Abstimmung auf gemeinsame Richtlinien und Patterns ist entscheidend.
Trotz der offensichtlichen Vorteile von Monorepos bleibt die Gestaltung von CI/CD-Prozessen eine Herausforderung. Durch den geschickten Einsatz geeigneter Werkzeuge können jedoch schlanke und klare Prozesse geschaffen werden. Der Monorepo-Ansatz in Kombination mit den richtigen Werkzeugen kann eine vielversprechende Möglichkeit bieten, die Entwicklung und Bereitstellung von Cloud-nativen Microservices effizient zu gestalten. Dabei gilt es, die Vorteile zu maximieren und mögliche Herausforderungen gezielt anzugehen.
In der Software-Architektur von Webanwendungen hat sich in den vergangenen Jahren ein Paradigmenwechsel vollzogen. Weg von monolithischen Strukturen hin zu heterogenen Architekturen, die sich durch die Implementierung verschiedener Microservices auszeichnen. Auch in größeren, komplexen, serverlosen und Cloud-native Webanwendungen für Amazon Web Services (AWS) wird dieses Vorgehen empfohlen. Dabei wird üblicherweise der Infrastrukturcode für unterschiedliche Technologien, der Businesscode sowie die notwendigen CI/CD-Prozesse mithilfe des AWS Cloud Development Kit (CDK) je Service in einer Applikation zusammengefasst. Diese Applikationen werden typischerweise jeweils in einem eigenen Repository untergebracht.
Die Aufteilung in verschiedene Microservices unter Anwendung von Domain-Driven Design erweist sich selbst für individuelle Teams, innerhalb von Teilprojekten, oder für kleinere Projekte als sinnvoll. Manchmal übernimmt ein Team auch aus organisatorischen Gründen die Verantwortung für mehrere Services.
Parallel zu dieser Strukturierung gibt es jedoch auch immer wiederkehrende Herausforderungen im Bereich Infrastrukturcode und technischer Lösungen für Querschnittsaspekte, die eine einheitliche und zentralisierte Bereitstellung erfordern. Hierbei entsteht für einzelne Teams jedoch ein erheblicher Mehraufwand in Bezug auf die Bereitstellung verschiedener Bibliotheksversionen, die Verwaltung von Abhängigkeiten und die Pflege von CI/CD-Prozessen in unterschiedlichen Repositories.
Ein Ansatz zur Bewältigung dieser Herausforderungen besteht darin, die Verwendung eines Monorepos in Betracht zu ziehen. Im Kontext von Microservices-Architekturen auf Basis des CDK stellt sich die Frage: Warum nicht alle Services und Abhängigkeiten in einem gemeinsamen Repository zusammenfassen, ohne jedoch eine monolithische Struktur zu schaffen?
Abbildung 1: Von Monolithen zu Microservices in Multi-Repos und wieder zurück zu Monorepos?
Abbildung 1 zeigt beispielhaft ein derartiges Szenario. Eine ursprünglich entwickelte und gewachsene Anwendung, die sich in einem Repository als Monolith befand, wurde zunächst in eine Microservices-Architektur mit mehreren Repositories umgewandelt. Diese Architektur besteht aus verschiedenen CDK-Applikationen und Bibliotheken. Schließlich erfolgte im Rahmen der Software-Evolution die Zusammenführung der einzelnen Komponenten und Services in ein Monorepo. Dies ist lediglich ein Beispiel aus einem existierenden Projekt und keine generelle Empfehlung, obwohl solche Migrationen in der Praxis häufig vorkommen. Bei Projektbeginn sollte man sich bewusst über die geeignete Strategie sein und kann, nach sorgfältiger Abwägung, direkt mit dem Monorepo-Ansatz starten. Alternativ kann es jedoch auch klare Gründe gegen ein Monorepo geben und eher für einen Multi-Repo-Ansatz sprechen. Betrachten wir zunächst näher, warum wir die Entscheidung für Monorepos treffen möchten und welche Konsequenzen sich daraus ergeben. Im zweiten Teil werden wir genauer beleuchten, wie eine Monorepo Strategie effektiv mit AWS CDK und dem Buildsystem Nx funktionieren kann.
Vorteile von Monorepos
Die zentrale Stärke eines Monorepos liegt in seiner Funktion als alleinige Quelle der Wahrheit. Hieraus ergeben sich diverse weitere Vorteile:
Vereinfachtes Abhängigkeitsmanagement: Das Repository beherbergt die gesamte Codebasis und jede Komponente ist mit ihrer Hauptversion integriert, was das Abhängigkeitsmanagement erheblich vereinfacht. Dies macht den Einsatz von Artefakt-Repositories (z.B. CodeArtifact, Nexus) überflüssig.
Vereinfachter Zugriff: Teams können mühelos zusammenarbeiten, da sie Einblick in das gesamte Repository haben.
Groß angelegte Code-Refaktorisierung: Atomare Commits im gesamten Code erleichtern moduleübergreifende Refaktorisierungen und Implementierungen erheblich.
Continuous Deployment Pipeline: Keine bzw. wenig neue Konfiguration erforderlich, um weitere Services hinzuzufügen.
Umgang mit möglichen Nachteilen von Monorepos
Natürlich gibt es auch Konsequenzen bei der Verwendung von Monorepos. Einige Nachteile können von vornherein aufgefangen werden, wenn bestimmte Voraussetzungen erfüllt sind. Dazu gehören idealerweise eine Einigung auf die verwendeten Technologien und die Wahl ähnlicher CI/CD-Prozesse über alle Services hinweg. Auch muss berücksichtigt werden, dass die Zugriffkontrolle i.d.R. nicht feingranular eingestellt werden kann und jeder Zugriff auf die gesamte Codebasis hat. Dies kann besonders wichtig werden, wenn mehrere Teams in einem Monorepo arbeiten. Andernfalls können viele der Vorteile von Monorepos schnell verloren gehen und ein Multi-Repo-Ansatz könnte besser geeignet sein.
Es gibt drei weitere Einschränkungen oder Gefahren, die berücksichtigt werden müssen:
Eingeschränkte Versionierung
Alle Service liegen immer in ihren jeweiligen aktuellen Versionen vor. Ein Service kann nicht einfach eine ältere Version eines anderen Services referenzieren. Bei der Konzeption von Microservices ist daher besonderes Augenmerk auf die Schnittstellenverträge der Services innerhalb des Monorepos zu legen. Diese sollten im Idealfall semantisch versioniert und dokumentiert werden. Etablierte Standards wie OpenAPI, GraphQL und JSON Schema unterstützen dies. Bei der Verwendung gemeinsamer Bibliotheken ist auf Abwärtskompatibilität zu achten, da Änderungen sonst Anpassungen in allen Modulen erfordern, die die Bibliothek verwenden.
Hohe Kopplung möglich
Die Vorteile eines Monorepos, nämlich die schnelle und effiziente Zusammenarbeit durch eine zentrale Codebasis, können sich schnell ins Gegenteil verkehren. Dies geschieht, wenn Services direkt auf Bausteine anderer Services referenzieren oder wenn die Wiederverwendbarkeit von Code falsch verstanden wird und dazu führt, dass die Geschäftslogik der Services in gemeinsame Bibliotheken ausgelagert wird. Dadurch entsteht schnell eine Architektur mit hoher Kopplung zwischen den einzelnen Bausteinen. Insbesondere unter Zeitdruck bei der Entwicklung neuer Features ist die Versuchung groß, technische Schulden einzugehen. Häufen sich diese, besteht die Gefahr, dass aus Angst vor Breaking Changes keine Refactorings mehr durchgeführt werden, was wiederum die Wartbarkeit des Gesamtsystems erheblich beeinträchtigt.
Es ist daher wichtig, klare Regeln zu definieren und sicherzustellen, dass die Einhaltung dieser Regeln idealerweise durch statische Codeanalysen überwacht und gemessen wird. Es ist anzustreben, dass die Services während der Build-Zeit keine Abhängigkeiten untereinander haben und stattdessen zur Laufzeit über klar definierte Schnittstellen miteinander kommunizieren. Die Schnittstellenverträge können effizient als Bibliotheken zentral im Monorepo abgelegt werden.
Monolithische, langwierige CI/CD-Prozesse
Wenn sich der gesamte Code in einem einzigen Repository befindet, müssen die CI/CD-Prozesse für automatisiertes Testen, statische Codeanalyse, Build und Deployment im schlimmsten Fall bei jeder Änderung den gesamten Code durchlaufen. Mit wachsender Projektgröße führen diese längeren Wartezeiten zu Frustration, was sich negativ auf die Teamleistung auswirken kann. In einer Microservices-Architektur sollte dies jedoch nicht der Fall sein, denn dies widerspricht dem Ziel, jeden Service individuell zu betrachten. Bei Codeänderungen in einem Service sollten nur die notwendigen CI/CD-Prozesse für diesen Service und seine abhängigen Bibliotheken durchgeführt werden. Die Entwicklung sollte so schnell und isoliert erfolgen, als würde man nur an der Codebasis eines Services in einem Repository arbeiten. Es gibt geeignete Werkzeuge wie Nx um dies in einem Monorepos zu realisieren.
Storybook ist ein komponentengetriebenes Werkzeug für die Erstellung von visuellen Styleguides und zur Demonstration von UI-Komponenten aus React, Angular, Vue sowie Web Components.
Speziell das Snapshot Testing bietet die Möglichkeit, ungewollte Anpassungen des Stylings frühzeitig zu erkennen und zu korrigieren.
Snapshot Testing in Storybook
Snapshot-Tests sind ein sehr nützliches Werkzeug, wenn Sie sicherstellen möchten, dass sich Ihre Benutzeroberfläche nicht unerwartet ändert.
Ein typischer Snapshot-Testfall rendert eine UI-Komponente, erstellt einen Snapshot und vergleicht ihn dann mit einer Referenz-Snapshot-Datei, die neben dem Test gespeichert ist. Der Test schlägt fehl, wenn die beiden Snapshots nicht übereinstimmen: Entweder ist die Änderung unerwartet oder der Referenz-Snapshot muss auf die neue Version der UI-Komponente aktualisiert werden.
Storybook bietet mehrere Möglichkeiten, eine Anwendung zu testen. Angefangen mit Chromatic. Diese sogenannte Werkzeugkette setzt allerdings voraus, dass der Quellcode in GitHub versioniert ist und kostet für den professionellen Gebrauch eine monatliche Gebühr.
Eine weitere Möglichkeit ist das schlanke Add-on Storyshots, welches auf dem Testframework “Jest” basiert. Es wird in der Kommandozeile gestartet und listet dort Abweichungen der Komponente zum vorherigen Stand auf. Der Programmierer muss prüfen, ob diese Änderung erwünscht oder ein Fehler ist.
Einrichtung für Angular
Diese Anleitung setzt voraus, dass Storybook bereits für die Angular-Anwendung installiert ist. Eine Setup-Anleitung finden Sie unter diesem Link. Angular bringt von Haus aus die Testumgebung Karma mit. Um die Anwendung auf Jest umzustellen, sind folgende Schritte nötig:
Installation der Jest Dependencies
Zum Installieren von Jest einfach die Zeile „npm install jest jest-preset-angular –save-dev“ in der Kommandozeile ausführen.
Jest Setup-Datei erstellen
Im root-Verzeichnis ihres Angular Projektes die neue Typescript-Datei setupJest.ts mit dem Inhalt import ‚jest-preset-angular‘; erzeugen.
package.json anpassen
Die package.json ihres Angular-Projektes muss um einen Absatz für das Testframework Jest ergänzt werden:
Im Anschluss sollten auch die Dateien Karma.config.js und test.ts im <root>/src Verzeichnis gelöscht werden und der Abschnitt für Test in der angular.json entfernt werden.
Migration von Jasmine (optional)
Für die Migration nach Jest müssen Anpassungen vorgenommen werden:
• Kommandozeile: npm uninstall @types/jasmine
• jasmine.createSpyObj(’name‘, [‚key‘]) wird zu jest.fn({key: jest.fn()})
• jasmine.createSpy(’name‘) wird zu jest.fn()
• spyOn mit returnValue() muss in jest.spyOn(…).mockReturnValue(…) umgewandelt werden
• spyOn mit callFacke() muss in jest.spyOn(…).mockImplementation(…) umgewandelt werden
• Asymmetric matchers: jasmine.any, jasmine.objectContaining, etc. wird zu expect.any,
expect.objectContaining
Storyshots Dependencies installieren
Nun wird Storyshots installiert. Um Storyshots zu installieren, sollen diese zwei Kommandozeilen ausgeführt werden:
npm i -D @storybook/addon-storyshots
npm i -D @storybook/addon-storyshots-puppeteer puppeteer
Nach der Installation sollten folgende Dependencies in der package.json vorhanden sein (Stand 12.11.2021; wichtig für den Installations-Workaround unter Angular):
Nach der Installation von Storyshots muss die Erweiterung noch eingestellt werden. Dafür muss im Verzeichnis <root>/src die Datei Storyshorts.test.js mit folgendem Inhalt erstellt werden:
import initStoryshots from '@storybook/addon-storyshots';
import { imageSnapshot } from '@storybook/addon-storyshots-puppeteer';
import path from 'path';
// Function to customize the snapshot location
const getMatchOptions = ({ context: { fileName } }) => {
// Generates a custom path based on the file name and the custom directory.
const snapshotPath = path.join(path.dirname(fileName), 'snapshot-images');
return { customSnapshotsDir: snapshotPath };
};
initStoryshots({
// your own configuration
test: imageSnapshot({
// invoke the function above here
getMatchOptions,
}),
});
tsconfig.json für Storyshots erweitern
Des Weiteren muss noch die tsconfig.json angepasst werden. Dafür muss der compilerOptions Abschnitt in tsconfig.json wie folgt erweitert werden:
"compilerOptions": {
"esModuleInterop": true,
Package.json für Storyshots erweitern
Zuletzt muss der in der Package.json enthaltene Abschnitt für Jest umkonfiguriert werden:
Diese Anpassungen sind speziell für die gewählte Version, da die Ordnerstruktur in Jest umgemappt werden muss. Das kann sich in späteren Versionen von Storyshorts wieder ändern.
Test der Komponenten
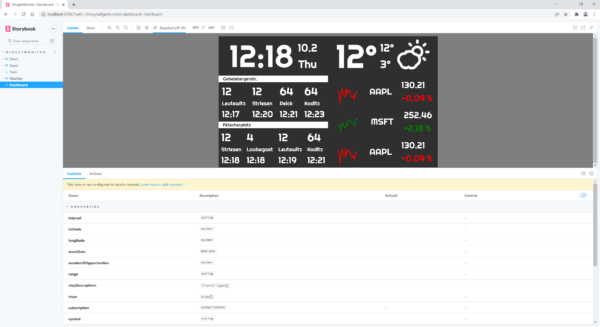
Für den Test gibt es eine Beispielanwendung, welche aus vier Einzelkomponenten besteht. Die erste Komponente zeigt die Uhrzeit inklusive Datum und Wochentag an. Die zweite Komponente gibt das aktuelle Wetter in Schaubild mit Gradzahl, Tageshöchst- und Tagestiefsttemperatur an. Über eine weitere Komponente werden die Straßenbahnabfahrten am Beispiel Dresden Striesen abgebildet. Zuletzt gibt es noch eine Komponente, welche 3 Aktienkurse anzeigt mitsamt Graph und Indikatoren.
Abbildung 1: Storybook für eine Anwendung bestehend aus vier Komponenten
Bespielhaft sieht der Quellcode der Uhrzeitkomponente wie folgt aus:
Diese beinhaltet drei Zustände, von denen die ersten beiden jeweils statische Zeitpunkte sind. Der dritte Zustand “Running” zeigt die aktuelle Uhrzeit an, d. h. er ist nicht statisch.
Voraussetzung für Snapshot Tests unter Storybook
Es ist wichtig, dass wir unter Storybook einen statischen Zustand haben, damit die Anwendung getestet werden kann. Im Uhrzeitbespiel ist der Zustand „Running“ nicht statisch. Diesen kann man überspringen, indem man den parameter storyshots: { disable: true } hinzufügt (siehe Quellcode weiter oben).
Test starten
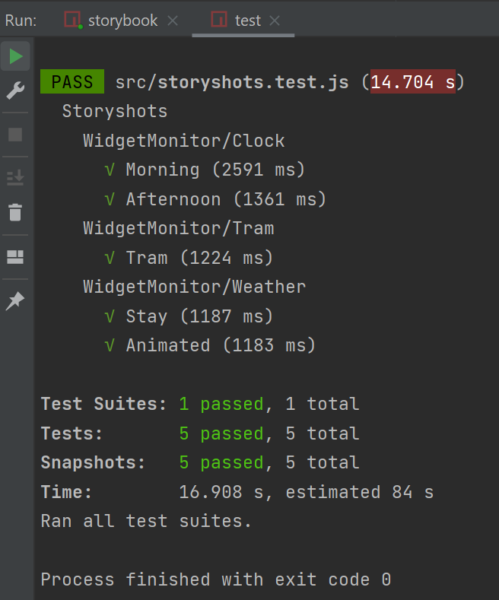
Mit der Kommandozeile npm test, wird der Test in der Kommandozeile im Angular-Projektverzeichnis gestartet. Der initiale Snapshot Test erstellt nun ein Snapshot Image von jedem Komponentenzustand.
Abbildung 2: Test starten in Storybook
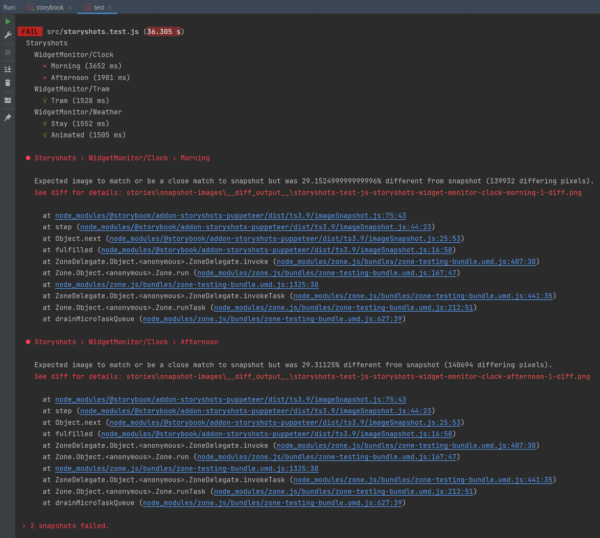
Zum Aufzeigen von Fehlern wird nun beispielhaft die Schrift der Uhrzeit in der Clock-Komponente sowohl kleiner als auch in Rot im SCSS umgestellt und der Test erneut gestartet.
Abbildung 3: Aufzeigen von Fehlern in Storybook
Das Ergebnis des Snapshot Tests zeigt, dass die beiden aktiven Zustände der Clock-Komponente umgefallen sind und auf ein Diff Image verwiesen wird. Dieses sieht wie folgt aus:
Abbildung 4: Ergebnis des Snapshot Tests
Links ist der ursprüngliche Zustand zu sehen, rechts der Zustand nach der Änderung. In der Mitte sieht man den Zustand, wie sich beide überschneiden. Nun gibt es die Möglichkeit, diesen Zustand entweder zu übernehmen oder den Test – nach Anpassung der Anwendung – erneut auszuführen.
Das Übernehmen des Zustands wird mittels der Kommandozeile npm test — -u erzwungen. Damit werden die Differenzbilder gelöscht und ein neuer Snapshot des Zustands der Komponente erstellt. Das erneute Aufrufen der Kommandozeile npm test sollte nun ohne Fehler durchlaufen.
Fazit
Einen Zustand für Storybook zu pflegen, bedeutet auch immer einen Mehraufwand im Projekt. Wer sich vor diesem Aufwand nicht scheut, hat mittels Jest und der Erweiterung StoryShots die Möglichkeit, einen bestimmten Zustand gekapselt prüfen zu können. Dies ist besonders hilfreich zur Früherkennung von Styling Bugs, welche schwierig in Unit- und Ende-Zu-Ende-Tests gefunden werden können und meist erst beim manuellen Testen auffallen.
Im ersten Teil dieser Artikelreihe haben wir uns angeschaut, wie man eigene Web Components baut. Nun schauen wir uns die Einbindung in React-Anwendungen an.
Ihrer Idee nach sind Web Components unabhängig von JavaScript-Frameworks einsetzbar. Während dies beispielsweise bei Angular auch mit wenigen Handgriffen ohne Probleme funktioniert, sieht die Situation bei React leider etwas anders aus. Warum das so ist und wie man das Problem lösen kann, wird im Folgenden näher erläutert.
Prinzipiell lassen sich Web Components auch in React vollständig nutzen. Allerdings muss man für bestimmte Fälle zusätzlichen Aufwand betreiben und von üblichen React-Konventionen abweichen. Die Benutzung entspricht nicht mehr unbedingt dem, was React-Entwicklerinnen und -Entwickler erwarten würden.
Im Wesentlichen gibt es zwei Problemfelder: Einerseits handelt es sich dabei um das Problem „Attribute vs. Properties“, welchem wir uns in diesem Artikel widmen. Andererseits gibt es das Problem der „Custom-Events“ – dieses wird im nächsten Teil dieser Reihe behandelt.
Problembeschreibung „Attribute vs. Properties“
Wie wir im ersten Teil der Reihe gesehen haben, gibt es zwei Möglichkeiten, um Daten an eine Web Component zu übergeben – als HTML-Attribut oder als JavaScript-Property.
In diesem Code-Beispiel wird der „value“ als Attribut im HTML definiert:
<my-component value="something"></my-component>
Hier wird dagegen mittels JavaScript das gleichnamige Property gesetzt:
In JavaScript ist es aber auch möglich, explizit das Attribut zu setzen:
myComponent.setAttribute("value", "something")
JavaScript ist in dieser Hinsicht also flexibler, denn in HTML sind nur Attribute möglich – Properties lassen sich nicht in HTML setzen.
Wichtig zum Verständnis ist hierbei: Ob und wie Attribute und Properties von der Komponente verarbeitet bzw. berücksichtigt werden, liegt vollständig in der Implementierung der Komponente. Es gibt zwar die Best Practice, im Regelfall sowohl Attribute als auch Properties anzubieten und diese synchron zu halten, aber technisch ist niemand daran gebunden. Es wäre daher ohne Weiteres möglich, entweder nur Attribute oder nur Properties zu akzeptieren oder die beiden mit völlig unterschiedlichen Namen zu versehen (womit man aber sicherlich den Unmut der Benutzerinnen und Benutzer der Komponente auf sich ziehen würde).
Auf der anderen Seite gibt es jedoch auch handfeste Gründe, in manchen Fällen von dieser Best Practice bewusst abzuweichen.
Ein wichtiger Faktor ist, dass Attribute und Properties unterschiedlich mächtig sind: Attribute erlauben nur solche Werte, die als String repräsentiert werden können, d. h. Strings und Zahlen. Außerdem kann man durch die An- bzw. Abwesenheit eines Attributes auch Boolean-Werte abbilden. Komplexere Daten wie JavaScript-Objekte oder Funktionen können nicht als Attribut übergeben oder müssten serialisiert werden.
Bei JavaScript-Properties gibt es diese Beschränkung naturgemäß nicht. Allerdings haben Properties den Nachteil, dass sie in der Benutzung stets imperativ und nicht deklarativ sind. Anstatt wie bei HTML einfach deklarativ zu sagen, welchen Zustand man haben möchte, muss man Properties mittels Befehlen imperativ der Reihe nachsetzen. Aus Entwicklersicht ist das eher unschön, denn besonders durch Frameworks wie React und (mit leichten Abstrichen) Angular hat man sich an die Vorzüge von deklarativem Arbeiten gewöhnt.
Ein weiterer Unterschied zwischen Attributen und Properties betrifft die Performance: Sowohl Attribute als auch Properties werden nicht nur dafür genutzt, Daten von außen in die Komponente zu geben, sondern auch, um auf Informationen der Komponente zugreifen zu können. Ein schönes Beispiel hierfür ist der Standard-HTML-Tag <video>, welcher die aktuelle Wiedergabeposition des abgespielten Videos mittels der JavaScript-Property „currentTime“ anbietet. Bei Abfrage dieser Properties erhält man die Position in Sekunden als Dezimalzahl. Ein dazu passendes HTML-Attribut existiert dagegen nicht. Ein solches Attribut müsste andernfalls ständig mit der aktuellen Abspielzeit aktualisiert werden, was im DOM eine relativ kostspielige Operation wäre. Die Abfrage über ein JavaScript-Property lässt sich dagegen recht performant lösen, da hierfür eine Lazy-Getter-Methode implementiert werden kann, die nur anspringt, wenn die Position tatsächlich abgefragt wird.
Wir haben bei Web Components somit zwei unterschiedliche Mechanismen für einen sehr ähnlichen Zweck, die sich dennoch in einigen Aspekten recht deutlich unterscheiden.
Attribute
Properties
deklarativ
imperativ
String, Number, Boolean
String, Number, Boolean, Date, Object, Function
React Props
Bei React sieht die Sache etwas übersichtlicher aus: React kennt lediglich so genannte „Props“. Da React einen starken Fokus auf deklaratives Programmieren legt, ähnelt die Benutzung der von HTML-Attributen:
<MyComponent value="something" />
React-Props sind aber nicht auf bestimmte Datentypen beschränkt, sondern erlauben das Übergeben von beliebigen Daten und auch von Funktionen. Hierfür wird anstelle der Anführungsstriche eine Syntax mit geschwungenen Klammern benutzt:
Als React-Entwickler muss ich sagen, dass mir persönlich die React-Variante mit Props deutlich besser gefällt als die Unterscheidung zwischen Attributen und Properties mit ihren jeweiligen Eigenarten bei Web Components – dies ist aber Geschmackssache.
Web Components in React
Nun ist die API von Web Components aber nun mal so, wie sie ist. Die Frage ist daher: Was passiert, wenn man eine Web Component in React benutzt? Werden „props“ als Attribute oder Properties an die Web Component weitergereicht?
Zunächst entscheidet React anhand der Groß- und Kleinschreibung des Tags, ob es sich um eine React-Komponente (beginnt mit Großbuchstaben) oder einen HTML-Tag handelt, worunter auch Web Components zählen. Mit Ausnahme einiger Sonderfälle bei einigen Standard-HTML-Tags setzt React Props bei HTML-Tags und Web Components immer mittels „setAttribute“. Das heißt, dass die Benutzung von Attributen bei Web Components in React keine Probleme bereitet. Anders sieht es aus, wenn explizit JavaScript-Properties benutzt werden müssen, z. B. weil komplexe Daten oder Funktionen in die Web Component hineingereicht werden sollen. Dies lässt sich gegenwärtig mit React nicht deklarativ umsetzen. In gefühlt 90 % der Fälle stellt dies kein Problem dar, da es, wie oben bereits angemerkt, als Best Practice gilt, Attribute und Properties synchron zu halten und möglichst beide Varianten zu unterstützen. Nur in den restlichen 10 % der Fälle, in denen Properties notwendig sind, weil sich entweder die Autorinnen und Autoren der Web Component nicht an die Best Practice gehalten haben oder ein anderer Grund die Nutzung von Attributen verhindert, müssen wir uns etwas einfallen lassen.
Das heißt allerdings nicht, dass solche Web Components überhaupt nicht in React genutzt werden können! Wir können lediglich nicht den üblichen, rein deklarativen Weg gehen, sondern müssen auf die von React ebenfalls unterstützte, imperative API zurückgreifen. Wie dies funktioniert, wollen wir uns im Folgenden anschauen.
React abstrahiert von konkreten Instanzen von DOM-Knoten. Auch unabhängig von Web Components muss man aber in manchen Fällen direkt auf DOM-Knoten zugreifen, beispielsweise wenn eine Methode wie „.focus()“ aufgerufen werden soll. Für diesen Zweck nutzt React so genannte „Refs“und genau diesen Mechanismus können wir auch für das Setzen von JavaScript-Properties an unseren Web Components benutzen. Im Code sieht das z. B. so aus:
Mit „const elementRef = useRef(null)“ erstellen wir eine Art Container, in die React nach dem Rendern die Referenz zum DOM-Knoten packt. „useEffect“ kann dazu genutzt werden, eine Funktion auszuführen, sobald bestimmte Variablen verändert wurden. Dazu geben wir die „elementRef„-Variable (in ein Array gewrappt) als zweiten Parameter an die „useEffect„-Hook-Funktion. Sobald React die Komponente das erste Mal gerendert hat, wird die angegebene Funktion ausgeführt, so dass unser Property entsprechend gesetzt wird. Wie man sieht, ist der Code doch um einiges umständlicher als lediglich ein Attribut direkt am Tag zu setzen. Das Beispiel zeigt aber, dass es eben doch möglich ist, Web Components in React zu nutzen. Im vierten Teil dieser Artikelreihe werden wir uns noch eine andere Variante anschauen, die besonders bei größeren Anwendungen, in denen bestimmte Web Components immer wieder eingesetzt werden sollen, besser skaliert. Im nächsten Artikel der Reihe schauen wir uns aber zunächst das zweite Problem von Web Components mit React genauer an: Die Verarbeitung von Custom-Events.
Fazit
Als Zwischenfazit lässt sich feststellen, dass die Situation von Web Components mit React kompliziert ist. Auf der einen Seite ist React hervorragend für die Entwicklung von umfangreichen Web-Anwendungen geeignet und daher auch weit verbreitet. Auf der anderen Seite ist es äußerst ärgerlich, dass React bei einer modernen Web-Technologie wie Web Components solche Probleme hat.
Als Grund hierfür lassen sich mindestens zwei Faktoren nennen: Zum einen entstand React zu einer Zeit, in der Web Components bzw. „custom elements“ noch eine bloße Idee und weit von der praktischen Umsetzung entfernt waren. Gleichzeitig legt das React-Team großen Wert auf Abwärtskompatibilität und schreckt verständlicherweise vor inkompatiblen Änderungen in der Art und Weise, wie React-Komponenten geschrieben werden, zurück. Die Diskussion dazu, welche Optionen im Raum stehen, um React kompatibel zu Web Components zu machen, kann bei Interesse im Issue-Tracker des Projekts verfolgt werden.
Der zweite Faktor, den ich hervorheben möchte, ist: Die Konzepte von Web Components und React unterscheiden sich relativ stark voneinander, wenn es darum geht, wie Komponenten benutzt werden. React ist vollständig auf deklaratives Programmieren ausgelegt, während Web Components und auch Standard-HTML-Tags eine Mischform vorsehen, die teilweise deklarativ, an einigen Stellen aber eben auch zwingend imperativ ist. Und da React-Entwicklerinnen und -entwickler genau diesen deklarativen Charakter von React mögen, kann es nicht die Lösung sein, die imperative API von Web Components einfach blind zu übernehmen. Stattdessen müssen Wege gefunden werden, wie eine Zusammenarbeit zwischen diesen beiden „Welten“ möglich ist. Leider dauert der Prozess dieser Lösungssuche mittlerweile schon relativ lange an und zwischenzeitlich schien die Diskussion innerhalb der Community der React-Entwicklerinnen und -Entwickler ein bisschen eingeschlafen zu sein.
Es bleibt daher nur zu hoffen, dass dieser Prozess wieder Fahrt aufnimmt, so dass Web Components in Zukunft auch in React-Projekten einfach und ohne umständliche Umwege eingesetzt werden können.
So genannte „Web Components“ sind eine Möglichkeit, wiederverwendbare UI-Komponenten für Web-Anwendungen zu bauen. Anders als bei etablierten Single-Page-App-Frameworks wie React oder Angular basiert das Komponenten-Modell aber auf Web-Standards. Da SPA-Frameworks aber weit mehr leisten als nur Komponenten zu bauen, stehen Web Components nicht in unmittelbarer Konkurrenz zu den etablierten Frameworks. Sie können diese aber sinnvoll ergänzen. Insbesondere dann, wenn Komponenten über Anwendungen mit verschiedenen Technologie-Stacks hinweg wiederverwendet werden sollen, können Web Components einen guten Dienst leisten.
Im Detail verbergen sich aber doch einige Tücken, wenn es um den Einsatz von Web Components in Single-Page-Anwendungen geht: Während die Einbindung in Angular-Anwendungen relativ einfach funktioniert, gibt es insbesondere bei React-Anwendungen einiges zu beachten.
Ob die „Schuld“ hierfür nun bei React oder dem Web-Components-Standard liegt, kommt auf die Perspektive an und ist nicht ganz so leicht zu beantworten. Es gibt aber auch Aspekte, bei denen Web Components auch in ihrer Kernkompetenz, dem Bauen von Komponenten den Kürzeren ziehen. Denn manches ist im Vergleich, z. B. mit React, unnötig kompliziert oder unflexibel.
Abbildung 1: Web Components und SPA-Frameworks
In dieser Artikelreihe soll es um diese und weitere Aspekte beim Zusammenspiel von Web Components und SPA-Frameworks, insbesondere React, gehen. Im ersten Teil der Reihe liegt der Fokus aber zunächst nur auf Web Components, was sich hinter dem Begriff verbirgt und wie man Web Components baut.
Was sind Web Components und wie baut man eigene Komponenten?
Hinter dem Begriff „Web Components“ verbergen sich mehrere separate HTML-Spezifikationen, die verschiedene Aspekte beim Entwickeln eigener Komponenten behandeln. Es gibt also nicht „den einen“ Standard für Web Components, sondern es handelt sich um eine Kombination von mehreren Spezifikationen.
Die beiden wichtigsten sind „Custom Elements“ und „Shadow DOM“. Die Custom-Elements-Spezifikation beschreibt u. a. die JavaScript-Basis-Klasse „HTMLElement“, von welcher eigene Komponenten abgeleitet werden müssen. Diese Klasse stellt zahlreiche Lifecycle-Methoden bereit, mit denen auf diverse Ereignisse im Lebenszyklus der Komponente reagiert werden kann. Beispielsweise lässt sich programmatisch darauf reagieren, dass die Komponente in einem Dokument eingehangen oder Attribute der Komponente gesetzt wurden. Entwickler und Entwicklerinnen einer Komponente können daraufhin die Darstellung der Komponente aktualisieren. Außerdem gehört zu Custom Elements die Möglichkeit, eigene Komponenten-Klassen unter einem bestimmten HTML-Tag zu registrieren, damit die Komponente anschließend im gesamten Dokument zur Verfügung steht.
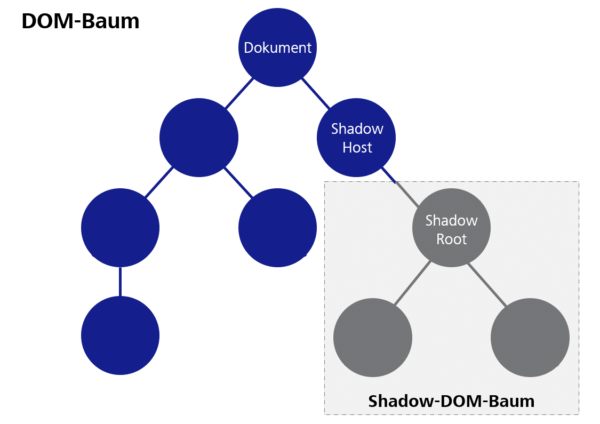
Hinter „Shadow-DOM“ verbirgt sich eine Technik, mit der für eine Komponente ein eigener DOM-Baum angelegt werden kann, der vom restlichen Dokument weitestgehend isoliert ist. Das bedeutet, dass zum Beispiel CSS-Eigenschaften, die global im Dokument gesetzt wurden, nicht im Shadow-DOM wirksam sind und in die andere Richtung auch CSS-Definitionen innerhalb einer Komponente keine Auswirkungen auf sonstige Elemente im Dokument haben. Das Ziel ist eine bessere Kapselung der Komponenten und die Vermeidung von unerwünschten Seiteneffekten beim Einbinden von fremden Webkomponenten.
Im folgenden Code-Block ist eine einfache Hallo-Welt-Komponente zu sehen, die ein Property für den Namen der zu grüßenden Person enthält.
Im Konstruktor der Komponente wird zunächst für die Komponente ein eigener Shadow-DOM-Baum angelegt. Die Angabe „mode: open“ bewirkt, dass trotz der Shadow-DOM-Barriere von außen mittels JavaScript auf den DOM-Baum der Komponente zugegriffen werden kann.
Anschließend wird der „shadowRoot“, also der Root-Knoten des Shadow-DOM, entsprechend unserer Wünsche gestaltet – hier mittels „innerHTML“.
Mit „observedAttributes“ erklären wir, welche Attribute die Komponente haben soll bzw. bei welchen Attributen wir benachrichtigt werden möchten (wir können hier also auch Standard-Attribute wie „class“ angeben).
Die Benachrichtigung findet über die Methode „attributeChangedCallback“ statt, die als Parameter den Namen des geänderten Attributs sowie den alten und neuen Wert erhält. Da wir in unserem Fall nur ein einziges Attribut in „observedAttributes“ angegeben haben, wäre eine Prüfung auf den Namen des Attributs eigentlich nicht notwendig. Bei mehreren Attributen muss aber stets geschaut werden, welches Attribut gerade geändert wurde.
In unserem Fall prüfen wir zunächst, ob sich der neue Wert tatsächlich vom bisherigen unterscheidet (wir werden später noch sehen, wie das zustande kommen kann). Anschließend setzen wir die Property „person“, die wir als Klassenvariable angelegt haben, auf den Wert des übergebenen Attributs.
Um die Darstellung der Komponente zu aktualisieren wurde im Beispiel die Methode „update“ angelegt. Diese gehört nicht zum Custom-Elements-Standard, sondern dient hier nur dazu, die Update-Logik an einer Stelle zu sammeln. Darin holen wir das zuvor angelegte Span-Element mit der ID „person“ aus dem Shadow-DOM und setzen dessen Text auf den Wert der „person“-Property.
Abbildung 2: Shadow DOM
Als letzten Schritt sieht man im Code-Beispiel, wie unsere Komponenten-Klasse mit dem Tag-Namen „app-hello-world“ registriert wird. Wichtig ist hier, dass der Name mindestens ein Minus-Zeichen enthält. Diese Regel wurde geschaffen, um mögliche Namens-Kollisionen mit zukünftigen Standard-HTML-Tags zu vermeiden. Es hat sich daher als zweckmäßig erwiesen, ein sinnvolles Präfix für eigene Komponenten zu wählen, um so auch Kollisionen mit anderen Komponenten-Bibliotheken möglichst zu vermeiden (das im Beispiel gewählte Präfix „app“ dürfte in dieser Hinsicht kein gutes Vorbild sein). Ein wirklich sicherer Mechanismus zur Vermeidung von Konflikten existiert jedoch nicht.
Mittels Attribute haben wir nun also die Möglichkeit, einfache Daten in die Komponente hineinzureichen. Beim Thema „Attribute“ gibt es noch einige Besonderheiten und Fallstricke, die wir aber für den nächsten Teil dieser Artikelreihe aufheben wollen. Für diese allgemeine Einführung wollen wir es erst einmal dabei belassen.
Slots
Ein weiteres wichtiges Feature von Web Components, welches uns ebenfalls in einem späteren Teil der Reihe nochmal beschäftigen wird, sind die sogenannten Slots. Damit lassen sich HTML-Schnipsel an eine Komponente übergeben. Die Komponente entscheidet dann, wie sie die übergebenen Elemente darstellt. Wollen wir beispielsweise eine Hinweisbox bauen, die neben einem Text auch ein Icon darstellt und mit einem Rahmen umgibt, bietet es sich an, den Hinweistext nicht als Attribut, sondern mit einem Slot an die Komponente zu geben. Auf diese Weise sind wir nicht nur auf reinen Text beschränkt, sondern können beliebigen HTML-Content nutzen.
In der Anwendung kann das beispielsweise so aussehen:
<app-notification-box>
<p>Some Text with additional <strong>tags</strong></p>
</app-notification-box>
Wir müssen also nur die gewünschten HTML-Tags als Kindelemente schreiben. Innerhalb der Komponente muss dafür ein <slot>-Element im Shadow-Root auftauchen. Anstelle des Slot-Elements wird beim Rendering der Komponente dann der übergebene Content angezeigt.
Eine Komponente kann auch mehrere Slots enthalten. Damit der Browser aber entscheiden kann, welche HTML-Elemente er welchem Slot zuordnen soll, müssen in diesem Fall sogenannte „Named Slots“ benutzt werden, d. h. die Slots bekommen ein spezielles Name-Attribut. Nur höchstens ein Slot darf innerhalb einer Komponente ohne Name-Attribut vorkommen. Bei diesem spricht man vom „Default Slot“. In der Komponente kann das z. B. so aussehen:
Hier sieht man die Nutzung des „slot“-Attributs. Die Werte müssen zu den „name“-Attributen an den Slots innerhalb der Komponente passen. Folglich gehört dies zum Teil der öffentlichen API einer Komponente und muss entsprechend dokumentiert werden.
Events
Bisher haben wir nur gesehen, wie Daten in Komponenten hineingereicht werden können, jedoch noch nicht den umgekehrten Weg skizziert. Denn um wirklich interaktiv zu sein, müssen Entwickler und Entwicklerinnen auch die Möglichkeit haben, auf bestimmte Ereignisse zu reagieren und Daten von der Komponente entgegenzunehmen.
Für diesen Zweck dienen bei HTML Events. Und auch diesen Aspekt wollen wir uns in diesem Artikel nur kurz anschauen und später genauer unter die Lupe nehmen.
Web Components können sowohl Standard Events als auch Custom Events erzeugen.
Standard-Events sind dann nützlich, wenn die Art des Events so auch schon bei Standard-HTML-Elementen vorkommt und daher nicht neu erfunden werden muss, beispielsweise ein KeyboardEvent. Custom-Events sind dann sinnvoll, wenn zusätzliche Daten als Payload dem Event mitgegeben werden sollen. Wenn wir beispielsweise eine eigene interaktive Tabellenkomponente bauen, in der die Nutzenden einzelne Zeilen selektieren können, bietet es sich möglicherweise an, ein Event bei der Selektion auszulösen , welches als Payload die Daten der gewählten Zeile enthält.
Der Mechanismus zum Auslösen von Events ist für alle Arten von Events gleich. Dies ist im folgenden Code-Block zu sehen:
Zur Erzeugung eines Events wird entweder direkt eine Instanz von „Event“ oder eine der anderen Event-Klassen (zu denen auch „CustomEvent“ gehört) erzeugt. Alle Event-Konstruktoren erwarten als ersten Parameter den Type des Events. Dieser Typ wird später auch benutzt, um Listener für diese Events zu registrieren.
Der zweite Parameter ist optional und stellt ein JavaScript-Objekt dar, welches das Event konfiguriert. Für CustomEvent ist beispielsweise das Feld „detail“ vorgesehen, um beliebige Payload-Daten zu übergeben.
Fazit
Der Artikel gibt eine kurze Einführung in das Thema „Web Components“ und mit den gezeigten Techniken können bereits eigene Komponenten gebaut werden. Natürlich gibt es noch zahlreiche weitere Aspekte, die bei der Entwicklung von Web Components beachtet werden müssen. Nicht umsonst füllt das Thema so manches Fachbuch. In dieser Artikelreihe wollen wir vor allem auf einige Fallstricke eingehen, die bei einzelnen Themen auftreten können und genauer beleuchten, wie diese umgangen werden können. Auch eine kritische Auseinandersetzung mit der Web-Components-API soll Teil dieser Serie werden. Insbesondere das Zusammenspiel mit SPA-Frameworks wird uns in den nächsten Artikeln beschäftigen.
Das Konferenzjahr 2017 startete im Januar – wieder mit der OOP. Auch diesmal befand sich eine Umfrage im Gepäck nach München. Wie im vorangegangenen Blogbeitrag zur WJax bereits beschrieben, wollten wir uns erneut dem Arbeitsumfeld der Befragten widmen. Dadurch ergibt sich die Möglichkeit, Rückschlüsse auf die zielgruppenabhängige Sichtweise auf eingespielte Teams zu ziehen, da die Rahmenbedingungen z.B. mit Fragen und Konferenzort im Vergleich zur WJax gleichbleibend sind. Einziger wesentlicher Unterschied ist bei den Funktionen der Umfrageteilnehmern festzustellen, da wir bei der OOP vorrangig Softwarearchitekten, Entscheider und Berater vorfinden, während die WJax überwiegend von Softwareentwicklern aufgesucht wird.
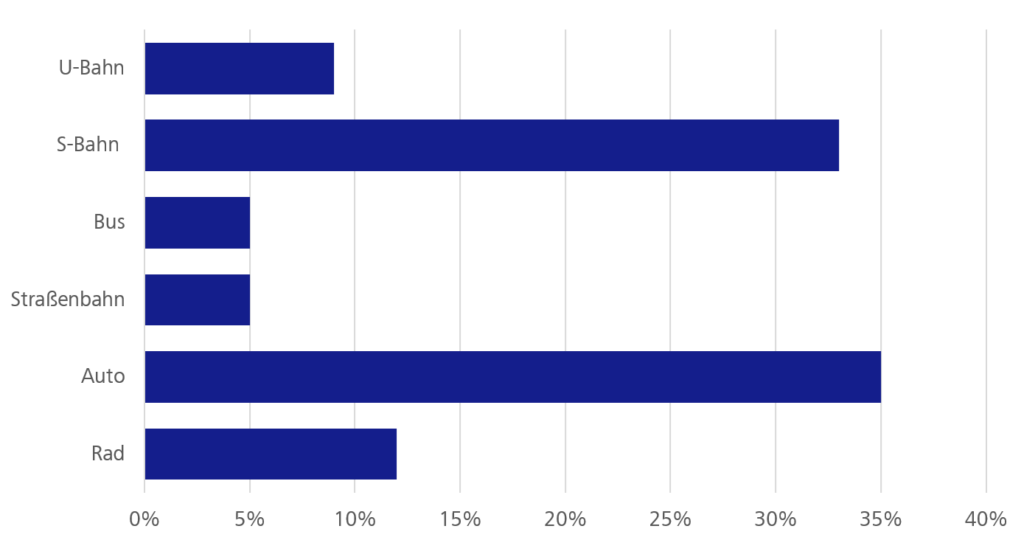
Durch den gleichen Aufbau der Fragebögen startet auch dieser mit der Frage, wie die Teilnehmer ihren Arbeitsweg zurücklegen. Die Aussagen weichen hier nur bedingt von denen der WJax ab. Das am stärksten genutzte Mittel ist weiterhin der PkW, auch wenn die S-Bahn ebenfalls weit mehr frequentiert ist, als andere öffentliche Verkehrsmittel.
Abbildung 1: Mit welchem Verkehrsmittel legen Sie Ihren Arbeitsweg zurück?
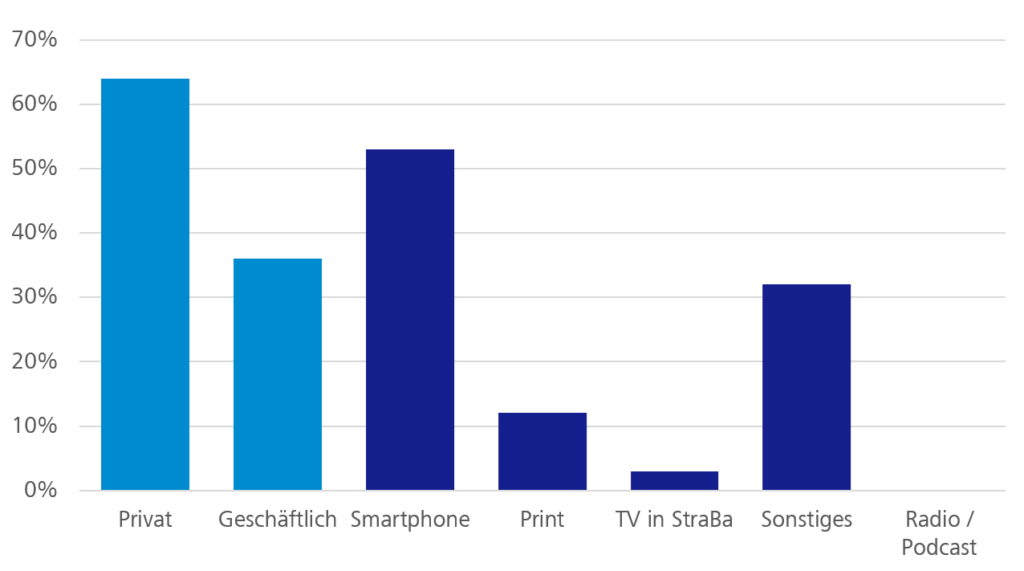
Der darauffolgenden Frage „Wie beschäftigen Sie sich auf dem Weg zur Arbeit?“ lagen weiterhin zwei Gedanken zu Grunde. Erstens ist es üblich, dass heutzutage immer wieder bereits auf dem Arbeitsweg erste Mails bearbeitet, neueste Nachrichten aufgeschnappt oder Fachartikel gelesen werden. Doch wie viele Personen beschäftigen sich tatsächlich mit geschäftlichen Dingen? Zweitens stellte sich die Frage, ob im Zeitalter der Digitalisierung Smartphone und Laptop die klassischen Medien gänzlich verdrängt haben. Daher ist unser Interesse darauf gerichtet, welches Medium vorrangig zum Informationskonsum genutzt wird.
Abbildung 2: Beschäftigung auf dem Arbeitsweg
Geht es um die Nutzungszwecke, sieht man auch in dieser Umfrage den deutlichen Vorsprung der digitalen Medien gegenüber den klassischen, wie Print und Fernsehen in Straßenbahnen. Auch nur vereinzelt werden Radio oder Hörbuch angegeben. Damit wird deutlich, dass das Smartphone immer mehr zur „Allzweckwaffe“ wird, da es die verschiedenen Kanäle auf Grund der vielfältigen Nutzungsoptionen miteinander vereint.
Auffällig ist jedoch, dass im Vergleich zur WJax die geschäftliche Nutzung einen Aufschwung verzeichnet. Mit gut 1/3 zu 2/3 liegen geschäftliche und private Nutzung hier nicht so weit von einander entfernt. Dies bestätigt unsere Erfahrungen, dass mit zunehmendem Entscheiderlevel der Arbeitsweg bereits durch Vorgänge im Arbeitsalltag bestimmt wird.
Zusammenarbeit – eingespielte Teams als Erfolgsgarant?
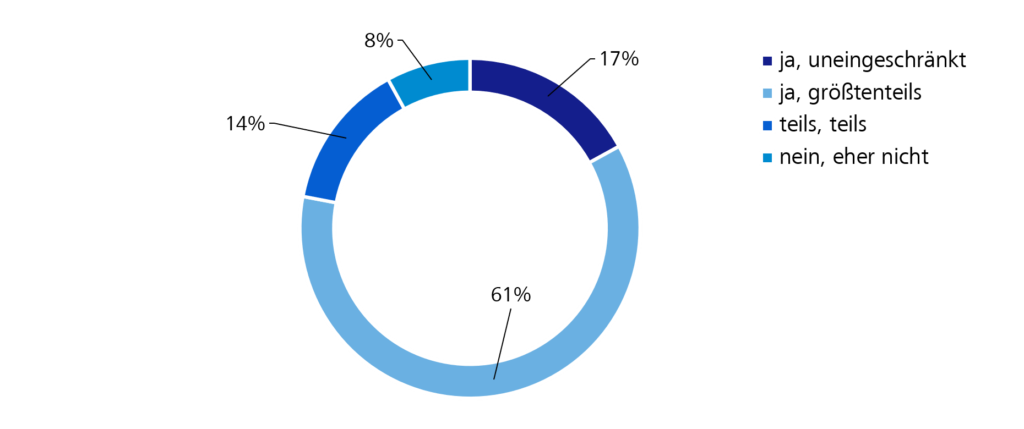
Abbildung 3: Stimmen Sie der These „Stabile Teams sind ein Garant für Projekterfolge“ zu?
Beim Einstieg in den inhaltlichen Bereich wird deutlich, dass sich die Meinungen auf den Konferenzen nicht so stark voneinander differenzieren. Der These Stabile Teams sind ein Garant für Projekterfolge stimmen in Summe 78 % zu, damit liegt dieser Wert nur 3 Prozentpunkte unter dem der WJax. Ebenso die „unentschlossenen“ Antworten, die sowohl Vor- als auch Nachteile in stabilen Teams sehen und sich nicht festlegen können, ähneln sich auf den Konferenzen (14 % zu 16 %).
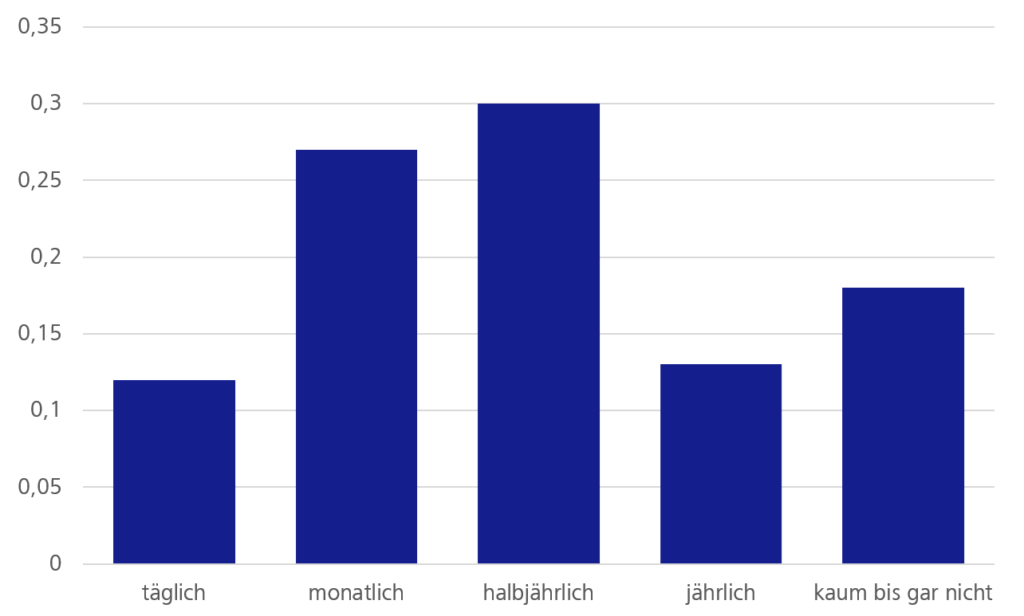
Abbildung 4: Wie oft ändert sich Ihr Kollegenkreis in Ihrer Arbeitsumgebung?
Betrachtet man die kollegialen Veränderungen durch Mitarbeiterfluktuation, findet sich auch hier ein ähnliches Bild. Nur gut 1/5 gibt an, dass sich ihr Kollegenkreis kaum bis gar nicht ändert. Damit zeigt sich eine noch stärkere Tendenz zu instabilen Teams. Es ist ebenfalls keine Abhängigkeit von dem Kollegenumkreis bzgl. ihrer Angestelltensituation erkennbar, beispielsweise ob ausschließlich mit internen Kollegen gearbeitet wird.
Abbildung 5: Ihre Kollegen sind …
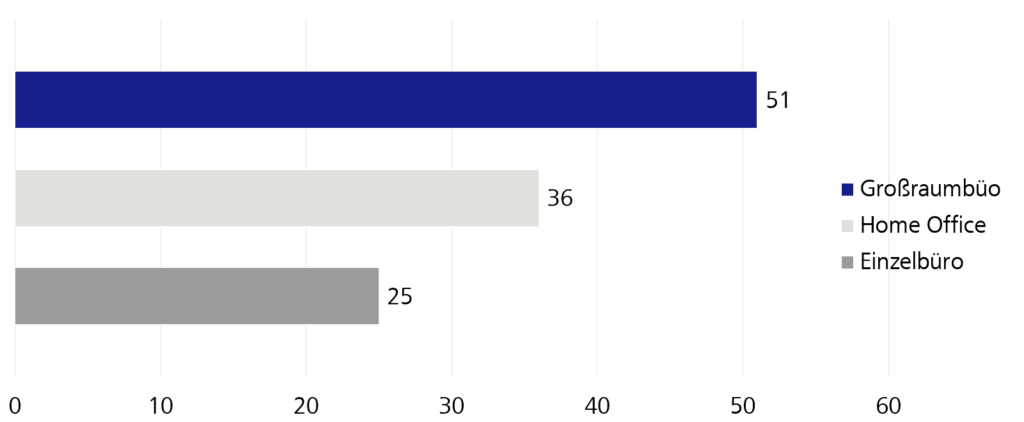
Ein weiterer Faktor, den wir erhoben haben, um besser das Arbeitsumfeld der Befragten verstehen zu können, ist das Wo gearbeitet wird. Dabei lässt sich auch ein entscheidender Unterschied zur WJax-Umfrage feststellen. Während dort gut doppelt so viele im Großraumbüro vergleichend zum Einzelbüro saßen, unterscheiden sich hier die Zahlen kaum voneinander.
Auf Grund dessen, dass diese Frage Mehrfachantworten zulässt, steht Home Office als weitere Antwort zur Verfügung. Da das Home Office aber ebenso wie auf der WJax bei keiner Befragung eigenständig angegeben worden ist, sondern nur in Verbindung mit den anderen beiden Optionen, lässt sich hier nur der Unterschied in der Verteilung auf die beiden anderen Optionen wahrnehmen: zwei Drittel ergänzen damit das Großraumbüro, ein Drittel das Einzelbüro.
Abbildung 6: Wie ist Ihr Arbeitsort beschaffen?
Ebenfalls als Einfluss auf die Stabilität von Teams, z.B. in Hinblick auf Aufgabenfokussierung, Kommunikationswege und Termine, stellt sich die Frage nach der Anzahl der Projekte, die zu absolvieren sind. Identische Werte zur WJax Umfrage (siehe Abbildung 7) zeigen, dass die stabilen Teams mit Barrieren, wie hohen Koordinationsaufwänden für jeden Einzelnen, die sich aus Deadlines, unterschiedlichen Anforderungen und Kommunikation mit den entsprechenden Teams, zu kämpfen haben. Diese (Konferenz-)zielgruppenübergreifenden Probleme lassen sich dadurch erklären, dass die Teams erst durch die Zusammensetzung verschiedenster Personenkreise zu Stande kommen und dadurch für alle Beteiligten die gleiche Situation vorhanden ist.
Abbildung 7: Arbeiten Sie an einem oder an mehreren Projekten?
Ein full-size Hintergrundbild mit CSS3 zu setzen, ist doch kein Problem, oder? Im Internet finden sich viele Lösungen. Die funktionieren auf den ersten Blick auch ganz gut, aber schaut man etwas genauer hin, wird man häufig enttäuscht. Sollte man ein 2 MB großes Bild an mobile Geräte mit 3G ausliefern? Wohl eher nicht. Werden mobile Browser auch unterstützt? Dazu findet man häufig keine Angaben und bei einem eigenen Test fällt die Standardlösung durch. Also stellt sich zunächst die Frage: Was macht ein gutes full-size Hintergrundbild aus?
Es ist immer scharf.
Es verbraucht nicht zu viel Netzwerk-Traffic.
Es ist zentriert.
Es ist nicht verzerrt.
Es passt sich ohne Whitespaces der Größe des Endgeräts oder Browserfensters an.
Es sieht dazu noch in allen gängigen Browsern – vom Android-Browser über Chrome, Safari und Firefox bis hin zum Internet Explorer – gleich aus.
Gibt es eine einfache und saubere Lösung, um all diese Punkte zu erfüllen?
Wer zur Auswahl des richtigen Motivs recherchiert oder eine svg-Datei als Hintergrund verwenden möchte, sucht hier leider an der falschen Stelle. Wer aber auf der Suche nach einer fundierten Antwort für das geschilderte Problem ist, sollte diesen Artikel lesen. Und wer nur schnell eine Lösung braucht, um ein Hintergrundbild auf seine Seite zu zaubern, sollte gleich bis ganz nach unten scrollen.
Das perfekte Bild
Bilder im Web haben sich mit der wachsenden Vielfalt der Bildschirmgrößen und den damit einhergehenden responsiven Designs zu einer eigenen Wissenschaft entwickelt. Unter dem “perfekten Hintergrundbild” ist daher vielmehr eine Komposition aus Bildgrößen zu verstehen, die für verschiedene Anforderungen optimiert sind. Aber welche Anforderungen müssen überhaupt erfüllt werden? Und wie kann ich diese erfüllen?
Was muss alles beachtet werden?
Generell sollte die User Experience – also die Wahrnehmung der Web-Plattform durch den Nutzer – im Vordergrund stehen. Auch Google sieht das so und macht viele seiner Rankingfaktoren für Suchergebnisse daran fest.
Hier die vier wichtigsten Punkte in Bezug auf Hintergrundbilder.
1. Kurze Ladezeiten sind essentiell für die User Experience
Wie eine Studie zeigt, brechen 65% der Online-Shopper nach drei Sekunden Wartezeit ihren Einkauf ab und kommen in vielen Fällen nie zurück. Dieses Ergebnis lässt sich auch allgemein auf Webauftritte übertragen. Bilder sollten daher möglichst wenig Downloadzeit beanspruchen, also klein sein.
2. Google rankt Seiten mit langen Ladezeiten schlechter
Das heißt, dass Dein Webauftritt in den Suchergebnissen weiter unten steht, je langsamer Deine Seite ist.
3. Das Ganze muss dann auch noch gut aussehen
Bilder werden vom Gehirn schneller wahrgenommen als andere Inhalte und sprechen die Gefühle des Nutzers an. Außerdem lässt sich ein Gefühl schwer durch Inhalte ausgleichen. Ein verpixeltes oder verzerrtes Bild wirkt sich negativ auf die Glaubwürdigkeit Deines Webauftritts aus und führt dazu, dass ein Nutzer die Seite schnell wieder verlässt, auch wenn die Performance stimmt.
4. Absprungrate ist Rankingfaktor
Zwar prüfen Suchmaschinen aktuell nicht, ob ein Bild optisch ansprechend ist, aber über die Absprungrate kann sich ein Bild mit schlechter Qualität auch auf den Rang Deiner Plattform in den Suchergebnissen niederschlagen.
Zusammenfassend heißt das:
Dein Hintergrundbild sollte so klein wie möglich, aber so groß wie nötig sein.
Welches Dateiformat sollte ich nutzen?
Für Fotos spielen im Web-Umfeld zwei Dateiformate eine wichtige Rolle: png und jpg. Das png-Format besitzt generell einen höheren subjektiven Detailreichtum, da bei der Komprimierung nur die Menge der Farben reduziert wird. Zudem unterstützt es den Alphakanal, das heißt, dass es durchsichtige Flächen ermöglicht. Der Vorteil von jpg liegt in der Komprimierung und der daraus resultierenden geringen Dateigröße.
Da für Hintergrundbilder selten viele Details oder Transparenz benötigt werden, es aber auf die Dateigröße ankommt, bietet sich in diesem Fall das jpg-Format an.
Welche Bildgrößen brauche ich?
Eine abschließende Antwort auf diese Frage wirst Du erst im Abschnitt “Media Queries” finden. Zunächst gibt es aber einige Punkte, die in die Auswahl geeigneter Bildgrößen einfließen und so zu einem tieferen Verständnis von Bildern im Web beitragen.
Um das passende Hintergrundbild für jede Bildschirmgröße auszuliefern, nutzen wir Media-Queries zur Einordnung in Größenbereiche. Jedem dieser Bereiche teilen wir dann ein für ihn optimiertes Bild zu. Nehmen wir z. B. einen Bereich, der Bildschirmbreiten von 320 bis 640 Pixel abdeckt. Ein Hintergrundbild für diesen Bereich sollte mindestens in der Breite von 640 Pixeln vorliegen. Die dots per inch (dpi) spielen dabei keine Rolle (72 dpi: Die größte Lüge des Webs).
Auch das Verhältnis zwischen logischen und physischen Pixeln (Pixel-Verhältnis) sollte bei der Wahl der geeigneten Bildgrößen einfließen. Das Pixel-Verhältnis gibt an, aus wie vielen physischen Pixeln (Gerätepixel) ein logischer Pixel (CSS Pixel) zusammengesetzt wird. Bei einem Wert von zwei wird jeder Bildpunkt Deines Hintergrundbildes mit vier Pixeln dargestellt (jeweils zwei in Höhe und Breite). Das führt dazu, dass ein 640 Pixel breites Bild auf einem 640 Pixel großen Bildschirm verpixelt aussieht. Daher sollte Dein Hintergrundbild in diesem Fall in doppelter Größe ausgeliefert werden.
Aktuell tummeln sich Pixel-Verhältnisse zwischen eins und fünf auf dem Markt. Theoretisch müssten also Bilder in bis zu fünffacher Größe bereitgestellt werden. Das würde vor allem mit Verbindungen im 3G-Bereich zu langen Ladezeiten führen. Allerdings kann das menschliche Auge bei einem Pixel-Verhältnis von eins ab einem Abstand von etwas mehr als der Bildschirmdiagonale keine Pixel mehr erkennen. Bei einem Pixel-Verhältnis von zwei wird dieser Abstand halbiert. Das heißt, dass man sich bei einem Pixel-Verhältnis von zwei schon die Nase an seinem Smartphone plattdrücken müsste, um Pixel zu erkennen. Für den Normalgebrauch reicht es also, Bilder in doppelter Größe bereitzuhalten.
Bleibt noch die Frage, bis zu welcher Bildgröße man geht. Momentan ist überall von 4K-Monitoren (meist 3840×2160 Pixel) die Rede und immer mehr Hersteller springen auf diesen Zug auf. Natürlich sind auch andere Größen wie beispielsweise 5K (MacBook Pro 2016) und 8K (Dell UltraSharp 32 Ultra HD 8K) auf dem Markt zu finden. Für welche Maximalgröße Du Dich entscheidest, liegt bei Dir. Dein Ausgangsbild sollte natürlich auch entsprechend groß sein.
Und wie optimiere ich jetzt mein Bild?
Stehen die Größen Deines Bilds fest, gibt es einige Tools oder Web-Apps, die die eigentliche Optimierung übernehmen. Photoshop bietet beispielsweise eine Funktion, um Bilder fürs Web zu exportieren. Da jedes Bild je nach Eigenschaften anders auf die Optimierungen reagiert, solltest Du ein wenig mit der Qualität und anderen Optionen spielen und mit dem Originalbild vergleichen. Dabei immer die Dateigröße und die damit verbundene Downloadzeit im Auge behalten. Letztere sollte im Einsatz in normalen Netzwerken (z. B. 3G) unter einer Sekunde bleiben. Um geeignete Downloadzeiten für Dateien zu ermitteln, können Onlinetools wie der Downloadrechner genutzt werden.
Um die gefühlte Wartezeit zu verringern, bietet das jpg-Format die progressive-Eigenschaft an. Diese wird vom IE ab Version 9 und von allen echten Browsern seit Urzeiten unterstützt. Anders als bei der üblichen baseline-Variante wird das Bild nicht zeilenweise von oben nach unten geladen, sondern schrittweise in seiner Qualität gesteigert.
Media-Queries
Leider gibt es noch keine Möglichkeit per CSS, JavaScript und Co die aktuelle Netzwerkgeschwindigkeit zu ermitteln und dementsprechend Bilder auszuliefern. Also muss man sich an der Bildschirmgröße und den Seitenverhältnissen orientieren und versuchen, das Bild für diese optisch ansprechend und so klein wie möglich zu gestalten. Wie oben schon erwähnt, werden hier CSS-Media-Queries dazu benutzt, das Hintergrundbild in verschiedenen Größen zu realisieren. Aber gibt es da nicht noch andere Methoden? Ja, die gibt es.
Warum dann ausgerechnet Media-Queries?
Man könnte beispielsweise verschiedene img-Elemente nutzen und diese per JavaScript ein- und ausblenden oder mit dem srcset-Attribut versehen. Aber diese Vorgehensweise verstößt gegen den Grundsatz der Trennung von Design und Inhalt. Wird ein Bild mittels img eingebunden, gehört es zum Inhalt, aber ein Hintergrundbild gehört eindeutig zum Design. Zudem wird das srcset-Attribut nicht vom Internet Explorer unterstützt.
Ok … und wie funktioniert das?
Mit Media-Queries kann man Styles an bestimmte Attribute knüpfen. Die Styles zeigen nur dann Wirkung, wenn das Attribut den gewünschten Wert hat. Für Hintergrundbilder sind besonders die Attribute min-width, max-width und orientation interessant. Diese richten sich nach Größe und Seitenverhältnis des Browserfensters und funktionieren daher sowohl im Vollbild- als auch im Fenstermodus. Die dabei verwendeten Werte nennt man Breakpoints. Bei Hintergrundbildern sorgen Breakpoints dafür, dass immer nur das für das aktuelle Browserfenster passende Bild heruntergeladen wird. Im unteren Beispiel ist der Hintergrund auf Geräten mit einer Breite von weniger als 640 Pixeln rot und auf größeren Geräten blau.
Das orientation-Attribut kann zwei Werte annehmen: landscape und portrait. Diese geben an, ob das Gerät aktuell breiter als hoch oder höher als breit ist. Also ob z. B. ein Smartphone hochkant oder quer gehalten wird. Da sich unser Hintergrundbild mit der längsten Kante des Browserfenster skaliert und im Normalfall breiter als hoch ist, müssen für Geräte im Protrait-Modus größere Bilder ausgeliefert werden. Wenn beispielsweise ein Tablet (16:9) im Portrait-Modus 640 Pixel breit und 1130 Pixel hoch ist, bekommt es das Bild (4:3) mit 640 Pixeln Breite und 480 Pixeln Höhe ausgeliefert. Also wird das Bild auf mehr als das Doppelte skaliert und dadurch unansehnlich. Daher sollte hier das Bild entsprechend größer ausgeliefert werden.
Und welche Breakpoints benutze ich jetzt für mein Hintergrundbild?
Wie generell im CSS ist es auch hier wichtig, das mobile-first-Prinzip anzuwenden. Das heißt, dass ma Styles für kleine Bildschirmgrößen ohne Media-Query angibt und dann Styles für größere Bildschirme mittels Media-Queries hinzufügt oder überschreibt. Für Hintergrundbilder sollte man gleichzeitig darauf achten, ob man im generellen Style das Bild für landscape oder portrait ausliefert.
In den Anfangsjahren der Media-Queries wurden Breakpoints noch für bestimmte Standardbildschirmgrößen vergeben. Doch durch die sehr hohe Gerätevielfalt werden die Breakpoints der Media-Queries mittlerweile anhand des Inhalts gewählt. Für unser full-size Hintergrundbild gibt es nun zwei Vorgehensweisen. Entweder verwendet man seine bis dahin gewählten Breakpoints wieder oder man wählt eigene für das Hintergrundbild. Beim Vergeben von eigenen Breakpoints kann man sich an vielem orientieren, z. B. an den DevTools seines Lieblingsbrowsers, den HD-Standards oder man denkt sich selbst etwas aus.
Ich beginne meine Designs gern bei einer minimalen Größe von 320 Pixeln. Das entspricht den älteren iPhones und ist aktuell das schmalste Smartphone, das ich kenne. Um weniger Bilder erzeugen zu müssen, orientiere ich mich an diesem Wert und verdopple ihn immer wieder. So kann ich Bilder mehrfach verwenden.
Meine Breakpoints:
640 Pixel
1280 Pixel
2560 Pixel
5120 Pixel
Mit dieser Variante kann man z. B. bei einer Breite von unter 1280 Pixeln im Landscape-Modus das auf 1280 Pixel Breite optimierte Bild verwenden. Sollte der Bildschirm ein Pixel-Verhältnis von zwei haben und/oder hochkant gehalten werden, liefert man das 2560 Pixel breite Foto aus. Das Bild wird für den Portrait-Modus dann je nach Seitenverhältnis zwar immer noch skaliert, aber nur in geringem Maße. Erfahrungsgemäß sind leichte Skalierungen kein Problem. Da leider keine Möglichkeit besteht, das Seitenverhältnis des Geräts mittels Media-Query zu ermitteln, lässt sich das auch nur schwer optimieren. Wer hier weiter optimieren möchte, kann mittels JavaScript das Seitenverhältnis ermitteln und entsprechende Klassen mit der Hintergrund-URL vergeben.
Und das Pixel-Verhältnis?
Es gibt auch “ein” Media-Query-Attribut für das schon oft genannte Pixel-Verhältnis (Cross browser retina/high resolution media queries). Leider ist der Browsersupport aktuell schlecht. Safari benötigt das `-webkit-`-Präfix und Google Chrome liefert trotz Media-Query immer das Bild für das höhere Pixel-Verhältnis aus. Eine erschöpfende Lösung für dieses Problem wird hoffentlich mit der Zeit kommen. Um eine beinahe Abdeckung zu erreichen, muss man folgende zwei Attribute vergeben:
Das , zwischen Attributen bedeutet so viel wie “oder”. Jeder Browser nutzt dabei die Query, die für ihn passt. Wie feingranular man das Pixel-Verhältnis abfragt und speziell optimierte Bilder ausliefert, ist jedem selbst überlassen. Um die pixel-ratio in dpi umzurechnen, muss man den Wert mit dem Faktor 96 multiplizieren.
Je nach angestrebter Ladezeit, kann man die Bilder auch generell in doppelter Größe ausliefern. Damit umgeht man das Problem, dass beim Drehen des Geräts neue Bilder geladen werden müssen.
Styling des Hintergrundbilds
Es gibt zwei Möglichekeiten, wo man sein Hintergrundbild setzt. Direkt im `body` oder in einem anderen Block-Element. Wobei die zweite Variante nur genutzt werden sollte, wenn es absolut notwendig ist.
Häufig findet man im Netz folgende Lösung:
body {
width: 100%;
height: 100%;
background-image: url('background.jpg');
background-repeat: no-repeat;
background-position: center center;
background-size: cover;
background-attachment: fixed;
}
Was will man damit erreichen?
Zunächst setzt man width und height auf 100%, um den gesamten Viewport auszufüllen.
Man setzt ein Hintergrundbild mit background-image, kein Hexenwerk.
Man verhindert mit background-repeat: no-repeat;, dass der Hintergrund wiederholt und damit gekachelt wird.
Mittels background-position: center center; zentriert man das Bild horizontal und vertikal.
Das Anpassen des Bilds an den Viewport übernimmt background-size. cover heißt, dass das Bild den Viewport ohne Whitespaces ausfüllt.
background-attachment: fixed; setzt das Bild fix. Damit scrollt es nicht weg, wenn body höher ist als der Viewport.
Klingt gut, aber…
Mobile Geräte passen das Bild in dieser Variante an den Inhalt an. Das heißt an die Gesamthöhe des Webauftritts. Sobald gescrollt werden muss, wird auch das Bild skaliert und es verpixelt sehr schnell. Um diesem Problem Herr zu werden, lohnt sich der Einsatz von noch ziemlich unbekannten Einheiten im CSS: vw und vh. vw steht für die Viewport-Width und vh für Viewport-Height. Diese Einheit wird von allen gängigen Browsern und dem IE ab Version 9 unterstützt. Mit width: 100vw; und height: 100vh; setzt man damit Höhe und Breite wirklich auf 100% der Höhe und Breite des Viewports. Das hat auch den Effekt, dass die Scrollbar von Windows-Browsern beim Erscheinen das Hintergrundbild nicht verändert. Zudem sollte das overflow-Attribut in html und body gesetzt werden.
Gibt es sonst noch Probleme?
Versucht man das Ganze z. B. auf ein div-Element zu übertragen, treten neue Probleme auf:
Auf mobilen Geräten wird das Bild wieder auf die Höhe des Inhalts verzerrt.
Bei bestimmten Skalierungen bekommt man eine Scrollbar am unteren Bildschirmrand angezeigt.
Im Internet Explorer tritt ein hässlicher Flackereffekt beim Scrollen auf.
Punkt 1 und 3 lassen sich lösen, indem background-attachment: fixed; durch position: fixed; ersetzt wird.
Für Punkt 2 muss overflow: auto; in html und body gesetzt werden.
Leider nicht. Wendet man die Variante für Block-Elemente auf den body an, verschiebt sich das Bild nach oben. Versucht man die Lösungen zu kombinieren und setzt sowohl background-attachment: fixed; als auch position: fixed; auf dem body-Element, flackert es im IE. Bei Anwendung beider Attribute auf ein Block-Element ändert sich nichts am Ursprungsproblem.
Und jetzt nochmal kurz zusammengefasst
Bilddateien sollten klein und trotzdem ansehnlich sein.
Hintergrundbilder sollten weniger als eine Sekunde zum Laden im 3G Netz benötigen, also kleiner als ~900 KB sein.
Das progressive-Attribut sollte in allen jpg-Dateien gesetzt sein.
Zur Auslieferung passender Bilder für verschiedene Bildschirmgrößen sollten Media-Queries benutzt werden.
Wähle deine Breakpoints weise.
Für Bildschirme mit einem hohen Pixel-Verhältnis sollten Bilder in doppelter Größe ausgeliefert werden.
Ebenso für Querformat-Bilder auf Geräten im Hochformat.
Setze das Hintergrundbild mit CSS.
Nutze die Einheiten vw und vh anstelle von %.
Browser sind Schweine, teste so viel Du kannst!!!
### Noch ein Beispiel gefällig?
Ich habe mich hier für eine Auflösung von bis zu 5K entschieden und darauf beschränkt, hohe Pixel-Verhältnisse nur bis Full-HD zu bedienen. Das größere Bild liefere ich bei einem Pixel-Verhältnis von 1,5 aus.
html, body {
overflow: auto;
}
body {
width: 100vw;
height: 100vh;
/* picture for a device-width between 0 and 640px in landscape-mode */
background-image: url(background_640.jpg);
background-repeat: no-repeat;
background-position: center center;
background-size: cover;
/* change */
background-attachment: fixed;
/* to */
/* position: fixed; */
/* if your style is not added to body */
}
@media (orientation: portrait),
(-webkit-min-device-pixel-ratio: 1.5),
(min-resolution: 144dpi) {
body {
background-image: url(background_1280.jpg);
}
}
@media (min-width: 640px) and (orientation: landscape) {
body {
background-image: url(background_1280.jpg);
}
}
@media (min-width: 640px) and (orientation: portrait) {
body {
background-image: url(background_2560.jpg);
}
}
@media (min-width: 640px) and (-webkit-min-device-pixel-ratio: 1.5),
(min-width: 640px) and (min-resolution: 144dpi) {
body {
background-image: url(background_2560.jpg);
}
}
@media (min-width: 1280px) and (orientation: landscape) {
body {
background-image: url(background_2560.jpg);
}
}
@media (min-width: 1280px) and (orientation: portrait) {
body {
background-image: url(background_5120.jpg);
}
}
@media (min-width: 1280px) and (-webkit-min-device-pixel-ratio: 1.5),
(min-width: 1280px) and (min-resolution: 144dpi) {
body {
background-image: url(background_5120.jpg);
}
}
@media (min-width: 2560px) and (orientation: landscape) {
body {
background-image: url(background_5120.jpg);
}
}