A few years ago, Harvard Business Review named “data scientist” the “Sexiest Job of the 21st Century” [1] – not least because data-driven companies such as Google, Amazon and Facebook can generate enormous profits. Since then, modern companies have been working on their data infrastructures and terms such as machine learning, data science and data mining are on everyone’s lips. But what exactly do all these terms mean? What do they have in common, what differentiates them? And what does a data scientist actually do? Read on to find out.

Buzzwords
We’re going to start by attempting to clarify the meaning of some keywords. But this comes with a word of warning: as this is still an emerging field that is evolving at a rapid pace, many terms and concepts are still in a state of flux and are sometimes used in different ways. We are going to use the example of a fictitious global logistics company called “OrderNow” to illustrate the key terms.
Data science attempts to generate knowledge from data. The method employed by data scientists is comparable with that of natural scientists, who derive general findings from large volumes of measured data. To do this, they use various algorithms that are developed in an academic context and applied in an industrial environment.
An important example of this use of algorithms relates to the prediction of orders. OrderNow’s accounting records indicate which customers ordered what at what time and in what quantity. A data scientist’s algorithm analyses this order data statistically and can then predict when in the future there will be demand for which products and in what quantities. Equipped with this information, OrderNow can place orders with its suppliers in good time and then supply goods to its own customers more quickly.
Big data refers to volumes of data that are too large, too complex, too fast-moving or too unstructured to be evaluated with conventional manual methods of data processing.
In our example, this could refer to the constantly growing volumes of historical order data.
A data lake is a system of data stored in its raw format without a structure. More data is stored than is urgently required. In other words, a data lake is a big data repository.
OrderNow is made up of many subcontractors with their own established structures. The order data is sometimes in the form of Excel files and sometimes it is recorded as entries in SQL databases.
Machine learning algorithms learn – in a similar way to a human – to identify patterns in data on the basis of examples. Once the learning phase has been completed, these patterns can be identified in new data. This is also referred to as the artificial generation of knowledge from experience. The application of these algorithms often involves the use of neural networks.
In the case of OrderNow, this technology is used in the customer app. The user can take photos of objects, the app identifies which product it is and an order can be placed directly. To make this possible, a machine learning algorithm has processed countless categorised image files in order to learn what a particular product looks like and be able to recognise it in new images.
Deep learning is a specialmethod of machine learning which uses neural networks with numerous hidden layers.
Data mining is the attempt to find new interconnections and trends in large databases using statistical methods. As it involves a different approach, data mining is regarded as complementary to machine learning.
OrderNow uses data mining to recommend products to its customers.
What does a data scientist do?
Data science can be regarded as the umbrella term that encompasses the other keywords. A data scientist uses methods such as machine learning or data mining to generate knowledge from data.
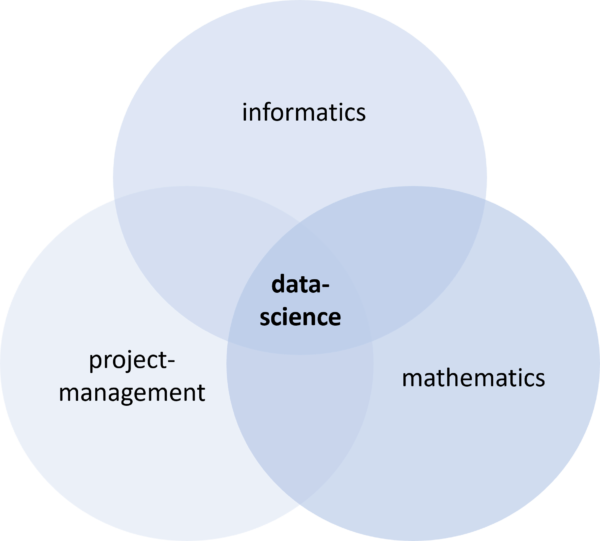
Figure 1: Data scientists use knowledge and skills from the fields of computer science, mathematics and project management.
This requires various skills, as summarised in Figure 1. Data scientists often use the programming languages Python or R, understand databases and know how to process data efficiently. They have a good understanding of mathematics and statistics. The scientific part of their work comprises the process of generating knowledge and also involves them formulating the questions that are to be answered with the database. At the same time, data scientists must also be good at project management. They work in a team with experts from the world of data, they have to be able to communicate results effectively within the company and ultimately they help put their findings into practice in order to create added value.
Using data to create added value
What might this added value look like? Findings that contribute to management decisions on the one hand, optimisation of existing products on the other – in many cases, however, the actual goal is to develop new products. For this to succeed, software developers and data scientists need to work together. The future will reveal how well we manage to put this into practice.
References
[1] Davenport and Patil, Havard Business Review, October 2012