The first part of the series presented the technical options that can be used to capture changes in databases, and how the Debezium tool can be used in combination with the Apache Kafka platform to stream such change events and provide them to other applications.
We are now going to develop, step by step, a small prototype that demonstrates the operating principle of Debezium. The architecture is structured as follows: There is a database with a single table labeled CdcDemo on a local instance of an SQL server. This table only contains a small number of datasets. We now install one instance each of Apache Kafka and Kafka Connect. Later, a topic for change events will be created in the Kafka instance, while Kafka Connect contains the SQL Server connector of Debezium. In the end, the change data from the topic will be read by two applications and displayed on the console in a simplified form. We use two consumers to show that the messages from Debezium can also be processed in parallel.
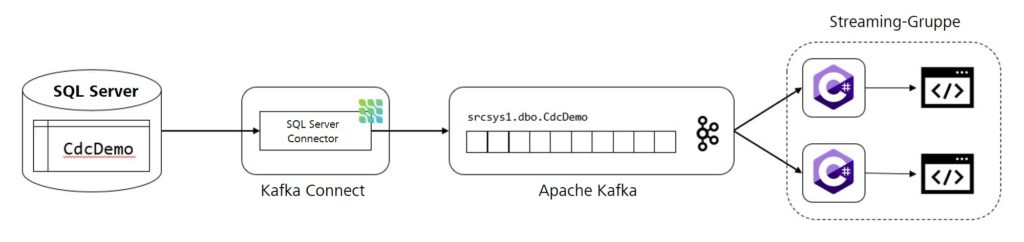
Preparing the SQL Server
First of all, we have to lay the foundations for a demonstration of the change data capture, i.e. we have to create a small database. For this purpose, we use the following command to create a table in a database in a local SQL Server instance:
CREATE TABLE CdcDemo ( Id INT PRIMARY KEY, Surname VARCHAR(50) NULL, Forename VARCHAR(50) NULL )
We can now add any number of datasets to the table. In the example, they are the names of famous writers.
| Id | Surname | Forename |
| 101 | Lindgren | Astrid |
| 102 | King | Stephen |
| 103 | Kästner | Erich |
| … | … | … |
Next, we have to make the preparations that are specific to the Debezium connector. In the case of the SQL Server, this means that both the database and the table have to be activated for the change data capture. This is done by executing the following two system procedures:
EXEC sys.sp_cdc_enable_db EXEC sys.sp_cdc_enable_table @source_schema = N’dbo’, @source_name = N’CdcDemo’, @role_name = N’CdcRole’
In the present example, dbo is the schema of the table labeled CdcDemo. The change data are accessed by way of the role CdcRole.
Setting up Kafka and Debezium
When the preparations in the SQL Server have been completed, we can set up the infrastructure required for Debezium. It is advisable to first check that a current version of Java Runtime is installed.
We can now download the Apache Kafka software from the official download site and unzip it to whichever folder we want. Installation is not required. Then, we have to download the SQL Server connector of Debezium and unzip it to a folder as well.
Once Apache Kafka and Debezium have successfully been downloaded, we can create a new configuration for the connector by means of a Java properties file:
name=srcsys1-connector connector.class=io.debezium.connector.sqlserver.SqlServerConnector database.hostname=123.123.123.123 database.port=1433 database.user=cdc-demo-user database.password=cdc-demo-password database.dbname=cdc-demo-db database.server.name=srcsys1 table.whitelist=dbo.CdcDemo database.history.kafka.bootstrap.servers=localhost:9092 database.history.kafka.topic=dbhistory.srcsys1
The connector.class setting is of particular importance. It tells Kafka Connect which of the downloaded, executable connectors is to be used. The class names of the Debezium connectors can be found in the respective documentation. Furthermore, database.server.name determines the logical name that Debezium uses for the database. This is important for the designation of the topic in Kafka later. By means of the table.whitelist configuration, we can specify all the tables that the Debezium connectors are expected to monitor. All the other parameters are explained in the Debezium documentation.
Next, we have to adapt the configuration file of Kafka Connect, which is located in the config folder of the Kafka installation. Since we only need one instance for the present example, we have to use the fileconnect-standalone.properties. In principle, we can keep the default settings in this case. We only have to indicate the path to the downloaded Debezium connector for the plugin.path property. Please note: This does not mean the path to the JAR files, but to the folder above them in the hierarchy, because Kafka Connect can also simultaneously execute several connectors located in this folder.
For Apache Kafka itself, a small modification in the configuration file server.properties is useful. As two consumers are supposed to process the Debezium message in the end, it is expedient to increase the number of partitions for a topic to two. This way, the change events are written either to the first or the second partition. Each partition is then allocated to a consumer, ensuring that the messages are processed in parallel, but not twice. To implement this, we enter the number 2 in the num.partitions parameter.
Now that all the components involved have been configured, we can start the instances. Following the correct sequence is important.
$ ./bin/zookeeper-server-start.sh config/zookeeper.properties $ ./bin/kafka-server-start.sh config/server.properties $ ./bin/connect-standalone.sh config/connect-standalone. properties <path_to_debezium_config>
Firstly, we start ZooKeeper, which is responsible for the management of the Kafka instances. Then, a Kafka server is executed and registers with ZooKeeper. Lastly, we start Kafka Connect together with the Debezium connector.
Implementing a consumer
The infrastructure for Debezium is now complete. All we need is a consumer that can process the messages from Kafka. As an example, we program a .NET Core console application using the Confluent.Kafka library, based on the introductory example of the library on GitHub. In addition, there is another method to briefly and succinctly present the JSON messages read from Kafka.
using Confluent.Kafka;
using Newtonsoft.Json.Linq;
using System;
using System.Threading;
namespace StreamKafka
{
class Program
{
static void Main(string[] args)
{
var config = new ConsumerConfig
{
GroupId = "streamer-group",
BootstrapServers = "localhost:9092",
AutoOffsetReset = AutoOffsetReset.Earliest,
};
using (var consumer = new ConsumerBuilder<Ignore, string>(config).Build())
{
consumer.Subscribe("srcsys1.dbo.CdcDemo");
CancellationTokenSource cts = new CancellationTokenSource();
Console.CancelKeyPress += (_, e) =>
{
e.Cancel = true;
cts.Cancel();
};
try
{
while (true)
{
try
{
var consumeResult = consumer.Consume(cts.Token);
if (consumeResult.Message.Value != null)
Console.WriteLine($"[{consumeResult.TopicPartitionOffset}] " + ProcessMessage(consumeResult.Message.Value));
}
catch (ConsumeException e)
{
Console.WriteLine($"Error occured: {e.Error.Reason}");
}
}
}
catch (OperationCanceledException)
{
consumer.Close();
}
}
}
static string ProcessMessage(string jsonString)
{
var jsonObject = JObject.Parse(jsonString);
var payload = jsonObject["payload"];
string returnString = "";
char operation = payload["op"].ToString()[0];
switch (operation)
{
case 'c':
returnString += "INSERT: ";
returnString += $"{payload["after"]["Id"]} | {payload["after"]["Nachname"]} | {payload["after"]["Vorname"]}";
break;
case 'd':
returnString += "DELETE: ";
returnString += $"{payload["before"]["Id"]} | {payload["before"]["Nachname"]} | {payload["before"]["Vorname"]}";
break;
case 'u':
returnString += "UPDATE: ";
returnString += $"{payload["before"]["Id"]} | {payload["before"]["Nachname"]} | {payload["before"]["Vorname"]} --> " +
$"{payload["after"]["Id"]} | {payload["after"]["Nachname"]} | {payload["after"]["Vorname"]}";
break;
default:
returnString += $"{payload["after"]["Id"]} | {payload["after"]["Nachname"]} | {payload["after"]["Vorname"]}";
break;
}
return returnString;
}
}
}
Some points in the source text are interesting: Firstly, a configuration is defined for the consumer. It includes a GroupId, that is represented by a string of characters. The group is used to split the work between the consumers because if applications are in the same group, they do not process messages twice. The consumer then subscribes to the topic srcsys1.dbo.CdcDemo that has previously been automatically created in Kafka by Debezium. The name of the topic results from the parameters for the server and the table specified in the Debezium configuration. Subsequently, the consumer goes into an infinite loop of reading, processing and outputting messages.
Testing the prototype
All the components required for this prototype have now been installed, configured, and implemented. Time to test the prototype. It is advisable to first start two instances of the implemented consumer and then execute Kafka and Debezium as described above.
Once all the components are up and running, the Debezium connector takes a snapshot of the database table and writes these messages to Kafka, where the two consumers are already waiting. They are supposed to produce output that resembles the image below.
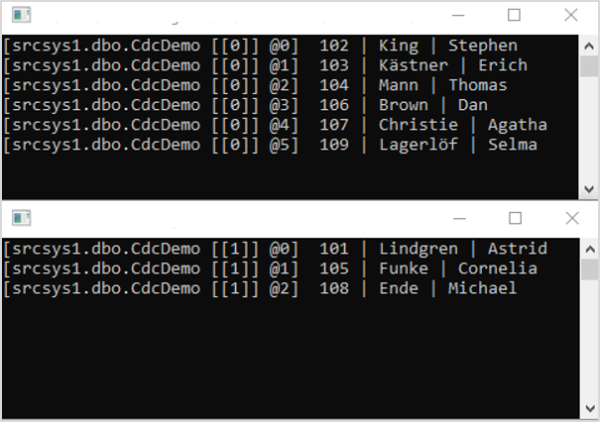
A word on the significance of the output: The information in the square brackets preceding the actual dataset provide details about the topic, the partition number and the log number of the respective message. You can see that each consumer only deals with the messages of one partition. Debezium decides which partition a dataset is allocated to by means of hashing and modulo calculation of the primary key.
We can now test how Debezium responds to changes in the table. We can execute INSERT, UPDATE and DELETE commands on the database by means of the SQL Server Management Studio. Shortly after a statement has been issued, the consumers should respond and produce corresponding output. After executing a few DML commands, the output could look like this:
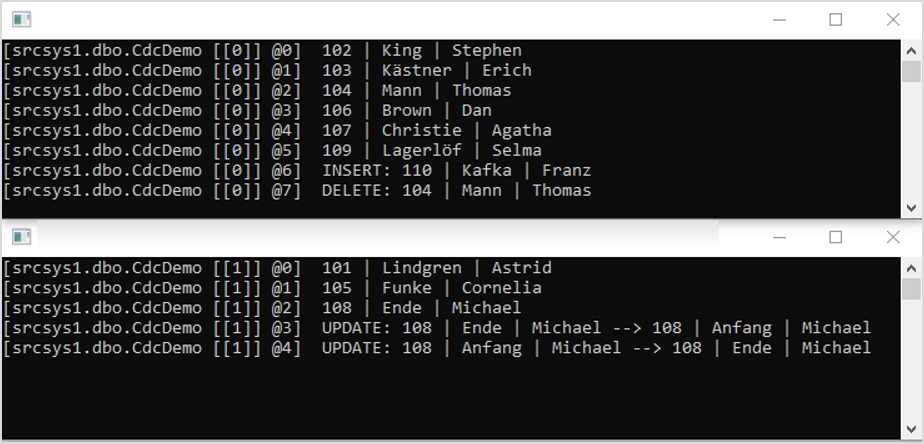
One last question that needs to be answered: Can the partitioning of the messages cause race conditions? In other words, could changes in the same dataset across both partitions “overtake” each other, causing them to be processed in the wrong order? The answer is no. Fortunately, Debezium has already considered this possibility. As the change events are allocated to their respective partition based on their primary key as described above, change data referring to the same dataset always end up in the same partition, one after the other, where they are processed by one consumer in the correct order.
Conclusion
The example shows that using Debezium in combination with Apache Kafka to stream database changes is relatively simple. Insert, update and delete commands can be processed in near real time. In addition to the examples shown in this prototype, it is also possible to stream changes in the data schema. For this purpose, Debezium creates a separate topic in Kafka.
Please note that the prototype presented here is a minimal example. To put Debezium to productive use, the respective components need to be scaled in order to ensure a certain level of fault tolerance and reliability.