Ein großer Teil der Apps, die wir regelmäßig benutzen, stellen für verschiedene Benutzerinnen und Benutzer individuelle Daten und Dienste bereit und müssen daher ihre Anwenderinnen und Anwender eindeutig identifizieren können.
Die klassische Herangehensweise wäre es hier, ein Login-Formular zu bauen und mit einer eigenen Nutzerdatenbank zu verwalten, was jedoch einige Nachteile mit sich bringen kann. Dieser Artikel stellt die alternative Herangehensweise mit den Protokollen „OAuth“ und „OpenID Connect“ vor, die für den Zweck der sicheren Authentifizierung und Autorisierung entwickelt wurden.

Nachteile der klassischen Login-Formulare
Die eingangs beschriebene, klassische Variante der User-Authentifizierung hat einige Nachteile:
Security
Sicherheitskritische Funktionen selbst zu bauen, ist immer mit einem gewissen Risiko verbunden. Bei Passwörtern reicht es beispielsweise nicht aus, einfach nur Hash-Werte abzuspeichern. Denn die Passwörter müssen selbst dann sicher sein, wenn der ungünstigste Fall eintritt und die Datenbank in die Hände von Hackern gelangt. Dafür stehen spezielle Verfahren zur Verfügung, jedoch müssen diese eben auch richtig implementiert sein. Im Zweifel bietet es sich daher in aller Regel an, lieber auf etablierte und durch Expertinnen und Experten begutachtete freie Produkte zu setzen, als diese selbst nachzubauen.
Aufwand
Mit einer einfachen Login-Maske ist es nicht getan. Auch weitere Prozesse wie Registrierung, Passwort ändern, Passwort vergessen usw. müssen bedacht und implementiert werden. Und natürlich gibt es auch hier Best Practices, beispielsweise hinsichtlich Usability, die beachtet werden sollten. Der Aufwand, um alle diese Aspekte in hoher Qualität umzusetzen, sollte nicht unterschätzt werden.
Zwei-Faktor-Authentifizierung
Um die Sicherheit weiter zu erhöhen, sollte den Usern die Möglichkeit gegeben werden, für den Login einen zweiten Faktor zu benutzen. Das kann z. B. ein Einmal-Code sein, der per SMS versandt oder durch eine Authenticator App generiert wird. Aber auch Hardware Token werden gern benutzt. Die Sicherheit wird dadurch enorm gesteigert, da es nun nicht mehr ausreicht, das Passwort zu erraten. Angreiferinnen und Angreifer müssen stattdessen zusätzlich im Besitz des Smartphones oder Hardware Token sein. Diese zusätzlichen Sicherheitsfeatures selbst zu implementieren, ist aber nicht nur fehleranfällig, sondern, siehe vorherigen Punkt, auch aufwändig.
Zentrale Account-Verwaltung
Insbesondere im Firmenkontext ist es häufig eine wichtige Anforderung, dass die Account-Informationen aus einer zentralen Verwaltung (z. B. LDAP, Active-Directory) genutzt werden können. Wenn Mitarbeiterinnen und Mitarbeiter sowieso einen Firmen-Account haben, warum sollten sie dann für jede firmeninterne Anwendung einen zusätzlichen Account mit (hoffentlich) individuellen Passwort anlegen? Die Möglichkeit für Single-Sign-On erhöht zusätzlich den Nutzerkomfort. Und auch außerhalb des Firmenkontexts möchten viele eben nicht für jede App und jede Webseite einen eigenen Account anlegen und sich die Zugangsdaten merken, sondern nutzen lieber einen zentralen Identitäts-Provider.
„OAuth“ und „OpenID Connect“ als Lösungsansatz
Mit den Protokollen „OAuth“ und „OpenID Connect“ stehen zwei Protokolle bereit, die genau für diesen Zweck entwickelt wurden.
Die tatsächliche Implementierung dieser Standards stellt in der Praxis dann aber meist doch eine gewisse Hürde dar, insbesondere wenn man das erste Mal mit diesen Verfahren in Berührung kommt. Dies liegt einerseits daran, dass die Abläufe eben doch etwas komplexer sind als ein simpler Abgleich mit einem gespeicherten Passwort-Hash. Ein anderer Grund dürfte sein, dass die Standards mehrere Varianten (sogenannte Flows) vorsehen, die in unterschiedlichen Situationen zum Einsatz kommen. Als Neuling steht man schnell vor der Frage, welche Variante für die eigene Anwendung die beste ist und wie es dann ganz konkret umzusetzen ist. Die Antwort auf diese Frage ist insbesondere von der Art der Anwendung abhängig, d. h. ob es sich z. B. um eine native Mobile-App, eine klassische serverseitig gerenderte Web-Anwendung oder eine Single-Page-App handelt.
In diesem Artikel wollen wir nicht zu sehr in die Tiefe der beiden Protokolle gehen (wer mehr über OAuth und OpenID Connect lernen möchte, dem sei dieser sehr gute Vortrag auf Youtube empfohlen: https://www.youtube.com/watch?v=996OiexHze0).
Stattdessen wollen wir einen konkreten Anwendungsfall herausgreifen, der bei uns in Projekten relativ häufig vorkommt: Wir bauen eine Single-Page-App (SPA), die statisch ausgeliefert wird. Das heißt, dass sich auf dem Server keine Frontend-Logik befindet, sondern lediglich JavaScript- und HTML-Dateien bereitgestellt werden. Stattdessen stellt der Server lediglich eine API zur Benutzung durch die SPA (und andere Clients) bereit, mit der sich Daten holen und Operationen ausführen lassen. Diese API könnte mittels REST oder GraphQL implementiert sein.
Wie bei OAuth üblich, kommt hierbei ein separater Authentication-Service zum Einsatz, wir wollen daher die Benutzerverwaltung nicht selbst implementieren. Dies könnte z. B. ein Cloud-Anbieter sein oder eine selbst gehostete Software, beispielsweise der freie Open-Source-Authentication-Server „Keycloak“. Wichtig ist lediglich, dass der Authentication-Dienst OAuth2/OpenID Connect „spricht“.
Das spannende an dieser Konstellation ist, dass anders als bei einem serverseitig verarbeiteten Web-Frontend, die Authentifizierung zunächst außerhalb der Einflusssphäre des Servers stattfindet (nämlich rein clientseitig in der SPA bzw. im Browser des Nutzers). Die SPA muss anschließend aber Requests gegen die Server-API absenden, wobei der Server der Glaubwürdigkeit der Requests zunächst mal misstrauen und die Authentifizierung nochmal selbstständig überprüfen muss.
Arbeiten mit OAuth: Implicit Flow und Authorization Code Flow
Die OAuth-Spezifikation gibt mehrere Flows vor, für unseren Zweck wollen wir uns aber nur zwei genauer anschauen: Den sogenannten „Implicit Flow“ und den „Authorization Code Flow“. Letztlich geht es bei beiden Varianten darum, dass der Auth Provider der Anwendung einen sogenannten „Access Token“ ausstellt, den die Anwendung anschließend bei allen Requests an den API-Server mitschickt. Der API-Server wiederum kann anhand des Access Token die Authentizität des Requests feststellen. Die Flows unterscheiden sich lediglich darin, wie genau die Ausstellung des Access Token vonstattengeht.
Der Implicit Flow war jahrelang die Empfehlung für den Einsatz in JavaScript-Anwendungen im Browser. Zunächst leitet die Anwendung den User auf eine Login-Seite des Auth-Providers weiter. Nach erfolgtem Login leitet der Auth-Provider den Browser wieder auf die ursprüngliche Seite zurück und übergibt der Anwendung den Access Token als Teil der Response. Genau hier liegen aber auch die Probleme bei dieser Variante. Über verschiedene Wege ist es für einen Angreifer oder eine Angreiferin möglich, an den Access Token zu gelangen, beispielsweise indem die Redirects manipuliert werden und damit der Access Token nicht mehr an die eigentliche App, sondern an den Angreifer oder die Angreiferin geschickt wird.
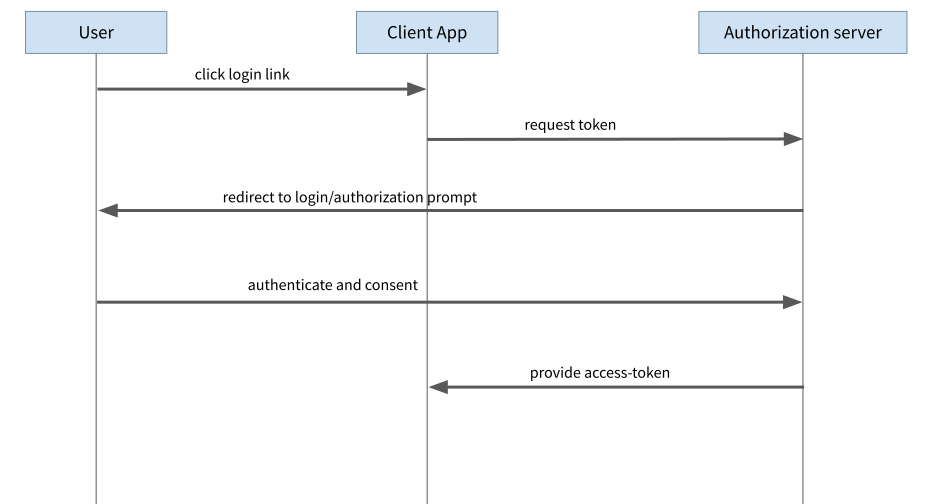
Der Implicit Flow war von Anfang an eine Notlösung für JavaScript-Anwendungen im Browser. Zum Zeitpunkt der Standardisierung gab es für Browser-Scripts keine Möglichkeit, Requests auf andere Server als den eigenen auszuführen (sogenannte Same-Origin-Policy). Damit war die Ausführung des eigentlich besseren Authorization Code Flow nicht möglich. In der Zwischenzeit wurde mit dem sogenannten CORS-Mechanismus (für Cross-Origin Resource Sharing) ein System eingeführt, welches genau diese Lücke schließt und Requests auch auf andere Server ermöglicht, sofern diese den Zugriff erlauben.
Beim Authorization Code Flow findet ebenfalls ein Redirect auf die Login-Seite des Auth Providers statt. Anstelle eines Access Token schickt der Auth Provider aber lediglich einen sogenannten „Authorization Code“ an den Client. In einem separaten Request muss dieser Authorization Code zusammen mit der „Client ID“ und dem „Client Secret“ an den Auth Provider geschickt und gegen das Access Token eingetauscht werden. Die Client-ID kennzeichnet den Client (in unserem Fall die Single-Page-App) und ermöglicht dem Auth-Server, für verschiedene Clients verschiedene Regeln anzuwenden. Die Client-ID ist im Prinzip öffentlich bekannt und taucht bei einigen Apps/Diensten als Teil der URL auf.
Das Client Secret dagegen ist ein geheimer Code, den nur dieser eine Client verwenden darf, um sich gegenüber dem Auth Server auszuweisen (wir kommen gleich noch einmal darauf zurück). Der entscheidende Punkt ist hier, dass dieser zweite Request nicht als GET-Request sondern als POST-Request implementiert wird. Damit sind die übermittelten Informationen nicht Teil der URL und sind mittels HTTPS (welches selbstverständlich verwendet werden muss) vor den Blicken von Hackern geschützt.
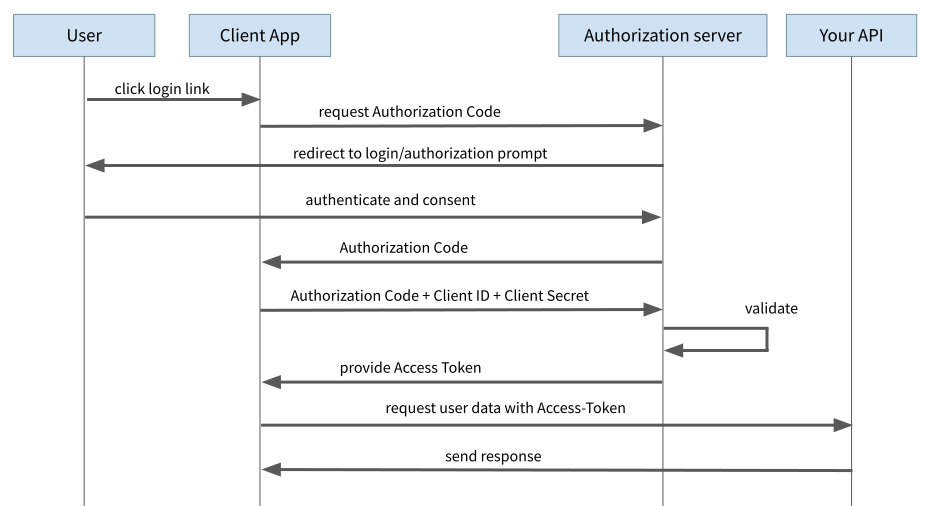
Das Problem mit der browserbasierten Single-Page-App
Eigentlich ist dieser Flow aber vor allem für serverseitig gerenderte Web-Anwendungen gedacht, so dass der Austausch des Authorization Codes gegen den Access Token auf dem Server stattfindet. In dem Fall kann insbesondere das Client Secret auf der Serverseite verbleiben und muss nicht an den Browser übermittelt werden. Bei Single-Page-Apps muss aber der gesamte Prozess im Browser stattfinden und daher benötigt die App auch das Client Secret. Die Schwierigkeit ist somit, das Client Secret „geheim“ zu halten. In der Praxis stellt sich dies als praktisch unmöglich heraus, denn letztlich muss das Client Secret als Teil des Anwendungscodes gebundelt und an den Browser ausgeliefert werden. Das Bundling bei modernen SPA-Frameworks produziert zwar unlesbaren JavaScript-Code, aber es bleibt eben JavaScript und ein Angreifer oder eine Angreiferin könnte sich diesen Code anschauen, das Client Secret extrahieren und damit die Anwendung kompromittieren. Die Lösung hierfür lautet „PKCE“.
Authorization Code Flow mit PKCE
PKCE steht für „Proof Key for Code Exchange“ und ist eine Erweiterung des Authorization Code Flows. Hierbei wird auf das statische Client Secret verzichtet und stattdessen im Prinzip bei jedem Authentifizierungsvorgang ein neues Secret dynamisch generiert.
Dazu wird ganz am Anfang ein sogenannter „Code Verifier“ generiert. Dabei handelt es sich um eine Zeichenkette aus Zufallszahlen. Aus dem Code Verifier wird die „Code Challenge“ berechnet, in dem der Code Verifier mit dem Hash-Verfahren SHA256 gehasht wird.
Beim initialen Login-Vorgang zum Anfragen des Authorization Codes schickt die Anwendung die Code Challenge mit zum Auth Provider. Der Auth Provider merkt sich die Code Challenge und antwortet wie bisher mit dem Authorization Code.
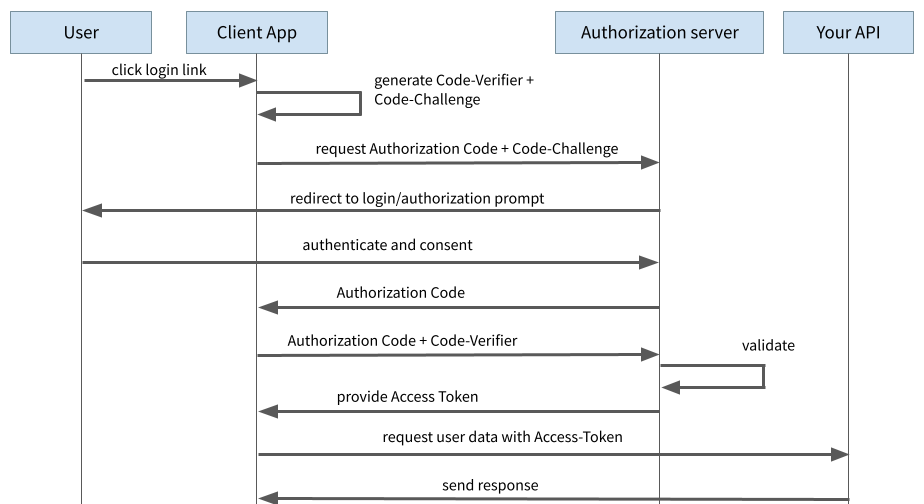
Beim anschließenden Request für den Austausch des Authorization Codes gegen den Access Token schickt der Client nun den Code Verifier mit. Der Auth Provider kann nun prüfen, ob der Code Verifier und die Code Challenge zusammenpassen, indem er seinerseits das Hashing mit SHA256 durchführt.
Ein Angreifer kann bei diesem Verfahren nicht mehr das Client Secret extrahieren, da kein solches Client Secret mehr existiert. Von außen könnte ein Angreifer oder eine Angreiferin höchstens die Code Challenge abgreifen, da diese beim initialen Request über einen Browser Redirect an den Auth Provider übermittelt wird. Der Angreifer oder die Angreiferin hat aber keine Kenntnis vom Code Verifier und kann diesen auch nicht anhand der Code Challenge ableiten. Ohne den Code Verifier stellt der Auth Provider aber kein Access Token aus, womit ein Angreifer oder eine Angreiferin erfolgreich ausgesperrt ist.
Ursprünglich wurde das PKCE-Verfahren vor allem für native Mobile-Apps entwickelt, es lassen sich damit aber auch im Quellcode öffentlich einsehbare Single-Page-Apps sicher umsetzen. Und nicht nur das: Mittlerweile wird das Verfahren sogar für weitere Anwendungsarten wie serverseitige Anwendungen empfohlen, für die bisher der normale Authorization Code Flow mit Client Secret vorgesehen war.
PKCE im Detail
Da der Authorization Code Flow mit PKCE das Mittel der Wahl für Single-Page-Apps ist, wollen wir die einzelnen Schritte etwas genauer anschauen.
- Code Verifier und Code Challenge
Zunächst wird der Code Verifier und die Code Challenge berechnet:
const code_verifier = "fkljl34l5jksdlf" // generate random string const code_challenge = sha256(code_verifier)
In diesem und den folgenden Beispielen verwende ich verkürzte Zufallswerte, um die einzelnen Schritte und Parameter besser darstellen zu können. In einer realen Anwendung müssen hier natürlich echte Zufallswerte generiert werden.
Zufallswerte im Security-Kontext sind aber ein eigenes Thema für sich und daher wollen wir an dieser Stelle nicht im Detail darauf eingehen, wie genau der Code Verifier generiert wird. Als Stichwort sei aber die relativ neue Web-Crypto-API genannt, die unter anderem Funktionen zur Generierung von sicheren Zufallszahlen bereitstellt. Auch für das Hashing mittels SHA256 stellt die Web-Crypto-API die richtigen Hilfsmittel bereit.
- Request Token
Nun wird ein Redirect bzw. GET-Request ausgeführt, um den Authorization Code zu erhalten:
GET <auth-server>/openid-connect/auth? & response_type=code & client_id=oauth-demo & scope=openid & state=hkjshkdwe & redirect_uri=https://<app-url>/callback & code_challenge=shkjhek34hk2lhkds & code_challenge_method=S256
Dem Request werden die Code Challenge und die Methode, die zum Berechnen der Code Challenge benutzt wurde (in unserem Fall also SHA256), mitgegeben.
Zusätzlich wird noch ein sogenannter „State“-Parameter mitgegeben, der ebenfalls aus einem Zufallswert besteht. Auf diesen werden wir gleich noch genauer eingehen.
- Login und Redirect
Der Browser wird zur Login-Seite beim Auth Provider weitergeleitet, auf der sich die User einloggen und die App autorisieren können. Anschließend leitet der Auth Provider wieder zur App zurück und nutzt dafür den beim ersten Request übergebenen „request_uri“-Parameter. In der Regel konfiguriert man im Auth Provider eine oder mehrere gültige Redirect-URIs, um zu verhindern, dass ein Angreifer oder eine Angreiferin den Request manipuliert und eine gefälschte Redirect-URI unterschieben will.
Die Redirect-URI muss natürlich im Router der Single-Page-App konfiguriert sein und dort die Parameter entgegennehmen, die der Auth Provider dem Client mitteilen möchte. Der Request dazu sieht in etwa so aus:
https://<app-url>/callback? & code=jehrejkjhsad223ndskj2 & state=hkjshkdwe
Der Authorization Code ist ein Token, den wir im nächsten Schritt gegen den eigentlichen Access Token eintauschen wollen (auch hier nochmal der Hinweis, dass ich zur vereinfachten Darstellung hier ausgedachte und verkürzte Zufallswerte benutze. Ein echter Authorization Code sieht anders aus).
Außerdem taucht wieder der State-Parameter auf. Diesen haben wir im vorherigen Schritt als Zufallswert generiert und dem Auth Provider mitgeschickt. Der Auth Provider schickt den State unverändert wieder zurück. Auf diese Weise kann unsere Client App herausfinden, ob der Antwort-Request tatsächlich auf einen eigenen Token Request folgt oder nicht. Sollte ein Angreifer einen Token Request initiiert haben, wäre der dazugehörige State-Parameter bei der App unbekannt und der Request damit direkt als unsicher entlarvt. Dieses Verfahren schützt insbesondere gegen sogenannte CSRF-Attacken (Cross Site Request Forgery, weitergehende Erklärung u. a. hier: https://security.stackexchange.com/questions/20187/oauth2-cross-site-request-forgery-and-stateparameter).
- Exchange Code for Access Token
Nun können wir unseren Authorization Code gegen den eigentlichen Access Token austauschen. Dazu starten wir einen POST-Request:
POST <auth-server>/openid-connect/auth/token? & grant_type=authorization_code & code=jehrejkjhsad223ndskj2 & client_id=oauth-demo & redirect_uri=https://<app-url>/callback & code_verifier=fkljl34l5jksdlf
Als Parameter übergeben wir u. a. den Authorization Code und den Code Verifier. Als Antwort erhalten wir nun endlich den Access Token, den wir anschließend für Requests gegen den API-Server verwenden können. Die Antwort sieht in etwa so aus:
HTTP/1.1 200 OK
Content-Type: application/json
{
"access_token": "<jwt token>",
"token_type": "bearer",
"expires_in": 3600,
"refresh_token": "<jwt token>",
"scope": "tasks"
}
Wir erhalten den Access Token und einige weitere Informationen zum Token.
Wie sieht so ein Access Token genau aus? Als Format hat sich der „JSON Web Token“ Standard, kurz JWT, etabliert. Dieser ermöglicht nicht nur den standardisierten Austausch von Authentication-/Authorization-Daten, sondern auch die Verifizierung der Token. Zur Verifizierung steht dabei sowohl eine symmetrische als auch asymmetrische Verifikation zur Verfügung. Damit kann unser API-Server die Gültigkeit der Access Token prüfen, ohne den Auth Provider bei jedem Request kontaktieren zu müssen.
User-Freundlichkeit steigern mit dem Refresh Token
Ein weiterer Aspekt von OAuth sind sogenannte „Refresh Token“. Im vorherigen Beispiel haben wir einen solchen Token zusammen mit dem Access Token erhalten. Die Idee ist, die Gültigkeit von Access Token möglichst kurz zu halten (im Bereich von einigen Minuten bis wenige Stunden). Nach Ablauf des Access Token muss dieser erneuert werden. Dies hat den Vorteil, dass eventuell kompromittierte Access Token nur begrenzten Schaden anrichten können. Außerdem haben User bei OAuth die Möglichkeit, ihre Autorisierung rückgängig zu machen, d. h. beispielsweise die Berechtigung einer App, auf die eigenen Daten zugreifen zu dürfen, beim Auth Provider wieder zu entziehen. Da zur Verifikation von Access Token auf Seiten des API-Servers aber keine Kommunikation mit dem Auth Provider vorgesehen ist, bekommt der API-Server von diesem Rechte-Entzug nichts mit.
Sobald jedoch der alte Access Token abgelaufen ist und ein neuer besorgt werden muss, greifen die neuen Berechtigungen. Allerdings möchte man aus Komfortgründen die eigenen Anwenderinnen und Anwender ungern alle paar Minuten erneut zum Einloggen auffordern. Aus diesem Grund übermittelt der Auth Provider einen länger gültigen Refresh Token. Dieser wird in der Client App gespeichert und bei Ablauf des Access Token benutzt, um sich bei beim Auth Provider einen neuen Access Token zu holen. Der Auth Provider fordert in diesem Fall keinen neuen Login vom Nutzer oder der Nutzerin. Sollte dieser aber zuvor die Berechtigungen für die App entzogen haben, stellt er keine neuen Access Token mehr aus. Wichtig ist: Der Refresh Token ist noch wertvoller als der Access Token und muss daher um jeden Preis vor dem Zugriff von unberechtigten Dritten geschützt werden!
Fazit
OAuth ist ein spannendes Protokoll, das die meisten Fragen rund um Authentifizierung und Autorisierung sicher lösen kann. Allerdings ist das Thema nicht gerade einsteigerfreundlich und am Anfang können einen die vielen Begriffe und Abläufe schnell überfordern.
Hat man sich dann endlich in die Thematik eingedacht, stellt sich die Frage nach der Umsetzung. Insbesondere bei Single-Page-Anwendungen existieren im Netz noch viele Anleitungen, die auf den mittlerweile nicht mehr empfohlenen Implicit Flow verweisen. Mit PKCE steht aber eine Erweiterung bereit, die auch den besseren Authorization Code Flow für JavaScript-Anwendungen ermöglicht.
Um die Umsetzung zu vereinfachen, existieren zahlreiche Bibliotheken. Zum einen bieten Cloud-Anbieter, die OAuth nutzen, häufig eigene Hilfsbibliotheken an. Empfehlenswert ist aber auch ein Blick auf die Bibliothek „OIDC-Client“ (https://github.com/IdentityModel/oidc-client-js), die eine anbieterunabhängige Lösung bietet. Neben dem reinen OAuth unterstützt diese Bibliothek auch die Erweiterung „OpenID Connect“, die OAuth um Funktionen für User-Profile und Authentifizierung ergänzt. Die Bibliothek abstrahiert zwar die einzelnen Schritte der OAuth Flows, so dass man sich nicht mehr mit den einzelnen Requests und deren Parametern „herumschlagen“ muss. Ein gewisses Grundverständnis der Abläufe ist aber dennoch nützlich und hilft bei der sinnvollen Verwendung der Bibliothek.