Vorwort
Automatisiertes Testen von grafischen Oberflächen ist ein wichtiges Thema. Für jede GUI-Technologie gibt es mehrere Bibliotheken, die es sorgsam auszuwählen gilt, um zügig ein qualitativ hochwertiges und akkurates Ergebnis zu bekommen.
Im Bereich Web-Technologien gibt es viele bekannte Frameworks wie Selenium, Playwright, Cypress und viele mehr. Aber auch im Bereich WPF oder Winforms gibt es passende Vertreter und ich möchte heute FlaUI vorstellen.
FlaUI ist eine .NET-Klassenbibliothek für automatisiertes Testen von Windows Apps, insbesondere der UI. Sie baut auf den hauseigenen Microsoft Bibliotheken für UI Automation auf.
Geschichte
Am 20. Dezember 2016 hat Roman Roemer die erste Fassung von FlaUI auf Github veröffentlicht. Unter der Version 0.6.1 wurden die ersten Schritte in Richtung Klassenbibliothek für das Testen von .NET Produkten gelegt. Seitdem wurde diese konsequent und mit großem Eifer weiterentwickelt, um die Bibliothek mit neuen und besseren Funktionen zu erweitern. Die neueste Version trägt die Versionsnummer 4.0.0 und bietet Features wie z.B. das Automatisieren von WPF und Windows Store App Produkten sowie das Tool FlaUI Inspect, welches die Struktur von .NET Produkten ausliest und wiedergibt.
Installation
Über GitHub oder NuGet kann FlaUI geladen und installiert werden. Zudem werde ich für diesen Artikel und das nachfolgende Beispiel noch weitere Plugins / Frameworks sowie Klassenbibliotheken verwenden wie:
- C# von OmniSharp
- C# Extensions von Jchannon
- NuGet Package Manager von Jmrog
- .NET Core Test Explorer von Jun Han
- Die neueste Windows SDK
- NUnit Framework
Beispiel
In diesem Beispiel werde ich mit mehreren unterschiedlichen Methoden eine typisches Windows-App, hier den Taskmanager, maximieren bzw. den Ausgangszustand wiederherstellen. Außerdem sollen unterschiedliche Elemente markiert werden.
Bei der Arbeit an diesem Artikel ist mir aufgefallen, dass Windows ein besonderes Verhalten aufweist: Wird ein Programm maximiert, ändert sich nicht nur der Name und andere Eigenschaften des Buttons, sondern auch die AutomationID. Das führte dazu, dass ich den Methodenaufrufen zwei verschiedene Übergabestrings für die AutomationID, „Maximize“ und „Restore“, mitgeben musste, die beide denselben Button ansprechen.
Code (C#)
Zuerst starten wir die gewünschte Anwendung und legen uns eine Instanz des Fensters für die weitere Verwendung an:
var app = Application.Launch(@"C:WindowsSystem32Taskmgr.exe");
var automation = new UIA2Automation();
var mainWin = app.GetMainWindow(automation);Desweiteren benötigen wir noch die Helper Class ConditionFactory:
ConditionFactory cf = new ConditionFactory(new UIA2PropertyLibrary());Diese Helper Class bietet uns die Möglichkeit, Objekte nach bestimmten Bedingungen zu suchen. Wie zum Beispiel, die Suche nach einem Objekt mit einer bestimmten ID.
In den folgenden Methoden wollen wir, wie oben erwähnt, das Programm maximieren und wieder den Ausgangszustand herstellen. Außerdem wollen wir Elemente hervorheben:
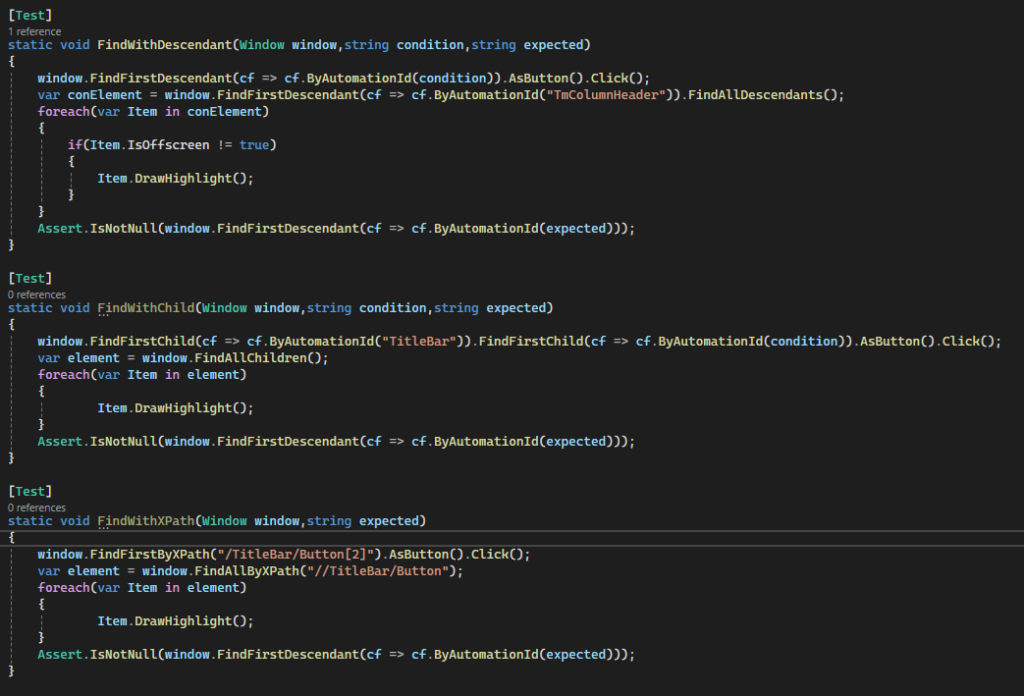
Für die erste Methode werden wir mit FindFirstDescendant und FindAllDescendant arbeiten. FindAllDescendant sucht sich alle Elemente, die unterhalb des Ausgangselements liegen. FindFirstDescendant findet das erste Element unterhalb des Ausgangselements, das mit der übergebenen Suchbedingung übereinstimmt und mit DrawHighlight wird ein roter Rahmen um das Element gelegt.
static void FindWithDescendant(Window window, string condition, string expected)
{
window.FindFirstDescendant(cf => cf.ByAutomationId(condition)).AsButton().Click();
var element = window.FindFirstDescendant(cf =>
cf.ByAutomationId("TmColumnHeader")).FindAllDescendants();
foreach(var Item in element)
{
if(Item.IsOffscreen != true)
{
Item.DrawHighlight();
}
}
Assert.IsNotNull(window.FindFirstDescendant(cf => cf.ByAutomationId(expected)));
}In der zweiten Methode nutzen wir FindFirstChild und FindAllChildren. Beide funktionieren fast gleich wie Descendant, nur dass hier nicht alle Elemente gefunden werden, sondern nur die, die direkt unter dem Ausgangselement liegen.
static void FindWithChild(Window window, string condition, string expected)
{
window.FindFirstChild(cf => cf.ByAutomationId("TitleBar")).FindFirstChild(cf =>
cf.ByAutomationId(condition)).AsButton().Click();
var element = window.FindAllChildren();
foreach(var Item in element)
{
Item.DrawHighlight();
}
Assert.IsNotNull(window.FindFirstDescendant(cf => cf.ByAutomationId(expected)));
}Und für die dritte Methode nehmen wir FindFirstByXPath und FindAllByXPath. Hier müssen wir, wie der Name sagt, den Pfad angeben. Bei First sollte es der genaue Pfad zum gewünschten Element sein und bei FindAll werden alle Elemente gesucht, die in dem Pfad gefunden werden können. Solltet ihr ein Programm untersuchen, welches ihr nicht kennt, hilft es, FlaUI Inspect zu nutzen, welches Eigenschafen wie den Pfad anzeigen, aber auch andere Informationen über Elemente von Windows-Apps darstellen kann.
static void FindWithXPath(Window window, string expected)
{
window.FindFirstByXPath("/TitleBar/Button[2]").AsButton().Click();
var element = window.FindAllByXPath("//TitleBar/Button");
foreach(var Item in element)
{
Item.DrawHighlight();
}
Assert.IsNotNull(window.FindFirstDescendant(cf => cf.ByAutomationId(expected)));
}Als letztes müssen wir nur noch die Methoden aufrufen und ihnen die gewünschten Werte übergeben. Zum einen das Fenster was wir uns am Anfang angelegt haben und zum anderen die AutomationID des Maximieren-Buttons, welche sich wie erwähnt ändert, sobald der Button betätigt wurde.
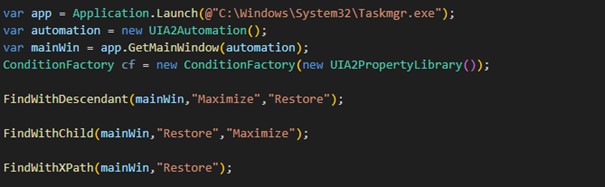
FindWithDescendant(mainWin,"Maximize", "Restore");
FindWithChild(mainWin,"Restore", "Maximize");
FindWithXPath(mainWin,"Restore");
Im Code sieht das bei mir wie folgt aus:
Schwachpunkte
Ein Problem sind selbst gebaute Objekte z.B. hatten wir in einem Projekt mit selbsterstellten Polygonen Buttons angelegt. Diese konnten weder von FlaUI Inspect noch von FlaUI selbst gefunden werden, was die Nutzung dieser in unseren Autotests stark eingeschränkt hat. Für solche Objekte muss ein AutomationPeer (stellt Basisklasse bereit, die das Objekt für die UI-Automatisierung nutzbar macht) angelegt werden, damit diese gefunden werden können.
Fazit und Zusammenfassung
FlaUI unterstützt mit UIA2 Forms und Win 32 Anwendungen sowie mit UIA3 WPF und Windows Store Apps. Es ist einfach zu bedienen und übersichtlich, da es mit relativ wenig Grundfunktionen auskommt. Außerdem kann es jederzeit mit eigenen Methoden und Objekten erweitert werden.
Auch die Software-Entwickler:innen sind zufrieden, da sie keine extra Schnittstellen und damit keine potenziellen Fehlerquellen für die Testautomatisierung einbauen müssen. Gerade weil FlaUI uns die Möglichkeit gibt, direkt die Objekte des zu testenden Programmes abgreifen zu können, brauchen wir keine zusätzliche Arbeitszeit darauf zu verwenden, für das Testing größere und fehleranfällige Anpassungen an der bestehenden Programmstruktur vorzusehen und zu verwalten.
Andererseits muss man um jedes Objekt automatisiert ansprechen zu können, seine AutomationID im Testcode mindestens einmal hinterlegen, damit sie für den Test auch nutzbar ist. Dies bedeutet, dass man praktisch die ungefähre Struktur des zu testenden Programmes nachbilden muss, was gerade bei komplexeren Programmen aufwändig sein kann. Und um dabei die Übersichtlichkeit zu erhalten, sollte man diese geclustert in mehreren, namentlich Aussagekräftigen, Klassen hinterlegen.
Wir werden es auf alle Fälle weiterverwenden und auch unseren Kolleg:innen empfehlen.