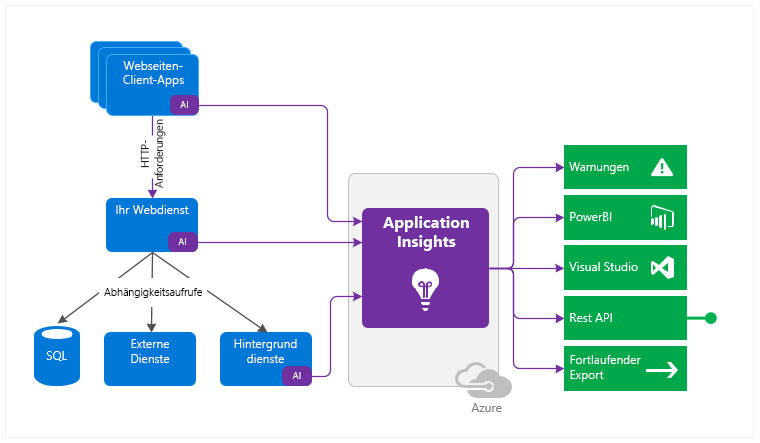
Mit Application Insights liefert Microsoft einen Dienst zur Anwendungsüberwachung für Entwicklung und DevOps. Damit kann so gut wie alles erfasst werden – von Antwortzeiten und -raten über Fehler und Ausnahmen, Seitenaufrufe, Benutzer (-Sitzungen), Backend bis hin zu Desktop-Anwendungen.
Die Überwachung beschränkt sich keinesfalls nur auf Webseiten. Application Insights lässt sich auch bei Webdiensten sowie im Backend einsetzen. Sogar Desktop-Anwendungen lassen sich überwachen. Anschließend können die Daten über unterschiedliche Wege analysiert und ausgewertet werden (siehe Abbildung 1).
Loggen
Als Ausgangsbasis wird eine Azure Subscription mit einer Application-Insights-Instanz benötigt. Ist diese angelegt, findet man in der Übersicht den sogenannten Instrumentation Key – dieser fungiert als Connection String.
Sobald die Instanz bereitgestellt wurde, kann auch schon mit der Implementierung begonnen werden. Programmiertechnisch ist man hier keinesfalls auf Azure-Ressourcen oder .Net beschränkt. Microsoft unterstützt eine Vielzahl an Sprachen und Plattformen.
Als Beispiel dient hier eine kleine .Net-Core-Konsolenanwendung. Dazu muss lediglich das NuGet-Paket Microsoft.ApplicationInsights eingebunden werden und schon kann es losgehen.
Als erstes wird ein Telemetry Client erstellt. Hier wird einfach der passende Instrumentation Key aus der eigenen Application-Insights-Instanz eingefügt und schon ist die Anwendung bereit für die ersten Log-Einträge.
- Mit Trace erzeugt man einen einfachen Trace-Log-Eintrag mit entsprechender Message und passendem Severity Level.
- Events eignen sich für strukturierte Logs, welche sowohl Text als auch numerische Werte enthalten können.
- Metrics sind dagegen ausschließlich numerische Werte und dienen daher vor allem zur Erfassung regelmäßiger Ereignisse.
static void Main(string[] args)
{
Console.WriteLine("Schau mir in die Augen");
var config = TelemetryConfiguration.CreateDefault();
config.InstrumentationKey = "INSTRUMENTATIONKEY";
var tc = new TelemetryClient(config);
// Track traces
tc.TrackTrace("BlogTrace", SeverityLevel.Information);
// Track custom events
var et = new EventTelemetry();
et.Name = "BlogEvent";
et.Properties.Add("Source", "console");
et.Properties.Add("Context", "Schau mir in die Augen");
tc.TrackEvent(et);
// Track custom metric
var mt = new MetricTelemetry();
mt.Name = "BlogMetric";
mt.Sum = new Random().Next(1,100);
tc.TrackMetric(mt);
tc.Flush();
}Als Hinweis sei noch erwähnt, dass die Log-Einträge mit bis zu fünf Minuten Verzögerung im Application Insights erscheinen.
Zusammenspiel mit NLog
Application Insights lässt sich mit wenigen Schritten auch in eine bestehende NLog-Konfiguration einbinden.
Dazu müssen das NuGet-Paket Microsoft.ApplicationInsights.NLogTarget installiert und danach die NLog-Konfiguration um folgende Einträge erweitern werden:
- Extensions mit dem Verweis auf die Application Insights Assembly hinzufügen
- Neues Target vom Typ Application Insights Target (hier wieder den eigenen Instrumentation Key angeben)
- Neue Regel mit Ziel auf das Application Insights Target
<nlog xmlns="http://www.nlog-project.org/schemas/NLog.xsd"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
throwConfigExceptions="true">
<extensions>
<add assembly="Microsoft.ApplicationInsights.NLogTarget" />
</extensions>
<targets>
<target name="logfile" xsi:type="File" fileName="log.txt" />
<target name="logconsole" xsi:type="Console" />
<target xsi:type="ApplicationInsightsTarget" name="aiTarget">
<instrumentationKey>INSTRUMENTATIONKEY</instrumentationKey>
<contextproperty name="threadid" layout="${threadid}" />
</target>
</targets>
<rules>
<logger name="*" minlevel="Info" writeTo="logconsole" />
<logger name="*" minlevel="Debug" writeTo="logfile" />
<logger name="*" minlevel="Trace" writeTo="aiTarget" />
</rules>
</nlog>Auswertung
Die Auswertung erfolgt anschließend über das Application-Insights-Portal. Sämtliche Logs finden sich anschließend unter Protokolle in der jeweiligen Tabelle (siehe Abbildung 2).

Die in der Konsolenanwendung erzeugten Trace-Logs können der Tabelle traces entnommen werden. Abfragen werden mit der Kusto Query Language (KQL) formuliert. Die Traces aus dem obigen Beispiel können über folgende Query abgefragt werden:
traces
| where message contains "BlogTrace"Die geloggten Metriken lassen sich mit folgender Abfrage auch grafisch als Liniendiagramm darstellen (siehe Abbildung 3):
customMetrics
| where timestamp >= ago(12h)
| where name contains "Blog"
| render timechart 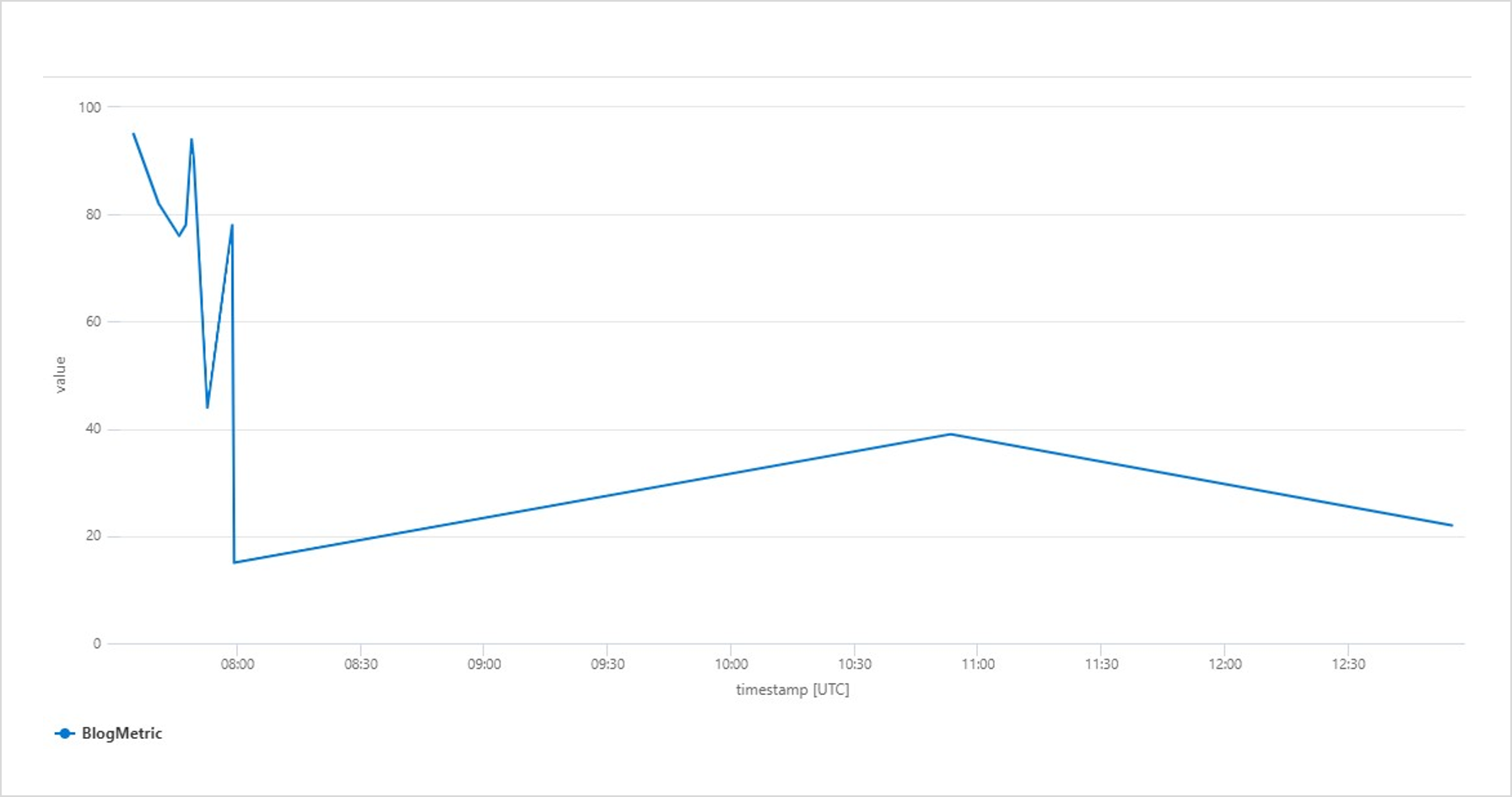
Dashboards & Warnungsregeln
Um Unregelmäßigkeiten frühzeitig zu erkennen, können individuelle Dashboards und Warnungsregeln angelegt werden. Im Falle der oben verwendeten Metriken kann man das Diagramm an ein freigegebenes Dashboard anheften. Dies lässt sich mit weiteren Abfragen beliebig fortsetzen, bis die gewünschten Informationen zu einer Übersicht zusammengetragen sind.
Das folgende Dashboard zeigt die Metrik der Konsolenanwendung. Gleichzeitig sind darin auch exemplarisch Informationen über Serveranfragen, fehlerhafte Anfragen, Antwortzeiten sowie Leistung und Verfügbarkeit enthalten (siehe Abbildung 4).

Hat man das Dashboard mal nicht im Blick und es kommt zu Anomalien, kann man sich auch über Warnungsregeln direkt per E-Mail oder SMS informieren lassen.
Einzelne Warnungsregeln lassen sich über den Menüpunkt Warnungen im Application-Insights-Portal anlegen und verwalten. Eine Warnungsregel besteht aus einer Signallogik (Bedingung) sowie einer Aktionsgruppe.
Bei der Bedingung wird ein Signal, z. B. eine Metrik, ausgewählt und mit einem Schwellwert versehen: „traces größer als 80“. Erhält man nun innerhalb eines definierten Zeitraumes mehr als 80 trace-Einträge, wird die Warnung ausgelöst.
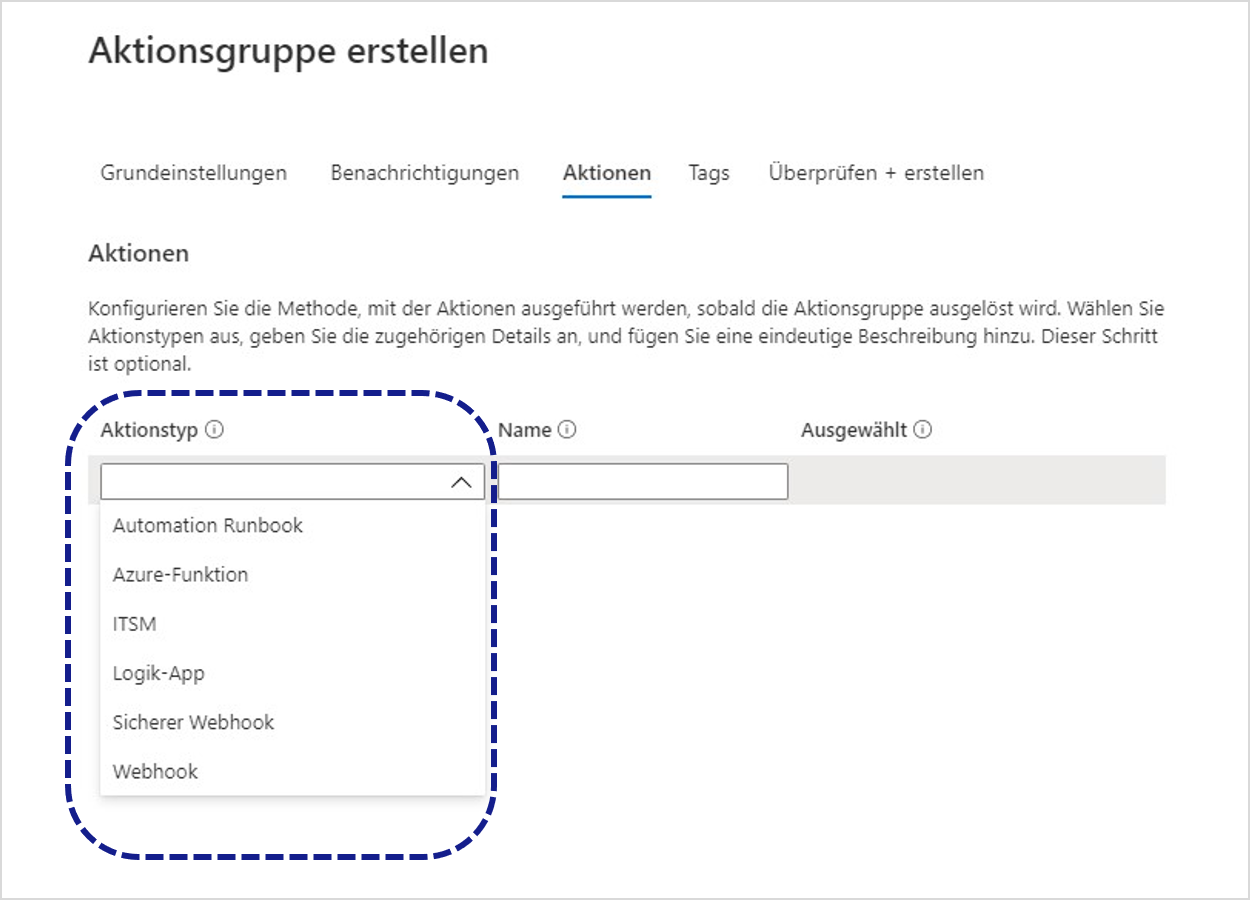
Die Aktionsgruppe legt abschließend fest, was im Falle einer Warnung zu tun ist. Hier lassen sich einfache Hinweis-E-Mails oder SMS an festgelegte Personen verschicken oder komplexere Handlungen programmatisch über Runbooks, Azure Functions, Logik-Apps oder Webhooks abbilden (siehe Abbildung 5).
REST API
Besteht der Bedarf, die Daten auch außerhalb von Application Insights zu verarbeiten, können diese über eine REST API abgefragt werden.
Die URL für die API-Aufrufe setzt sich aus einem Basis-Teil und der gewünschten Operation zusammen. Operationen sind metrics, events oder query. Dazu muss noch ein API-Key als „X-API-Key“ HTTP-Header übergeben werden:
https://api.applicationinsights.io/v1/apps/{app-id}/{operation}/[path]?[parameters]
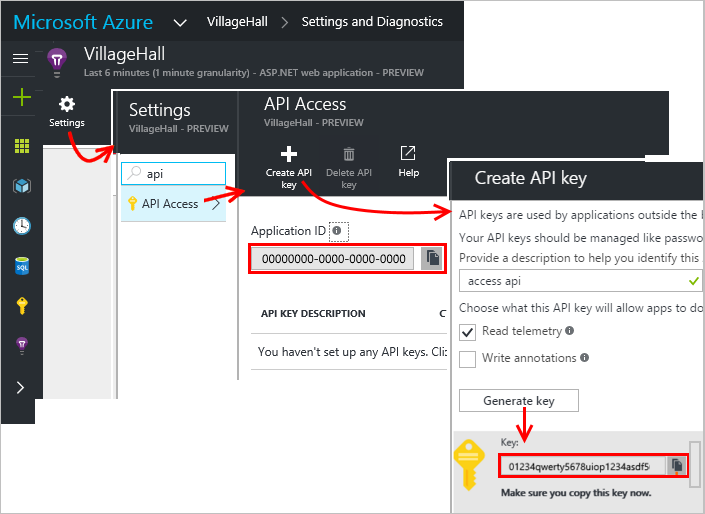
Die App-ID ist in den Settings unter API Access zu finden.
Um bei den oben beschriebenen Metriken zu bleiben, hier der API-Aufruf mit query-Operation für die Anzahl aller Einträge der letzten 24 Stunden:
https://api.applicationinsights.io/v1/apps/{}app-id}/query?query=customMetrics | where timestamp >= ago(24h) | where name contains „Blog“ | summarize count()
Das Ergebnis kommt im JSON-Format zurück:
{
"tables": [
{
"name": "PrimaryResult",
"columns": [
{
"name": "count_",
"type": "long"
}
],
"rows": [
[
13
]
]
}
]
}Fazit
Wie anhand dieses kleinen Beispiels zu sehen ist, lässt sich ein zentralisiertes Logging mit Hilfe von Application Insights in wenigen Schritten aufbauen und verwalten. Neben der schnellen und einfachen Integration ist auch die automatisierte Infrastruktur von Vorteil. Man muss sich um kein Hosting kümmern und sollte die Last einmal steigen, skaliert Application Insights automatisch.

