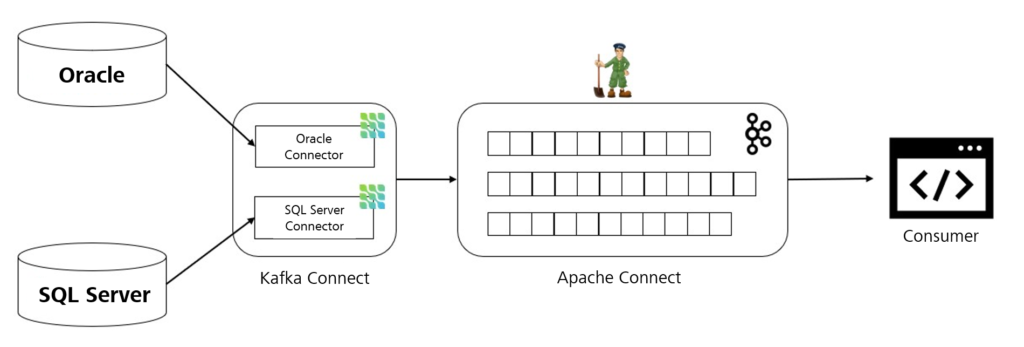
Im ersten Teil des Blogposts wurde vorgestellt, welche technischen Möglichkeiten man zum Erkennen von Datenbankänderungen hat und wie das Tool Debezium zusammen mit der Plattform Apache Kafka genutzt werden kann, um solche Change-Events zu streamen und anderen Anwendungen zur Verfügung zu stellen.
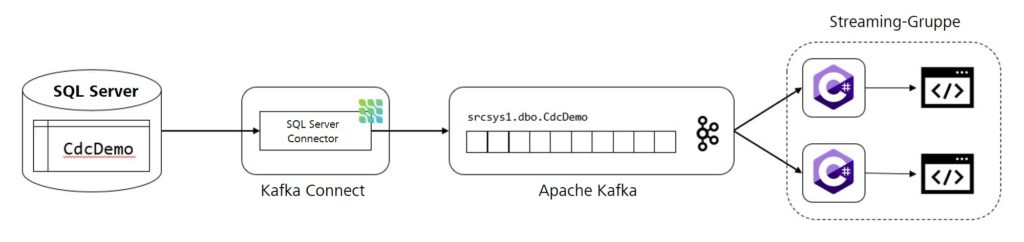
Jetzt soll dazu Stück für Stück ein kleiner Prototyp erarbeitet werden, welcher die Funktionsweise von Debezium demonstriert. Die Architektur dazu ist folgendermaßen aufgebaut: Auf einer lokalen Instanz eines SQL Servers befindet sich eine Datenbank mit einer einzigen Tabelle, die den Namen CdcDemo trägt. Diese enthält ein paar wenige Datensätze. Dazu wird jeweils eine Instanz von Apache Kafka und Kafka Connect aufgesetzt. In der Kafka-Instanz wird später ein Topic für Change-Events erstellt, während Kafka Connect den SQL-Server-Konnektor von Debezium beinhaltet. Letztendlich werden die Änderungsdaten aus dem Topic von zwei Anwendungen ausgelesen und vereinfacht auf der Konsole dargestellt. Die beiden Consumer sollen zeigen, dass sich die Nachrichten von Debezium auch parallelisiert verarbeiten lassen.
Vorbereitungen im SQL Server
Zuallererst muss die Grundlage dafür gelegt werden, das Change Data Capture demonstrieren zu können, d. h. es muss eine kleine Datenbasis erstellt werden. Dazu wird in einer Datenbank einer lokalen SQL-Server-Instanz eine Tabelle mit dem folgenden Befehl angelegt:
CREATE TABLE CdcDemo ( Id INT PRIMARY KEY, Surname VARCHAR(50) NULL, Forename VARCHAR(50) NULL )
Nun können beliebige Datensätze in die Tabelle eingefügt werden. In diesem Beispiel handelt es sich um die Namen von berühmten Autorinnen und Autoren.
| Id | Surname | Forename |
| 101 | Lindgren | Astrid |
| 102 | King | Stephen |
| 103 | Kästner | Erich |
| … | … | … |
Im Anschluss sind die für den Debezium-Konnektor spezifischen Vorkehrungen zu treffen. Das bedeutet im Falle des SQL Servers, dass sowohl die Datenbank als auch die Tabelle für das Change Data Capture aktiviert werden müssen. Das geschieht über die Ausführung der beiden folgenden Systemprozeduren:
EXEC sys.sp_cdc_enable_db EXEC sys.sp_cdc_enable_table @source_schema = N’dbo’, @source_name = N’CdcDemo’, @role_name = N’CdcRole’
In diesem Beispiel ist dbo das Schema der Tabelle, die CdcDemo heißt. Der Zugriff auf die Änderungsdaten erfolgt über die Rolle CdcRole.
Kafka und Debezium einrichten
Wenn die Vorbereitungen im SQL Server erfolgreich getroffen wurden, kann nun die für Debezium benötigte Infrastruktur eingerichtet werden. Zuvor sollte aber noch sichergestellt werden, dass eine aktuelle Version der Java-Runtime installiert ist.
Jetzt kann die Apache-Kafka-Software von der offiziellen Downloadseite heruntergeladen und in einen beliebigen Ordner entpackt werden. Eine Installation ist nicht erforderlich. Danach muss der SQL-Server-Konnektor von Debezium heruntergeladen und ebenfalls in einen Ordner entpackt werden.
Nach dem erfolgreichen Download von Apache Kafka und Debezium kann nun eine neue Konfiguration für den Konnektor mittels einer Java-Properties-Datei erstellt werden:
name=srcsys1-connector connector.class=io.debezium.connector.sqlserver.SqlServerConnector database.hostname=123.123.123.123 database.port=1433 database.user=cdc-demo-user database.password=cdc-demo-password database.dbname=cdc-demo-db database.server.name=srcsys1 table.whitelist=dbo.CdcDemo database.history.kafka.bootstrap.servers=localhost:9092 database.history.kafka.topic=dbhistory.srcsys1
Besonders wichtig ist die Einstellung connector.class. Diese gibt Kafka Connect an, welcher der zuvor heruntergeladenen, ausführbaren Konnektoren genutzt werden soll. Die Klassennamen der Debezium-Konnektoren finden sich in der jeweiligen Dokumentation. Weiterhin bestimmt database.server.name den logischen Namen, den Debezium für die Datenbank verwendet. Dieser ist wichtig für die spätere Benennung des Topics in Kafka. Mithilfe der Konfiguration table.whitelist können alle Tabellen angegeben werden, die der Debezium-Konnektor überwachen soll. Eine Erklärung zu allen weiteren Parametern ist in der Dokumentation von Debezium zu finden.
Als nächstes muss die Konfigurationsdatei von Kafka Connect angepasst werden, welche sich im Ordner config der Kafka-Installation befindet. Da für dieses Beispiel nur eine Instanz gebraucht wird, ist die Datei connect-standalone.properties zu verwenden. An sich können hier die Voreinstellungen beibehalten werden. Nur für die Eigenschaft plugin.path muss der Pfad zum heruntergeladenen Debezium-Konnektor angegeben werden. Wichtig: Damit ist nicht der Pfad zu den JAR-Dateien gemeint, sondern zu dem Ordner in der Hierarchie darüber, da Kafka Connect auch mehrere Konnektoren gleichzeitig ausführen kann, die sich in diesem Ordner befinden.
Für Apache Kafka an sich ist noch eine kleine Änderung in der Konfigurationsdatei server.properties sinnvoll. Da letztendlich zwei Konsumenten die Debezium-Nachricht verarbeiten sollen, macht es auch Sinn, die Anzahl der Partitionen für ein Topic auf zwei zu erhöhen. Damit werden die Change-Events entweder in die erste oder in die zweite Partition geschrieben. Die Partitionen werden dann jeweils einem Consumer zugeordnet, sodass die Nachrichten parallel, aber nicht doppelt verarbeitet werden. Zur Umsetzung davon ist beim Parameter num.partitions die Zahl 2 einzutragen.
Nachdem nun die beteiligten Komponenten konfiguriert wurden, können die Instanzen gestartet werden. Dabei ist die Beachtung der Reihenfolge wichtig.
$ ./bin/zookeeper-server-start.sh config/zookeeper.properties $ ./bin/kafka-server-start.sh config/server.properties $ ./bin/connect-standalone.sh config/connect-standalone. properties <path_to_debezium_config>
Zuerst wird der ZooKeeper gestartet, der für die Verwaltung der Kafka-Instanzen verantwortlich ist. Danach wird ein Kafka-Server ausgeführt, der sich beim ZooKeeper anmeldet. Zum Schluss wird Kafka Connect zusammen mit dem Debezium-Konnektor gestartet.
Einen Consumer implementieren
Mittlerweile steht die Infrastruktur für Debezium vollständig und es fehlt nur noch ein Consumer, der die Nachrichten aus Kafka verarbeiten kann. Dafür wird beispielhaft unter Verwendung der Bibliothek Confluent.Kafka eine .NET-Core-Konsolenanwendung programmiert, die sich am Einführungsbeispiel der Bibliothek auf GitHub orientiert. Zusätzlich dazu gibt es noch eine weitere Methode, die die gelesenen JSON-Nachrichten aus Kafka kurz und knapp auf der Konsole darstellt.
using Confluent.Kafka;
using Newtonsoft.Json.Linq;
using System;
using System.Threading;
namespace StreamKafka
{
class Program
{
static void Main(string[] args)
{
var config = new ConsumerConfig
{
GroupId = "streamer-group",
BootstrapServers = "localhost:9092",
AutoOffsetReset = AutoOffsetReset.Earliest,
};
using (var consumer = new ConsumerBuilder<Ignore, string>(config).Build())
{
consumer.Subscribe("srcsys1.dbo.CdcDemo");
CancellationTokenSource cts = new CancellationTokenSource();
Console.CancelKeyPress += (_, e) =>
{
e.Cancel = true;
cts.Cancel();
};
try
{
while (true)
{
try
{
var consumeResult = consumer.Consume(cts.Token);
if (consumeResult.Message.Value != null)
Console.WriteLine($"[{consumeResult.TopicPartitionOffset}] " + ProcessMessage(consumeResult.Message.Value));
}
catch (ConsumeException e)
{
Console.WriteLine($"Error occured: {e.Error.Reason}");
}
}
}
catch (OperationCanceledException)
{
consumer.Close();
}
}
}
static string ProcessMessage(string jsonString)
{
var jsonObject = JObject.Parse(jsonString);
var payload = jsonObject["payload"];
string returnString = "";
char operation = payload["op"].ToString()[0];
switch (operation)
{
case 'c':
returnString += "INSERT: ";
returnString += $"{payload["after"]["Id"]} | {payload["after"]["Nachname"]} | {payload["after"]["Vorname"]}";
break;
case 'd':
returnString += "DELETE: ";
returnString += $"{payload["before"]["Id"]} | {payload["before"]["Nachname"]} | {payload["before"]["Vorname"]}";
break;
case 'u':
returnString += "UPDATE: ";
returnString += $"{payload["before"]["Id"]} | {payload["before"]["Nachname"]} | {payload["before"]["Vorname"]} --> " +
$"{payload["after"]["Id"]} | {payload["after"]["Nachname"]} | {payload["after"]["Vorname"]}";
break;
default:
returnString += $"{payload["after"]["Id"]} | {payload["after"]["Nachname"]} | {payload["after"]["Vorname"]}";
break;
}
return returnString;
}
}
}
Im Quelltext gibt es einige interessante Stellen: Zunächst wird für den Consumer eine Konfiguration erstellt. Diese beinhaltet eine GroupId, die durch eine Zeichenkette repräsentiert wird. Die Gruppe dient dazu, die Arbeit unter den Konsumenten aufzuteilen, da Applikationen derselben Gruppe keine Nachrichten doppelt verarbeiten. Im Nachfolgenden abonniert der Consumer das Topic srcsys1.dbo.CdcDemo, das zuvor von Debezium automatisch in Kafka eingerichtet wurde. Der Name des Topics ergibt sich dabei aus den in der Debezium-Konfiguration angegebenen Parametern für den Server und die Tabelle. Im Anschluss geht der Consumer in eine Endlosschleife über, in der Nachrichten gelesen, verarbeitet und ausgegeben werden.
Den Prototypen testen
Jetzt sind für diesen Prototyp alle erforderlichen Komponenten installiert, konfiguriert und implementiert. Es wird Zeit, den Prototypen auch einmal auszuprobieren. Dafür ist es ratsam, zunächst zwei Instanzen des implementierten Consumers zu starten und erst im Anschluss Kafka bzw. Debezium wie oben beschrieben auszuführen.
Sind alle Komponenten hochgefahren, führt der Debezium-Konnektor einen Snapshot der Datenbanktabelle durch und schreibt diese Nachrichten an Kafka. Dort warten schon die beiden Consumer. Sie sollten eine Ausgabe produzieren, die der folgenden Abbildung ähnlichsieht.
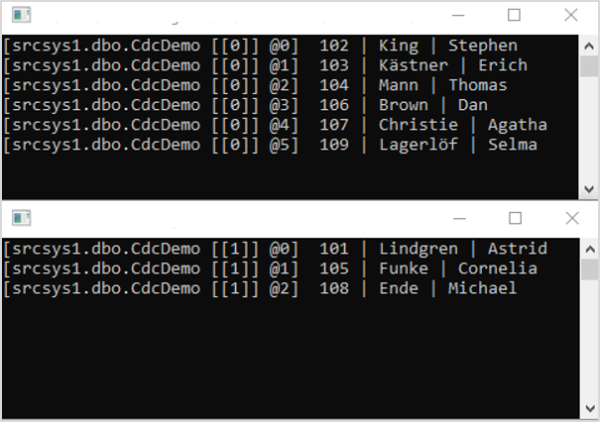
Kurz zur Bedeutung der Ausgabe: Die Informationen in den eckigen Klammern vor dem eigentlichen Datensatz geben Auskunft über das Topic, die Partitionsnummer und die Lognummer der jeweiligen Nachricht. Es wird ersichtlich, dass sich ein Consumer nur um die Nachrichten einer Partition kümmert. Debezium entscheidet durch Hashing und Modulo-Rechnung des Primärschlüssels, welcher Partition ein Datensatz zugeordnet wird.
Nun kann man testen, wie Debezium auf Änderungen an der Tabelle reagiert. Mittels des SQL Server Management Studios lassen sich INSERT-, UPDATE-, und DELETE-Befehle auf der Datenbank ausführen. Nur kurze Zeit, nachdem ein Statement abgesetzt wurde, sollten die Consumer darauf reagieren und eine entsprechende Ausgabe produzieren. Nachdem ein paar DML-Kommandos ausgeführt wurden, könnte die Ausgabe wie folgt aussehen:
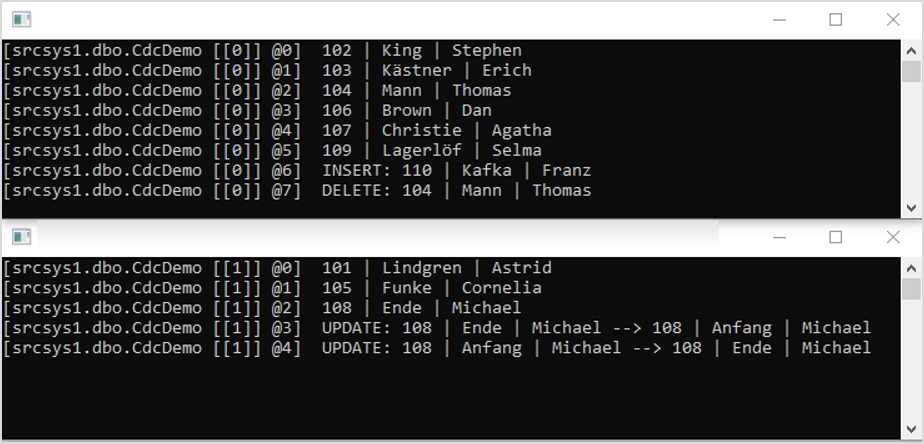
Eine Frage sollte zum Schluss noch geklärt werden: Ist es durch die Partitionierung der Nachrichten möglich, dass Race Conditions auftreten? Könnten sich also Änderungen am selben Datensatz über die beiden Partitionen gegenseitig „überholen“ und somit in der falschen Reihenfolge verarbeitet werden? Die Antwort ist nein. Daran hat Debezium zum Glück schon gedacht. Da die Change-Events anhand ihres Primärschlüssels wie oben beschrieben den jeweiligen Partitionen zugeordnet werden, landen Änderungsdaten bezüglich desselben Datensatzes auch immer hintereinander in derselben Partition und werden dort nur von einem Consumer in der richtigen Reihenfolge verarbeitet.
Fazit
Das Beispiel hat gezeigt, dass die Nutzung von Debezium zusammen mit Apache Kafka zum Streamen von Datenbankänderungen recht einfach umzusetzen ist. Einfüge-, Änderungs- und Lösch-Befehle können damit in annähernder Echtzeit bearbeitet werden. Zusätzlich zu den in diesem Prototyp gezeigten Beispielen gibt es auch die Möglichkeit, Änderungen am Datenschema zu streamen. Dafür erstellt Debezium ein separates Topic in Kafka.
Wichtig ist es zu beachten, dass der vorgestellte Prototyp nur ein Minimalbeispiel darstellt. Für den produktiven Einsatz von Debezium ist es erforderlich, die entsprechenden Komponenten so zu skalieren, dass ein gewisses Maß an Fehlertoleranz und Ausfallsicherheit gewährleistet ist.